javascript 学习笔记(重新整理版)
前言
是时候重新整理笔记了,从一无所知的萌新变成菜鸟,总归是有点进步了
严格模式
严格模式的作用
ES5 新增的严格模式是一种不同的 JavaScript 解析和执行模型,ES3 的一些不规范写法在这种模式下会被处理,对于不安全的活动将抛出错误。
使用方式
"use strict";语法虽然看起来像个没有赋值给任何变量的字符串,但它其实是一个预处理指令。任何支持的 JavaScript 引擎看到它都会切换到严格模式。
严格模式的作用域:全局作用域和函数作用域
当在
*.js文件开头使用,整个脚本文件启用严格模式在函数作用域中使用,仅在函数作用域内生效
javascriptfunction fun1() { "use strict"; //函数体 }
严格模式的总结
关键字:
- 严格模式定义变量必须使用关键字
var,let,const,否则抛出 ReferenceError - 不能使用
eval和arguments作为变量名
注意:使用严格模式会影响 javascript 的执行效果,所以在下文中,除非特别声明,默认都是不使用严格模式
变量
标识符
命名规则
第一个字符必须是字母、下划线(_)、美元符号($)【记住标识符不能数字开头就行,命名一般是驼峰命名法,例如
myHouse】剩下的其他字符可以是字母、下划线、美元符号或数字
关键字和保留字不能做标识符
text//关键字 break case catch class extends const continue debugger default delete do in typeof else export finally for function if import instanceof new return super switch this throw try var void while With yieldtext//为ES6保留的关键字(保留字) 始终保留:enum 严格模式下保留:implements package public interface protected static let private 模块代码中保留:await
变量声明
关键字并不决定变量的类型,仅仅是规定了变量的作用域和其它一些特性。
作用域:使用不同关键词定义的变量作用域不同,在使用变量时会在自己的作用域内查找,找不到才会向上一级作用域查找(使用 let 关键字,可能会出现暂时性锁区)
无关键字
声明赋值
a;作用域
无关键词定义的变量,只有全局作用域,所以a一定会被添加到window对象上。这里当fun1函数执行后,会在全局作用域下创建变量a
function fun1(){
a=2;
console.log(a);
}
fun1();// 2
console.log(a)// 2严格模式:严格模式下不允许使用这种方式,否则抛出 ReferenceError
var 关键字
声明赋值
var a; //默认值为undefined
var b = 1; //声明和赋值
var c = 2,
b,
d = 2; //多变量同时声明赋值,c为2,b为undefined,d为2
var e = 1;
var e = 3; //同一个作用域var变量可重复声明,后面值的会覆盖前面的,详细参见`其它`注意:var声明的变量a,如果不赋值默认为undefined
作用域
var 有全局作用域和函数作用(无块级作用域),如果定义在全局作用域上,a会被添加到window对象上
//全局作用域
var a = 1;
console.log(a); // 1
//函数作用域
function fun1() {
var b = 2;
console.log(b);
}
fun1(); // 2
console.log(b); //报错定义在函数作用域内的b,只在函数执行时存在,函数执行完毕,就会销毁变量,所以会报错
声明提升
仅将变量声明提升到变量所在作用域的第一行(变量赋值不会提升)
function fun1() {
console.log(b);
var b = 2;
}
fun1(); //undefined考虑变量提升,实际是
function fun1() {
var b; //仅声明提升到了作用域顶部,这时候b未赋值,默认为undefined
console.log(b);
b = 2; //赋值还是在原来的位置
}
fun1(); //undefined其他
var 声明的变量在同一个作用域可重复声明,不会报错
function fun1() {
var b = 2;
var b = 3;
var b = 4;
console.log(b);
}
fun1(); //4考虑变量提升,实际是
function fun1() {
var b; //使用var关键字时,JS引擎会自动移除多余的声明,
b = 2;
b = 3;
b = 4;
console.log(b);
}
fun1(); //4不同作用域可以定义重名变量,使用变量时,如果本级作用域能查找到该变量,就使用本级作用域,否则向外寻找该变量,直到找到为止,否则抛出错误ReferenceError: xxx is not defined
let 关键字
声明赋值
let a; //默认值为undefined
let b = 1; //声明和赋值
let c = 2,
b,
d = 2; //多变量同时声明赋值与 var 不同的地方: 同一作用域下,不可重复声明,否则抛出错误SyntaxError: Identifier 'xxx' has already been declared
let e = 1;
let e = 3; //SyntaxError: Identifier 'e' has already been declared下面的使用不同关键字的同名变量仍会报错。(只有多个 var 定义的同名变量才不会把报错)
let e = 1;
var e = 3; //SyntaxError: Identifier 'e' has already been declared作用域
let 有全局作用域、函数作用域、块级作用域
//全局作用域
let b = 1;
console.log(b); // 1
//函数作用域
function fun1() {
let b = 2;
console.log(b);
}
fun1(); // 2
//块级作用域
if (true) {
let b = 3;
console.log(b); //3
}暂时性死区
暂时性死区(temporal dead zone,TDZ),这个名字很形象。
使用不同关键词定义的变量作用域不同,在使用变量时会在自己的作用域内查找,找不到才会向上一级作用域查找,但是如果出现下面的暂时性锁区,就会抛出错误ReferenceError: Cannot access 'a' before initialization
对于 let 出现暂时性锁区的发生有 3 个原因:
- 第一个,在块级作用域中,访问了在其后面声明的 let/const 变量(let,const 都没有声明提升)
- 第二个,也是最为重要的,js 引擎是能感知到块级作用域内有该变量的。所以 js 引擎会在该块级作用域的顶部(下面代码中的A 区域)——使用变量之前的范围查找变量,但是却找不到。但 js 引擎又能感知到块级作用域内有该变量,所以不会再上一级作用域去继续查找该变量。【这里就能明白,暂时性死区,就是指的查找变量的位置被锁死在了上面提到的范围里了】
let a = 1;
function fun() {
//-------------
// A区域
//---------------
console.log(a); //使用变量a,会在上面的区域查找变量a。但是却找不到,而js引擎又感知到块级作用域内有变量a,所以不会再向上一级查找变量a,所以被锁死在这个位置了
let a = 2;
}
fun(); //ReferenceError: Cannot access 'a' before initializationconst 关键字
基本与 let 相同,唯一区别是 const 是常量,初始化时必须赋值,且不能修改。更严谨的说法是,const 类型的变量,初始化后的变量指向的内存地址不可以改变
声明 const 变量未赋值
javascriptconst a; //SyntaxError: Missing initializer in const declaration修改 const 变量初始值
javascriptconst a = 10; a = 9; //报错赋值给常量,Uncaught TypeError: Assignment to constant variable.
但是!!!当 const 的是对象时,const 变量指向对象的内存地址,不可修改,但是对象的内容可以修改,因为对象的内容更改,不会引起内存位置变化
const stu = {
name: "张三",
age: 18,
};
stu.age = 20;
console.log(stu); //输出{name: "张三", age: 20}如何锁定 const 指向对象时,对象不许改变
const stu = {
name: "张三",
age: 18,
};
Object.freeze(stu); //锁定对象
stu.age = 20;
console.log(stu); //不报错,但是修改失效,输出{name: "张三", age: 18}变量类型
两种变量类型
每种对象的详细信息可查询菜鸟教程 - JS对象参考手册
ECMAScript 有两大数据类型
基本类型(也称为原始类型):
undefined、null、boolean、number、string和symbol引用类型:
Object、Array、Function、Set、Map【object是所有引用类型的基类】包装类型
Boolean、Number、String 。这几种包装类型我们一般不是使用,而是使用字面量创建值,当对应的基本类型的字面量,使用
.方法调用相关属性和方法时,就在背后自动创建jsconsole.log("hello".length); //5 //本质:包装类String("hello"),创建了string对象内置的工具类型
Data(时间相关)、Math(数学计算相关)、RegExp(正则相关)
Bom对象(浏览器)
Window 对象、Navigator 对象、Screen 对象、History 对象、Location 对象、存储对象【由sessionStorage对象 和 localStorage对象组成】
Dom对象(网页文档)
Html对象
两大数据类型的区别:
基本类型
占用空间固定,保存在栈中(当一个方法执行时,这个方法就会建立自己的内存栈,在这个方法内定义的变量将会逐个放入这块栈内存里,随着方法的执行结束,这个方法的内存栈也将会销毁)
变量保存的是值本身
引用类型:
占用空间不固定,保存在堆中(因为对象的创建成本通常较大,所以当程序中创建的对象将被保存到堆内存,以便反复利用。堆内存中的对象不会随方法的结束而销毁,即使方法结束后,这个对象还可能被另一个引用变量所引用,只有当一个对象没有任何引用变量引用它时,系统的垃圾回收机制才会在核实的时候回收它。)
变量保存的是指向对象的一个指针
1、基本类型的属性和方法
变量类型的确定
因为 JS 中没有类型检查,所以经常接收到某个变量时,需要判断变量类型时,如果变量是预期的类型才进行操作,常用 if 来进行流程控制
if (typeof a === "number") {
//a如果是数字,才执行操作(逻辑一般写在这里)
} else {
//不是数字,就另一种处理方式
}基本类型
基本类型中,只有 null 类型检测不出来,无法区分null和object
var b = null;
console.log(typeof b); //object ,所以使用typeof是判断不出来null的但是,null 类型,只有一个值 null,我们可以直接使用 ===来判断
let a = null;
console.log(a === null); //true
//undefined同理(推荐使用===,而不是typeof)
let a = undefined;
console.log(a === undefined);其他基本类型都可以用typeof
var a = undefined; //undefined
console.log(typeof a === "undefined"); //true
var c = true; //布尔值
console.log(typeof c === "boolean"); //true
var d = 9; // 数值
console.log(typeof d === "number"); //true
//--------NaN属于number类型---------
var e = NaN; // 数值
console.log(typeof e === "number"); //true
//-----------------------------
var str = "hehehe"; // 字符串
console.log(typeof str === "string"); //true
var f = Symbol();
console.log(typeof f === "symbol"); //true引用类型
引用类型本质都是 object 类,其中只有 function 能用typeof检测出来
var h = function () {};
console.log(typeof h === "function"); //true数组使用instanceof
console.log(typeof []); //object
console.log([] instanceof Array); //true如何判断除去数组和函数的其他对象呢?
因为null、array的typeof返回值都是object,所以没法用typeof的值是否为"object"区分console.log(typeof a === "object" && a !== null && a instanceof Array);令人迷惑的一点是,typeof用未声明变量,不仅不会报错,还能返回 undefined。
console.log(j); //ReferenceError: a is not defined
console.log(typeof j); //undefined基本变量类型
undefined类型
undefined类型只有一个值,就是undefined。强调下,undefined是一个值,而不是报错,报错是Error对象
字面量赋值
let a = undefined;其他情况下产生的 undefined
声明但未赋值的变量的默认值为
undefined, 注意区分下,打印声明但未赋值的变量值为undefined,打印未定义变量则会报错javascriptlet a; console.log(a); //undefined console.log(b); //ReferenceError: b is not defined数组。令人迷惑的是,在其他语言中访问不存在的数组索引,必然报数组越界的错误,而 js 不会报错,而是返回值
undefinedjavascriptlet a = []; console.log(a[0]); //undefined对象,这个也十分令人迷惑
javascriptlet stu = {}; console.log(stu.name); //undefined console.log(stu.name.firstName); //TypeError: Cannot read properties of undefined (reading 'firstName')
null类型
null类型只有一个值,就是null。
补充:
null 可以理解为一个空值,其他文章中常常将 null 理解为空对象,这是错误的
是使用typeof判断其类型,返回值是object,是一个历史悠久的 bug,在 js 的最初版本中使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,然而 null 表示为全零,所以将它错误的判断为 object。虽然现在的内部类型判断代码已经改变了,但这个 Bug 却是一直流传下来。
我们在声明一个对象时,一般将该对象使用初始化为null
字面量赋值
let a = null;其他
由于undefined值是由null值派生而来的,因此 ECMA-262 将它们定义为表面上相等:
console.log(null == undefined); //true
console.log(null === undefined); //false 所以,推荐一定要使用===和!==,因为==和!=会将等号两边做一个隐式转换,全部转换为数字,再进行比较
boolean类型
boolean类型包含两个值:true,false
字面量赋值
let a = true;
let b = false;构造函数创建
使用Boolean包装类创建的是一个对象,所以 typeof 是 object ,我们通常不使用这种方式
let a = new Boolean(true);
console.log(typeof a); //object类型包含的值
boolean类型包含两个值:true,false,可以直接判断
let a = true;
if (a === true) {
}else{
}不能用以下的方式,因为对变量判断真假时,会将变量隐式转换为对应的布尔值。非布尔值,也会被判断为真或者假
let a = true;
if (a) {
} else {
}这份表格是不同类型变量转化为布尔值的对应关系

总结下:以下 6 个值转化为布尔值,均是 false。其他均是 true,尤其注意[]和{}都是 true
Number类型中的0,NaNString类型中的""Null类型中的null,undefined类型中的 undefined,Boolean类型中的 false
number类型
number类型包含NaN、0 和其他数字
字面量赋值
let a = 1;Number包装类创建
let a = new Number(1);
console.log(typeof a); //object存储
由于存储浮点数需要占用较大的空间,所以 js 尽可能将浮点数存储为整数
当数字很大或很小时,会转化为科学记数法存储
let num1 = 1; // 当成1处理
let num2 = 10.0; // 当成10处理Infinity/-Infinity
当数字超过浏览器限制的最大/最小值后,数字就会变成 Infinity/-Infinity
比如:除数和被除数都是 0
console.log(5 / 0); // Infinity
console.log(-5 / 0); // -Infinity无穷是数字,所以是可以继续运算的,只不过结果也一定是无穷
console.log((-5 / 0) * -2); // Infinity可通过Number.MAX_VALUE和Number.MIN_VALUE获取浏览器的数字的最大和最小值
console.log(Number.MAX_VALUE);
console.log(Number.MIN_VALUE);通过isFinite()判断运算的结果是否超过最大和最小值,返回值为布尔值,正常范围的数字返回true
console.log(isFinite(2.31)); //true
console.log(isFinite(Infinity)); //false
console.log(isFinite(-Infinity)); //false
console.log(isFinite(NaN)); //falseNaN
NaN表示返回数字的操作失败了(一般语言会报错,而 js 不会报错)
哪些操作会导致产生NaN呢?
除数和被除数都是 0
javascriptconsole.log(0 / 0); // NaN数字计算式中,某一步出现了
NaN,所有的运算的结果都是NaNjavascriptconsole.log(3 + NaN); //NaN内置函数返回
javascriptconsole.log(parseInt("a2")); //NaN
NaN不等于包括 NaN 在内的任何值,无论是使用==还是===
console.log(NaN === NaN) //falseisNaN()
判断变量是否是NaN
这个函数会使用Number()把参数转变为数值,其中转化为NaN的返回true
因为Number()的缺陷,所以可以参照表格中第二列,查看哪些类型的参数会被错误的认定为数字(即,返回 false)
console.log(isNaN(null));
console.log(isNaN(""));
console.log(isNaN(true), isNaN(false));
console.log(
isNaN([]),
isNaN([undefined]),
isNaN([null]),
isNaN([3]),
isNaN(["3"])
);Number()
转化结果参照变量转化为数字表
Number的缺陷是,Number会将各种的变量类型转化为数字,十分可能造成运算结果的错误。比如,将true转化为 1,将""转化为 0 等
parseInt()
参数不是字符串时,使用Number()转化为数字后,再取整数部分。
当参数是字符串时,不是Number()转化的,而是直接按照从左到右的顺序一位一位的转换为数字
- 如果遇到空格或 0,直接忽略
- 直到遇到负号或第一非 0 数字,才开始转化
- 直到遇到非数字的字符或到了字符串结尾,才停止转化,然后返回转化结果
//情况一:从左到右遇到非数字结束
console.log(parseInt("11a")); //11
console.log(parseInt("12.3")); //12注意:以下两种情况的例子
当参数是空字符串时
Number('') //返回0
console.log(parseInt("")); //NaN当参数是空数组
Number([]) //0
console.log(parseInt([])); //NaNparseInt的缺陷大部分与Number相同,会将各种的变量类型转化为数字,造成计算的错误。 再加一点是会错误的把例如11a这种字符串转化为数字11,如果运算中出现了11a,js 仍然不会报错,而是当成11继续去计算,而Number不会有这种问题
parseFloat()
基本与parseInt相同,只是从左到右转化字符串时,遇到第一个.不会结束,还会继续向右转化数字
//情况一:从左到右遇到非数字结束
console.log(parseFloat("11a")); //11
console.log(parseFloat("12.3")); //12.3
console.log(parseFloat("12.3.4")); //12.3
//情况二:Number('')返回0
console.log(parseInt("")); //NaN总结
最佳实践:有时候使用后端返回的字段进行计算数据时,万一出现了非数字部分,很容易出现错误。
这里使用Number转化,因为parseInt('123a')的结果是123,这回使的计算式按照错误的值去计算;但是Number("")会转化为0,这是错误的,需要排除 ""
let str=""//通过外部传入,可能是各种类型
if(typof str===string && str!=="" && !isNaN(Number(str)*2)){
//如果运算的结果是正常的数字,就会执行到这里
}else{
}
//使用这个更好,甚至数字超出最大值/最小值都能规避掉
if(typof str===string && str!=="" && isFinite(Number(str)*2)){
}else{
}toFixed
将数字转换为字符串,并保留指定位数的小数位
toFixed的保留方式不是四舍五入,而是银行家舍入规则
- 四舍
- 六入
- 五考虑 :
- 五后非零就进一
- 五后为零看奇偶,五前为偶应舍去,五前为奇要进一
5.426.toFixed(2) //'5.43'如何实现四舍五入
Math的round是遵循四舍五入的,但是这能保留整数,所以需要做处理
function myRound(num,n){ //将num保留n位
let multiple=Math.pow(10,n)
Math.round(num*multiple)/multiple
}string类型
String类型包含""、其他字符串
字面量赋值
ES 标准中对于字符串使用不同引号是没有区别的
let str1 = "hello";
let str2 = "hello";
let str3 = `hello`;使用String()包装类型
let str = new String(1);
console.log(typeof str); //objectES 标准中的字符串是不可变的,一旦创建,它们的值就不能变了。要修改某个变量的字符串值,必须先销毁原始的字符串,然后将包含新值的另一个字符串保存到该变量
let str = "hello";
str = str + " world"; //原来的hello会被销毁,从新分配内存空间给 hello worldstr.length
字符串字节个数,一个汉字/字母/数字/空格算一个字符
console.log("hello world".length); //11str.toString()
将变量str转化为  字符串,除了undefined和null以外,将其他类型原模原样的转过去
let a = true;
console.log(a.toString()); //true
let b = 2;
console.log(b.toString()); //2
let c = "hello";
console.log(c.toString()); //hello
let d = [1, 2, 3];
console.log(a.toString()); //1,2,3 就是直接数组元素组成的字符串
let e = {};
console.log(e.toString()); //[object Object]这个方法有缺陷,当变量是undefined和null没有toString()方法,会抛出错误,所以如果不确定变量的值,更推荐使用String()
console.log(null.toString()); //TypeError: Cannot read properties of null (reading 'toString')
console.log(undefined.toString()); //TypeError: Cannot read properties of undefined (reading 'toString')String()
解决toString()的缺陷,除了这两个以外,其他的类型都有toString()方法,所以其他的类型会调用toString()
console.log(String(undefined)); //undefined
console.log(String(null)); //null模版字面量
- 可以直接把变量或表达式放入${ }中,不必拼接字符串
- 可以折行,不必写在一行上,但是字符串显示也相应换行
let title = "标题";
let content = "内容";
//过去的写法,拼接字符串,麻烦,而且不能折行写
let str = "这里是" + title + ",那里是" + content;
//字符串模板
let str2 = `这里是${title},那里
是${content}`;
console.log(str);
console.log(str2);
//输出
//这里是标题,那里是内容
//这里是标题,那里
//是内容
document.write(str2); //网页上输出:这里是标题,那里 是内容
//字符串即使有多个连续的空格,在网页中也只是有1个空格,网页想要有多个空格用多个 ${}甚至可以放函数
//${}中可以放表达式
var a = `www.${3 + 1}`;
console.log(a); //www.4注意:${a}显示变量 a,相当于String(a)函数
console.log(`${undefined}`); //undefined
console.log(`${null}`); //null标签函数
var name = "hedaodao";
var age = 20;
tag`你好我是${name},年龄${age}。`; //字符串前,加一个标记,可以是tag也可以是其他什么名字
function tag(string, name, age) {
//函数名是标记名,第一个参数string,接收除变量的部分
console.log(string);
console.log(name, age);
}
//输出
//["你好我是", ",年龄", "。", raw: Array(3)]
//hedaodao 20
//注意:函数的第一个参数string,接收除变量的部分,如果字符串是 tag`${name}` ,返回的是["",""],即使变量前后没有字也会返回symbol(内容太晦涩,暂时跳过)
Symbol(符号)是 ES 6 新增的数据类型。符号是原始值,且符号实例是唯一、不可变的。符号的用途是确保对象属性使用唯一标识符,不会发生属性冲突的危险。
Symbol没有字面量语法,必须使用Symbol()来创建,且不能使用new关键字来创建symbol对象,创建方式:
一、普通符号
即使描述相同也不相等
//创建两个Symbol
let a = Symbol();
let b = Symbol();
console.log(a === b); //false
//创建带描述的Symbol
let c = Symbol("张三");
let d = Symbol("张三");
console.log(c === d); //false二、全局符号
描述相同的符号相等,原因看下面的原理
Symbol.for(String)
参数会使用使用 String() 转化为字符串【前面讲过这个方法没缺陷,可以转null和undefined为字符串"null"和"undefined"】
原理:Symbol.for会对每个字符串键都执行以下操作。在全局运行时注册表中查找参数字符串对应的Symbol,找不到就会生成一个新Symbol实例并添加到全局注册表中。找的到,就会返回该Symbol实例。
let c = Symbol("张三");
let d = Symbol.for("张三");
let e = Symbol.for("张三");
console.log(c === d); //false 普通和全局即使描述相同,相等
console.log(d === e); //true 全局只有一个"张三"实例,所以相等Symbol.keyFor(Symbol)
查找全局注册表中,是否存在传入的Symbol参数,如果找到了,返回该Symbol的描述;没找到,返回undefined【参数为Symbol,返回值是Symbol的描述(输入其他类型参数,会抛出异常TypeError: xxx is not a symbol)】
let a = Symbol("123");
let b = Symbol.for("456");
console.log(Symbol.keyFor(a)); // undefined
console.log(Symbol.keyFor(b)); // 456实践
班级统计成绩时,重名很常见,如果重名的话,对象中重名的 key 会被覆盖
let user1 = "张三";
let user2 = "张三";
let grade = {
//对象中使用变量,需要用中括号括起来,key就成了"张三"和"李四",否则key为user1和user2
[user1]: { math: 80, english: 60 },
[user2]: { math: 60, english: 70 },
};
console.log(grade); //输出张三: {math: 60, english: 70}
//解决
let user1 = {
key: Symbol(),
name: "张三",
};
let user2 = {
key: Symbol(),
name: "张三",
};
let grade = {
[user1.key]: { math: 80, english: 60 },
[user2.key]: { math: 60, english: 70 },
};
console.log(grade);
//输出
//Symbol(): {math: 80, english: 60}
//Symbol(): {math: 60, english: 70}取出 Symbol 类型的 key
let symbol = Symbol("这是一个字符串");
let obj = {
name: "张三",
age: 20,
[symbol]: "abcde",
};
for (let key in obj) {
console.log(key);
} //输出name age .不会输出[symbol]
//使用Reflect.ownKeys(obj)解决
for (let key of Reflect.ownKeys(obj)) {
console.log(key);
} //输出 name age Symbol(这是一个字符串)
////这样可以保护内部私有属性
let school = Symbol("这是一个Symbol");
class Student {
constructor(name, age) {
this.name = name;
this.age = age;
this[school] = "实验小学";
}
getName() {
return `${this[site]} ${this.name}}`;
}
}
let stu = new Student("李四", 20);
for (const key in stu) {
console.log(key);
} //输出 name age ,可以看出来即使遍历对象的key,symbol类型的school不会显示出来变量类型隐式转换
发生隐式转换的场景
情况一: 使用if判断变量时
if(a) //将变量转化为布尔值
情况二:进行比较时
a===b //将左右变量都转化为布尔值
情况三:使用&&和||运算符时,会将运算值转化为布尔值
情况四:三元表达式 a?b:c 中,a的值会转化为布尔值变量转化为布尔值
变量转化为数字
与
Number()的效果相同类型 数字 NaN Undefined undefined 转化为 NaN Null null 转化为 0 String "2","4","1.2","-3.5"等纯整数/浮点数/正负数的字符串转化为对应数字,转化时会忽略最前面的 0 和空格,比如:" 00012",转化为 12
""会转化为 0其他情况都是 NaN,比如混合着字母的字符串"123a","a123" boolean true 转化为 1;false 转化为 0 Number 所有具体数字转化为自身;(包括:Infinity、-Infinity 分别转化为 Infinity、-Infinity) NaN Array []转化为 0
[null]转化为 0
[undefined]转化为 0
["3"]等只含有一个数字的数组会转化为对应数字
[3]等只含有一个数字字符串的数组会转化为对应数字其他情况都是 NaN
所有其他情况:元素是布尔值[true]/[false]
数组中有多个元素的,无论是什么元素,均为 NaN,比如[1,2,3]Object 所有对象,包括{} 这里注意下,
parseInt('123a')的结果是123,当你不确定数据的具体形式时,这会带来很大的潜在问题。所以转换数字使用Number(),Number('123a')会直接返回NaN
对象(待完成)
数据属性
我们最为常见的就是对象的数据属性,键值对的形式。key必须是字符串或symbol,value可以是任何类型。
赋值
字面量赋值(常使用)
如果通过中括号语法传入的key不会被直接转化字符串
let b="爱好"
let obj= {
//1、key不包含空格,不以数字开头,也不包含特殊字符(允许使用 $ 和 _),默认转化为字符串。所以,一般省略引号
name: "jack",
//2、key不满足上述要求,这种必须用引号印起来
"l-name": "tom",
//3、默认key是字符串,如果希望把key当做是变量,使用方括号
[b]:"tony"
//4、使用模板字符串,必须用中括号
[`${b}`]:3
}
console.log(obj) //{ name: 'jack', 'l-name': 'tom', '爱好': 'tony' }点方法
点后跟着的是key值(与字面量相同,key默认转化为字符串类型)
let obj={}
//1、设置:key是字符串a,value是数字1
obj.a=1
//2、读取:key为字符串a的值
console.log(obj.a) //1
//3、删除
delete obj.a方括号
中括号中是key值(并不会像字面量中默认转化为字符串)
let obj={}
//1、设置:key是字符串a,value是数字1
obj["a"]=1
//2、读取:key为字符串a的值
console.log(obj["a"]) //1
//3、删除
delete obj["a"]补充提示
let b="name"
obj[b]=1 //设置: key是字符串name,value是数字1简写
let obj={
//1、key和value同名,可简写
name:name,
//简写
name
//2、value是函数类型,可简写
getSome:function(){}
//简写
getSome(){}
}访问器属性
也就是对象的getter与setter用法
在对象字面量中,它们用 get 和 set 表示
属性的setter、getter,不必全部存在
字面量设置访问器属性
let obj={
name:"will",
subName:"smith",
// 可以看做是获取fullName属性的值(必须return一个值)
get fullName(){
return `${this.name} ${this.subName}`
},
// 可以看做是给fullName属性设置值(参数就是传入的新值)
set fullName(value){
this.name=value.split(" ")[0]
this.name=value.split(" ")[1]
}
}
//自动调用get
console.log(obj.fullName)//will smith
//自动调用set
obj.fullName="tom cruise"
console.log(obj.name,obj.subName)//cruise smith用途:访问器属性中的getter可以是将其他数据属性运算后的结果的,setter可以在赋值之前做一些限制操作,符合才给数据属性赋
属性描述符(待补充)
对象的每一个属性都存在一些隐形的描述符,来描述该属性的特性。我们通过字面量方式建立的对象,所有描述符属性都是true,我们也可以使用defineProperty来手动指定
数据属性的属性描述符
writable— 如果为true,则值可以被修改,否则它是只可读的。enumerable— 如果为true,则会被在循环中列出,否则不会被列出。configurable— 如果为true,则此属性可以被删除,这些特性也可以被修改,否则不可以
访问器属性的属性描述符
以上一节的fullName属性为例子,其属性描述符为
set函数
get函数
enumerable:true
configurable:true手动指定属性描述符
let obj={
name:"will",
subName:"smith",
}
Object.defineProperty(obj,"fullName",{
get (){
return `${this.name} ${this.subName}`
},
set (value){
this.name=value.split(" ")[0]
this.name=value.split(" ")[1]
}
})
console.log(obj.fullName)//will smith
obj.fullName="tom cruise"
console.log(obj.name,obj.subName)//cruise smith原型链
记住一点,原型链是对象的
1、[[Prototype]]
每个对象中都有一个内部的而且是隐藏的属性[[Prototype]],
- 这个属性的值只能是null或者另一个对象的引用
- 一个对象只能有一个
[[Prototype]]属性
如果我们访问对象A中不存在的属性(方法),就会去[[Prototype]]属性指向的对象B中查找,如果找不到就会去对象B的[[Prototype]]指向的对象中查找,直到找到该属性(方法),或者找到[[Prototype]]为null的对象作为终点。这条查找的链条叫做原型链
我们也可以说是对象A继承了原型链上其他对象的属性、方法
2、__proto__
因为Prototype这个属性我们不能直接访问到,所以需要借助一个访问器属性(getter/setter)去设置Prototype属性。__proto__的存在是出于历史的原因,现代编程语言建议我们应该使用函数 Object.getPrototypeOf/Object.setPrototypeOf
let animal={
sleep:"动物睡觉"
}
let dog={
say:"汪汪",
__proto__:animal
}
console.log(dog.sleep) //动物睡觉如果dog属性存在sleep,就不会再沿着原型链查找了
let animal={
sleep:"动物睡觉"
}
let dog={
say:"汪汪",
sleep: "狗睡觉",
__proto__:animal
}
console.log(dog.sleep) //狗睡觉3、原型链中的this
可以参照后面的章节【this的指向】,属于其中的【规则3】的情况,对象.函数()其中this指向的都是调用他的对象
形式1:
dog.getThis(),虽然getThis方法是在原型链上的animal中找到的,但是由于是dog调用的,所有其this指向dog
let animal={
sleep:"动物睡觉",
getThis(){
console.log(this)
this.sleep='animal中修改'
}
}
let dog={
sleep: "狗睡觉",
__proto__:animal
}
dog.getThis() //{ sleep: '狗睡觉' }
//下面能看出,getThis修改的是dog中的sleep
console.log(dog.sleep) //animal中修改
console.log(animal.sleep) //动物睡觉形式2
changeSleep中的this指向的应该是dog,相当于在dog中新增了sleep属性
let animal={
sleep:"动物睡觉",
upgradeSleep(){
this.sleep="升级版睡眠"
}
}
let dog={
__proto__:animal
}
dog.upgradeSleep()
console.log(animal.sleep) //动物睡觉
console.log(dog.sleep) //升级版睡眠形式3
dog和cat调用eat方法,虽然也是在animal中找到,并且其中的this指向dog和cat,但是this.stomach.push并不是直接新建一个stomach属性,而是找到animal中的stomach在push
let animal={
stomach:[],
eat(food) {
this.stomach.push(food);
}
}
let dog={
__proto__:animal
}
let cat={
__proto__:animal
}
dog.eat("苹果")
console.log(animal.stomach) //[ '苹果' ]
console.log(dog.stomach) //[ '苹果' ]如何解决dog、cat共用一个stomach。参照前两种方式
let animal={
stomach:[],
eat(food) {
this.stomach.push(food);
}
}
let dog={
stomach:[],
__proto__:animal
}
let cat={
stomach:[],
__proto__:animal
}
dog.eat("苹果")
console.log(animal.stomach) //[ '苹果' ]
console.log(dog.stomach) //[ '苹果' ]4、for in 遍历
for..in 循环也会遍历到原型链上其他对象的属性(前提是该属性的描述符enumerable必须是true)
let animal={
sleep:"动物睡觉",
changeSleep(){
this.sleep="升级版睡眠"
}
}
let dog={
say:"汪汪",
__proto__:animal
}
for(let key in dog){
console.log(key)
}
// say
// sleep
// changeSleep如果不希望遍历其他对象的属性,可以使用hasOwnProperty
let animal={
sleep:"动物睡觉",
changeSleep(){
this.sleep="升级版睡眠"
}
}
let dog={
say:"汪汪",
__proto__:animal
}
for(let key in dog){
if(dog.hasOwnProperty(key)){
console.log(key)
}
}
// say其他对象方法
除for in外,其他的方法都是只能获取对象自身的属性
例如
Object.keys 和 Object.values5、new一个函数
new 函数会返回一个对象,这对象的[[Prototype]]属性(原型链)上会自动添加一个对象
详情见【函数】-【new关键字】章节
静态方法、实例方法
文档:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Object
Object 本质上是个函数,等同于类
常用的静态方法
| 方法 | 描述 |
|---|---|
| keys() | 返回所有key组成的数组 |
| values() | 返回所有value组成的数组 |
| entries() | 返回所有[key,value]组成的数组 |
| assign() | 合并对象,返回合并后新的对象 Object.assign({},{name:"jack"},{age:18}) |
| hasOwn() | Object.hasOwn(obj, 'prop') 判断obj中是否存在prop属性,返回布尔值 |
let obj={name:'jack',age:12}
Object.keys(obj) //['name', 'age']
Object.values(obj) //['jack', 12]
Object.entries(obj) //[['name':'jack'], ['age',12]常用的静态方法
通过prototype属性可以查看到类的普通成员

其他语言一般实例化对象,调用对象的方法
const obj=new Object({name:'tom'})
obj.hasOwnProperty('name') // true
// JS中字面量对象等同于 new Object(字面量)
const obj= {name:'tom'}
obj.hasOwnProperty('name') // trueJS有个很特殊的用法可以直接用类调用实例的方法,如果实例方法访问了this是不存在的,因为没有实例化对象,但是可以用call调用绑定一个对象
const obj={name:'tom'}
Object.prototype.hasOwnProperty.call(obj,'name') // true补充:hasOwnProperty是Object的普通成员,对象可以覆盖了这个方法,使用Object.prototype可以避免
Object.prototype.hasOwnProperty.call(obj,'name')
//
const foo = {
hasOwnProperty() {
return '覆盖';
},
};
foo.hasOwnProperty("bar"); // 覆盖后来有了Object.hasOwn,这个方法是静态成员,就不用使用prototype、call了。
Object.hasOwn(obj, "prop");但是很多旧代码遗留上面的用法,这里分析了这种用法的成因
还有个实例方法toString,这个函数没有相同功能的静态方法,所以只有prototype一种使用方式。目前这是最准确的判断类型的方式
Object.prototype.toString.call(obj) // 返回类型 [object XXXX]
// 例子
console.log(Object.prototype.toString.call('123')) // [object String]
console.log(Object.prototype.toString.call(null)) // [object Null]
// 可以提取出来类型
function typeOf(obj) {
//return Object.prototype.toString.call(obj).replace(/^\[object (.*)\]$/, "$1")
return Object.prototype.toString.call(obj).match(/^\[object (.*)\]$/)[1]
// 个人更倾向于使用match语法,使用replace也行
}
console.log(typeOf(123)); // Number
console.log(typeOf("hello")); // String
console.log(typeOf(true)); // Boolean
console.log(typeOf(undefined)); // Undefined
console.log(typeOf(null)); // Null
console.log(typeOf({})); // Object
console.log(typeOf([])); // Array
console.log(typeOf(new Date())); // Date
console.log(typeOf(/regex/)); // RegExp
console.log(typeOf(function(){})); // Function函数
函数的声明
函数也是一种类型,它使用function关键字声明
使用标准函数声明来定义函数(命名函数,函数名是func1)
javascriptfunction func1(){ //函数体 } func1()声明匿名函数
javascriptlet a=function(){ //函数体 } a()箭头函数:一种匿名函数的简写
javascriptfunction(参数){函数体} //对应 (参数)=>{函数体}注意:
如果只有一个参数,()可以省
javascriptparam=>{//只有一个参数param}如果只有一行,return和{}可以省
js(x,y)=>x+y //当函数体只有一句,就是一个return时,可以省略return和{},函数体就是x+y //对应 function(x,y){ return x+y }
把函数当成构造函数 详见【new关键字】章节
javascriptfunction stu(name,age){ this.name=name//这里的this指向的是stu对象,不是window对象 this.age=age this.show=function(){ //函数体 } //构造函数的返回值是对象,默认有以下这句,this表示user对象 //return this } let res=new stu()对象字面量属性函数
javascriptlet user={ setUsername:function(name){ this.name=name }, getUsername:function(){ return this.name } //简写: //setUsername(name){ // this.name=name //}, //getUsername(){ // return this.name //} } user.setUsername("张三") console.log(user.getUsername())//输出 张三
函数声明存在的问题
覆盖window对象中的属性
这种方式定义函数,函数会压入到window对象中,一旦window对象中有同名属性,会把window对象的该属性覆盖掉
function func(title){
console.log(title)
}
func("你好")//输出 你好
window.func("你好")//输出 你好函数参数
形参与实参
JS中函数是把实参赋值给形参
注意:
如果实参是基本类型,改变形参,肯定不会影响实参
jslet a=1 function show(a){ a=a+100 return a } show(a)//输出 101 console.log(a)//输出 1如果实参是引用类型,形参接收到的是实参的存储地址,所以操作形参的属性,肯定会影响实参
jsfunction show(a){ a.age=20 } let user={name:"张三"} show(user) console.log(user)//输出 {name: "张三", age: 20}当实参个数>形参个数,多余的实参会被略去
jsfunction mySum(a,b){ return a+b } console.log(mySum(1,2,3)) //输出 3
定义默认参数
//定义函数带有默认参数,传入就按传入的值,不传就按默认
function show(a,b=5,c=7){
console.log(a,b,c)
}
show(1)// 输出1,5,7
show(1,2,3)// 输出1,2,3接收多个形参
arguments对象(不建议使用)
javascriptfunction func(){ console.log(typeof arguments)//arguments对象。里面包含着传进来的参数 for(let i=0;i<arguments.length;i++){//arguments对象可以使用下标取值 console.log(arguments[i]) } } func(1,2,3)// 输 1 2 3解构赋值(详见,后面**【解构赋值】章节**)
javascriptfunction func2(...args){ //args就是个数组 console.log(args) } func2()//输出[1,2,3]
函数提升
使用标准函数声明,会有函数提升现象
javascriptshow()//输出 hi function show(){ console.log("hi") }通过变量引用匿名函数,没有函数提升(与赋值变量是var或let没关系)
javascriptfunc()//报错,Uncaught TypeError: func is not a function var func=function(){ console.log("hi") }重点理解
第一个函数函数提升到最前面,在console.log之前
javascriptconsole.log(hd(3)); //4 function hd(num) { return ++num; } var hd = function() { return "hd"; };第一个函数函数提升到最前面,console.log之前被第二个函数覆盖了
javascriptfunction hd(num) { return ++num; } var hd = function() { return "hd"; }; console.log(hd(3)); //hd函数提升和变量提升,当函数和变量同名
jsconsole.log(foo); var foo = 1 //变量提升 console.log(foo) foo() function foo(){ //函数提升 console.log('函数') } //等价于 function foo(){ //提到顶端 console.log('函数') } var foo console.log(foo) //输出foo这个函数,因为上面foo没有被赋值,foo还是原来的值 foo = 1; //赋值不会提升,赋值后 foo就不再是函数类型了,而是number类型 console.log(foo) //输出1 foo() //这里会报错,因为foo不是函数了简略的说
js//函数提升优先级高,但是var a没有赋值,所以不会覆盖函数 var a function a(){ } console.log(a)// 函数a //函数提升优先级高,但是var a赋值为1,所以会覆盖函数 var a=1 function a(){ } console.log(a)// 1
new关键字
使用new调用函数,我们称为这个函数为构造函数。JS中的类本质就是函数
注意:
以下涉及的this指向问题,会在**【this的指向】章节**详细介绍
以下涉及的原型链问题,会在**【原型链】章节**详细介绍
例如
function fun() {
this.a = 3;
this.b = 5;
}
var obj = new fun();
console.log(obj);原理过程是:
function fun() {
//1 .在函数体开头,自动创建了一个空白对象{}
//2 .this指向这个空白对象
//3 .执行函数体中的语句
this.a = 3;
this.b = 5;
//4 .
// 情况一:函数没有return,或者"return;"、"retrun 基本类型;",则直接忽略原本的return。返回自动创建的那个对象
// 情况二:如果 return 返回的是一个对象,则返回这个对象。忽略自动创建的这个对象
}
var obj = new fun();
console.log(obj); //{a: 3, b: 5}实际使用:
- 通过传入参数,返回不同对象
- 约定函数名首字母大写
function Student(name,age){
this.name = name;
this.age = age;
}
console.log(new Student('jack',18)) // { name: 'jack', age: 18 }
console.log(new Student('tom',19)) //{ name: 'tom', age: 19 }为对象添加函数
- 在构造函数内添加一个函数作为对象的属性
- 通过向prototype属性中添加其他函数/属性
//---------- 属性挂载到实例对象上
function Student(name,age){
this.name = name;
this.age = age;
this.getName = ()=>{ //方式1
return this.name
}
}
//---------- 属性挂载到实例对象上
Student.prototype.getAge =function (){ //一定要注意,这里不能用箭头函数,否则其中的this指向了全局的window
return this.age
}
//---------- 属性挂载到函数上,类似于类的静态方法 (this无法访问到name、age)-------------
Student.getSingleInstance =function (){ //方式3
if (this.instance) {
return this.instance;
}
//注意这里是把instance挂在到Student上了
return this.instance = new Singleton(name);
}
// 访问静态方法
console.log(Student.getSingleInstance)
// 访问实例对象方法
// 正常需要new创建实例对象,才能访问到,但是JS中可以直接通过prototype属性访问到
console.log(Student.prototype) // {getAge:f(),constructor: ƒ Student(name,age) }
// 注意如果通过prototype属性访问实例方法,一定要用call。因为实例不存在,getAge内部如果访问this会不存在,我们可以用call绑定到任意上下文
console.log(Student.prototype.getAge.call(this))
let stu1=new Student('jack',18)
console.log('stu1 --> ',stu1.getName(),stu1.getAge()) //stu1 --> jack 18
let stu2=Student.getSingleInstance()
let stu3=Student.getSingleInstance()
console.log(stu2===stu3) // true 即同一个实例函数默认的prototype属性
只有函数才有prototype属性(Class是个语法糖,本质上也是个函数,所以Class也有prototype属性),其值默认为{constructor: ƒ},即key是constructor,value就是函数本身(注意,prototype就是一个属性而已,不是对象的[[prototype]])
let f=function(){
let name='jack'
}
console.log(f.prototype); //{constructor: ƒ}new function的原理
使用new function创建新对象时,就会自动调用该对象的__proto__访问器属性,用来设置对象的[[prototype]]属性为函数的prototype属性,即{constructor: ƒ}
例子:
/*
默认的prototype
即:Rabbit.prototype = { constructor: Rabbit };
*/
function Rabbit() {}
/*
rebbit的`[[prototype]]`是{ constructor: Rabbit }
*/
let rabbit=new Rabbit()
/*
对象rabbit没有constructor方法,但是其原型链上有{ constructor: Rabbit }对象
*/
console.log(rabbit.constructor == Rabbit)//true自定义prototype
prototype就是一个普通属性,所以是可以覆盖的。如果被覆盖就不是默认指向{constructor:Rabbit}了
function Rabbit() {}
Rabbit.prototype={
name:"tom"
}所以,为了不覆盖对象的constructor属性,我们常用的方式是添加新的属性
这样在new function时,创建的对象可以在其原型链上([[prototype]])找到name属性
function Rabbit() {}
Rabbit.prototype.name="tom"
let rabbit=new Rabbit
console.log(rabbit.name); //tom回顾下JS的内建函数
以Object为例子
函数Object的prototype属性
{
//1、构造函数
constructor:Object,
//2 、其他函数
toString() {
//toString的具体实现
}
//3、其上一级原型对象就是null
[[prototype]]:null
}o=new Object()
新对象的上一级原型对象就是上面的这个对象,所以能直接使用原型上的toString方法
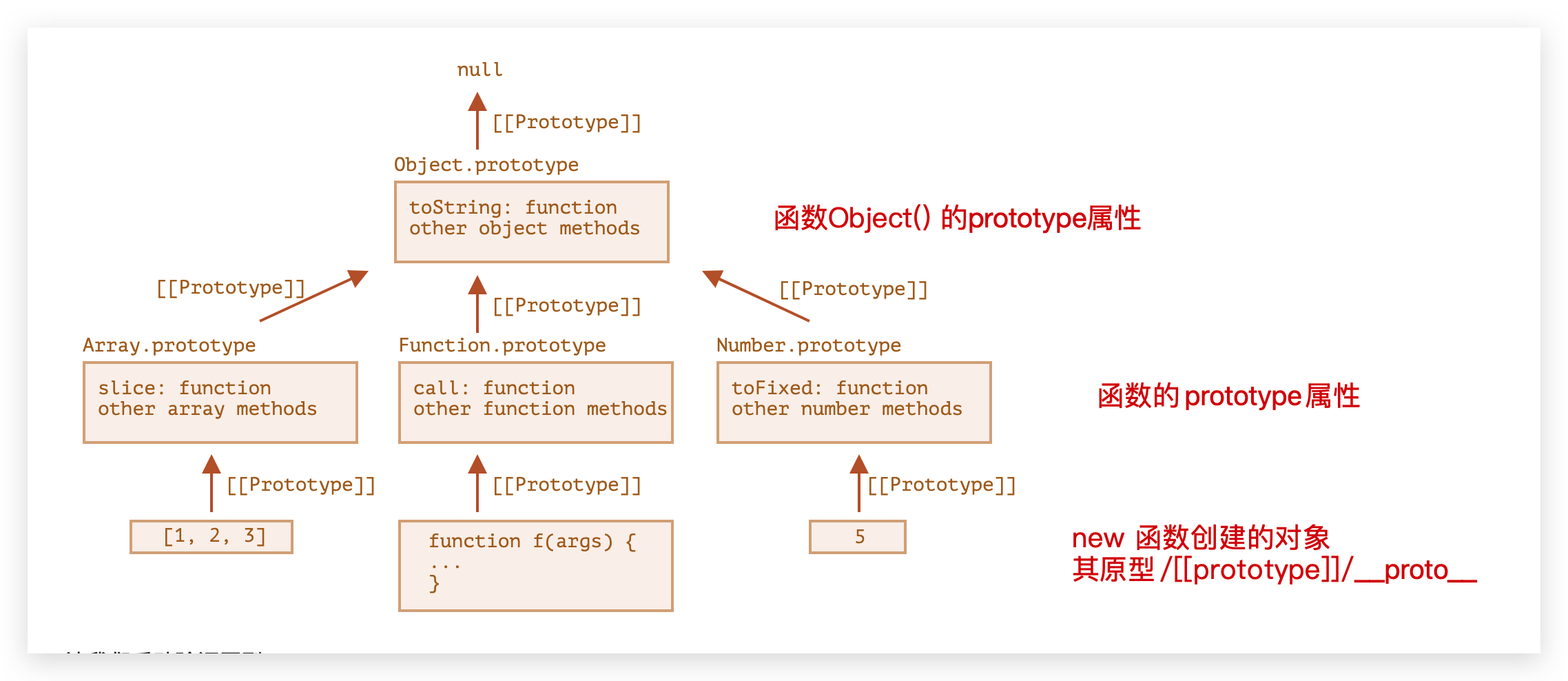
o.toString()总结
将函数A创建的对象,按照原型链一步一步捋到null

或者看这个实际的图,我们应该知道JS所有的内建方法,其实都在其对应函数的prototype对象里。比如,数组的slice方法,就是在Array.prototype里
立即执行函数
立即执行函数(这里放函数声明)()
立即执行函数,执行完毕后立即销毁,所以即使,使用了var关键字,仍然不会污染全局window变量
(function (str) {
console.log(str);
var web = 'houdunren';
})("hello"); //这里把hello传给内部的str参数
console.log(web);
//hello
//web is not defined立即执行函数与作用域的冲突
//1.js
function show(){
console.log("执行1.js中的show函数")
}
function ab(){
console.log("执行1.js中的ab函数")
}
//2.js
function show(){
console.log("执行2.js中的show函数")
}
function ab(){
console.log("执行2.js中的ab函数")
}在html中引用两个外部js文件
<!--两个js文件中都有show()函数-->
<script src="1.js"></script>
<script src="2.js"></script>
<script>
show()//输出 执行2.js中的show函数
</script>
<!--这里调用只能调用到2.js中的show()函数-->解决方案一:使用模块化,ES6以后有了类的概念,提供了新的解决办法,后面会讲到
解决方案二:这是一种老的解决方案,使用立即执行函数
(function(){
console.log("执行了")
})()//输出 执行了
//如何调用内部的函数看下面
//将1.js和2.js改造成这样
(function(window){
function show(){
console.log("执行1.js中的show函数")
}
function ab(){
console.log("执行1.js中的ab函数")
}
window.js1={show,ab}
})(window)//这里带参数把,window传递到函数中
//html页面引入外部js后,调用函数
js1.show()//输出 执行1.js中的show函数
js1.ab()//输出 执行1.js中的ab函数方案三:这是一种老的解决方案,使用let作用域
//前面提到的"函数存在的问题----覆盖window对象中的属性"中,写过全局作用域中的var变量会压入window对象中,let不会
//如何调用内部的函数看下面
//将1.js和2.js改造成这样
{
let show=function(){
console.log("执行1.js中的show函数")
}
let ab=function(){
console.log("执行1.js中的ab函数")
}
window.js1={show,ab}
}
//html页面引入外部js后,调用函数
js1.show()//输出 执行1.js中的show函数
js1.ab()//输出 执行1.js中的ab函数从类的角度看函数
JS中类就是函数的语法糖,但是由于函数的一些性质,导致JS中将函数当做类使用时,存在大量神奇的语法
目前还未测试直接使用Class关键字声明的类是否也具有这些特殊的能力
动态调整类
import { ExtractJwt, Strategy } from 'passport-jwt';
import { PassportStrategy } from '@nestjs/passport';
import { Injectable } from '@nestjs/common';
@Injectable()
// PassportStrategy类可以传入参数,来定制类的功能
export class JwtStrategy extends PassportStrategy(Strategy) {
constructor() {
super({
jwtFromRequest: ExtractJwt.fromAuthHeaderAsBearerToken(),
ignoreExpiration: false,
secretOrKey: 'guang',
});
}
async validate(payload: any) {
return { userId: payload.userId, username: payload.username };
}
}类直接调用实例方法
正常情况下,类实例化后的对象才能调用实例方法
Object.prototype返回的是类的全部实例成员,调用其中的toString方法,但是缺少实例对象,但是可以在调用时通过call指定实例对象
Object.prototype.toString.call(123) // '[object Number]'动态修改类的成员
function A(){}
A.prototype.x=1
const a1 = new A()
A.prototype.x=2
const a2 = new A()
// 修改了A.prototype指向对象的属性。两个实例访问的同一个对象,故都是2
console.log(a1.x,a2.x) // 2 2function A(){}
A.prototype.x=1
A.prototype.y=1
const a1 = new A()
A.prototype={x:2,y:3}
const a2 = new A()
// 修改了A.prototype指向的对象。两个实例访问的是不同对象,所以存在差异
console.log(a1.x,a1.y) // 1 1
console.log(a2.x,a2.y) // 2 3数组
声明数组
//方式一:对象的方式
const arr=new Array("A","B","C")
console.log(arr)//输出 ["A", "B", "C"]
//方式二:字面量方式(常用)
let arr=["A","B","C"]
console.log(arr)//输出 ["A", "B", "C"]多维数组(不常用)
let arr=["A",["B1","B2"],"C"]
console.log(arr[1][0]) //输出 B1注意:
let arr=["a"]
arr[3]="b"
console.log(arr)//输出 ["a", empty × 2, "b"]
//所以为了防止出现undefined,我们通常使用push,直接添加到队尾
//注意:empty的位置是个占位符,是包含在长度length之内的,但是for in循环时,是无法遍历的(直接跳过去)。for of和for(let i=0;i<arr.length;i++){ console.log(arr[i])}时可以遍历到,是undefined
delete arr[1]//输出 [ empty × 3, "b"],delete删除可以出现empty
//----分隔线----
let arr=new Array(6)
let arr2=Array.of(6)
console.log(arr)//创建一个长度为6的空数组
console.log(arr2)//输出 [6],即一个长度为一的数组,数组内容为6数组对象的属性和方法
数组属性
| 属性 | 描述 |
|---|---|
| constructor | 返回创建数组对象的原型函数。 |
| length | 设置或返回数组元素的个数。 |
| prototype | 允许你向数组对象添加属性或方法。 |
Array 对象方法
| 方法 | 描述 |
|---|---|
| 静态方法 | |
| isArray() | 判断对象是否为数组 |
| from() | 通过给定的对象中创建一个数组 |
| 操作数组元素——>增删 | |
| pop() | 删除数组的最后一个元素,返回删除的元素 |
| push() | 向数组的末尾添加一个或更多元素,返回新的长度 |
| shift() | 删除,返回数组的第一个元素 |
| unshift() | 向数组的开头添加一个或更多元素,返回新的长度 |
| splice() | 从数组中添加或删除元素,返回被删除的元素的组成的数组 |
| copyWithin() | 从数组的指定位置拷贝元素到数组的另一个指定位置中 |
| 操作数组元素——>顺序 | |
| reverse() | 反转数组的元素顺序,返回值也是反转后的数组 |
| sort() | 对数组的元素进行排序 |
| 不操作数组元素——>返回查找 | |
| includes() | 判断一个数组是否包含一个指定的值。 |
| indexOf() | 从前到后查找数组中的元素,返回它第一次出现位置的索引 |
| lastIndexOf() | 从后到前查找数组中的元素,返回它第一次出现位置的索引 |
| findIndex() | 返回符合传入函数条件的数组元素的索引 |
| find() | 返回符合传入函数条件的数组元素 |
| 不操作数组元素——>返回截取部分 | |
| slice() | 选取数组的一部分,并返回一个新数组 |
| 不操作数组元素——>返回拼接 | |
| join() | 把数组的所有元素放入一个字符串 |
| concat() | 连接两个或更多的数组,并返回结果 |
| 不操作数组元素——>遍历处理结果 | |
| filter() | 检测数值元素,并返回符合条件所有元素的数组 |
| map() | 通过指定函数处理数组的每个元素,并返回处理后的数组 |
| some() | 检测数组元素中是否有元素符合指定条件 |
| every() | 检测数值元素的每个元素是否都符合条件 |
| reduce() | 将数组元素计算为一个值(从左到右) |
| reduceRight() | 将数组元素计算为一个值(从右到左) |
| 其他 | |
| fill() | 使用一个固定值来填充数组 |
注意:js中数组的方法最为丰富,所以几乎所有类型都可以转化为数组进行处理,处理结束后再转化回去
补充下
数组方法中出现的index参数都是可正可负,为负数时,例如:-1代表倒数第一个元素,即索引为( length-1)
清空数组
let arr=["A","B","C"]
////
arr=[]
//清空原理,在内存中开辟一个新的空间,放一个空数组,把arr指向它。原来的数组并未清空
let new=arr
arr=[]
console,log(new)// ["A", "B", "C"]
////
arr.length=0
////
arr.splice(0,arr.length)
////
while(arr.pop())isArray
console.log(Array.isArray([]))//输出true
console.log([] instanceof Array)//输出truefrom
Array.from用来将可迭代对象转化为数组
内置的字符串、数组、对象都是可迭代对象,可以使用通用的方法遍历其内部。详见【可迭代对象】章节
如果观察过一些框架的内置对象的话,你会发现他们很少使用数组,而是使用一种类数组的对象
类数组的对象如下,这种对象key是索引,而且有一个length属性表示长度
let obj={
1:'jake',
0:'tom',
length:2
}我们可以把类数组的对象当成对象来处理,而需要使用数组方法时,又可以通过Array.from转化为数组
转化的数组长度就是length的数值,按照key的值作为索引放置
console.log(Array.from(obj)) // [ 'tom', 'jake' ]操作数组元素——>增删
略:pop、push、shift(队首出队)、unshift(队尾出队)
splice(index[,howmany][,item1,item2,...itemX)
替换指定位置的元素
参数:
- index 开始索引
- howmany 替换的元素个数,不传递默认为从index到数组最后一位
- item1....itemX 最后替换为这些值 (howmany给值,这些参数才能传递)
返回值:选取元素组成的数组(数组发生变化,是替换后的新数组)
let arr=["A","B","C","D"]
//删除
console.log(arr.splice(0,2))//["A", "B"]
console.log(arr)//["C", "D"]
//替换
console.log(arr.splice(0,2,"张三","李四"))//["A", "B"]
console.log(arr)//["张三", "李四", "C", "D"]
//增加
let arr3=["A","B","C","D"]
console.log(arr3.splice(1,0,"张三"))//[]
console.log(arr3)//["A", "张三", "B", "C", "D"]注意
[1].splice(2, 1, '*')copyWithin(target[, start, end])
将指定范围的元素复制后,覆盖到数组的其他位置(注意:复制的元素如果超出了数组长度,则只覆盖处在数组长度范围内的元素)
- 参数
- target 目标位置索引
- start 复制的开始位置索引
- end 复制的结束位置的下一位索引
- 返回值:覆盖后的结果(原数组发生变化和返回值相同)
//复制了b、c、d,到e的位置,b覆盖了e,剩下的c、d超出了数组范围
let arr=["a","b","c","d","e"]
console.log(arr.copyWithin(4,1,3))//[ 'a', 'b', 'c', 'd', 'b' ]
console.log(arr)//[ 'a', 'b', 'c', 'd', 'b' ]操作数组元素——>顺序
reverse()
原数组元素反转,返回值也是反转的数组
参数:无
返回值:前后反转的数组(原数组发生变化和返回值相同)
sort([function(preValue,nextValue)])
排序函数,数组元素排序,返回值也是排序后的数组
参数:排序规则函数
返回值:排序后的数组(原数组发生变化和返回值相同)
sort回调函数返回值
如果返回值小于 0,换位置
如果返回值大于等于 0,位置不变
let arr=[1,8,3,4]
arr.sort((a,b)=>{ //第一轮,a=8,b=1
return b-a //从大到小
return a-b //从小到大
})
//arr是 [ 8, 4, 3, 1 ]简写
let arr=[1,2,3,4]
arr.sort(function(a,b){
//a-b 从小到大 ; b-a 从大到小
return b-a
})
console.log(arr) //输出[4,3, 2, 1]**例子:**商品价格排序
let cart=[
{name:"ipad",price:5000},
{name:"imac",price:20000},
{name:"iphone",price:8000},
{name:"makbook",price:10000},
]
cart.sort(function(a,b){
return a.price-b.price
})
console.log(cart) //输出对象按从小到大排列sort原理
//sort是冒泡排序
function Mysort(array,callback){
for(const n in array){
for(const m in array){
if(callback(array[n],array[m])<0){//callback的返回值是小于0时,交换位置
const temp=array[n]
array[n]=array[m]
array[m]=temp
}
}
}
}
let arr=[1,2,3,4]
Mysort(arr,function(a,b){
return a-b
})
console.log(arr)// 输出[1, 2, 3, 4]不操作数组元素——>返回查找
includes(item[,index])
从index开始,从前到后,查找数组中是否有item这个元素
- 参数:
- item 目标查找元素
- index 查找开始位置索引
- 返回值:布尔值
console.log(arr.includes("a"))//输出true
console.log(arr.includes("a",3))//输出false,从标号为3的位置向右查找indexOf(item[,index])
在数组中查找item,首次出现位置的索引
参数:
- item要查找的元素
- index:从index位置开始查找
返回值:
找到返回元素所在索引,找不到返回-1
let arr=["a","d","a","d"]
console.log(arr.indexOf("a")) //输出0,从左->右查找,找到第一次出现位置的标号,找不到返回-1
console.log(arr.indexOf("a",2)) //第二个参数从角标为2的位置,向右查找lastIndexOf(item[,index])
从index位置(默认是数组最后一位),从后向前在数组中查找item,首次出现位置的索引(与indexOf类似)
index的取值范围可正可负
find(function(currentValue[, index,arr])[,thisValue])
参数
- function(currentValue[, index,arr])
- thisValue
返回值
function一旦返回true,就返回数组中对应的元素,不再查找了;如果结束都没有返回true,则返回undefined
let arr=[{name:'a',age:18},{name:'b',age:19}]
let res=arr.find((item)=>{
return item.name==='a'
})
console.log(res) //{ name: 'a', age: 18 }**findIndex(function(currentValue[, index,arr]),[thisValue]) **
返回查找到值的索引,找不到返回-1(与find类似)
试一试
自己实现类似find的查找函数
function findValue(array,callback){
for(const value of array){
if(callback(value)) return value
}
return undefined
}
let arr=["a","d","a","d"]
let res=findValue(arr,(item)=>{
return item=="d"
})
console.log(res) //输出d不操作数组元素——>返回截取部分
slice([start,end])
参数:
start,开始截取的索引 ,范围可正可负
end,结束截取元素的下一个索引,范围可正可负
(左闭,右开区间)
返回值:
返回被截取元素组成的数组
let arr=["A","B","C","D"]
console.log(arr.slice())//输出["A", "B", "C", "D"],无参数截取所有
console.log(arr.slice(1))//输出["B", "C", "D"],截取标号1到最后
console.log(arr.slice(1,3))//输出["B", "C"],截取:索引1——索引2
// 二个参数都可以为负数,是一个很实用的能力,可以实现按倒数位置截取
console.log(arr.slice(0,-2)) // 其实就是[0,len-2) 即["A","B"]不操作数组元素——>返回拼接
join
let arr=["a","b","c"]
console.log(arr.join("-")) //输出a-b-c补充:字符串拆分成数组
let str="abcdef"
console.log(Array.split())//输出["a", "b", "c", "d", "e", "f"]concat
array1.concat(array2,array3,...,arrayX)
let arr2=["e","f","g"]
//方法二,原数组未改变
console.log(arr.concat(arr2))
//方法三,原数组未改变
console.log([..arr,...arr2]不操作数组元素——>遍历处理结果
filter
检测数值元素,函数返回一个数组。是:当内部函数返回为true时的元素组成的数组。找不到返回空数组
let arr=["a","b","c"]
let res=arr.filter(function(value,index,arr){
//value是数组元素
//index是索引
//arr是原数组
//把所有元素都遍历一遍,函数返回所有return为true的数组元素
if(value=="b") return true
})
console.log(res)//输出["b"]例子
//简单写法,
let arr=[12,5,6,3,9,7]
let result=arr.filter(item=>{
return item%3==0//这个表达式本来就是布尔值,可以直接return
})
console.log(result)又一个例子
//
let arr=[
{name:"帽子",price:50},
{name:"外套",price:150},
{name:"鞋子",price:500},
{name:"袜子",price:2},
]
let result=arr.filter(item=>{
return item.price>100
})
console.log(result)
//输出
[{name: "外套", price: 150},
{name: "鞋子", price: 500}]filter实现原理
function Myfilter(array,callback){
let newArray=[]
for(const value of array){
if(callback(value)===true){
newArray.push(value)
}
}
return newArray
}
let arr=[60,50,70,80,100]
let res=Myfilter(arr,function(item){
return item>=60
})
console.log(res) //输出[60, 70, 80, 100]map
映射。内部函数返回的值组成的数组
let arr=[1,8,3,4]
let res=arr.map((item)=>{
return {id:item}
})
console.log('res --> ',res) //res --> [ { id: 1 }, { id: 8 }, { id: 3 }, { id: 4 } ]every
检测数值元素的每个元素是否都符合条件。内部函数所有元素都返回true,最后才返回true。如果有一个返回了false,就不会继续向后遍历了,直接返回false
let arr=["a","b","c"]
arr.every((value,index,arr)=>{
//value是数组元素
//index是索引
//arr是原数组
//函数必须返回布尔值,true,才能继续,否则停止
console.log(value)
return true
})
//输出a b c应用
//判断是否有人未及格
let arr=[
{name:"张三",score:80},
{name:"李四",score:50},
{name:"王五",score:70},
{name:"赵六",score:90},
]
let res=arr.every(function(item){
return item.score>=60
})
console.log(res?"全部及格":"有人未及格")
//输出 有人未及格some
检测数组元素中是否有元素符合指定条件。如果return true,结束函数,整体返回true;如果整个数组遍历完都没有return true,整体返回false
let arr=["a","b","c"]
let res=arr.some((value,index,arr)=>{
//value是数组元素
//index是索引
//arr是原数组
//函数必须返回布尔值,true就结束
if(value==="a"){
return true
}
})
console.log(res) //truereduce(function(preValue, currentValue[, currentIndex, arr]), [initialValue])
数组中的每个值(从左到右)开始遍历,最终计算为一个值
参数:
- preValue 是上一次循环return的值
- currentValue 本轮循环的数组的元素
- currentIndex 本轮循环数组元素的索引
- arr调用reduce方法的数组
返回值:最后一轮return的值
reduce只有第一个参数(函数)时,第一轮循环preValue为数组第一个元素,currentValue为第二个元素
let arr=[1,2,3,4]
let res=arr.reduce(function(pre,value,index,array){
console.log(pre,value)
return 99
})
//输出
//1 2
//99 3
//99 4
console.log(res) //99reduce有第2个参数时,第二个参数是指定第一轮preValue的初始值,currentValue从数组的第一个元素开始
let arr=[1,2,3,4]
arr.reduce(function(pre,value,index,array){
console.log(pre,value)
return 99
},0)//reduce的第二个参数,是给第一给参数中的pre赋值
//输出
//0 1
//99 2
//99 3
//99 4
console.log(res) //99应用场景1
//统计item在array数组中出现了几次
function arrayCount(array,item){
return array.reduce(function(pre,cur){
if(cur==item)
pre=pre+1
return pre
},0)
}
let arr=[1,2,1,3,4,1]
console.log(arrayCount(arr,1))//输出3,返回了pre最终的值应用场景2
//找最大值
let arr=[6,2,9,4]
let res=arr.reduce(function(pre,cur){
return cur>pre?cur:pre
})
console.log(res)应用场景3
//求总和
let arr=[1,5,3,8,6]
let res=arr.reduce(function(pre,cur){
return pre= pre+cur
})
console.log(res)
//输出23reduceRight
与reduce一样,只不过方向是从右向左
字符串
JS 中字符串本质是一个可迭代对象(iterable),并且它的迭代行为是按 Unicode 码点进行的
长度
- 每一个字符对应一个 Unicode 码点,JS 使用 utf-16编码存储
- length 很坑,返回的是并不是字符个数,而是码元个数 。有些字符是多个码元构成的,例如:
"😄".length=2 - 不过 JS 是个可迭代对象(for 循环),可以用
Array.from("😄").length=1,把迭代器转化为数组
方法
静态方法
| 方法 | 描述 |
|---|---|
| fromCharCode() | 将 Unicode 编码转为字符 |
方法
| 方法 | 描述 |
|---|---|
| 不操作字符串 | |
| toLowerCase() | 把字符串转换为小写 |
| toUpperCase() | 把字符串转换为大写 |
| trim() | 去除字符串两边的空白 |
| 不操作字符串——>判断字符串是否符合 | |
| charAt() | 返回在指定位置的字符。 |
| charCodeAt() | 返回在指定的位置的字符的 Unicode 编码。 |
| startsWith() | 查看字符串是否以指定的子字符串开头。 |
| endsWith() | 判断当前字符串是否是以指定的子字符串结尾的(区分大小写)。 |
| 不操作字符串——>返回查找 | |
| includes() | 查找字符串中是否包含指定的子字符串。 |
| indexOf() | 返回某个指定的字符串值在字符串中首次出现的位置。 |
| lastIndexOf() | 从后向前搜索字符串,并从起始位置(0)开始计算返回字符串最后出现的位置。 |
| 不操作字符串——>返回截取部分 | |
| slice() | 提取字符串的片断,并在新的字符串中返回被提取的部分。 |
| substring() | 提取字符串中两个指定的索引号之间的字符。 |
| 不操作字符串——>返回截拼接/分割 | |
| concat() | 连接两个或更多字符串,并返回新的字符串。 |
| repeat() | 复制字符串指定次数,并将它们连接在一起返回。 |
| split() | 把字符串分割为字符串数组。 |
| 正则匹配 | |
| match() | 查找找到一个或多个正则表达式的匹配。 |
| replace() | 在字符串中查找匹配的子串,并替换与正则表达式匹配的子串。 |
| replaceAll() | 在字符串中查找匹配的子串,并替换与正则表达式匹配的所有子串。 |
| search() | 查找与正则表达式相匹配的值。 |
正则相关的方法详见【正则对象】章节
数组与字符串对比
数组和字符串有很多方法十分相似,这里整理下
| 相同的方法 | 描述 |
|---|---|
| includes() | 判断一个数组/字符串是否包含一个指定的值 |
| indexOf() | 从前到后查找数组/字符串中的元素,返回它第一次出现位置的索引 |
| lastIndexOf() | 从后到前查找数组/字符串中的元素,返回它第一次出现位置的索引 |
| slice() | 截取数组/字符串 |
| concat() | 拼接数组/字符串 |
展开语法
收集不定个数的参数,放入数组中
应用在函数参数中
jsfunction show(a,b,...args){//...args只能放在最后,接收剩余变量 console.log(a,b,...args)//输出 1 2 3 4 5 6 console.log(args)//输出 [3, 4, 5, 6],注意这里是把接受的参数放入数组中 } //相当于 show(1,2,3,4,5,6)// 1给a,2给b,剩余的3,4,5,6被放到...args中 ,args是[3,4,5,6]应用在结构赋值中 【结构赋值】中会讲到
jslet [first,...second] = ['a','b','c']; //first是a,second是['b','c']
展开语法,可以将任何可迭代对象展开(把外层不管是**[]、{},“ ”**,Set,Map全部脱掉脱掉!)
例子:展开数组
//1. 展开数组,用数组接收
let arr=[1,2,3,4]
[...arr]//
//2. 展开多个数组,用数组接收(合并效果)
arr=["h","e","r"]
arr2=["q","w","e"]
arr3=[...arr,...arr2]
console.log(arr3)//输出 ["h", "e", "r", "q", "w", "e"]例子展开对象
// 展开多个对象,用对象接收(合并效果)
var obj1 = {name:'hehe'}
var obj2 = {age:20}
var mergeObj = {...obj1,...obj2}
console.log(mergeObj)//输出{name: "hehe", age: 20}Set
集合类型,Set的特点是无序、自动去重
Set声明
创建空集合
let set=new Set()接收可迭代对象,转化为集合
let set1=new Set([1,2,1,3])
let set2=new Set("abcd")Set 操作
- add
- delete 删除指定元素,删除成功返回true,若不存在,返回false
- size 返回元素个数
- has 判读是否存在指定元素,存在返回true,否则返回false
- clear() 清空数组,无返回值
let s1=new Set([1,2,1,3])
s1.add(4)
console.log(s1.size) //4
console.log(s1.has(2)) //true
console.log(s1.delete(1))//true
s1.clear()类型转换 Set<-->Array
// Set-->Array
let set=new Set(["a","b","c"])
console.log(Array.from(set))
console.log([...set])
// Set<--Array
arr=[1,2,3]
let set=new Set(arr)
consle.log(set) //输出 Set(3) {1, 2, 3}应用
取出set中小于3的,把set转为array,处理完,转会set类型
let set =new Set("123456")
let set2=new Set([...set].filter(item=>{
return item<=3
}))
console.log(set2)//输出 Set(3) {"1", "2", "3"}数组去重
let arr=[1,2,3,4,1,4]
let arr2=[...new Set(arr)]
console.log(arr2) //输出 [1, 2, 3, 4]并集 交集 差集的实现
let a=new Set(["a","b","c"])
let b=new Set(["b","c","d"])
//并集
console.log(new Set([...a,...b]))//输出 Set(4) {"a", "b", "c", "d"}
//a-b差集
let res=new Set([...a].filter(item=>![...b].includes(item)))
console.log(res)//输出Set(1) {"a"}
//交集
let res2=new Set([...a].filter(item=>[...b].includes(item)))
console.log(res2)//输出 Set(2) {"b", "c"}WeakSet
WeakSet和Set不同的是,WeakSet的键必须是引用类型。
- add()
let set=new Set(["a","b"])
set.add(["c","d"])
console.log(set) //{"a", "b", Array(2)}weakSet的弱引用特性
let a={name:"张三"}
let b=a //在这里b和a指向的是同一块内存地址。这个对象有一个引用计数器,现在值为2
let c=new weakSet()
c.add(a)//并不会让引用计数器加1,这就是弱引用
a=null
b=null//当两个变量都不引用了,对象的引用计数器为0,会被垃圾回收期回收。
//注意:这时候WeakSet还在引用这个对象,只不过现在对象为null,WeakSet有可能因为别的操作变成null,因此WeakSet没有size,遍历等方法,以防止出错Map
Map的声明
键名可以是字符串,函数,对象,数值
let map=new Map()
let map=new Map([["a",1],["b",2],["c",3]])
console.log(map)
//输出 Map(3) {"a" => 1, "b" => 2, "c" => 3}且键名唯一,同名后面的覆盖前面的
let m=new Map([["a",1],["a",2]])
console.log(m)
//输出 Map(1) {"a" => 2}Map操作
- set()
- get() 通过key查找value,不存在的key返回undefined
- delete() 删除成功返回true,若map中没有要删除的键名,则返回false
- has() 若键名存在,返回true,否则返回false
- clear() 清空map,没有返回值
let map=new Map()
map.set("a",1)
map.set("b",2)
console.log(map.get("b"))//输出2
console.log(map.delete("b"))//输出true
console.log(map)//输出 Map(1) {"a" => 1}
console.log(map.has("a"))//输出true
map.clear()
console.log(map)//Map(0) {}类型转换Map<-->Array
//Map-->Array
let map=new Map([["张三",60],["李四",70],["王五",30]])
console.log([...map])
//输出 [["张三", 60],["李四", 70],["王五", 30]],注意:这个输出的是一个数组,数组元素也是数组
console.log([...map.entries()])//输出[["张三", 60],["李四", 70],["王五", 30]]
//所有键转化为数组
console.log([...map.keys()])//输出 ["张三", "李四", "王五"]
//所有值转化为数组
console.log([...map.values()])//输出 [60, 70, 30]
//Array-->Map
//这种声明方式就是用Array转化为Map
let map=new Map([["张三",60],["李四",70],["王五",30]])
console.log(map)
//输出 Map(3) {"张三" => 60, "李四" => 70, "王五" => 30}
////注意:Array必须符合Map的格式才能转换为Map
new Map([["张三",60]]) //符合
new Map(["张三",60]) //不符合,报错
let arr=[["张三",60,"男"],["李四",60,"女"]]
console.log(new Map(arr))//不符合,但是可以用 输出 Map(2) {"张三" => 60, "李四" => 60} //张三作为key,60作为值,剩下的"男"被略掉了应用,map转化为array,完成指定功能后,转换回map
//map中筛选出来成绩大于等于60
let map=new Map([["张三",60,],["李四",30],["王五",80]])
let newArray=[]
for(const value of [...map]){
//console.log(value)
if(value[1]>=60)
newArray.push(value)
}
console.log(newArray)//输出 ["张三", 60] ["王五", 80]WakMap
如果key是对象,将key的引用置为null。map仍然持有引用
var a = {};
var map = new Map();
map.set(a, '测试value')
a = null;
console.log(map.keys()) // MapIterator {{}}
console.log(map.values()) // MapIterator {"测试value"}WeakMap解决了这个问题
解构赋值
基础用法
结构赋值:等号后侧可以是任何可迭代对象解构,赋值给新的变量
解构数组
//1. 只赋值部分变量:逗号分隔,留下空白,可以跳过不想接收的数据
let [first,,third] = ['a','b','c']; //first是a,second是b
//2. 只赋值部分变量:后续不用接收,可以不写
let [first] = ['a','b','c']; //first是a
//3. 使用展开语法获取多个值
let [first,...second] = ['a','b','c']; //first是a,second是['b','c']解构字符串
let [a, b, c] = "abc"; // ["a", "b", "c"]解构Set
let [one, two, three] = new Set([1, 2, 3]);解构Map
let [one, two, three] = new Map([1, 2, 3]);设置默认值
为变量设置默认值
const user={
password:'xxx',
name:'tom',
age:18
}
let { score=100 }= user
console.log(score); //默认值函数参数解构
可以实现命名参数的效果
function func({name="jack",age=18,habit,score,classNum}){
}
func({name:"tom",score:100})剔除属性
用户信息中剔除秘密属性
const user={
password:'xxx',
name:'tom',
age:18
}
const {password,...other}=user
console.log(other) // {name: 'tom', age: 18}遍历
forEach遍历
数组、Set、Map支持使用forEach遍历
forEach(function(item[,index,arr]))
- 参数
- item 每一项数组元素
- index 索引
- 调用forEach方法的类型
- 返回值
let arr=["a","b","c","d"]
arr.forEach(function(item,index,arr){
console.log(item,index)
})
//输出
//a 0
//b 1
//c 2
//d 3
let set=new Set(["a","b","c"])
set.forEach(function(value,key,set){
//key和value一样,都是set内元素,set是调用forEach的
console.log(value,key)
})
let map=new Map()
map.set("a",1)
map.set("b",2)
map.forEach(function(value,key,map){
console.log(value,key)
});
//输出
//1 "a"
//2 "b"for key in遍历
遍历数组的key,key就是索引
let arr=["n","m","d"]
for(key in arr){
console.log(key)
}
//输出0 1 2遍历对象的key
let stu={
name:"jack",
age:18,
score:20
}
for(let key in stu){
console.log(key)
}
// name
// age
// scorefor value of遍历可迭代对象
可迭代对象的遍历
数组、字符串、内置的对象、Set、Map都是可迭代对象(Iterable),可迭代对象均可以使用for value of遍历
注意:我们自己创建的对象不是可迭代对象,需要自己实现Symbol.iterator属性(后面会有详细介绍实现过程),但是内置的对象,都默认实现了,所以可以迭代
例如:遍历数组的value
//值类型不可改变
let arr=[1,2,3,4,5]
for(let value of arr){
value=value+10
}
console.log(arr) //输出 1 2 3 4 5什么是可迭代对象的
通过自己实现一个可迭代对象来学习,我们给对象添加for value of(对象不是可迭代对象)
当
for..of循环时,会调用Symbol.iterator方法(如果没找到,就会报错)。这个方法返回一个 迭代器对象(iterator)迭代器对象中,必须有一个
next()方法,其返回的结果的格式必须是{done: Boolean, value: any}- 当
done=true时,表示循环结束 - 当
done=false时,表示还有下一个元素,会再次返回下一个迭代器对象,value就是这次的数据
- 当
for..of循环会自动判断done的值,遍历整个可迭代对象
let stu={
name:"jack",
age:18,
score:20
}
stu[Symbol.iterator]= function (){
return{
entriesList:Object.entries(this), //this指向stu对象
curIndex:0,
next(){
if(this.curIndex+1<=this.entriesList.length){
let res={done:false,value:this.entriesList[this.curIndex][1]}//this指向当前这个对象中
this.curIndex++
return res
}else{
return {done:true,value:null}
}
}
}
}
for(let value of stu){
console.log(value)
}
//jack
//18
//20获取可迭代对象
我们也可以获取迭代器对象后,手动调用next方法
let str = "Hello";
let iterator = str[Symbol.iterator](); //获取带了可迭代对象
while (true) {
let result = iterator.next(); //其中的next方法
if (result.done) break;
console.log(result.value); // 一个接一个地输出字符
}获取迭代器
数组、Set、Map都有这三个方法,通过这三种方式获取可迭代对象
keys( )
参数:无
返回值:可迭代对象
**values( ) **
参数:无
返回值:可迭代对象
entries( )
参数:无
返回值:可迭代对象
数组
let arr=["a","b","c"]
//所有键
console.log(arr.keys())//输出 Object [Array Iterator] {}
//所有值
console.log(arr.values())//输出 Object [Array Iterator] {}
//所有键和值
console.log(arr.entries())//输出 Object [Array Iterator] {}
//遍历所有键
for(const value of arr.keys()){
console.log(value)
}//输出0 1 2
//遍历所有值
for(const value of arr.values()){
console.log(value)
}//输出a b c
//遍历所有键和值,[key,value]是解构
for(const [key,value] of arr.entries()){
console.log(key,value)
}
// 0 a
// 1 b
// 2 cSet
set没有键,但是为了使迭代器对所有类型统一,所以让set的键和值一样,都是set内的元素
let set=new Set(["a","b","c"])
//所有键
console.log(set.keys())//输出 SetIterator {"a", "b", "c"}
//所有值
console.log(set.values())//输出 SetIterator {"a", "b", "c"}
//所有键和值
console.log(set.entries())//输出 SetIterator {"a" => "a", "b" => "b", "c" => "c"}
//直接遍历
for (const value of set) {
console.log(value);
}//输出a b c
//遍历所有键
for(const value of set.keys()){
console.log(value)
}//输出a b c
//遍历所有值
for(const value of set.values()){
console.log(value)
}//输出a b c
//遍历所有键和值,[value,key]是解构
for(const [value,key] of set.entries()){
console.log(value)
console.log(key)
}Map
let map=new Map()
map.set("a",1)
map.set("b",2)
//所有值
console.log(map.values())//输出 MapIterator {1, 2}
//所有键
console.log(map.keys())//输出 MapIterator {"a", "b"}
//所有键和值
console.log(map.entries())//输出 MapIterator {"a" => 1, "b" => 2}
// 直接遍历
for(const value of map){
console.log(value)
}//输出[a,1] [b,2]
//遍历值
for(const value of map.values()){
console.log(value)
}//输出1 2
//遍历key
for(const key of map.keys()){
console.log(key)
}//输出a b
//遍历值和键,[key,value]用了解构
for(const [key,value] of map.entries()){
console.log(key)
console.log(value)
}//输出 a 1 b 2
//也可直接遍历
for(let [key,value] of m){
console.log(key,value)
}this的指向
this指向规则
对于普通函数
1、this指向调用者(调用链从右向左找到第一个调用者,如果是对象this指向这个对象,如果是函数this指向window)
js//(函数b由函数a调用,函数a由对象obj调用) function b(){ console.log(this) } function a(){ b() } const obj={ a } obj.a() //window2、call、apply、bind会改变普通函数的this指向
对应箭头函数
this指向箭头函数所在的作用域。箭头函数的难点在于:其作用域的this可能还要沿着调用链找,才能找到
jsfunction xx(){ //作用域 } if(){ //作用域 } for(){ //作用域 } while(){ //作用域 }注意,对象也是花括号,但是其内部不是作用域
jsconst obj={ }
补充实际场景
this指向的规则只有上面两点,但是实际场景非常复杂,这部分是用来补充实际场景下this指向如何判断
下面函数实际是挂在了window上
jsfunction f1(){ console.log(this) } f1() //指向window //f1实际是挂在了window上。f1的最终调用者是window window.f1()this在入参的函数中。注意:f1的入参是对象,但是这个对象不是一定是最终调用者
jsfunction f1(params){ params.callback1() // this指向params对象。(调用关系:callback1<=params对象 ) params.callback2() params.action.getInfo()//this指向action对象。(调用关系:getInfo<=action对象<=params对象 ) } f1({ name:'tom', age:20, callback1(){ //普通函数this取决于谁调用了函数callback1 console.log(1,this) }, callback2:()=>{ //箭头函数this指向,其自身函数所在上下文中的this //this指向window。箭头函数的指向不必关心函数f1内部如何调用, //只需看到,这里入参对象{},不是作用域,需要继续向上找,callback2所在作用域=调用f1的函数作用域,所以这里的this是指向window的 console.log(2,this) }, action:{ getInfo(){ //普通函数this取决于谁调用了函数callback1 console.log(3,this) } } })完整的例子
jsfunction Page(params) { // 解构出来的onLoad,调用者应该是window,但是下面使用了call改变了调用者 const { onLoad } = params; if (onLoad instanceof Function) { //onLoad的this取决于谁调用了Page。后面可以看到Page是直接调用的,this指向window //call强制指定this为{name:'jack'} onLoad.call({name:'jack'}) } } function test(params) { const { success, fail } = params; if (success) { success({ msg: "success" }); } if (fail instanceof Function) { fail(); } } //Page是直接调用的 Page({ onLoad() { //call绑定了{name:'jack'},当前块级作用域this就是{name:'jack'} console.log('1',this) //{name:'jack'} test({ name: "tom", //注意下面是简写,实际是=》success:function(){ xxx } success() { console.log('2',this); //window。success是test调用的,test是函数,this指向window }, fail:()=> { console.log('2',this); //{name:'jack'} 。test所在作用域this是{name:'jack'} }, }); }, });构造函数
这个需要特殊记忆,前面学过构造函数会创造新的对象,this就指向这个新对象
定时器
定时器函数比较特殊,他会把函数内部的this重写为window【在node环境下,会重写成 Timer对象】
jsfunction f(){ console.log(this) } setTimeout(f,100) //【规则5】window解构对象
例子中解构出来的函数getThis的最终调用者是window
jslet obj={ getThis(){ console.log(this) } } const {getThis}=obj getThis() //window因为函数getThis直接被window调用了,箭头函数的当前作用域就是window
jslet obj={ getThis:()=>{ console.log(this) } } const {getThis}=obj getThis() //window将函数地址存在新的变量里,调用变量
注意:lesson.show并没有调用函数
jslet lesson={ show:function(){ console.log(this) } } lesson.show() //对象lesson newVar = lesson.show //这里并没有调用函数 newVar()//window #这里比较特殊,这里理解为newVar()被挂在window上了jslet lesson={ show:function(){ console.log(this) } } function fn(callback) { callback() // fn是函数的调用者,所以指向window } fn(lesson.show) //window下一节介绍bind、call、apply来绑定this的指向
jslet lesson={ show:function(){ console.log(this) } } //固定this指向了lesson lesson.show=lesson.show.bind(lesson) function fn(callback) { callback() } fn(lesson.show) // lesson对象监听器回调函数一般都用bind,或者箭头函数
js// 如果不用bind,myListener使用this就会受到addEventListener内部实现的影响 // 用bind可以让我们的myListener函数操作指定的上下文 // hash路由 class Route{ constructor(){ // 监听器函数freshRoute内部的this指向由addEventListener内部如何调用的相关,我们是没法控制的,而且funtion形式this要么指向window,要么执行调用它的对象,肯定不会指向Route实例 // 可是class中函数又没箭头函数的形式,所以为了保证监听器函数freshRoute内部的this能一直访问实例,需要用bind绑定。 // 为啥赋值给一个属性? 因为bind每次执行返回的都是新函数,增加、移除监听器必须都是同一个函数。赋值给属性新增、移除就能用一个函数了 this.freshRoute = this.freshRoute.bind(this) } addListener(){ window.addEventListener('hashchange', this.freshRoute) } removeListener(){ window.removeEventListener('hashchange', this.freshRoute) } // 更新 freshRoute () { this.currentHash = location.hash.slice(1) || '/' this.routes[this.currentHash]() } }Object的实例方法使用call、bind绑定对象。这个原因解释在 【对象】-【静态方法、实例方法】
简单来说就是Object.prototype可以访问到实例对象的成员,但是没有实例对象
JS中可以通过call给实例方法绑定对象
jsObject.prototype.hasOwnProperty.call(obj,'name') Object.prototype.toString.call(obj)闭包中的this
js// function形式 function createRequest(){ return function (){ console.log(this) return '' } } // 箭头函数形式 function createRequest(){ return ()=>{ console.log(this) return '' } } // 调用方式1: createRequest() // 返回的是内部return的函数 // 调用方式2: createRequest()() // 或 const util=createRequest() util() // 都是使用箭头函数指向window,使用function指向createRequest内部的this指向 // 调用方式2的例子 const obj={name:'tom'} const util=createRequest().call(obj)// 使用箭头函数指向window,使用function指向 obj
call apply bind
用于设置普通函数中的this的指向
构造函数中this,this指向的是本身,是空白的。new新的对象后,传入参数那么,对象内部才有的name: "张三"
function User(name) {
this.name=name
}
let res=new User("张三")
console.log(res) //输出 User {name: "张三"}call
call的第一个参数:初始User对象,放入到第一个参数对象之中;
call中剩下的参数给了User对象中的参数赋值。
注意:这里this已经指向obj,name的赋值操作,其实把”张三“,放到了obj之中,最后改变了obj的值
function User(name){
this.name=name
}
let obj={age:20}
User.call(obj,"张三")//call和apply都是立即执行User函数,这时候this指向obj
console.log(obj)//输出 {age: 20, name: "张三"}call与apply区别
相同点:两个都是立即执行
不同点:传递函数参数时,apply需要把所有的参数放到数组中
let lisi={
name:"李四"
}
function User(age,score){
console.log(this.name,age,score)
}
//注意看这里,call和apply立即执行,其中的this已经指向了lishi这个对象
User.call(lisi,18,100) //李四 18 100
User.apply(lisi,[18,100]) //李四 18 100bind
bind与call,apply的不同是,bind不能立即执行
function show(age,score){
console.log(this.name,age,score)
}
//使用call
show.call({name:"张三"},20,99)//输出 张三 20 99
//使用apply
show.apply({name:"张三"},[21,80])//输出 张三 21 80
//----重点开始----
//使用bind,返回值是show函数,所以在后面加()才能组成立即执行函数
console.log(show.bind({name:"张三"},19))
//输出
//ƒ show(age,score){
// console.log(this.name,age,score)
//}
////可以直接传参数
let res=show.bind({name:"张三"},19,95)
res()//输出 张三 19 95
////可以调用时传参数
let res=show.bind({name:"张三"})
res(19,95)//输出 张三 19 95gh
////假如同时传参,以使用bind是传的参数优先
let res=show.bind({name:"张三"},19,95)
res(20,100)//输出 张三 19 95
let res=show.bind({name:"张三"},19)
res(20,100)//输出 张三 19 20,res调用时的20,自动略去了应用
其实,最主要的应用分为两种场景:this指向当前上下文、指向使用上下文
以小程序为例子
封装了工具函数handlerXXX
import handlerXXX from 'xxx.js'
Page({
onLoad(){
// 函数中的this指向函数内部
handlerXXX()
// 函数中的this指向当前页面
handlerXXX.call(this)
}
})Math对象
只介绍下,Math常用的(静态)方法
| 函数 | 描述 |
|---|---|
| abs(x) | 返回 x 的绝对值 |
| ceil(x) | 向上取整 |
| floor(x) | 向下取整 |
| max(x,y,z,...,n) | 返回 x,y,z,...,n 中的最高值 |
| min(x,y,z,...,n) | 返回 x,y,z,...,n中的最低值 |
| random() | 返回 0 ~ 1 之间的随机数 |
| round(x) | 四舍五入,保留整数 |
| sqrt(x) | 返回数的平方根 |
| pow(x,y) | 返回 x 的 y 次幂 |
传入的参数会通过Number转化为数字后在运算,如果参数中有被转化为NaN的,则返回NaN
Date对象
Date对象
创建Date对象,返回的都是当地时区的时间对象
无参数
jsvar today = new Date() //获取设备当前的时间参数是时间戳
jsvar today = new Date(1681975460517)参数是年月日时分秒毫秒
jsnew Date(year, monthIndex [, day [, hours [, minutes [, seconds [, milliseconds]]]]]); //注意: //1. year, monthInde两个参数必传的。如果只传入一个数,会被当成时间戳 //2. 其中monthIndex=0,表示的是1月,11为12月jsnew Date(2022,0) //Sat Jan 01 2022 00:00:00 GMT+0800 (中国标准时间)参数是日期字符串
即将日期字符串转换为时间对象
jsnew Date(dateString); // 入参格式建议为(年份为4位,其他必须为两位): //'yyyy-mm-dd HH:MM:SS' 、 'yyyy/mm/dd HH:MM:SS' //'yyyy-mm-dd' 、 'yyyy/mm/dd' //注意: //1. 当你使用字符串这个形式的时候, 1 表示 1 月, 12 表示 12 月 //2. 年月日与时分秒中间有一个空格js// 注意:巨坑,Date格式化 年月日,返回的时间不是当天的0点,而是当天的8点 new Date("2022-01-20") //Thu Jan 20 2022 08:00:00 GMT+0800 (中国标准时间) new Date("2022-01-20 14:30:00") //Thu Jan 20 2022 14:30:00 GMT+0800 (中国标准时间) new Date("2022/01/20 14:30:00") //Thu Jan 20 2022 14:30:00 GMT+0800 (中国标准时间)
Date对象的运算
function getDates(startDate, endDate) {
const dates = [];
const currentDate = new Date(startDate);
//可比较大小
while (currentDate <= endDate) {
dates.push(new Date(currentDate));
currentDate.setDate(currentDate.getDate() + 1);
}
return dates;
}
// 示例用法
const startDate = new Date('2023-01-01');
const endDate = new Date('2023-01-10');
const dates = getDates(startDate, endDate);
dates.forEach(date => console.log(date.toISOString().split('T')[0]));Date对象的方法
| Data对象的方法 | 描述 |
|---|---|
| getDay() | 返回Date对象的是星期几(0~6,0是星期日) |
| getFullYear() | 返回Date对象的年份(四位数,例如2022) |
| getMonth() | 返回Date对象的月份 (0 ~ 11,0指的是1月,之后类推) |
| getDate() | 返回Date对象的日 |
| getHours() | 返回Date对象的小时 (0 ~ 23) |
| getMinutes() | 返回 Date 对象的分钟 (0 ~ 59) |
| getSeconds() | 返回 Date 对象的秒数 (0 ~ 59) |
| getMilliseconds() | 返回 Date 对象的毫秒(0 ~ 999) |
| 时间戳 | |
| getTime() | 返回 1970 年 1 月 1 日至今的毫秒数(时间戳) |
时间戳
一共有3种方式
new Date().getTime()
new Date()*1Date.now()//直接用Date对象,返回当前时间的时间戳(毫秒)实践
注:两个时间对象比较,一般都是使用时间戳
计算两个日期相差的天数
let now=new Date()
let end=new Date().setFullYear(2050,11,22)//月份是从0开始的,这里是12月22日。这里end是时间戳
let res=(end-now)/ (1*24*60*60*1000)
console.log("距离时间",res)//打印当前时间到2020-11-22的天数计算今天是指定的某一天
通常的思路是分别获取两个时间的年、月、日,然后分别比较,都是一样的就是同一天
其实这个也可以用时间戳
function isToday(dataStr){
todayDateStamp=new Date().setHours(0,0,0,0) //返回的是当天0时0分0秒0毫秒(参数分别是 时、分、秒、毫秒,必须都写0)
if(new Date(dataStr).setHours(0,0,0,0)===todayDateStamp){
console.log("同一天")
return true
}
return false
}
isToday('2022-08-03')格式化时间 :由于JS中没有提供相关的功能,所以需要自己实现
//格式化时间的函数
let date=new Date()
function dateFormat(date,format='YYYY-MM-DD HH:mm:SS'){
const config={
YYYY:date.getFullYear(),
MM:date.getMonth()+1,
DD:date.getDate(),
HH:date.getHours(),
mm:date.getMinutes(),
SS:date.getSeconds()
};
for(const key in config){
format=format.replace(key,config[key])
}
return format
}
console.log(dateFormat(date,"YYYY年-MM月-DD日"))//输出 2020年-5月-11日正则对象
正则对象介绍
构造函数方式:
var patt=new RegExp(pattern,modifiers)字面量方式:
var patt=/pattern/modifiers;注意:
pattern是正则表达式串modifiers是修饰符,用于指定全局匹配、区分大小写的匹配和多行匹配等规则修饰符可以连用,比如
/xxxx/gmi修饰符 描述 i 执行对大小写不敏感的匹配 g 执行全局匹配(查找所有匹配,不用这个修饰符默认找到第一个匹配后停止) m 多行匹配 (https://zh.javascript.info/regexp-multiline-mode) s 启用 “dotall” 模式,允许点 .匹配换行符\nu 开启完整的 Unicode 支持。该修饰符能够正确处理代理对 (https://zh.javascript.info/regexp-unicode) y 粘滞模式,在文本中的确切位置搜索 (https://zh.javascript.info/regexp-sticky)
正则对象属性
| 属性 | 描述 |
|---|---|
| constructor | 返回一个函数,该函数是一个创建 RegExp 对象的原型。 |
| global | 返回布尔值,判断是否设置了 "g" 修饰符 |
| ignoreCase | 返回布尔值,判断是否设置了 "i" 修饰符 |
| multiline | 返回布尔值,判断是否设置了 "m" 修饰符 |
| source | 返回正则表达式字符串 |
| lastIndex | 用于规定下次匹配的起始位置 |
例子
console.log(/\w+/g.global) //true
console.log(/\w+/i).ignoreCase //true
console.log(/\w/i).source // '\\w+'lastIndex的例子
// 该属性只有设置标志 g 才能使用
// 该属性是可读可写的。RegExp.exec() 和 RegExp.test()都以 lastIndex 属性所指的位置作为本次检索的终点
// 找不到可以匹配的文本时,RegExp.exec() 和 RegExp.test()会自动把 lastIndex 属性重置为 0
var str="The rain in Spain stays mainly in the plain";
var patt1=/ain/g;
while (patt1.test(str)==true)
{
document.write(`ain lastIndex at: ${patt1.lastIndex}`)
document.write("<br>");
}
'ain' lastIndex at: 8
'ain' lastIndex at: 17
'ain' lastIndex at: 28
'ain' lastIndex: 43正则对象方法
| 方法 | 描述 |
|---|---|
| exec | 检索字符串中指定的值。返回找到的值,并确定其位置。 |
| test | 检索字符串中指定的值。返回 true 或 false。 |
| toString | 返回正则表达式的字符串。 |
exec
返回正则表达式匹配到的值
参数:
- 待检索的字符串
返回值:
- 如果字符串中有匹配的值返回该匹配值,否则返回 null。
/Hello/g.exec("Hello world! Helloo") //输出:Hellotest
判断字符串中是否有正则表达式能匹配的值
参数:
- 待检索的字符串
返回值:
- 布尔值
/a/.test("ab cde") //truetoString
与source属性一样
console.log(/\w+/i).source //输出: /\w+/i
console.log(/\w+/i.toString()) //输出 /\w+/i字符串对象的正则方法
| 方法 | 描述 |
|---|---|
| search | 检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串 |
| match | 找到一个或多个正则表达式的匹配 |
| replace | 替换与正则表达式匹配的子串 |
| split | 把字符串分割为字符串数组 |
字符串的正则方法非常强大,可以从文本中直接匹配出来我们需要的内容
search
match
搭配正则的捕获组,可以从文本中提取我们需要的部分
注意:match的正则一般不要加g,避免出错
const matchRes='薪水 20-30K'.match(/^薪水 (.*)-(.*)K$/)
if(matchRes){
console.log('最低薪水',matchRes[1])
console.log('最高薪水',matchRes[2])
}
// (.*) 是正则的捕获组,.*表示任意数量的字符
// 注意:捕获组匹配不到,返回null。下面的replace方法匹配不到返回空字符串
// 匹配到,返回值matchRes是个类数组对象,索引0是输入字符串、索引1是第1个捕获组,索引2是第2个捕获组如果我们匹配到字母文本后,需要将字母转化为大写,就可以用replace。参照:replace的用法3
// \b 适合提取英文单词,注意尾部如果有空格也会提取出来
" abc cde fgh hi ".match(/\b(.*)\b/g) // ['abc cde fgh hi', '']
// 所以,一般用 \w+ , \w表示数字、字母、下划线,+表示大于等于1,所以可以过滤掉空
" abc cde fgh hi ".match(/\b(\w+)\b/g)replace
文档:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/replace
// 返回替换后的值。原字符串未改变
'xxxx'.replace(pattern, replacement)用法
// 用法1
"hello".replace('h', 'H'); // "_xxx"
// 用法2:pattern是空字符串,则插入字符串开头
"xxx".replace('', '_'); // "_xxx"
// 用法3:pattern是正则
'[object Array]'.replace(/^\[object (.*)\]$/, '$1'); // $1表示第一个捕获组。返回'Array'
// 用法3:replacement可以是函数
"a1b".replace(/[a-z]/g, (match,offset) => {
console.log(match,offset); // a 0 ; b 2
return match.toUpperCase();
});
// 当正则中存在匹配组时, match,...pN,offset ,其中pN就是匹配组
'[object Array]'.replace(/^\[object (.*)\]$/, (match, p1)=>{
// match是正则匹配到的文本,p1是第一个捕获组。如果有第二个捕获组,就再加1个入参
// 注意:捕获组匹配不到是空字符串
console.log(match, p1) // [object Array] Array
return p1.toLowerCase()
}); // 返回 'array'错误对象
错误对象
JS内建的错误对象
Error
Error是错误的基类型,其他错误类型继承自该类型 。一般是开发者抛出
jsthrow Error('错误提示文案')ReferenceError
使用了未声明的变量
jsconsole.log(a) //ReferenceError: a is not definedSyntaxError
语法错误,这个错误触发的情况挺多不具体列举了
TypeError
JS的某些函数的参数是有类型限制的,如果传入了错误的类型会抛出错误
还有就是更为常见的,使用了
.方法,试图访问null或者undefined的属性jsconsole.log(null.a)//TypeError: Cannot read property 'a' of null console.log(undefined.a)//TypeError: Cannot read property 'a' of nullInternalError
JS引擎发生异常时,例如栈溢出
EvalError
eval函数的错误使用触发的异常
jsnew eval() //抛出EvalErrorRangeError
使用Array构造数组时,传入负数或者Number.MAX_VALUE
jslet a=new Array(-120) //RangeError: Invalid array length let a=new Array(Number.MAX_VALUE) //RangeError: Invalid array lengthURIError
只出现在encodeURI()和decodeURI(),传入错误参数,这两个函数非常健壮,极特殊情况下的参数才会报错
jsconsole.log(encodeURI('\uD800')) //URIError: URI malformed
错误对象
使用new关键字,可以创建错误实例
错误实例的结构
对于所有内建的错误定向,都具有两个主要属性:
name错误名称。例如,Error对象的name是"Error",ReferenceError对象的name就是"ReferenceError"
message关于该错误的详细文字描述
还有其他非标准的属性(虽然不是官方规范,但是在大多数环境中可用),例如:
stack当前的调用栈:用于调试目的的一个字符串,其中包含有关导致 error 的嵌套调用序列的信息
错误类的伪代码
JS自身定义的内建的 Error 类的“伪代码”
class Error {
constructor(message) {
this.message = message;
this.name = "Error"; // (不同的内建 error 类有不同的名字)
this.stack = <call stack>; // 非标准的,但大多数环境都支持它
}
}例子
let error = new Error(message);
let syntaxError = new SyntaxError(message);错误name 属性刚好就是构造器的名字,message 则来自于参数。
捕获错误对象
基本语法
可以使用try...catch语法捕获错误实例。如果发生了错误,但是没有捕获到该错误实例,那JS代码就会终止执行,然后再控制台打印出错误
try{
//可能会出错的代码
}catch(err){
//err就是try中抛出的错误实例
}finall{
//最终一定会执行
}try中错误的来源
代码中自动抛出的错误实例,一般是各种语法错误。比如,这个TypeError就是代码自动抛出的错误
jstry{ console.log(null.a) }catch (err){ console.log(err) //TypeError: Cannot read property 'a' of null } //name:TypeError , message: Cannot read property 'a' of null开发者根据业务主动抛出错误实例。使用JS内建的错误构造器,构造出错误实例,通过throw抛出(省略new关键字)
JS允许将
throw与任何参数一起使用,比如抛出一个字符串,catch中的参数就是这个字符串,一般还是建议throw一个错误对象入参一般是字符串,放置在错误对象的message字段中
jstry{ throw Error("这里是错误") // name:Error , message: 传入的参数 }catch (err){ console.log(err.message) //这里是错误 }入参可以是对象,但是不建议这么做
jstry{ throw Error({name:'tom'}) // name:Error , message: 传入的参数 }catch (err){ console.log(err.message) // [object Object] }
如何在catch中处错误
我们应该在catch中进行判断,明确哪些错误是需要进行处理的,哪些错误是不处理,对不处理的错误要再次抛出
切记:
不能在catch中捕获所有的错误后,不做区分,对所有错误都不再次抛出。这样有可能掩盖真正的代码错误(比如语法错误),使得程序问题难以排查
流程:
- 使用instanceof对错误进行判断(或者使用err.name进行判断)
- 使用throw再次抛出未处理的错误
例如:
要求外部输入的JSON字段必须有name属性,否则不符合业务要求。
//假设json是外部用户输入的数据
let json = '{ "age": 30 }';
try {
let user = JSON.parse(json);
if (!user.name) {
throw new SyntaxError("缺少name字段");
}
} catch (err) {
if (err instanceof SyntaxError) {
console.log(err);//可以在这里加一个弹窗,提示用户
} else {
throw err; // 再次抛出
}
}try语法补充
finally 子句适用于 try...catch 的 任何 出口。这包括 return
function testFinally(){
try {
return 1;//执行到这里就结束了,下一句错误的语句不会被执行,所有也没有错误被catch捕获
null.a
} catch(err){
console.log("catch到错误",err)
}finally{
return 3;//一定会执行
}
}
console.log(testFinally()) //3自定义错误类
JS内置的错误类,可能并不能满足我们的业务要求,我们需要特定的错误对象来描述具体的业务错误
上一节【部或错误对象】中出现的例子:
要求外部输入的JSON字段必须有name属性,否则不符合业务要求
在代码里面,我们抛出的是JS内置的语法错误,但其实JSON必须要有name属性,是我们的业务要求,其并不是一个JS的语法错误,所以,为了和真正的JS语法错误区分开,我们需要定义自己的错误对象
//假设json是外部用户输入的数据
let json = '{ "age": 30 }';
try {
let user = JSON.parse(json);
if (!user.name) {
throw new SyntaxError("缺少name字段");
}
} catch (err) {
if (err instanceof SyntaxError) {
console.log(err);//可以在这里加一个弹窗,提示用户
} else {
throw err; // 再次抛出
}
}自定义错误
可以根据自己的需要,在下面的基础上添加更多的字段记录需要的错误信息
class ValidationError extends Error {
constructor(message) {
super(message);
this.name = "ValidationError";
}
}如果不希望手动设置name字段
class ValidationError extends Error {
constructor(message) {
super(message);
this.name = this.constructor.name; //自动以类名作为错误对象的name字段
}
}错误类的体系结构
通过继承来构建一整个错误体系
Proxy与Reflect
(() => {
const stu = {
name: 1,
score: {
math: {
title:'1'
},
},
};
const handler = {
get(target,prop){
let val = Reflect.get(target, prop);
if(val instanceof Object){
return new Proxy(val,handler)
}
return val
},
set(target, prop, val) {
console.log(target, prop, val)
let val = Reflect.get(target, prop);
if(val instanceof Object){
new Proxy(val,handler)
}
val[prop]=val
return true;
},
};
const newStu = new Proxy(stu, handler);
newStu.score.math.title = 3;
//难以置信---》 newStu.score.math.title 等价于
// newStu.score get拦截到score为对象就 return 新的Proxy(score,handler)
// (get拦截器return的值).math get拦截到math为对象就 return 新的Proxy(math,handler)
// (get拦截器return的值).title=3 这里不会触发get,而是set
})();实现一个写时深拷贝
function produce(base, recipe) {
// 预定义一个 copy 副本
let copy;
let lastKey;
// 定义 base 对象的 proxy handler
const baseHandler = {
get(target,key){ // a.b.c=1
if (!copy) {
copy = { ...target };
}
const val=Reflect.get(target,key)
if(val instanceof Object){
lastKey=key
return new Proxy(val,baseHandler)
}
return val
},
set(target, key, value) {
// 先检查 copy 是否存在,如果不存在,创建 copy
if (!copy) {
copy[lastKey] = { ...target };
}
copy[lastKey][key] = value;
return true;
},
};
// 被 proxy 包装后的 base 记为 draft
const draft = new Proxy(base, baseHandler);
// 将 draft 作为入参传入 recipe
recipe(draft);
// 返回一个被“冻结”的 copy,如果 copy 不存在,表示没有执行写操作,返回 base 即可
// “冻结”是为了避免意外的修改发生,进一步保证数据的纯度
return Object.freeze(copy || base);
}
const stu={
name:'tom',
score:{
english:100,
math:80
}
}
const deepData=produce(stu,(data)=>{
data.score.math=1
// data.name=1
})
console.log(deepData)
console.log(deepData===stu)
console.log(deepData.score===stu.score)Promise
Promise介绍
Promise是用来处理异步函数的利器,相较于传统的回调函数的弊端(回调地狱)
Promise包含pending、fulfilled、rejected三种状态
pending指初始等待状态,初始化promise时的状态fulfilled指已经解决rejected指失败
pending只能转化为最终态fulfilled或reject,且转化不可逆
创建Promise
注意:最终态Promise可以携带数据
Pending状态
创建一个Pending状态的Promise
p=new Promise()变更状态:
let p1=new Promise((resolve,reject)=>{
// 调用resolve函数后,Promise从pending态转变为fulfilled态
resolve("成功状态Promise携带的数据")
})
let p2=new Promise((resolve,reject)=>{
// 调用reject函数后,Promise从pending态转变为rejected态
reject("成功失败Promise携带的数据") // 习惯上抛出Error对象,例如 reject(new Error("失败的信息"))
})Promise的构造函数入参是一个回调函数,Promise内部会向会回调函数的入参中塞入resolve、reject函数
这样在回调函数中,就可以控制Promise内部的行为
class Promise{
constructor(executor){
executor(this.resolve,this.reject)
}
resolve(){}
reject(){}
}Fulfilled状态
使用 promise.resolve 方法可以快速的返回一个成功状态的promise对象
Promise.resolve("成功的信息")Reject状态
Promise.reject(new Error("失败的信息"))流水线then
then是Promise实例上的函数
入参
then有两个参数,都是回调函数
let p=new Promise((resolve,reject)=>{
// 这里转化了Promise的状态,then才会触发执行。获取其结果
resolve("成功失败Promise携带的数据")
}).then(
value=>{ // 如果前面的Promise转化为了 fulfilled ,这个回调会执行。value是Promise携带的数据
console.log("fulfilled状态",value)
},
reason => { // 如果前面的Promise转化为了 rejected ,这个回调会执行。reason是Promise携带的数据
console.log("rejected状态",reason)
}
)then中只写一个函数,默认是执行成功的那个回调函数
let p1=new Promise((resolve)=>{
resolve("成功失败Promise携带的数据")//转化为fulfilled状态
}).then(value=>{
console.log(value) //执行成功,会把值传递给参数value
)如果then中只想写执行失败的回调函数
let p1=new Promise((resolve,reject)=>{
reject("成功失败Promise携带的数据")//转化为fulfilled状态
}).then(
null,//执行成功的函数不写,也得放个null占位置
reason=>{////执行失败,会把值传递给第二个参数reason
console.log(reason)
}
)返参
then函数的返参还是Promise ,所以其可以继续调用then方法
下面只以fulfilled状态的Promise,调用then函数为例子
1、返回fulfilled的Promise
let p=new Promise((resolve,reject)=>{
resolve("传递给then的值")
}).then(
value=>{
// 方式1
return Promise.resolve("成功")
// 方式2:return 值 ,默认返回Fulfilled状态Promise,Promise的数据为return的值
return "成功"
// 方式3: 不写return ,默认返回的Fulfilled状态Promise的参数是 undefined
}
)2、返回Reject的Promise
let p=new Promise((resolve,reject)=>{
resolve("传递给then的值")
}).then(
value=>{
return Promise.reject("失败")
}
).then(
value=>{
console.log("fulfilled状态",value)
},
reason => {
console.log("rejected状态",reason) //rejected状态 失败
}
)异步
一定要注意:then的两个回调函数是异步的
resolve() 执行后,需要等待Promise转化为最终状态后(这部分不是立即执行的),回调函数才会执行
let p=new Promise((resolve,reject)=>{
resolve() // 第一步
console.log(1) // 第二部
}).then(value=>{
console.log(2) // 第三部,回调回来
})
// 1
// 2更复杂的例子
let p=new Promise((resolve,reject)=>{
console.log("1")
reject("2")
console.log("3")
}).then(
null,
reason=>{
console.log(reason)
return Promise.reject("错误")
}
).catch(()=>{
console.log("5")
})
console.log("6")
// 1
// 3
// 6
// 2
// 5这个例子,需要注意 p1.then返回的Promise,在then回调执行之前是pending状态
let p1=new Promise((resolve,reject)=>{
console.log("你好")
resolve("succeed")
})
let p2=p1.then(
value=>console.log(value),
reason=>console.log(reason)
)
console.log(p1)
console.log(p2)
流水线错误处理catch
catch是Promise实例的参数
【1】catch也可以捕获到rejected状态的Promise和Error对象,then的第二个回调函数也可以
【2】未捕获到的rejected状态的Promise和Error对象,都会造成代码终止执行,在控制台会打印错误
一般规律是:出现rejected状态的Promise或抛出错误对象,会被后面最近【1】或【2】捕获到,且被捕获后除非重新抛出rejected状态的Promise 或者 重新抛出错误对象,否则就不能被捕获到了
let p=new Promise((resolve,reject)=>{
reject("2222")//执行成功,传递参数
}).then(
null,
reason=>{
console.log("then中被捕获",reason) //then中被捕获 2222
}
).catch(err=>{
console.log("catch中被捕获:",err)
})常见的写法是:不在then中写处理失败的回调函数,而是将catch写到调用链的最后,前面发生的失败参数和错误会跳过所有的then,直接被传递到catch中处理
const promise = new Promise((resolve, reject) => {
reject("你好");
})
.then((value)=>{
console.log("then中打印") //注意:这里被跳过了,直接跳到了最近的错误处理部分
})
.catch(msg => {
console.log("这里是catch捕获的参数:"+msg);
});
//输出 这里是catch捕获的参数:你好注意细节:
catch的返回值也是resolve状态的promise,而且之前的then即使有rejected的处理函数,仍然会被忽略,直接被catch捕获
let p1 = new Promise((resolve, reject) => {
reject("参数")
}).then(
value => {
console.log("第一个then中处理resolve:" + value) //这里打印,但是没写return value,但是这个then的返回值任然是resolve状态的promise,只不过没参数
}, reason => {
console.log("第一个then中处理reject:"+value)
}
).then(
value => { //
console.log("第二个then中处理resolve:" + value)
},reason=>{
console.log("第二个then中处理reject:"+value)
}
).catch(msg => {
console.log("这里是catch捕获的参数:" + msg);
}).then(
value => { //
console.log("第三个then中处理resolve:" + value)
},reason=>{
console.log("第三个then中处理reject:"+value)
}
)
//这里是catch捕获的参数:ReferenceError: value is not defined
//第三个then中处理resolve:undefinedthen返回的resolve状态的promise,跳过了catch,把参数传递给了下一个then
let p1 = new Promise((resolve, reject) => {
resolve("参数")
}).then(
value => {
console.log("第一个then中处理resolve:" + value) //这里打印,但是没写return value,但是这个then的返回值任然是resolve状态的promise,只不过没参数
}, reason => {
console.log("第一个then中处理reject:"+value)
}
).then(
value => { //
console.log("第二个then中处理resolve:" + value)
return "参数2"
},reason=>{
console.log("第二个then中处理reject:"+value)
}
).catch(msg => {
console.log("这里是catch捕获的参数:" + msg);
}).then(
value => { //
console.log("第三个then中处理resolve:" + value)
},reason=>{
console.log("第三个then中处理reject:"+value)
}
)
//第一个then中处理resolve:参数
//第二个then中处理resolve:undefined
//第三个then中处理resolve:参数2例题1
程序由上到下运行
创建p1
打印”你好“
执行到resolve后,把then中的函数加入到微任务队列。并把then返回的promise对象赋值给p2
打印p1对象,因为已经resolve,所以状态是fulfilled
打印p2对象,但是p2未执行
主线任务结束后,开始执行微任务队列,value函数执行,打印"succeed"
例题2
程序由上到下运行
创建p1
打印”你好“
执行到resolve后,把then中的函数加入到微任务队列。并把then返回的promise对象赋值给p2
setTimeout是异步函数,会被加入到宏任务队列
主线任务结束,开始执行微任务队列,value函数执行,打印"succeed"
执行宏任务队列,打印p1和p2,这时候两个都是fulfilled状态
Promise API
Promise.all
使用Promise.all 方法可以同时执行多个并行异步操作,参数是Promise组成的数组
Promise.all适合用在我们需要 所有 结果都成功时做成功处理,如果一个失败就做失败处理的场景下
以下是不同情况下的例子:
所有Promise 状态都为
fulfilled时,Promise.all的结果才是fulfilledthen按照all参数的顺序,接收所有
fulfilled状态的Promise传递过来的参数javascriptlet p1 = new Promise((resolve, reject) => { resolve("参数1"); }); let p2 = new Promise((resolve, reject) => { resolve("参数2"); }); Promise.all([p2, p1]).then( value=>{ console.log("fulfilled状态:",value)// fulfilled状态:["参数2", "参数1"] },reason=>{ console.log("rejected状态:",reason) } );其中一个 Promise 状态都为
rejected时,Promise.all就会立即返回rejected的结果then的结果是按照all参数顺序中,接收第一个状态是
rejected的Promise传递过来的值注意:只是忽略其他 promise的结果,但是并没有取消其他Promise(因为 promise 中没有“取消”的概念),其中的异步操作还是会执行下去
javascriptlet p1 = new Promise((resolve, reject) => { resolve("参数1"); }); let p2 = new Promise((resolve, reject) => { reject("参数2"); }); let p3 = new Promise((resolve, reject) => { reject("参数3"); }); Promise.all([p1,p2,p3]).then( value=>{ console.log(value) },reason=>{ console.log(reason)//参数2 } );参数数组的元素,不是Promise就会原样返回
jsPromise.all([ new Promise((resolve, reject) => { setTimeout(() => resolve(1), 1000) }), 2, 3 ]).then(alert); // 1, 2, 3
Promise.allSettled
allSettled 也适用于处理多个promise ,无论promise是fulfiled还是rejected,allSettled都是按照参数的顺序返回结果
Promise.allSettled适合用在我们需要获取所有结果(无论成功,还是失败)的场景下
注意,then的第二个回调函数和catch都不能捕获到失败的结果,只能在then的第一个结果中被捕获
const p1 = new Promise((resolve, reject) => {
resolve("参数1");
});
const p2 = new Promise((resolve, reject) => {
reject("参数2");
});
//入参数组,是一个返回promise的函数
Promise.allSettled([p1, p2])
.then(msg => {
console.log(msg);
//[ {status: "fulfilled", value: "参数1"},{status: "rejected", reason: "参数2"} ]
})Promise.race
使用Promise.race() ,Promise无论是resolve还是reject,哪个快用哪个,按状态返回到对应的处理函数
与all函数相同,Promise中没有取消的概念,所有只是或忽略了返回慢的Promise的结果,但是并没有取消其异步操作
const hdcms = new Promise((resolve, reject) => {
setTimeout(() => {
resolve("第一个Promise");
}, 2000);
});
const houdunren = new Promise((resolve, reject) => {
setTimeout(() => {
reject("第二个异步");
}, 1000);
});
Promise.race([hdcms, houdunren])
.then(results => {
console.log("fulfilled状态:"+results);
})
.catch(msg => {
console.log("rejected状态:"+msg);
});回调函数Promise化
回调函数
首先第一个问题,回调函数一定是异步的吗?
答案:不是。回调只是代码层面的一种手段,函数可以不在执行时立即拿到结果,而是在之后的某个时间触发回调函数带回结果
下面例子是回调函数是同步的
function f1(callback) {
callback()
}
// 第1步 回调函数立即就执行了
f1(()=>{
console.log(1)
})
// 第2步
console.log(2)
//1
//2下面的回调是异步的
异步其实本质是浏览器控制的,代码并不会等待1s,而是1s后浏览器将"setTimeout传入的函数"放入微任务队列,当宏任务执行完毕后才会继续执行微任务,即这里的callback函数
function f1(callback) {
setTimeout(()=>{
callback()
},1000)
}
// 第1步 回调函数立即就执行了
f1(()=>{
console.log(1)
})
// 第2步
console.log(2)
//2
//1 等待1s后才输出1应用
一般情况下,我们只会把异步的回调函数Promise化
网络请求是异步的,当浏览器接收到请求结果后将其放入微任务队列等待,当宏任务执行完毕后执行触发回调
改成Promise后,只有请求结果返回时才会触发then,then中就可以处理这个数据了。相当于指定了一个顺序:请求--->处理请求的数据
function ajax(url) {
return new Promise((resolve, reject) => {
let xhr = new XMLHttpRequest()
xhr.open("GET", url)
xhr.send()
xhr.onload = function () {
if (this.status == 200) {
resolve(JSON.parse(this.response))
} else {
reject("加载失败")
}
}
})
}
// 使用时,返回的peomise由then处理
ajax("网址").then(
value=>console.log(value),
reason=>console.log(reason)
)变化
回调函数不只能执行一次回调,可以多次
function f1(callback) {
setInterval(()=>{
callback()
},1000)
}
// 第1步 回调函数立即就执行了
f1(()=>{
console.log(1)
})
// 第2步
console.log(2)
//2
//1 循环输出1但是一旦Promise化后,由于Promise转化为最终态后,不可逆转。所以下面的代码只能输出一次回调的结果
function getDate() {
return new Promise((resolve) => {
setInterval(resolve,1000)
})
}
this.getDate(()=>{
console.log(1)
})
console.log(2)
//2
//1async/await
Promise已经能实现异步转化为同步处理了
只不过,当为多个异步操作指定处理顺序时,会出现嵌套
getData1().then((res1)=>{
getData2(res1.value).then((res2)=>{
getData3(res2.value).then((res3)=>{
// 指定 getData1 -> getData2 -> getData3 循序执行
})
})
})async/await语法本质是Promise的语法糖,仅仅是使得Promise的书写更加明晰
用async修饰的函数内部才能使用await
await后面接值,会直接返回之该值
jsfunction f() { return 1 } async getRes(){ const res=await f() console.log(res) //1 }await后面接Promise对象,如果Promise对象为fulfilled状态会直接取出其携带的数据,rejected状态会直接结束
jsfunction f() { return new Promise((resolve) => { setTimeout(()=>{ resolve(1) },1000) }) } async getRes(){ const res=await f() // 返回值是Promise对象,await取出携带的值 console.log(res) //1 }
async/await错误处理方案
try{
// await
await xxx()
}catch(err){// 错误处理 rejected状态的Promise、Error都能被捕获到
}finally{ //无论状态是`resolve` 或 `reject` 都会执行`finally`
}但是请注意,对于异步函数必须使用await同步化后,才能使用try catch来处理错误
function p(){
return new Promise((resolve,reject)=>{
setTimeout(resolve,2000)
})
}
async function run (){
try{
await p1() // 这里必须await,否则代码不会等待,而是直接打印输出了: try和finally
console.log('try')
}catch (err){
console.log('err',err)
}finally {
console.log('finally')
}
}
run()限制Promise并发量
JS是单线程的,all、allSettle都是将大量任务委托给宿主。如果任务占据资源太多很容易造成CPU或内存占用过多
class pool{
#pool=new Set()
#waitQueue=[]
#excuteQueue=[]
#size=10
constructor(){
}
pushTask(asyncTask){
#excuteQueue.push(asyncTask)
}
excuteTask(){
}
}实现Promise
实现Promise
初步实现resolve和reject方法
class HD {
static PENDING = "pending";
static FULFILLED = "fulfilled";
static REJECTED = "rejected";
constructor(executor) {
this.status = HD.PENDING;
this.value = null;
try {
//executor中的参数中this还是指向HD对象的
//但是执行到resolve和reject函数内部时,使用this,this会指向undefined(class中默认严格模式)
//所以使用bind,将resolve和reject函数中的this指向HD对象
executor(this.resolve.bind(this), this.reject.bind(this));
} catch (error) {
this.reject(error);
}
}
resolve(value) {
//promise的状态只能是从pending转换过去
if (this.status == HD.PENDING) {
this.status = HD.FULFILLED;
this.value = value;
}
}
reject(value) {
//promise的状态只能是从pending转换过去
if (this.status == HD.PENDING) {
this.status = HD.REJECTED;
this.value = value;
}
}
}测试
let a=new HD((resolve,reject)=>{
resolve("参数")
})
console.log(a) //输出 HD {status: "fulfilled", value: "你好"}添加then方法
then(onFulfilled, onRejected) {
//前两个if的作用:then的函数参数都不是必须的,所以需要设置默认值为函数,用于处理当没有传递时情况
//比如then(null,reject=>{ }),这种如果没有之前的两个if判断就会报错
if (typeof onFulfilled != "function") {
//将class HD中保存的传递的参数value的值,塞到onFulifilled和onRejected这两个函数中
onFulfilled = () => this.value;
}
if (typeof onRejected != "function") {
onRejected = () => this.value;
}
//只有promise状态改变了,才会执行then中的内容
if (this.status == HD.FULFILLED) {
try {
onFulfilled(this.value);
} catch (error) {
onRejected(error);
}
}
if (this.status == HD.REJECTED) {
try {
onRejected(this.value);
} catch (error) {
onRejected(error);
}
}
}存在的问题:HD没有异步的效果
let a = new HD((resolve, reject) => {
resolve("你好")
}).then(
value=>console.log("fulfilled状态:"+value),
reason=>console.log("rejected状态:"+reason)
)
console.log("他好")
//输出 fulfilled状态:你好 他好
//then先于主线任务被执行,这样是不对的修改then,给then添加异步
then(onFulfilled, onRejected) {
if (typeof onFulfilled != "function") {
onFulfilled = value => value;
}
if (typeof onRejected != "function") {
onRejected = value => value;
}
if (this.status == HD.FULFILLED) {
//其实就是添加了setTimeout函数之中,then中函数不会立即执行
setTimeout(() => {
try {
onFulfilled(this.value);
} catch (error) {
onRejected(error);
}
});
}
if (this.status == HD.REJECTED) {
setTimeout(() => {
try {
onRejected(this.value);
} catch (error) {
onRejected(error);
}
});
}
}存在的问题:resolve/reject放在定时器中,当它还未被执行时,就执行了then方法。then方法缺少对于pending状态的处理。
let a = new HD((resolve, reject) => {
setTimeout(()=>{
resolve("你好")
},1000)
}).then(
value=>console.log("fulfilled状态:"+value),
reason=>console.log("rejected状态:"+reason)
)
console.log("他好")
//输出 他好
//因为resolve/reject放在定时器中,当它还未被执行时,就执行了then方法。then方法缺少对于pending状态的处理。修改方法
//在HD构造函数中添加
constructor(executor) {
...
this.callbacks = []
...
}
//在then函数中添加pending状态,如果Promise没有被resolve或者reject(计时器计时1s之后执行),就进入then方法,会把两个函数push进HD对象中,当计时器到了时间,执行到resolve或者reject时,会在then中push进去的方法中,执行对应的方法
then(onFulfilled, onRejected) {
...
if (this.status == HD.PENDING) {
this.callbacks.push({
onFulfilled: value => {
try {
onFulfilled(value);
} catch (error) {
onRejected(error);
}
},
onRejected: value => {
try {
onRejected(value);
} catch (error) {
onRejected(error);
}
}
});
}
...
}
//修改resolve和reject函数
resolve(value) {
if (this.status == HD.PENDING) {
this.status = HD.FULFILLED;
this.value = value;
this.callbacks.map(callback => {
callback.onFulfilled(value);
});
}
}
reject(value) {
if (this.status == HD.PENDING) {
this.status = HD.REJECTED;
this.value = value;
this.callbacks.map(callback => {
callback.onRejected(value);
});
}
}存在问题: 这里pending状态下是同步的,应该是先执行到reslove(“你好”),将then添加到微任务,然后打印“哈哈”,然后再执行微任务,打印"你好"
let p = new HD((resolve, reject) => {
setTimeout(() => {
resolve("你好");
console.log("哈哈");
});
}).then(
value => {
console.log(value);
},
reason => {
console.log(reason);
}
);
//输出 你好 哈哈修改resolve和reject函数
resolve(value) {
if (this.status == HD.PENDING) {
this.status = HD.FULFILLED;
this.value = value;
setTimeout(() => {
this.callbacks.map(callback => {
callback.onFulfilled(value);
});
});
}
}
reject(value) {
if (this.status == HD.PENDING) {
this.status = HD.REJECTED;
this.value = value;
setTimeout(() => {
this.callbacks.map(callback => {
callback.onRejected(value);
});
});
}
}存在的问题:未实现then的链式调用
- then的返回值是新的Promise
- then中通过
return 参数,将参数传递给下一个then,且状态是fulfilled状态
继续修改:
then(onFulfilled, onRejected) {
if (typeof onFulfilled != "function") {
onFulfilled = value => value;
}
if (typeof onRejected != "function") {
onRejected = value => value;
}
//返回新的Promise,这里的参数是新Promise的resolve和rejec两个函数。
return new HD((resolve, reject) => {
if (this.status == HD.PENDING) {
this.callbacks.push({
onFulfilled: value => {
try {
let result = onFulfilled(value);
//then中的"return 参数",返回的新Promise默认是fulfilled状态
resolve(result);
} catch (error) {
reject(error);
}
},
onRejected: value => {
try {
let result = onRejected(value);
//then中的"return 参数",返回的新Promise默认是fulfilled状态
resolve(result);
} catch (error) {
reject(error);
}
}
});
}
if (this.status == HD.FULFILLED) {
setTimeout(() => {
try {
let result = onFulfilled(this.value);
//then中的"return 参数",返回的新Promise默认是fulfilled状态
resolve(result);
} catch (error) {
reject(error);
}
});
}
if (this.status == HD.REJECTED) {
setTimeout(() => {
try {
let result = onRejected(this.value);
//then中的"return 参数",返回的新Promise默认是fulfilled状态
resolve(result);
} catch (error) {
reject(error);
}
});
}
});
}继续修改:实现then中可以return 一个Promise
then(onFulfilled, onRejected) {
if (typeof onFulfilled != "function") {
onFulfilled = value => value;
}
if (typeof onRejected != "function") {
onRejected = value => value;
}
return new HD((resolve, reject) => {
if (this.status == HD.PENDING) {
this.callbacks.push({
onFulfilled: value => {
try {
let result = onFulfilled(value);
//判断下,return的是Promise对象,则用then函数执行其中的resolve或者reject函数
if (result instanceof HD) {
result.then(resolve, reject);
} else {//如果return的是一个参数,默认新的Promise是fulfilled状态,resolve参数即可
resolve(result);
}
} catch (error) {
reject(error);
}
},
onRejected: value => {
try {
let result = onRejected(value);
if (result instanceof HD) {
result.then(resolve, reject);
} else {
resolve(result);
}
} catch (error) {
reject(error);
}
}
});
}
if (this.status == HD.FULFILLED) {
setTimeout(() => {
try {
let result = onFulfilled(this.value);
if (result instanceof HD) {
result.then(resolve, reject);
} else {
resolve(result);
}
} catch (error) {
reject(error);
}
});
}
if (this.status == HD.REJECTED) {
setTimeout(() => {
try {
let result = onRejected(this.value);
if (result instanceof HD) {
result.then(resolve, reject);
} else {
resolve(result);
}
} catch (error) {
reject(error);
}
});
}
});
}优化then函数
then(onFulfilled, onRejected) {
if (typeof onFulfilled != "function") {
onFulfilled = value => value;
}
if (typeof onRejected != "function") {
onRejected = value => value;
}
return new HD((resolve, reject) => {
if (this.status == HD.PENDING) {
this.callbacks.push({
onFulfilled: value => {
this.parse(onFulfilled(this.value), resolve, reject);
},
onRejected: value => {
this.parse(onRejected(this.value), resolve, reject);
}
});
}
if (this.status == HD.FULFILLED) {
setTimeout(() => {
this.parse(onFulfilled(this.value), resolve, reject);
});
}
if (this.status == HD.REJECTED) {
setTimeout(() => {
this.parse(onRejected(this.value), resolve, reject);
});
}
});
}
//把重复的操作封装
parse(result, resolve, reject) {
try {
if (result instanceof HD) {
result.then(resolve, reject);
} else {
resolve(result);
}
} catch (error) {
reject(error);
}
}最后一个问题:Promise的then函数中,return可以是参数,可以是新的Promise,但是不允许是自己,会报错。而HD则不会报错
let a=new Promise((resolve,reject)=>{
resolve("参数")
})
p.then(value=>{
return p //会报错
})修改then函数和parse函数
then(onFulfilled, onRejected) {
if (typeof onFulfilled != "function") {
onFulfilled = value => value;
}
if (typeof onRejected != "function") {
onRejected = value => value;
}
let promise = new HD((resolve, reject) => {
if (this.status == HD.PENDING) {
this.callbacks.push({
onFulfilled: value => {
this.parse(promise, onFulfilled(this.value), resolve, reject);
},
onRejected: value => {
this.parse(promise, onRejected(this.value), resolve, reject);
}
});
}
if (this.status == HD.FULFILLED) {
setTimeout(() => {
this.parse(promise, onFulfilled(this.value), resolve, reject);
});
}
if (this.status == HD.REJECTED) {
setTimeout(() => {
this.parse(promise, onRejected(this.value), resolve, reject);
});
}
});
return promise;
}
//多了一个传递的参数promise,第一个参数:如果then中return的是promise对象,则是该Promise对象
parse(promise, result, resolve, reject) {
//return的promise和上一个promise传递过来的参数,是否相等
if (promise == result) {
throw new TypeError("Chaining cycle detected for promise");
}
try {
if (result instanceof HD) {
result.then(resolve, reject);
} else {
resolve(result);
}
} catch (error) {
reject(error);
}
}综上最终实现的Promise对象
class HD {
static PENDING = "pending";
static FULFILLED = "fulfilled";
static REJECTED = "rejected";
constructor(executor) {
this.callbacks = [];
this.status = HD.PENDING;
this.value = null;
try {
//executor中的参数中this还是指向HD对象的
//但是执行到resolve和reject函数内部时,使用this,this会指向undefined(class中默认严格模式)
//所以使用bind,将resolve和reject函数中的this指向HD对象
executor(this.resolve.bind(this), this.reject.bind(this));
} catch (error) {
this.reject(error);
}
}
//resolve函数
resolve(value) {
if (this.status == HD.PENDING) {
this.status = HD.FULFILLED;
this.value = value;
setTimeout(() => {
this.callbacks.map(callback => {
callback.onFulfilled(value);
});
});
}
}
//reject函数
reject(value) {
if (this.status == HD.PENDING) {
this.status = HD.REJECTED;
this.value = value;
setTimeout(() => {
this.callbacks.map(callback => {
callback.onRejected(value);
});
});
}
}
//then函数
then(onFulfilled, onRejected) {
if (typeof onFulfilled != "function") {
onFulfilled = value => value;
}
if (typeof onRejected != "function") {
onRejected = value => value;
}
let promise = new HD((resolve, reject) => {
if (this.status == HD.PENDING) {
this.callbacks.push({
onFulfilled: value => {
this.parse(promise, onFulfilled(this.value), resolve, reject);
},
onRejected: value => {
this.parse(promise, onRejected(this.value), resolve, reject);
}
});
}
if (this.status == HD.FULFILLED) {
setTimeout(() => {
this.parse(promise, onFulfilled(this.value), resolve, reject);
});
}
if (this.status == HD.REJECTED) {
setTimeout(() => {
this.parse(promise, onRejected(this.value), resolve, reject);
});
}
});
return promise;
}
//then函数中,重复的部分单独封装出的函数parse
parse(promise, result, resolve, reject) {
if (promise == result) {
throw new TypeError("Chaining cycle detected for promise");
}
try {
if (result instanceof HD) {
result.then(resolve, reject);
} else {
resolve(result);
}
} catch (error) {
reject(error);
}
}
}###实现 Promise.resolve
添加静态方法到HD类中
static resolve(value) {
return new HD((resolve, reject) => {
if (value instanceof HD) {
value.then(resolve, reject);
} else {
resolve(value);
}
});
}实现 Promise.reject
添加静态方法到HD类中
static reject(reason) {
return new HD((_, reject) => {
reject(reason);
});
}实现 Promise.all
添加静态方法到HD类中
Promise.all=function(promises){
resolves=[]
return new Promise((resolve,reject)=>{
promises.forEach(promise => {
promise.then(
value=>{
resolves.push(value)
if(resolves.length==promises.length){
resolve(resolves)
}
},reason={
reject(reason)
}
)
});
})
}实现 Promise.race
添加静态方法到HD类中
static race(promises) {
return new HD((resolve, reject) => {
promises.map(promise => {
promise.then(value => {
resolve(value);
});
});
});
}事件循环
事件循环涉及的概念
主线程:用于执行JS任务的线程
执行栈(call stack):放入执行栈中的任务,会被主线程执行
任务:分为宏任务(task queue,有些文章也直接称为
任务)、微任务(Microtask Queue)宏任务:
textscript(同步代码) setTimeout() setInterval() postMessage I/O UI交互事件 requestAnimationFrame(浏览器) setImmediate(Node.js)微任务
textPromise的resolve、reject、then函数,注意回调结果才放入微任务队列 MutationObserver(html5 新特性) process.nextTick(Node.js)
注意
主代码属于宏任务,将主代码放入执行栈执行
宏任务产生微任务(setTimeout等宏任务的回调结果属于微任务)
微任务也会产生微任务+宏任务(promise的then方法能一直添加,即一直增加微任务);
微任务不可能凭空出现,第一个微任务一定是宏任务的回调产生的。例如主代码执行到发起网络请求的部分,发起请求后挂起,等待请求结果返回后浏览器会将回调结果放入微任务(并不是把异步任务放入微任务队列,而是异步有结果后,将回调结果放入微任务队列)
事件循环
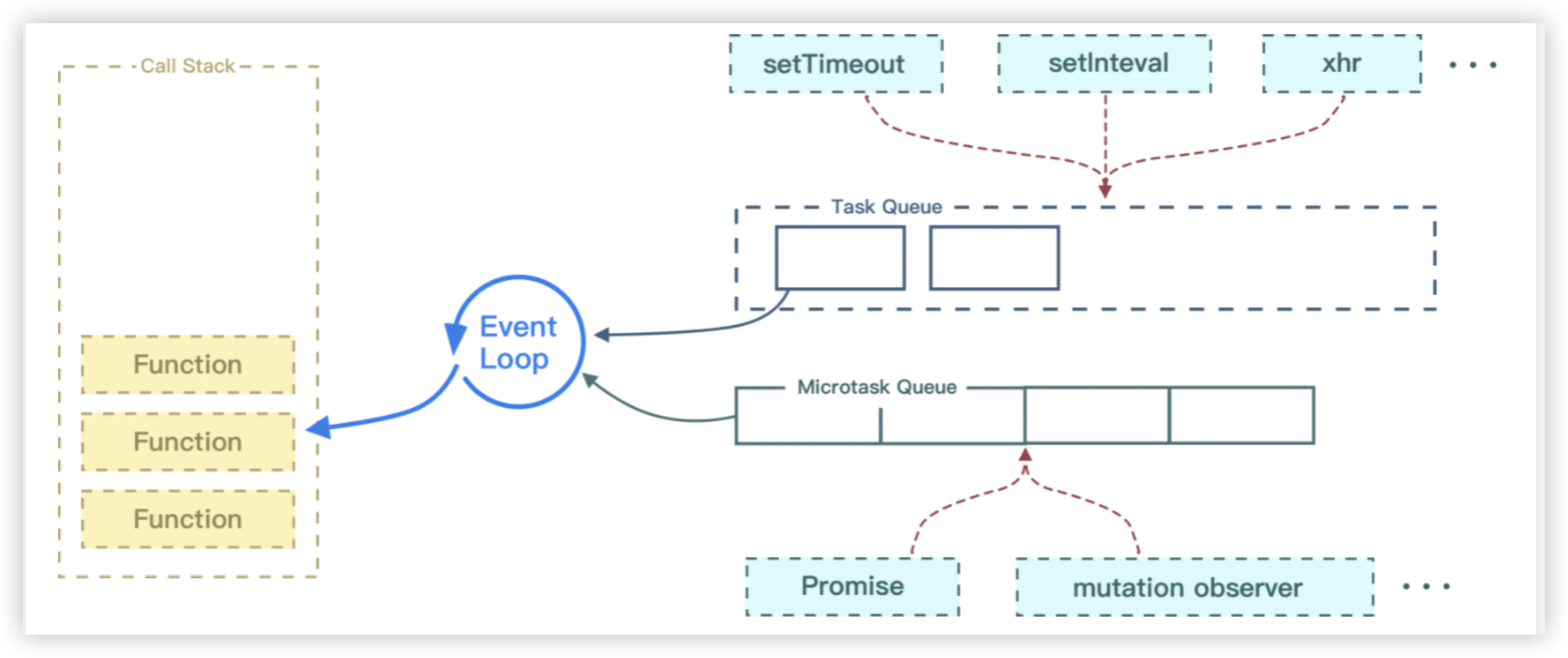
事件循环流程如下:
JS引擎中存在一个
monitoring process的进程,这个进程会循环不断的检查主线程的执行情况,一旦主线程空闲,就会去检查宏任务队列在执行宏任务之前,浏览器会检查是否需要渲染UI界面,如果需要则在宏任务队列中添加一个渲染的任务。该宏任务比较特殊,由GUI线程接管渲染
如果宏任务队列有任务,则将宏任务放入执行栈。主线程执行完后,继续读取宏任务,直至宏任务队列为空(执行宏任务过程中,如果有回调,待回调有结果,则加入微任务队列),主线程空闲才会检查微任务队列
如果存在微任务,则将其添加至执行栈,主线程开始执行其中的微任务
微任务执行过程中如果产生微任务,则添加至微任务队尾(promise的有多个then链式调用,假设一直产生微任务,则就会一直执行微任务)
微任务执行过程中如果产生宏任务,则添加至宏任务队尾,待微任务队列执行执行完毕,才会进入下一轮循环,即读取宏任务
一直读取微任务,直至微任务队列为空,开启下一轮循环,即主进程执行:渲染-宏任务-微任务
渲染任务
前面提到的渲染任务比较特殊,这里做出解释
下面是浏览器渲染引擎的工作过程
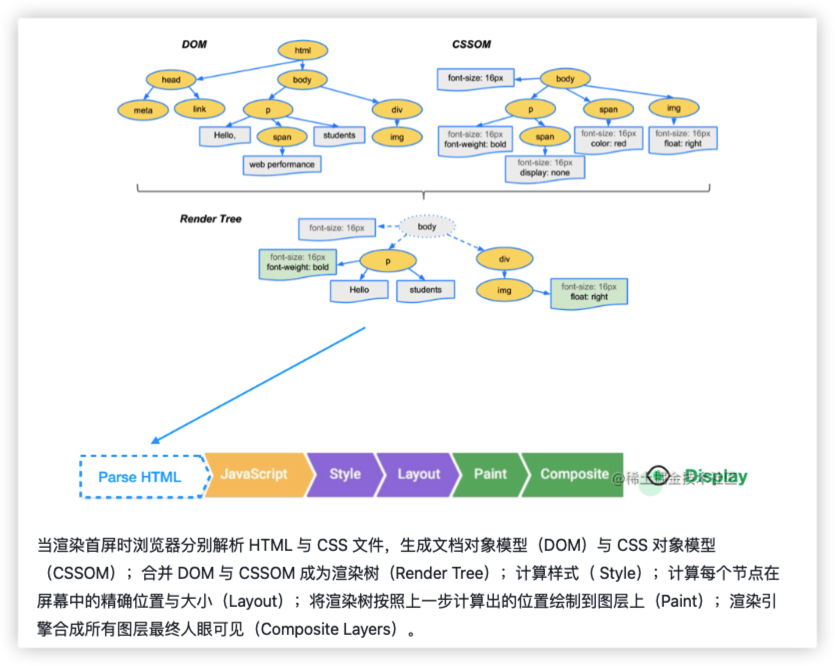
渲染引擎和 JS引擎是两个不同的引擎
- HTML 和 CSS 文件的解析由渲染引擎的 HTML 解析器和 CSS 解析器负责,它们会分别生成文档对象模型(DOM)和 CSS 对象模型(CSSOM)【但是这些 DOM 和 CSSOM 并不能直接被渲染引擎使用的,而是先传递给 JS 引擎】
- JS引擎将它们合并成为渲染树(Render Tree)【将Render Tree传递给渲染引擎】
- 渲染引擎完成Style、Layout、Paint、Composite
所以说,渲染任务是一个特殊的宏任务(因为其需要渲染引擎的参与)
浏览器渲染引擎和 JS引擎都是运行在主线程上的,它们共享主线程资源。因此,如果 JS引擎执行的任务过于耗时,会影响到浏览器渲染引擎的正常工作,从而导致页面卡顿、响应迟缓等问题
补充:使用 v-if 隐藏的 DOM 仍然会被解析并构建成 DOM 树,因此它会影响 Parse HTML 的时间。但是不会影响 Layout 和 Paint 的时间
await是否阻塞
当一个函数含有await关键字时,它将被认为是异步函数,并在遇到await语句时暂停执行异步函数后的代码,等待Promise对象的解析结果。但是,使用await并不会阻塞JS执行线程,。
结论:
await操作并不会阻塞JS线程,但它可以暂停异步函数的执行。当Promise对象解析完成后,事件循环会将await之后的代码放入微任务队列,等待执行,其他的JS代码仍然可以继续执行。直到同步代码执行完毕再去执行微任务队列
举例
如果有一个async函数中包含了await操作,当代码执行到await操作时,这个函数会被暂停,等待await操作所在的Promise对象返回结果。在此期间,JS引擎会在事件循环队列中继续执行其他任务,这些任务可以是其他异步操作的回调函数,也可以是同步代码。
Class
在很长一段时间,我都很排斥面向对象编程的开发方式
可能是由于在我的视角来看,面向过程编程已经能够解决日常开发中遇到的极大多数问题,也有可能是由于我对于面向对象编程本身的理解不到位,也有可能是因为我觉得JS中的面向对象编程是使用原型链来模拟的(其中充斥了一些大坑,甚至兼容性问题)
总之,
- 在我开始接触Dart与TS后
- 看到公司大佬编写的一些工具库源码后
开始愈发的觉得存在既有其必要性,必须要要开始学习了,学如逆水行舟不进则退
所以,这一部分开始,我将尝试学习面向对象编程的这种方式,并希望能应用到项目之中
class中的this指向问题,会逐步在每一部分讲解
类的定义
// 类声明
class Person {}
// 类表达式
const TestPerson = class {}区别:类声明不会有提升现象,使用类表达式如果使用变量var接收,则会出现变量提升
构造函数
类的数据类型就是函数(所以才有函数的prototype属性),类本身指向构造函数
class Person {}
console.log(typeof Person) // function
console.log(Person === Person.prototype.constructor) // true所以,使用new关键字创建一个实例对象,实际会调用类的构造函数constructor
构造函数的this指向创建的实例
class Person {
//构造函数
constructor(name){
this.name=name
}
}
new Person()不定义构造函数时,会默认生成一个空的构造函数
class Person {}
// 等于
class Person {
constructor () {}
}new class的过程
class本质上就是new function的语法糖,下面的过程也与其一致
1、在内存中创建一个新对象
2、这个新对象内部的[[Prototype]]属性,被赋值为构造函数的prototype属性
3、构造函数内部的this被赋值为这个新对象(即this指向新对象);
4、执行构造函数内部的代码(给新对象添加属性);
5、如果构造函数返回非空对象,则返回该对象;否则,返回刚创建的新对象;函数才有prototype属性,因为class底层也是函数,所以也有prototype属性,其值也是一个对象,键名为constructor,值为类的构造函数constructor
class Person {
constructor (name) {
this.name=name
}
}
console.log(Person.prototype); //{constructor: ƒ}如果存在普通成员,则也会加到实例的原型链上,如下:所有Person的实例都可以访问到getName方法。静态成员不会被添加进去,这也是为什么实例不能访问到静态方法的原因
class Person {
constructor (name) {
this.name=name
}
getName(){
console.log(this)
}
static getName(){
console.log(this)
}
}
console.log(Person.prototype) //{constructor: ƒ, getName: ƒ}我们可以在创建函数时,传入初始化的一些参数,new返回的对象会带着这些数据(初始化实例对象)
class Person {
constructor (name,age) {
this.name=name //this指向new创建出的实例对象,即向实例对象添加属性name
this.age=age
}
}
let p = new Person('jack',20)
console.log(p.name,p.age);//jack 20类的普通成员
普通方法:this指向创建的实例,可以用来操作实例对象的数据。
class Person {
constructor (name) {
this.name=name
}
//普通方法,其中this指向创建的实例对象
getName(){
console.log(this)
}
//箭头函数语法
getName=()=>{
console.log(this)
}
//类不是对象,`函数名:`的写法在类里都是错的
getName:()=>{
console.log(this)
}
}
let p = new Person('jack',20)
p.getName() //Person { name: 'tom' }实例对象的属性。可直接通过点语法读写实例属性
class Person {
constructor (name) {
this.name=name
}
}
let p = new Person('jack',20)
//取值
console.log(p.name);//jack
//赋值
p.name='tom'
//取值
console.log(p.name);//tom前面学习对象时,我们直到对象能直接通过点方法完成读写属性,是因为setter和getter。在class中我们可直接定义setter和getter来实现读写的拦截
class Person {
constructor (name) {
this.name=name
}
//属性名
get propName(){
//这里可以做拦截处理
return this.name
}
//属性名
set propName(value){
//这里可以做拦截处理
this.name=value
}
}
let p = new Person('jack',20)
// 读取 (实例.属性名)触发get
console.log(p.propName);//jack
// 赋值 (实例.属性名=xxx)触发set
p.propName='tom'
console.log(p.propName);//tom解构类中的函数,通常我建议不要这样调用函数。但是,这在语法上是成立的,所以这里仍然需要提下这种用法造成的this指向问题
this的调用者是window,但是由于class内部默认严格模式所以是undefined
class Person {
constructor (name) {
this.name=name
}
//普通方法,其中this指向创建的实例对象
getName(){
console.log(this)
}
}
let p = new Person('jack',20)
const {getName} =p
getName() //undefined解决this指向不是当前实例的问题
bind手动修改this指向
利用了创建实例时,构造函数执行的时机,获取方法并bind改变this指向为当前实例,最后赋值回去
jsclass Person { constructor (name) { this.name=name this.getName=this.getName.bind(this) } //普通方法,其中this指向创建的实例对象 getName(){ console.log(this) } } let p = new Person('jack',20) const {getName} =p getName() //Person { getName: [Function: getName], name: 'jack' }箭头函数(类中推荐使用箭头函数)
jsclass Person { constructor (name) { this.name=name } //普通方法,其中this指向创建的实例对象 getName=()=>{ console.log(this) } } let p = new Person('jack',20) const {getName} =p getName() //Person { getName: [Function: getName], name: 'jack' }代理方案(网上抄来的)
jsfunction classProxy (target) { const map = new Map() // 读取拦截配置, 只需要配置 get const hanlder = { get(target, key) { const val = Reflect.get(target, key) // 要获取的是函数执行, 如果不是函数就直接返回 val if (typeof val !== 'function') return val if (!map.has(val)) { // 使用 bind改变运行函数的 this为拦截的实例对象 map.set(val, val.bind(target)) } return map.get(val) } } const proxy = new Proxy(target, hanlder) return proxy } class Person { constructor (text) { this.text = text } getText () { console.log(this.text) return this.text } } const person = classProxy(new Person('test')) const { getText } = person getText() // test
类的静态成员
包括静态变量、方法、块。静态成员是所有实例共享的
静态成员是属于类的,只有静态成员中的this指向当前类
class Person {
//3、静态变量
static school ='默认值'
//1、构造函数、普通方法中的this指向创建的实例对象。只能操作实例数据
constructor (name) {
this.name=name
}
getName(){
return this.name
}
//2、静态方法中的this指向类,所以静态方法能访问其他所有成员,关键的是只要有他能才能操作静态变量
static getThis(){
console.log(this)
//
this.school='这有这里才能访问到静态变量'
}
}
//4、类调用静态方法
console.log(Person.school) //默认值
Person.getThis() //{ school: '默认值' }
//5、实例调用普通方法
let p=new Person()
p.getName()可以看到普通方法、静态方法的this不同,他们只能访问自己this范围内的数据
类的私有成员
构造函数、普通方法在其函数内部可以通过this访问到普通成员、私有成员(静态方法才能访问静态成员)
new class创造的实例仅能通过点操作符访问普通成员,无法访问私有成员
# 语法是ECMAScript 2022(ES12)开始支持
# node16以上版本才支持
# eslint 选指定
module.exports = {
parserOptions: {
ecmaVersion: '12',
},
};class Person {
#school ='默认值' // 私有变量
//1、构造函数,通过this调用私有方法
constructor () {
this.#getThis()
}
f1(){
console.log('普通方法f1')
}
static f2(){
console.log('静态方法f2')
}
//2、私有方法,通过this调用普通方法
#getThis(){
console.log(this) //Person {#getThis: ƒ}。为啥没有f1呢?前面提到过,f1是普通方法,要放在实例对象的[[Prototype]]原型链上
this.f1() //普通方法f
}
}
let p = new Person()继承
通过extends关键字,继承父类的普通成员、静态成员
子类(Child)如果设置了 constructor 方法就必须在函数开始调用 super() ,super()表示父级构造函数,如果父级构造函数需要参数,可以通过super(xxx)传入
本质:new子类时,会调用子类的构造方法,其中的super方法创建一个父级实例,然后把父级实例赋值给this(指向子类的实例),所以子类有了父级的普通成员、静态成员
class Person {
//静态属性
static school ='默认值'
//构造函数
constructor (text) {
console.log('父级构造函数,入参:',text)
}
//普通方法
f1(){
console.log('普通方法f1')
}
//静态方法
static f2(){
console.log('静态方法f2')
}
//私有方法
#f3(){
console.log('私有方法f3')
}
}
//------子类Child-------
class Child extends Person{
constructor(){
super('子类调用')// super(xxx) 相当于父类的构造函数
}
f4(){
super.f2() //super.xxx 调用父类的普通成员、静态成员(私有成员不能调用)
}
}
//1、可调用父类的静态方法
Child.f2()//静态方法f2
//2、可调用父类的普通方法
let c=new Child() //父级构造函数,入参: 子类调用
c.f1()//普通方法f1如果子类没有指定构造函数
class Person {
constructor (text) {
this.text = text
}
}
class Child extends Person {}
const a = new Child('设置 text'); // Child { text: '设置 text' }super还可以调用父级普通方法
//------父类Person-------
class Person {
//普通方法
f1(){
return '普通方法f1'
}
}
//------子类Child-------
class Child extends Person{
constructor(){
super()
}
f4(){
return '通过super调用'+super.f1()
}
}
let c=new Child()
c.f4()'通过super调用普通方法f1'混入
将多个模块代码混入到类中
// 定义一个 Mixin 对象
const Mixin = {
foo() {
console.log('foo');
},
bar() {
console.log('bar');
}
};
// 定义一个类
class MyClass {
constructor() {
// 将 Mixin 合并到当前对象中
Object.assign(this, Mixin);
}
}
// 创建一个实例
const obj = new MyClass();
// 调用 Mixin 中的方法
obj.foo(); // 输出 "foo"
obj.bar(); // 输出 "bar"
JSDocs
JSDoc 注释规则
JSDoc注释一般应该放置在方法或函数声明之前,它必须以/**开始
/**
* JSDoc 注释写在这里
*/变量类型 @type
写在变量前一行,指定变量类型。格式:
/** @type {xxx} */基本类型
指定变量为string类型
/** @type {string} */
var a;
数组类型
/** @type {number[]} */
/** @type {Array<number>} */
/** @type {Array.<number>} */指定对象字面量类型
/** @type {{name:string,age:number}} */
指定函数类型【推荐第一种形式,形参名和类型更加清晰。更推荐@param方式】
//---箭头函数形式,必须指定形参名a、b---
/** @type {(a:number,b:number)=>number} */
var a;
//---function形式,不指明形参,不推荐---
/** @type {function(number,number):number} */
var b;
/** @type {Function} */
var a;
不指定类型默认为any类型,或者手动声明
/** @type {*} */
/** @type {?} */
字面量
/**
* @type {1}
*/
let a;联合类型
/** @type {string|number} */
var a;断言
/**
* @type {number | string}
*/
var numberOrString = Math.random() < 0.5 ? "hello" : 100;
//将numberOrString断言为number类型
var typeAssertedNumber = /** @type {number} */ (numberOrString)参数类型 @param、@callback、@returns
函数形参、返回值注释
/**
* @param {string} p1 参数p1类型为string
* @param {string} [p2] 参数p2类型为string,可选参数
* @returns {string} 返回值类型
*/
function a(p1, p2, p3, p4){
}回调函数注释
/**
* 返回用户信息的回调
* @callback UserInfoCallback
* @param {string} name 姓名
*/
/**
* 获取用户
* @param {UserInfoCallback} cb 回调函数
*/
async function fetchUser (cb) {
const username = await fetch('get/users')
return cb(username)
}使用@typedef 定义对象,有些时候会失效,所以我推荐下面的方式:
/**
* 查询地锁状态
* @param {Object} data
* @param {string} data.connectorId 枪id
* @param {number} data.supplierId 供应商id
* @see [接口文档](http://xxxx)
*/
function getInviteCode(data){};
@typedef、@property
如果类型不是基础类型,而是对象类型(使用@property字段)
/**
* 定义新类型Student
* @typedef {object} Student
* @property {string} Student.name
* @property {number} Student.age
*/
/**@type {Student} */
let a;
/**
* @param {Student} 查询的学生
* @returns {number} 年龄
*/
function getUserAge(stu) {
return stu.age
}@enum
枚举类型,一般配合@readonly使用,因为枚举值正常来说是不能被更改的
/**
* @readonly
* @enum {0|1}
*/
const gender ={
male:0,
female:1
}
/**
* @type {gender.male}
*/
let a;@template
声明泛型
/**
* @template T
* @param {T} x - A generic parameter that flows through to the return type
* @return {T}
*/
function id(x){ return x }@example
/**
* 计算两个数字的和
* @param {number} a - 第一个数字
* @param {number} b - 第二个数字
* @returns {number} 两个数字的和
* @example
* // 示例 1
* const result1 = add(2, 3);
* console.log(result1); // 输出: 5
*
* // 示例 2
* const result2 = add(5, -2);
* console.log(result2); // 输出: 3
*/
function add(a, b) {
return a + b;
}@see
文档url地址
/**
* 领取证书
* @param {Object} data
* @see [接口文档](http://xxxx)
*/案例
/**
* 首页-数据预览接口
* @param {Object} data
* @param {number} data.level 证书等级(1-7)
* @param {string} data.showName 用户昵称
* @returns {string} 返回值类型
* @see [接口文档](http://yapi.yiche.com/project/743/interface/api/74850)
*/
customStatisPreview(data) {
// xxxx
},d.ts文件
JSDoc仅仅可以在鼠标悬浮在变量或者函数时出现提示。但是,并不能在输入时提示字段名
d.ts文件是记录声明与类型关系的文件,编辑器会自动读取这个文件为我们做代码提示
参考:https://m.php.cn/faq/394698.html
模块化规范
模块化概述
EMS
官方的模块化标准,目前浏览器已原生支持、Node环境下也支持
CommonJS
仅Node环境中支持
UMD
Universal Module Definition 通用模块定义,它可以通过运行编译时让同一个代码模块支持EMS、CommonJS
本质就是一个立即执行函数,通过判断是否存在某些全局变量,来使用不同的导出
js(function(root, factory) { if (typeof module === 'object' && typeof module.exports === 'object') { //commonjs模块规范 module.exports = factory(); } else if (typeof define === 'function' && define.amd) { //是AMD模块规范,如require.js define(function(require,exports,module){ //如果要将指定模块名(比如:fpd)挂载到window对象,可以用 \ // root.fpd= factory();}); module.exports = factory();}); } else if (typeof define === 'function' && define.cmd) { //CMD模块规范,如sea.js define(function(require, exports, module) { module.exports = factory() }) } else { //没有模块环境,直接挂载在全局对象上 root.umdModule = factory(root); } }(this, function() { // 方法 function 私有方法名(){}; function 公共方法(){}; //对外暴露的方法 return { 公共方法: 公共方法 } }));IIFE
IIFE打包成一个立即执行函数
js(function foo(){ console.log('立即执行函数') }())较为常见的 SDK 打包方式,项目使用script标签引入后,就会立即执行向window上挂载SDK类
在另一个script标签中增加 new SDK类(配置参数),就可实现加载SDK功能
CommonJS
基础
Node环境中模块内置变量、函数
module 变量
代表当前JS模块,存储当前模块的信息
jsmodule.path // 当前js文件的查找路径 module.exports // 表示当前模块对外输出的接口,其他文件加载该模块,本质就是读取该变量exports 变量
是module.exports的别名
jsvar exports = module.exports;
require 函数
用于引入模块的函数
js// 内置模块 const foo1 = require("http"); // 第三方模块(axios模块需要通过npm安装) const axios = require("axios"); // 文件模块(参数是路径) const foo2 = require("/a.js"); //看后面的 路径分析——>文件定位
加载模块流程
加载内置模块的流程:缓存加载、文件定位、编译执行
加载第三方模块、文件模块的流程:缓存加载、路径分析、文件定位、编译执行
缓存加载
node 为了提高性能,优先从缓存中加载,如果缓存中没有,才会从路径分析、文件定位、编译执行,最后放入缓存中
文件模块:在第一次加载模块后,会把模块编译执行并放在缓存中。从而以后再次加载模块的时候,会直接去缓存中找相应的模块。
内置模块:它在 Node 源代码编译过程中直接编译成了二进制可执行文件,在启动 Node 进程的同时就从内存中加载了核心模块,并缓存起来。所以内置模块的加载跳过了文件定位和编译执行的步骤,并且优先于文件模块加载
路径分析
路径分析主要是对模块标识符分析,根据不同类型的模块标识符使用不同规则分析路径
jsrequire("模块标识符");(1)如果模块标识符为路径(绝对路径、相对路径),比如:
require(./a.js)或者require(./a),会从指定路径寻找(2)如果模块标识符不为路径,比如
require('a.js')、require('a'),就会按照以下的顺序去寻找- 查询当前文件目录下的
node_modules路径 - 查询父级目录下的
node_modules路径 - 查询父级的父级目录下的
node_modules路径 - 一直递归,直到查询到根目录下的
node_modules路径
- 查询当前文件目录下的
文件定位
由于模块标识符的文件后缀可以省略,node 需要知道要查找的模块,到底是一个文件还是一个文件夹(包)
主要分为两个步骤:
文件拓展名分析和目录(包)分析文件拓展名分析
我们使用 require 引入模块的时候,可以不加文件的后缀名。比如:
jsvar foo = require("foo");这个时候 Node 就会进行文件拓展名分析,会依次分析下面三个拓展名:
.js、.node、.json在分析的过程中,Node 会同步阻塞式调用 fs 模块来判断文件是否存在如果查找不到这个文件,那么就会进行目录(包)分析
找到 foo 这个目录(或者叫包)【如何找到?请看上面的路径分析】
- 如果有 package.json 文件,使用 JSON.parse 解析 JSON 对象,找到 name 属性值,如果和模块标识符一样,那就找到 main 字段,这个字段指定了包的入口文件
- 如果没有 package.json 文件,就会在当前目录下依次寻找
index.js、index.node、index.json,如果都不符合条件就抛出异常
编译执行
文件定位无论是
文件拓展名分析还是目录(包)分析,只要成功,最后都会找到一个文件node 根据文件后缀,处理最终定位的文件
.js:通过 fs 模块同步载入后编译执行.node:这是 c/c++编写的拓展文件,需要调用 dlopen()方法来编译.json:通过 fs 模块同步载入后使用 JSON.parse 解析结果- 其余拓展名都被当做 js 文件来处理
导出和引入
使用module.exports导出/引入
module.exports 是 node 提供的一个导出对象
多次导出
//a.js
var a = 1;
var aPlus = function () {
return a++;
};
module.exports.a = a;
module.exports.aPlus = aPlus;批量导出
//a.js
module.exports = {
//对象
fun1() {},
fun2() {},
count: 1,
};引入(多次导出还是批量导出,导出的都是对象,引入的也是整个对象)
//b.js
const obj = require('./a.js');//导入整个对象
console.log(obj.count) //1
const {fun1,fun2,count} = require('./a.js');//解构赋值使用exports导出/引入
在每个 node 模块中,node 提供一个 exports 变量,指向 module.exports。这等同在每个模块头部,有一句代码
var exports = module.exports;使用 exports 时,只能给 exports 添加属性
//a.js
exports.area = 10;
//b.js 引入与前面一样不能直接给 exports 赋值,这种用法是错误的
let count = 1;
exports = count;因为,相当于下面代码。node 实际导出的是 module.exports,exports 存的 count 根本没有导出
var exports = module.exports;
let count = 1;
exports = count;这种形式的 exports 和 module.exports 混用,也是错误的
exports.hello = function () {
return "hello";
};
module.exports = "Hello world";因为等价于下面的代码。
var exports = module.exports;
//
module.exports.hello = function () {
return "hello";
};
//module.exports原本是一个有hello属性的对象,现在变成了字符串
module.exports = "Hello world";注意
为避免导出时出现问题,尽量只使用module.exxports
ESM
基础
每个模块都是单独的私有作用域,模块内部,自动采用严格模式(“use strict”)
ESM 导出的是值的地址,且默认为 const,是不可以修改的,修改操作只在模块内部进行(由于 const 的问题,实际上引用类型,是可以更改的)
js//a.js export let count = 1; export function countPlus() { count++; } export let stu = { name: "jack", age: 18, };js//b.js import { count, stu, countPlus } from "./a.js"; //--可以直接修改引用类型的值-- stu.age++; console.log(stu); //{ name: 'jack', age: 19 } //--模块内部的函数是可以修改,其内部值的-- countPlus(); console.log(count); //2 //--直接修改内部count值报错-- count++; //TypeError: Assignment to constant variable.引入 ESM 模块,模块内的代码就会被被执行
js//a.js console.log("a.js文件中的打印");js//b.js import {} from "./a.js"; //a.js文件中的打印
import 关键字不能直接在作用域种使用
jsif (true) { import { name } from "./module.js"; // 这么写会报错的 } // 动态导入模块就可以解决上面的问题 import("./module.js").then(function (module) { console.log(module); });
导出和引入的方式
引入
// 具名导入(named import)
import { useRef } from "react";
// 命名空间导入(namespace import)
import * as ReactCopy from "react";
// 默认导入(default import)
import React from "react";导出
多值导出
jsexport let count = 1; export function countplus() { count++; console.log(count); } export class Person {}也可以统一在最后导出
jsexport { count, countplus, Person }; //as关键字可以重命名 export { name as myName, hi as hello, Person as People }; // as default是一个特殊名字,相当于把name作为默认导出 export { name as default, hi }; // !!!! 错误语法 : export多值导出的并不是对象,所以切记不能写成下面键值对语法 export { name:11 }引入模块
js//引入某个值 import { xxx } from "yyy"; //引入命名空间,xxx是一个对象,包含所有使用“多值导出”的 import * as xxx from "yyy"; console.log(xxx.name)默认导出(仅导出一个值)
js//默认导出一个对象 export default { } //默认导出一个函数 export default function add(){ }默认导出后不能是语句
js//!!!!报错 export default const add= function(){} // 可以 const add = function(){} export default add引入模块
js//xxx是默认导出的值 import xxx from "yyy";特殊写法(比较少用)
jsimport { name } from "./module.js" import { age } from "./module2.js" export { name age }
重新导出
在一个文件中导入又导出,可以直接这样写:
一般用法是在index文件中把整个npm包需要导出的重新具名导出
// module中如果有具名导出name,通过下面可以再次具名导出
export { name } from "./xxx";
// 从module2拿到默认导出,在改成具名导出NewCar
export { default as NewCar } from './xxx'
export * from './xxx' // 重新导出xxx中的多值导出。不包含default默认导出注意
这两种导出方式其实可以同时使用(并不推荐)
// 多值导出
export const foo = "Hello";
export const bar = "World";
//默认导出
export default { name: "John", age: 30 };引入
// 只能访问到多值导出的内容。 xxx.name是undefined
import * as xxx from "yyy";
console.log(xxx.foo); // "Hello"
console.log(xxx.bar); // "World"
// 使用只能访问到默认导出的内容
import xxx from "yyy";
console.log(xxx.name); // "John"
console.log(xxx.age); // 30补充
在b.js 写引入,查看效果
node b.js会出现提示,按照提示来 就可以了
Warning: To load an ES module, set "type": "module" in the package.json or use the .mjs extension.使用npm init -y生成一个package.json文件,在里面添加
"type": "module"输入 node b.js,重新运行,输出结果
浏览器
HTML 网页中,浏览器可通过<script>标签加载 JS 脚本
同步加载
默认情况下,浏览器是同步加载JS 脚本【渲染引擎遇到<script>标签就会停下来,等到执行完脚本,再继续向下渲染。如果是外部脚本,还必须加入脚本下载的时间】
如果脚本体积很大,下载和执行的时间就会很长,因此造成浏览器堵塞,用户会感觉到浏览器“卡死”了,没有任何响应。
<!-- 页面内嵌的脚本 -->
<script type="application/javascript">
//脚本代码
</script><!-- 外部脚本 -->
<script type="application/javascript" src="脚本地址"></script>**异步加载 **
<script>标签默认为同步加载,只要打开 defer 或 async 属性,脚本就会异步加载【渲染引擎遇到这一行命令,就会开始下载外部脚本,但不会等它下载和执行,而是直接执行后面的命令】
<script src="path/to/myModule.js" defer></script>
<script src="path/to/myModule.js" async></script>defer:要等到整个页面在内存中正常渲染结束(DOM 结构完全生成),才会执行
async:一旦下载完,渲染引擎就会中断渲染,执行这个脚本以后,再继续渲染
注意:如果有多个 defer 脚本,会按照它们在页面出现的顺序,执行脚本;而多个 async 脚本是不能保证按照在页面出现的顺序执行脚本。
使用type属性可开启浏览器原生ESM支持,main.js文件可以使用ESM导出
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<!--html文件是入口,在其中会加载main.js-->
<script src="./main.js" type="module">
import xxx from 'xxx'
</script>
<body></body>
</html>ESM 与 CJS 模块的差异
区别一:运行阶段
CommonJS 本质是加载的是一个对象(即
module.exports属性)require是同步加载代码,运行时动态加载
jsconst cmjExample = require("./a.js");ES6 模块不是对象,它的对外接口只是一种静态定义(语法级别的)
在代码静态解析阶段就可以确定依赖关系(按需加载所需依赖),必须写在文件开头
jsimport esmExample from "./a.js";也可以运行时动态加载,写法必须是下面这样
jsimport('lang/zh.js').then(module) => { /* 获得语言包对象 */ }
区别二:导出值
CommonJS 模块输出的是一个值的拷贝
对于基础类型,修改引入值是不会改变模块原本的值
但是引用类型比较特殊,修改引入的对象会改变模块原本的值
js// a.js module.exports = { count: 1, };不可修改
js// b.js const { count } = require("./a.js"); console.log(count); //1 count=2 // 输出 TypeError: "city" is read-only // c.js const { count } = require("./a.js"); console.log(count); //1可修改
js// b.js const A = require("./a.js"); console.log(A.count); //1 A.count=2 // c.js const A = require("./a.js"); console.log(A.count); //2ESM模块输出的是值的引用
实际测试,居然与cmj是一样的,只有对象能改
js//a.js export let count = 1; //b.js import { count } from "./a.js"; console.log(count); //1 count=2 //b.js import { count } from "./a.js"; console.log(count); //2注意
cmj、esm是一样的,都是导出运行后的结果
下面用cmj举例子,导出的是实例、返回值,无论多少次引入都是同一个值
js// 导出的是实例 class RootApi{ } module.exports=new RootApi() // 导出的是返回值 function f1{ return 111 } module.exports=f1()
区别三:还是导出值
CommonJS 模块除了可以导出JS模块,还能导出JSON文件
ESM模块只能导出JS模块(在使用打包工具时,是因为打包工具会替我们做一层转换,所以才能通过import引入图片、JSON等等)
打包与构建
这块可以参考 Vite 的笔记,这里做一个额外的补充
Tree Shaking
JS 是以模块为单位的,虽然只引入了 Button 组件,但是实际上引入了整个 xxx 模块
import { Button } from 'xxx'; // 这实际上全量导入如果项目中引入了支持Tree Shaking 的打包工具,例如:rollup 。就可以实现仅仅打包引入的函数
参考 rollup 官方提供的 Repl 查看打包结果
果我们自己封装了组件库/工具提供给三方使用,也需要与 Tree Shaking 兼容,才能保证三方用户在打包时能充分利用 Tree Shaking 去除我们组件库/工具中无用代码
ESM 支持
所有模块需要以 ESM 格式发布的,打包工具可以进行静态分析识别哪些代码是真正被使用到的,哪些是可以安全移除的
无副作用声明
在
package.json中,声明"sideEffects": false或者列出具有副作用的具体文件。这帮助打包工具更准确地执行 Tree Shaking,避免意外移除必要的代码优化的导入路径
虽然 Tree Shaking 能进行静态分析去除全量引入中无用的代码,但是仍然推荐使用者直接使用按需加载
js// 全量导入(不推荐) import { Button } from 'element-plus'; // 按需加载(推荐) import Button from 'element-plus/lib/button'; // 或者使用 Babel 插件后 import { Button } from 'element-plus';支持按需加载需要 组件库/工具开发者 进行适配,利用 Bable 实现(这部分可以参考我写的 vite 组件库,后续补充到这里来)
设计模式
参考设计模式
策略模式
https://www.jianshu.com/p/bfa7e289303a
发布订阅模式
EventBus通常是指事件总线系统,可以在不同的组件和模块之间传递事件。它用于解耦不同组件之间的通信,各组件只需要关注自己需要的事件和数据
class EventBus {
constructor() {
this.events = {}; // 存储事件及其对应的回调函数列表
}
// 订阅事件
subscribe(eventName, callback) {
this.events[eventName] = this.events[eventName] || []; // 如果事件不存在,创建一个空的回调函数列表
this.events[eventName].push(callback); // 将回调函数添加到事件的回调函数列表中
}
// 发布事件
publish(eventName, data) {
if (this.events[eventName]) {
this.events[eventName].forEach(callback => {
callback(data); // 执行回调函数,并传递数据作为参数
});
}
}
// 取消订阅事件
unsubscribe(eventName, callback) {
if (this.events[eventName]) {
this.events[eventName] = this.events[eventName].filter(cb => cb !== callback); // 过滤掉要取消的回调函数
}
}
}EventEmitter 是一个 Node.js 中的模块,使用它可以定义和触发事件
class EventEmitter {
constructor() {
this.events = {}; // 用于存储事件及其对应的回调函数列表
}
// 订阅事件
on(eventName, callback) {
this.events[eventName] = this.events[eventName] || []; // 如果事件不存在,创建一个空的回调函数列表
this.events[eventName].push(callback); // 将回调函数添加到事件的回调函数列表中
}
// 发布事件
emit(eventName, data) {
if (this.events[eventName]) {
this.events[eventName].forEach(callback => {
callback(data); // 执行回调函数,并传递数据作为参数
});
}
}
// 取消订阅事件
off(eventName, callback) {
if (this.events[eventName]) {
this.events[eventName] = this.events[eventName].filter(cb => cb !== callback); // 过滤掉要取消的回调函数
}
}
// 添加一次性的事件监听器
once(eventName, callback) {
const onceCallback = data => {
callback(data); // 执行回调函数
this.off(eventName, onceCallback); // 在执行后取消订阅该事件
};
this.on(eventName, onceCallback);
}
}单例模式
目的:维护一个全局实例对象
弹窗(登录框,信息提升框)
全局态管理 store (Vuex / Redux)
1、函数/类实现方案(唯一的实例存在静态成员里)
let Singleton = function (params) {
this.params=params // 这里就是类的构造函数 this指向new Singleton时新创建的对象
}
Singleton.getInstance = function (params) {//静态方法
return this.instance|| (this.instance=new Singleton(params)) //this指向Singleton
}
let res1 = Singleton.getInstance('Winner');
let res2 = Singleton.getInstance('Looser');
console.log(res1) // Singleton { params: 'Winner' }
console.log(res2) // Singleton { params: 'Winner' }
console.log(res1===res2) // trueclass Singleton{
constructor(params){
this.params=params
}
static instance=null
static getInstance(params) {
return this.instance|| (this.instance=new Singleton(params))
};
}
const res1= Singleton.getInstance('Winner')
const res2= Singleton.getInstance('Looser')
console.log(res1) // Singleton { params: 'Winner' }
console.log(res2) // Singleton { params: 'Winner' }
console.log(res1===res2) // true2、闭包实现(唯一的实例存在闭包里)
let CreateSingleton = (function () {
let instance;
return function (name) {
if (instance) {
return instance;
}
this.name = name;
return instance = this;
}
})();
let Winner = new CreateSingleton('Winner');
let Looser = new CreateSingleton('Looser');
console.log(Winner === Looser); // true3、模块化
esm、commonjs导出的对象其实就是单例模式 (全局只有一个)
// a.js
module.exports ={
city:'北京'
}
// b.js
const obj require('./a')
obj.city='上海'
// c.js
const obj require('./a')
console.log(obj.city) //上海如果导出的是个类呢?每个文件引入后,new创建的肯定不是一个实例。所以不能导出类,应该导出实例【用的闭包的方式】
class Location{
//xxxx
}
module.exports = (function () {
let location;
return function () {
if (location) {
return location;
}
location = new Location();
return location;
};
})()();最后
高阶函数包装下,不同的fn返回对象,都是唯一单例
// 定义
var getSingleton = function(fn) {
var ret;
return function() { // arguments 是传入的fn的参数
// apply目的是让fn内的this和funcHandle的指向保证一致,即谁调用funcHandle时的决定
return ret || (ret = fn.apply(this, arguments));
// 如果不使用apply,fn这个函数中的会指向window
//return ret || (ret = fn(arguments));
};
};下面调用例子里,是否使用apply,是没有区别的
var funcHandle = getSingleton(function() {
console.log('this指向',this) // window
return {}
});
var res1 = funcHandle();
var res2 = funcHandle();
console.log(res1 === res2);// true这个例子才有差异
// 使用apply绑定this:this 等于 funHandle 中的this,obj调用的funHandle,所以最后this指向了obj
// 不使用apply绑定this:this 指向 window
let obj={}
obj.funcHandle = getSingleton(function() {
console.log('this指向',this)
});
var res1 = obj.funcHandle();
var res2 = obj.funcHandle();
console.log(res1 === res2);// true这个例子里是否使用apply是返回的都是同一个实例,对我们的主功能无影响,为什么选择使用apply的方案
funcHandle是一个可复用的工具函数,当使用文件A导出funcHandle函数
在其他任何页面调用funcHandle,其中的this都应该指向使用页面中的this
参考:https://juejin.cn/post/7266702105829687354
装饰器模式
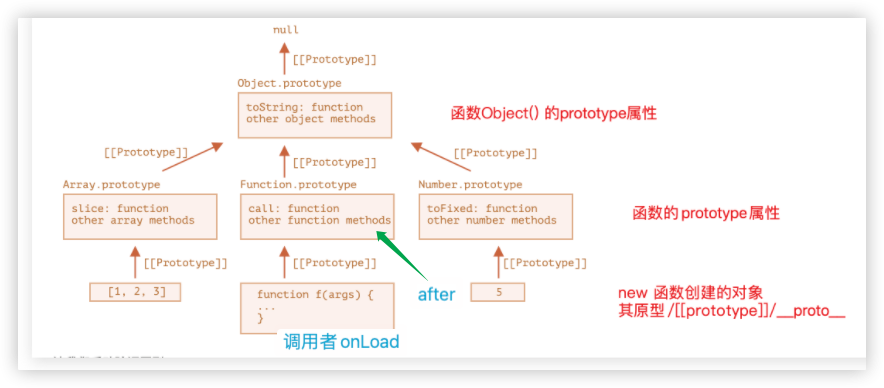
// Function.prototype(看成一个整体), 增加一个after字段
Function.prototype.after = function (fn) {
const _this = this; // 本质是load对象调用了原型链上的after方法,this指向load对象(函数)
return function () { // 这里是<新load函数>可以看下面,该函数直接调用this指向window
// _this指向load,这里是调用load函数执行。arguments是新load函数的入参
_this.apply(this, arguments);
if (fn && typeof fn === 'function') {
fn.apply(this);//
}
};
};
// 函数是Function类的实例,load是一个对象
function load() {
console.log('load')
}
// load对象上没有after属性,所以沿着原型链查找,原型链指向 Function.prototype(看成一个整体),其中有一个after属性
// <返回值是新的load函数>
const load=load.after(() => {
console.log('after')
})
load()新例子
module.exports={
Page(option){
const option.load=option.load.after(() => {
console.log('after')
})
}
}
// 页面 。框架会自动调用
const Api=require('./a.js')
Api.Page({
onLoad(){
// xxx
}
})Dom
HTML结构
<html>
<head></head>
<body></body>
</html>获取顶层节点
<html>是最顶层的 document 节点,通过document.documentElement获取
<body> 通过document.body获取
<head> 通过document.head获取获取其他节点
<html>
<body>
<div>Begin</div>
<ul>
<li>Information</li>
</ul>
<div>End</div>
<script>
//遍历body中的顶层节点
for (let elem of document.body.children) {
console.log(elem); // DIV, UL, DIV, SCRIPT
}
</script>
...
</body>
</html>查找节点
最常见的就是这几个,不常见的这里就不介绍了
document.getElementById 参数是html的id值
document.querySelectorAll()、document.querySelector() 参数是css选择器
element.matches() 参数是css选择器,返回布尔值,表示是否存在该元素
closest() 参数是css选择器,向上查找与 CSS 选择器匹配的最近的祖先,找到则停止搜索并返回该祖先例子1:
<ul>
<li>The</li>
<li>test</li>
</ul>
<ul>
<li>has</li>
<li>passed</li>
</ul>
<script>
let elements = document.querySelectorAll('ul > li:last-child');
for (let elem of elements) {
console.log(elem.innerHTML); // "test", "passed"
}
</script>例子2:
<h1>Contents</h1>
<div class="contents">
<ul class="book">
<li class="chapter">Chapter 1</li>
<li class="chapter">Chapter 2</li>
</ul>
</div>
<script>
let chapter = document.querySelector('.chapter'); // LI
console.log(chapter.closest('.book')); // UL
console.log(chapter.closest('.contents')); // DIV
console.log(chapter.closest('h1')); // null(因为 h1 不是祖先)
</script>创建节点
document.createElement(tag) //用给定的标签创建一个元素节点
document.createTextNode(value) //创建一个文本节点(很少使用)例子
<html>
<head></head>
<body>
</body>
<script>
let divEle=document.createElement('div')
divEle.className='alert' //类名
divEle.innerHTML='hi' //
document.body.append(divEle) //页面中追加创建的div元素
</script>
</html>克隆节点
node.cloneNode(deep) //deep为true,是深克隆;false表示不克隆子元素添加节点
//将节点或字符串插入不同位置:
node.append(...nodes or strings) —— 在 node 内部的末尾 插入节点或字符串,
node.prepend(...nodes or strings) —— 在 node 内部的开头 插入节点或字符串,
node.before(...nodes or strings) —— 在 node 前面 插入节点或字符串,
node.after(...nodes or strings) —— 在 node 后面 插入节点或字符串,
删除节点
node.remove()替换节点
node.replaceWith(...nodes or strings) —— 将 node 替换为给定的节点或字符串页面长度、距离
两个概念:文档、窗口(视口)
Dom元素
注意:属性是否包含 :content、padding、 border、margin、scollbar
offset- 属性
offsetHeight: Dom元素的高、宽。(包含 content+padding+border+scollbar)
常用于做高度展开动画
vue<template> <div class="parent" style="overflow: hidden;transition: 0.4s ;"> <div class="son"> 这里是文案区域 </div> </div> </div> </template> 获取son的offsetHeight,设置parent的高度来实现展开、折叠offsetTop:相对于其最近的定位祖先元素(position)的顶部边缘的距离

client- 属性
- clientHeight:如果没有定义 CSS 或者内联元素其为0,否则表示元素的高(包含 content+padding)
- clientTop:元素上边框的长度
scroll- 属性
scrollHeight:元素内容的高度(包含 content+padding)。如果内容<=元素高度就等于clientHeight,大于就是完整内容高度
scrollTop:这个属性很特殊,是可读、可写的。所以其可以设置滚动位置

getBoundingClientRect方法
元素距离可视区域的距离和宽高
补充:整个页面也可以看成是一个Dom元素。通过document.documentElement获取,也有Dom元素的属性
窗口
- window.innerHeight:窗口的高度
- winodw.scrollY、window.pageYOffset:页面滚动的距离(等价于document.documentElement.scrollTop)

点击事件
点击位置距离其他位置的距离
- event.pageY:点击位置距离文档顶部的距离
- event.clientY:点击位置距离窗口顶部的距离
- event.offsetY:点击位置距离触发事件元素顶部的距离
- event.screenY:点击位置距离屏幕顶部的距离

Canvas
MDN canvasAPI :https://developer.mozilla.org/zh-CN/docs/Web/API/Canvas_API
创建
在canvas标签上指定width、height(单位px),或者获取canvas对象设置width、height属性(单位px)指定的是canvas画布大小。(不设置会初始化宽度为300像素和高度为150像素)
使用CSS指定的是实际可视区大小,canvas画布会被强制拉伸为CSS指定的宽高。(不设置会以canvas画布的大小为可视区域)
Dom创建
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<canvas width="600" height="400" id="canvas"></canvas>
</body>
<style>
</style>
<script>
/** @type {HTMLCanvasElement} */
// 获取canvas对象
const canvas=document.getElementById('canvas')
// 获取context(画笔)对象,可以调用context的各种方法绘制
const context =canvas.getContext('2d')
// 绘制一个填充黑色的矩形
context.fillRect(100, 100, 150, 150)
</script>
</html>JS创建
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body></body>
<script>
const canvas = document.createElement('canvas')
canvas.width = 400
canvas.height = 400
document.body.append(canvas)
const context = canvas.getContext('2d')
context.fillRect(100, 100, 150, 150)
</script>
</html>坐标
canvas获取context后,可以调用context上的方法绘制各种图形、线条
这些方法的参数很多都包含(x,y)坐标
注意下,参数里的坐标都是相对于canvas画布的
线条
使用获取的context对象,来调用它的相关方法绘制
开始、结束路径
context.beginPath() //开始
//。。。绘制一条线段
context.closePath() //结束直线
将起始点、中间点坐标按代码顺序链接起来
context.beginPath() //开始
context.moveTo(100,100) //起始坐标
context.lineTo(300,100) //中间点
context.lineTo(300,300) //中间点
context.closePath() //结束
context.stroke() //绘制线段。这个必须写,且需放置在最后
线段样式
context.lineWidth=50 // 线段宽度,单位px
context.lineCap='round' //线段终点。 默认直角,round为圆角
context.lineJoin='round' //线段连接点。 同上代码
context.beginPath() //开始
context.moveTo(100,100)
context.lineTo(300,100)
context.lineTo(300,300)
context.lineWidth=50
context.lineCap='round'
context.lineJoin='round'
context.closePath() //结束
context.stroke() //绘制线段。这个必须写,且需放置在最后
线段颜色
context.strokeStyle='red' //默认黑色颜色支持 颜色字符串(例如:red)、 十六进制色值、渐变色
渐变色比较复杂,放在最后讲
填充
填充指定区域
前面讲了使用moveTo、lineTo指定点后,最后使用stroke绘制线段
我们也可以使用fill填充点之间的区域,默认黑色
context.moveTo(100,100)
context.lineTo(300,100)
context.lineTo(300,300)
context.fill()
还有一个用于快捷填充矩形区域的函数fillRect
context2.fillRect(矩形左上角x,矩形左上角y,宽,高)注意:无论是stroke还是fill、fillRect都必须写在指定条件之后
填充颜色
与线段可指定颜色一样,填充区域也可以指定颜色
context.fillStyle='red'
圆弧
context.arc(x, y, radius, startAngle, endAngle, anticlockwise);
// x:圆心的 x 坐标。
// y:圆心的 y 坐标。
// radius:圆的半径。
// startAngle:起始角度,以弧度表示 ( 范围 0-2*Math.PI )
// endAngle:结束角度,以弧度表示。
// anticlockwise:一个布尔值,可选参数,表示绘制方向是顺时针还是逆时针。默认是 false,即顺时针。环形进度条

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<canvas width="200" height="200" id="canvas"></canvas>
</body>
<script>
const canvas=document.getElementById('canvas')
const context=canvas.getContext('2d')
context.lineWidth=10
context.strokeStyle='#eee'
context.arc(canvas.width/2,canvas.height/2,50,(3/4)*Math.PI,(2+1/4)*Math.PI,false)
context.stroke()
</script>
</html>渐变色
线段和填充区域都可以使用渐变色,这里为了看的更清楚,在填充区域使用渐变色
线性渐变
const canvas = document.createElement('canvas')
canvas.width = 400
canvas.height = 400
document.body.append(canvas)
const context = canvas.getContext('2d')
//创建渐变色起点(100,100),终点(300,100);
let gradient = context.createLinearGradient(100, 100, 300, 100)//注意:只是渐变色的起点终点,具体线条呈现的颜色取决于它处于渐变对象起点到终点的哪个范围
// 配置渐变色对象,第一个参数0-1之间,0是起点,1是终点。设置渐变开始的位置
gradient.addColorStop(0, 'red')
gradient.addColorStop(1, 'green')
//指定填充区域颜色
context.fillStyle = gradient
//绘制矩形填充区域
context.fillRect(100, 100, 200, 200)
径向渐变
const canvas = document.createElement('canvas')
canvas.width = 400
canvas.height = 400
document.body.append(canvas)
const context = canvas.getContext('2d')
let radialGradient= context.createRadialGradient(200,200,0,200,200,150)//前三个参数是圆1的x坐标、y坐标、半径。后三个是第二个圆的x坐标、y坐标、半径。两个圆
radialGradient.addColorStop(0,'red')
radialGradient.addColorStop(1,'green')
context.fillStyle=radialGradient
context.fillRect(100, 100, 200, 200)
锥形渐变
const canvas = document.createElement('canvas')
canvas.width = 400
canvas.height = 400
document.body.append(canvas)
const context = canvas.getContext('2d')
let conicGradient= context.createConicGradient(0*(Math.PI/180),200,200)//第一个参数是弧度(公式:PI/180*目标度数=目标弧度),中心x坐标、y坐标。
conicGradient.addColorStop(0,'red')
conicGradient.addColorStop(1,'green')
context.fillStyle=conicGradient
context.fillRect(100, 100, 200, 200)
实践:绘制虚线框
用 setLineDash 方法和 lineDashOffset 属性来制定虚线样式。 setLineDash 方法接受一个数组,来指定线段与间隙的交替;lineDashOffset属性设置起始偏移量。
function draw(){
var canvas = document.getElementById('tutorial');
if (!canvas.getContext) return;
var ctx = canvas.getContext("2d");
ctx.setLineDash([20, 5]); // [实线长度, 间隙长度]
ctx.lineDashOffset = -0;
ctx.strokeRect(50, 50, 210, 210);
}
draw();
实践:绘制海报
使用canvas的drawImage方法可以向canvas画布上绘制图片
可多次调用drawImage,达到绘制不同图片叠加的效果,利用这种特性制作海报(后绘制的图层级高)
toDataURL方法可以将canvas导出为base64格式的图片
过程中遇到两个问题
canvas绘制的图片模糊的原因
绘制图像时,会出现加粗
在高分辨率屏幕下(背景网格是实际像素),单位css像素会占据更多的实际像素,且不使用原本的颜色填充,而是使用了某种近似颜色算法
解决:
js// 设备像素比=物理像素/css像素(即1个css像素,占据几个实际像素) const ratio = window.devicePixelRatio || 1; //将canvas尺寸设置为 原本正常尺寸的ratio倍 canvas.width = 315 * ratio; canvas.height = 464 * ratio; // 绘制的内容 宽、高放大为ratio倍 context.scale(ratio, ratio); let imgQrcode = new Image(); imgQrcode.setAttribute("crossOrigin", "anonymous");//解决图片跨域问题 imgQrcode.src = 'https://hedaodao-1256075778.cos.ap-beijing.myqcloud.com/JS/20230423190815%20.png'; imgPost.onload = function () {//图片加载url后,触发 //canvas的确变大了ratio倍, context.drawImage(imgPost,0,0,canvas.width / ratio,canvas.height / ratio);//在canvas容器的(0,0)位置放置图片左上角。裁切长度=canvas.width/ratio,高度=canvas.height/ratio这样尺寸的图片。所以图片是原本的尺寸 }canvas上绘制的图片需要是同源,否则就会报错提示跨域
 js
jslet imgQrcode = new Image(); imgQrcode.setAttribute("crossOrigin", "anonymous"); //设置忽略同源 imgQrcode.src = 'a.png';
生成海报
//创建图片对象,将其改造为同步方式
function loadImageSync(imageUrl) {
let imgPost = new Image();
imgPost.setAttribute('crossOrigin', 'anonymous');
imgPost.src = imageUrl;
return new Promise((resolve, reject) => {
imgPost.onload = function () {
return resolve(imgPost);
};
imgPost.onerror = function () {
return reject(`加载失败,图片资源:${imageUrl}`);
};
});
}
//创建海报。入参是二维码url
export async function createIndexSharePostImage(qrCode) {
const originWidth = 315;
const originHeight = 464;
const canvas = document.createElement('canvas');
canvas.style.display = 'none';
const ratio = (window.devicePixelRatio || 1) * 2;
canvas.width = Math.round(originWidth * ratio);
canvas.height = Math.round(originHeight * ratio);
document.body.append(canvas);
const context = canvas.getContext('2d');
context.scale(ratio, ratio);
let imgPost = await loadImageSync(
'https://hedaodao-1256075778.cos.ap-beijing.myqcloud.com/JS/20230423190645%20.png'
);
let qrCodePost = await loadImageSync(qrCode);
//绘制背景
context.drawImage(imgPost, 0, 0, originWidth, originHeight);
//绘制二维码
context.drawImage(
qrCodePost,
originWidth / 2 - 85 / 2,
originHeight - (52 + 85),
85,
85
);
//转成base64编码的图片
return canvas.toDataURL({
format: 'image/png',
quality: 1,
width: canvas.width,
height: canvas.height,
});
}
下载或保存
下载:目前发现通过a标签下载图片的方式,在PC端正常,而在移动端浏览器上存在兼容性问题。尤其是在微信中会直接弹窗toast提示,不允许下载。
//下载
const link = document.createElement('a');
link.style.display = 'none';
link.href = canvasBase64;
link.setAttribute ('download', 'yc-qrcode.png');
document.body.appendChild (link);
link.click();保存:
移动端各个浏览器均实现了长按保存图片到相册的功能(微信也实现了),所以我们可以在合成海报后,直接使用image组件显示base64格式的图片。用户可以通过长按保存图片
前端数据存储
Cookie
Cookie一般是由服务端在响应请求时,通过设置响应体的头的Set-Cookie字段,浏览器读取后在该域名下设置的键值对(多个键值对使用分号分隔),并存储在前端浏览器中
默认情况下,页面域名、发起请求域名与存储Cookie的主域名相同就能访问到该Cookie
注意:子域名不同也无法访问(但是可以设置domain这个key来改变,后面会讲到)
在 site.com 下设置的Cookie
在 forum.site.com 下不可以被访问协议不同可以访问(可以通过设置secure这个key改变)
http://site.com 下的Cookie
https://site.com 也能访问到端口不同可以访问
发送请求时实现携带Cookie:
前端通过
fetch:同源默认发送,不同源默认不发送;可手动设置withCredentials:"include"发送
xhr:默认withCredentials:false,需手动设置为true
axios :基于xhr的封装,所以同上
服务端也必须设置下面响应头
Access-Control-Allow-Credentials:true前端存储Cookie的限制:
- 一个域名下 存储的Cookie 总数不得超过 20+ 左右(和浏览器自身的限制相关)
- 每个Cookies大小不能超过 4KB
JS操作当前域名下的Cookie:
// 读取当前域名下的Cookie
document.
//该操作只会更新Cookie中的user字段为hedaodao,其他Cookie字段不会被影响
document.cookie = "user=hedaodao";Cookie中默认的一些Key:
通过指定这些Key的值,可以设置浏览器对Cookie的处理方式
path
值是:url 路径,该路径必须是绝对路径,设置后该路径下的页面才可以访问该 Cookie
js//默认值,即该域名下的所有路径都可以访问 path=/ //仅该域名下的/user路径可以访问 path=/userdomain
值是:Cookie的根域名,这个根域名下的子域名都可以访问Cookie。默认情况下,不允许子域访问Cookies(注意:设置IP不行,必须是域名)
jsdomain=site.com 在 site.com 下设置的Cookie 在 forum.site.com 下也可以被访问expires、max-age
设置Cookie的有效期,两个字段设置任意一个即可,Cookie过期后,浏览器自动删除。如果都不设置则在关闭浏览器页面tab后,立即自动删除
expires:过期时间(必须为标准时间),如果这个时间设置的是过去的时间,则浏览器自动删除该Cookie
js//设置过期时间为明天 let date = new Date(Date.now() + 86400e3); //Tue Dec 20 2022 19:50:09 GMT+0800 (中国标准时间) date = date.toUTCString();//'Tue, 20 Dec 2022 11:50:23 GMT' document.cookie = "user=John; expires=" + date;max-age:指明了距离过期的秒数
js//一小时后过期 document.cookie = "user=hedaodao; max-age=3600";secure
设置后,在https域名下设置的Cookie,在http的同域名下不可访问到
jsdocument.cookie = "user=hedaodao; secure";httpOnly
防止XSS攻击
设置后,不可使用
document.cookie来获取当前域名下的Cookie了jsdocument.cookie = "user=hedaodao; httpOnly";samesite
防止 XSRF(跨网站请求伪造)攻击。用于设置从第三方域名跳转到网址A的策略
strict 从邮件链接跳转到网址A,如果是strict,则所有请求都不携带cookie
lax(默认值)可是有时候我们确实会存在从外部营销网址引流到网址A的情况,所以才有了lax。他是在strict的基础上放松了限制
Get 链接会发送 Cookie,跨域的Post、图片、iframe、form表单都不会发送 Cookie
实践案例
安装express
yarn init -y
yarn add express新建app.js,作为服务端设置Cookies
const express = require('express')
const router = express.Router();
const app = express()
//设置header要在路由之前
app.all('*', function(reqest, response, next) {
response.header('Access-Control-Allow-Origin', '*');//解决跨域
response.header('Access-Control-Allow-Credentials','true')
response.header('Access-Control-Allow-Methods','PUT,POST,GET,DELETE,OPTIONS');
next();
});
//路由
router.get('/test',(request,response)=>{
console.log('接口响应',response)
//有一点需要注意:现在都是前后端分离的项目,后端设置cookie要设置domain,domain值得是前端的域名,否则无法自动种在前端域名下
response.cookie('username', 'hedaodao',{ maxAge: 900000,httpOnly:true })
response.json({
data:null
})
})
//挂载路由
app.use(router)
//监听端口
app.listen('8099',()=>{
console.log('启动')
})直接在浏览器访问接口 http://127.0.0.1:8099/test,可以看到成功在该域名下存储了Cookie,且访问时,请求头自动带了Cookie字段

新建index.html(使用VSCode的Live Server插件运行起来),在不同的域名下,请求接口
注意:现在都是前后端分离的项目,后端设置Cookie要设置domain,domain值得是前端的域名,否则无法将接口返回的Cookie自动存储在前端域名下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script>
<script>
axios({
method: 'get',
url: 'http://127.0.0.1:8099/test'
})
</script>
<body>
</body>
</html>sessionStorage、LocalStotage
网页只能访问到当前的 <协议+域名+端口> 下存储的数据,注意:子域名不一致也无法访问
例如: http://www.baidu.com与http://www.yy.baidu.com
sessionStorage
当前页签不关闭就一直存在,页签关闭就会被清楚
如果是window.open打开的页面,也可以访问
sessionStorage.setItem('token', res.data); //如果key存在时,就更新value
sessionStorage.getItem(key) //如果key不存在就返回nullLocalStotage
一直存储,除非清楚浏览器缓存
localStorage.setItem('token', res.data); //如果key存在时,就更新value
localStorage.getItem(key) //如果key不存在就返回null监听缓存
window.addEventListener('storage', () => { ...});
// 或
window.onstorage = () => { ...};前端攻击
XSS(跨站脚本漏洞攻击)
跨站脚本攻击是指攻击者往Web页面里插入恶意JS代码,当用户浏览该页之时,嵌入其中的JS代码会被执行,从而达到恶意攻击用户的目的
例如最常用的手段:新闻详情页面支持评论、展示用户评论的功能,攻击者将JS脚本作为评论提交到服务器,其他用户访问该页面展示该评论时,就会在用户浏览器执行该JS脚本
Cookie的httpOnly字段可以阻止JS获取Cookie,一定程度上防止XSS获取存储用户登录信息的Cookie
XSRF(跨站请求伪造)
跨站请求伪造(Cross-Site Request Forgery)
该攻击手段很大程度上是依赖Cookie来实现的,因为默认情况下,访问A.com时存下的Cookie,在访问A.com相关的数据时,Cookie会被自动携带(请求该域名下的接口也会携带)
用户在访问银行网站bank.com时,存下了Cookie,其中存储了用户信息。在evil.com网站上有一个表单,向bank.com域名下的接口提交表单时,也会自动携带带有用户信息的Cookie,这时候evil.com就能伪装成用户进行非法操作了。这就实现了XSRF攻击

Cookie的samesite字段可以防止XSRF攻击
Web API
Web API的完整列表 其中包含了大量的API,这里仅涉及一些有意思的内容
Intersection
监听指定元素与目标元素之间相交,常用于计算广告曝光相关等业务
文档:https://developer.mozilla.org/zh-CN/docs/Web/API/Intersection_Observer_API
let observer = new IntersectionObserver((entrys)=>{// #listItem元素可能有多个,这个entrys是个数组
entrys.forEach((entry)=>{
// entry.boundingClientRect
// entry.intersectionRatio
// entry.intersectionRect
// entry.isIntersecting // 是否相交。多个entry只处理相交的,可以用这个判断
// entry.rootBounds
// entry.target
// entry.time
})
},
{
root: document.querySelector("#scrollArea"), // 指定元素区域,默认为视口
rootMargin: "0px", // 与css的margin一样,可以设置一个值或者 上、右、下、左。扩展、缩小设置root区域的范围。默认 0px
threshold: 1.0, // 相交的百分比,取值[0,1]之间,默认0。1为目标元素完全进入root区域才触发,可设置数组[0,0.25,0.5,0.75,1]则会触发5次
});
let target = document.querySelector("#listItem");
observer.observe(target);案例:图片懒加载
const observer = new IntersectionObserver((changes) => {
changes.forEach((change) => {
if (change.isIntersecting) {
const img = change.target
img.src = img.dataset.src
observer.unobserve(img)
}
})
})
observer.observe(img)requestAnimationFrame
requestAnimationFrame可以在浏览器下一次重绘之前,调用用户提供的回调函数。
注意:
- 这个函数是一次性的,如果希望每次重绘都触发,必须在回调函数中继续调用requestAnimationFrame
- 回调函数的调用频率通常与显示器的刷新率相匹配。在高刷屏幕上,运行的更快
网络请求相关
请求基础
最开始为了安全,跨源请求是被禁止的
后来,跨源请求被允许了,但是任何新功能都需要服务器明确允许,以特殊的 header 表述。请求被分为了
安全的请求
请求方法为:GET,POST 或 HEAD
请求header为:
AcceptAccept-LanguageContent-LanguageContent-Type的值为application/x-www-form-urlencoded,multipart/form-data或text/plain
非安全的请求
请求方法或请求header不符合上面的
对于非安全的请求浏览器会向服务器先发起一个预检请求(preflight),通过header中的字段告知服务器该请求的新功能,服务器通过返回的header字段告知浏览器是否同意,同意才会真正发起请求
注意浏览器作为一个绝对被信任者参与其中,负责上面的流程
https://zh.javascript.info/fetch-crossoriginURL对象
一般使用字符串,使用qs这个库(https://www.npmjs.com/package/qs),或者当成字符串处理,但是使用URL对象会更加简单
URL对象
protocol以冒号字符:结尾search以问号?开头的一串参数hash以哈希字符#开头- 如果存在 HTTP 身份验证,则这里可能还会有
user和password属性:http://login:password@site.com(图片上没有,很少被用到)

const url=new URL('user/login','https://www.baidu.com')
console.log(url.href) // https://www.baidu.com/user/login
console.log(url.protocol) // https:
console.log(url.port) //空字符串SearchParams:URL的参数对象
append(name, value)—— 按照name添加参数delete(name)—— 按照name移除参数get(name)—— 按照name获取参数(存在有个相同的name,只获取第一个)getAll(name)—— 获取相同name的所有参数(这是可行的,例如?user=jack&user=tom),has(name)—— 按照name检查参数是否存在set(name, value)—— set/replace 参数(如果name已存在,则覆盖)sort()—— 按 name 对参数进行排序(字典排序)
const url=new URL('user/login','https://www.baidu.com')
let searchParams=url.searchParams
searchParams.set('a','1')
searchParams.set('b','2')
searchParams.set('b','3') //重复的后面会覆盖前面的
console.log(url.href) // https://www.baidu.com/user/login?a=1&b=3URL编码
URL中不被允许的字符必须被编码,例如非拉丁字母和空格 —— 用其 UTF-8 代码代替,并加上前缀 %。例如 空格会被编码为%20(由于历史原因,空格也可以用 + 编码,但这是一个例外)
URL对象会自动进行URL编码
XMLHttpRequest
XMLHttpRequest是一个内建的浏览器对象,只能在浏览器环境使用,它允许使用 JavaScript 发送 HTTP 请求
fetch是更新的方法,在浏览器和Node环境中均可以使用,但是fetch无法完成上传进度的跟踪,这里我们主要看下XMLHttpRequest如何实现上传进度的跟踪
//创建对象
let xhr = new XMLHttpRequest()
//配置请求信息
xhr.open('GET','') //xhr.open(method, URL, [async, user, password]) async默认为true表示同步请求,user和password字段在需要HTTP基本身份验证(如果有的话)的请求中使用
xhr.timeout = 2000 //指定超时时间,超时请求就会被取消,并且触发 timeout 事件
xhr.responseType = 'json' //设置服务器响应格式,text字符串,arraybuffer二进制数据,blob二进制数据,json
//设置header
//使用setRequestHeader设置header不会覆盖;xhr.setRequestHeader('X-Auth', '123');xhr.setRequestHeader('X-Auth', '456'); 最后的结果是X-Auth: 123, 456
xhr.setRequestHeader('Content-Type', 'application/json'); //注意:一些header字段是浏览器控制,不允许js设置,前面提到过
//发送请求,参数是请求体,不写则不传递
xhr.send()
//xhr.abort() //终止XHR请求
//xhr的监听事件
xhr.onload = function () {//当请求完成(即使 HTTP 状态为 400 或 500 等),并且响应已完全下载
//status状态码;statusText状态消息,例如状态码200对应ok,404对应Not Found,403对应Forbidden
//请求就会被取消,并且触发 timeout 事件
if (xhr.status != 200) { // 分析响应的 HTTP 状态
console.log(`Error ${xhr.status}: ${xhr.statusText}`); // 例如 404: Not Found
} else { // 显示结果
console.log(`Done, got ${xhr.response.length} bytes`); // response 是服务器响应
}
};
xhr.onerror = function () { // 非 HTTP 错误,断网、URL不存在
console.log(`网络错误`);
};
//下载的监听事件
xhr.onprogress = function (event) { // 定期触发
// event.loaded —— 已经下载了多少字节
// 当服务器发送了 Content-Length header 时,event.lengthComputable = true
// event.total —— 总字节数(如果 lengthComputable 为 true)
if (event.lengthComputable) {
console.log(`Received ${event.loaded} of ${event.total} bytes`);
} else {
console.log(`Received ${event.loaded} bytes`); // 没有 Content-Length
}
};
//上传的监听事件 xhr.upload
xhr.upload.onload = function () { //上传成功完成
console.log(`Upload finished successfully.`);
};
xhr.upload.onerror = function () { //非 HTTP 错误,断网、URL不存在
console.log(`Error during the upload: ${xhr.status}`);
};
xhr.upload.onprogress = function (event) {//上传期间定期触发
// event.loaded —— 已经上传了多少字节
// event.total —— 总字节数
console.log(`Uploaded ${event.loaded} of ${event.total} bytes`);
};
//大文件恢复上传。需要服务器记录接收字节数,前端通过另一个接口拿到,然后使用slice处理完成文件
//xhr.send(file.slice(startByte));XHR实际上还有很多事件:
loadstart—— 请求开始。progress—— 一个响应数据包到达,此时整个 response body 都在response中。abort—— 调用xhr.abort()取消了请求。error—— 发生连接错误,例如,域错误。不会发生诸如 404 这类的 HTTP 错误。load—— 请求成功完成。timeout—— 由于请求超时而取消了该请求(仅发生在设置了 timeout 的情况下)。loadend—— 在load,error,timeout或abort之后触发。
error,abort,timeout 和 load 事件是互斥的。其中只有一种可能发生
fetch
发起请求
fetch法是一个异步方法用来发起网络请求
参数:
- 第一个是url
- 第二个是个对象,用来指定请求时的配置 (更多参数详见:https://zh.javascript.info/fetch-api)
返回值:请求的结果,是一个Promise对象
注意:如果 fetch 无法建立一个 HTTP 请求,例如网络问题,亦或是请求的网址不存在,那么 promise 才会 reject。异常的 HTTP 状态,例如 404 或 500,不会导致出现 error
fetch(url,{
method:'POST',//fetch默认为Get请求。但是可以在第二个参数中使用method字段指定为其他方式
headers:{
//注意:为了保证了 HTTP 的正确性和安全性,有些属性仅由浏览器控制。详见(https://fetch.spec.whatwg.org/#forbidden-header-name)
},
body:'你好' //请求体发送内容。注意:如果值是字符串,则 Content-Type 会默认设置为text/plain;charset=UTF-8;所以,当这里发送json字符串时,记得要设置为application/json
});
let url = 'https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits?per_page=100';
let response = await fetch(url);解析请求结果
fetch返回的响应对象,有很多成员,下面一一介绍
response.ok和response.status
jslet url = 'https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits?per_page=100'; let response = await fetch(url); // 1、response.ok => 如果 HTTP 状态码为 200-299,则为 true if (response.ok) { let json = await response.json(); console.log(json) } else { alert("HTTP-Error: " + response.status); }response.headers
response.headers =>headers不是map对象,但是其有map方法
js//get方法 console.log('response --> ',response.headers.get('Content-Type')) //遍历header for (let [key,value] of response.headers){ console.log('header --> ',key, value) }response.body
body是一个ReadableStream对象,不能直接读取。可以通过以下的异步函数读取其内容
response.text() —— 读取 response,并以文本形式返回response response.json() —— 将 response 解析为 JSON 格式 response.formData() —— 以 FormData 对象的形式返回response response.blob() —— 以 Blob(具有类型的二进制数据)形式返回response response.arrayBuffer() —— 以 ArrayBuffer(低级别的二进制数据)形式返回 response response.body.getReader() —— 获取一个流读取器,可以使用它的read方法来逐块读取body数据(response.body是一个流对象)例子:将response解析为
jslet json =await response.json() console.log('response json --> ',json)例子:通过流读取器读取数据,存储在chunks数组中(每个元素是一个字节类型的数据块)
jsconst reader=response.body.getReader() const totalLength=response.headers.get('Content-Length') //注意:Content-Length字段不一定存在,我们应该检查循环中的 receivedLength,一旦达到一定的限制就将其中断。这样 chunks 就不会溢出内存了。 let receiveLength=0 let chunks = [] //数据 while (true){//在循环中接收响应块(response chunk) const {done,value}=await reader.read() //done为true接收结束,value是接收的字节化块数据,value.length就是当前块数据的长度(单位是字节) if (done){ break; } receiveLength+=value.length console.log(`接收了${receiveLength}bytes/${totalLength}bytes`); //获取下载进度(fetch 方法无法跟踪 上传 进度) chunks.push(value) }将字节类型的数据块转化为需要的类型
js// 如果我们需要的是二进制内容 let blob = new Blob(chunks); // // 如果我们需要的是字符串呢 // 由于没有单个方法可以将每一个块数据串联起来,所以这里需要通过遍历数据按照顺序拼接放置在Uint8Array中 let chunksAll=new Uint8Array(receiveLength) let position=0 for (let chunk of chunks){ chunksAll.set(chunk,position) position+=chunk.length } let res=new TextDecoder('utf-8').decode(chunksAll) //解析字节数据,返回值是文本 console.log(JSON.parse(res)) //转为json数据注意:我们只能选择一种读取 body 的方法,例如:我们已经使用了 response.text() 方法来获取 response,那么如果再用
response.json(),则会提未捕获的rejected错误jsTypeError: Failed to execute 'text' on 'Response': body stream already read终止网络请求
亦可以用来终止Promise操作,Promise原本没有终止的概念
AbortController对象,有abort()方法和signal属性。调用后有abort()后signal属性就变成了true
1、有fetch结合,fetch内部做了处理,当它的第二个配置对象中配置了signal的值后,就会监听这个值。为假就会终止请求
jslet controller=new AbortController() let url = 'https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits?per_page=100'; let response = await fetch(url,{ signal:controller.signal }).catch(err =>{ console.log('err --> ',err) }) controller.abort()2、一般的Promise异步操作,也可以使用
jslet controller=new AbortController() function f(signal){ return new Promise((resolve,reject)=>{ signal.throwIfAborted() //如果signal是终止状态,就会抛出异常。后面就不执行了 setTimeout(()=>{ resolve('执行完毕') },1000) controller.abort() signal.addEventListener('abort',()=>{ reject() }) }) } controller.abort() let res= await f(controller.signal).catch(err =>{ console.log('err --> ',err) }) console.log(res)3、Node中的一些异步函数也类似于fetch函数。例如fs.readFile,fs.writeFile,http.request,https.request 和 timers 以及新版本支持的 Fetch API
jsconst fs = require('fs'); const ac = new AbortController(); const { signal } = ac; fs.readFile('data.json', { signal, encoding: 'utf8' }, (err, data) => { if (err) { console.error(err); return; } console.log(data); }); ac.abort();
长轮询
Long polling,每个一段时间就向服务器发送一个请求,获取最新状态
这种方式,对于服务器是一种负担,所以要注意服务器架构是否能同时在有很多连接的情况下正常工作
async function subscribe() {
let response = await fetch("/subscribe");
if (response.status == 502) {
// 状态 502 是连接超时错误,
// 连接挂起时间过长时可能会发生,
// 远程服务器或代理会关闭它
// 让我们重新连接
await subscribe();
} else if (response.status != 200) {
// 一个 error —— 让我们显示它
showMessage(response.statusText);
// 一秒后重新连接
await new Promise(resolve => setTimeout(resolve, 1000));
await subscribe();
} else {
// 获取并显示消息
let message = await response.text();
showMessage(message);
// 再次调用 subscribe() 以获取下一条消息
await subscribe();
}
}
subscribe().catch(err=>{
console.log('网络错误',err)
})WebSocket
WebSocke可以是客户端和服务端直接建立一条持久化的连接,双方都可以主动发送消息
注意,要打开一个 WebSocket 连接,需要使用特殊的协议 ws 创建 new WebSocket( wss:// 是加密的协议)
express框架使用WebSocket
var express = require("express");
var expressWs = require("express-ws");
var app = express();
expressWs(app); //将 express 实例上绑定 websock 的一些方法
app.ws("/socketTest", function (ws, req) {
ws.send("你连接成功了");
ws.on("message", function (msg) {
ws.send(`这是第二次发送信息,接收到:${msg}`);
});
});
app.listen(3000);
console.log("Listening on port 3000...");浏览器
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="utf-8">
</head>
<script type="module">
let socket = new WebSocket('ws://localhost:9091/socketTest')
socket.onopen=function (e){ //连接已建立
console.log('连接已经建立',e)
socket.send('这里是客户端')
}
socket.onmessage = function (e) {//接收到消息
let message = e.data;
console.log('onmessage事件:',message)
}
socket.onerror=function (e){ //出错
console.log('onerror事件:',e)
}
socket.onclose=function (e){ //关闭websocket
console.log('onclose事件:',e)
}
</script>
<body>
<div style="height:200px;border:red solid 1px;position: relative">
<div style="background-color:red; ">子元素</div>
</div>
</body>
</html>JS高级进阶
闭包封装
简单说,函数中返回一个函数。父函数中的变量不会销毁,如下add每次调用count都会加1
function createAdd(){
let count=0
return function(){
count++
return count
}
}
const add=createAdd()
add() // 1
add() // 2方式1
重要的事情,日常开发用到最多的就是对第三方API、系统的API做封装。这里用一个简单的例子
function createRequest(globalCofing){ // 全局的公用参数,存到闭包中
const {baseUrl} = globalCofing||{}
return function(requestConfig){ // 实际上每个请求用的函数,其内部使用了fetch发起请求
const {url,methed} = requestConfig||{}
return fetch(`{baseUrl}${url}`,{
methed
})
}
}
// 作为闭包存下了baseUrl数据
const request = createRequest({
baseUrl:'xxxx'
})
request({
url:'xxx',
method:'GET'
})方式2
不直接返回函数,而是挂载函数。通过递归收集参数
function sum(...args){
// 闭包,但是不直接返回函数,而是在函数上挂calc函数,再返回
// fn的参数就是sum(1)返回的函数的参数
const fn=(...rest)=>sum(...args,...rest)
// 这里的args就是合并后的。调用calc进行计算
fn.calc=()=> args.reduce((pre,cur)=>pre+cur,0)
return fn
}
console.log(sum(1)(2)(3,7).calc()) // 13柯里化封装
接收一个函数func1,内部返回一个函数,这个函数调用func1
// 任意函数,返回值会被缓存
function slow(x) {
// 这里可能会有重负载的 CPU 密集型工作
console.log(`Called with ${x}`);
return x;
}
// 缓存工具(柯里化,入参是一个函数)
function cachingDecorator(func) {
// 这里是闭包
let cache = new Map();
// 这里的x实际上传给 "入参func的"
return function(x) {
if (cache.has(x)) { // 如果缓存中有对应的结果
return cache.get(x); // 从缓存中读取结果
}
let result = func(x); // 否则就调用 func
cache.set(x, result); // 然后将结果缓存(记住)下来
return result;
};
}
slowWrapper = cachingDecorator(slow) // 这里就是入参func
slowWrapper(1) // 这里是入参func的参数
状态机(FSM)
FSM(finite state machine)
预定义了所有的状态
状态接收变更,完成从状态A转换为状态B的状态转换
以常见的订单状态为例子

不使用状态机
const orderInfo={
status:0 // 0初始值,1创建成功,2已支付
}
// 以取消为例子
functin cancelOrderPay(){
if(是否已支付){
// 这里做大量的逻辑,来重置订单
// 这些逻辑都需要判断各种状态是否符合要求,再执行
}
}使用状态机


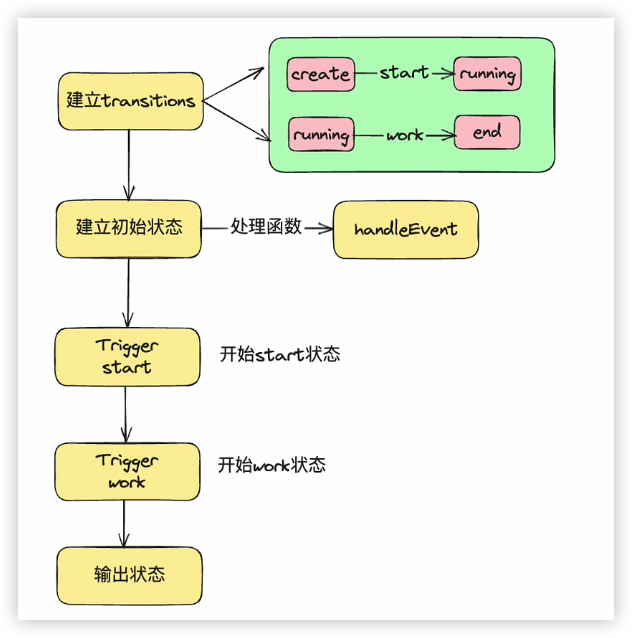

fsm的Go包:https://pkg.go.dev/github.com/looplab/fsm
JS包:https://github.com/jakesgordon/javascript-state-machine
Node
路径
node中所有接收路径作为参数的函数,如果传入相对路径,默认都是会和process.cwd()做拼接
fs.readFileSync('./data')我们可以在不同的目录执行同一个index文件,process.cwd()表示的是当前路径。这样会导致执行同一个文件,但是其中入参路径是根据执行目录而变化的
node ~/Document/test/index.js
node index.js所以,我们推荐node中凡是传入路径的,都是使用resolve
一般分为下面两种情况
__dirnamejs// path.resolve 拼接两个路径,最后返回一个绝对路径 // __dirname表示的是当前文件所在目录 // 使用resolve入参路径,不会随着执行目录变化 const path =require('path') fs.readFileSync(path.resolve(__dirname,'./data'))process.cwd()执行脚本时,所在的目录该目录会随着,执行脚本做在目录而变化,一般情况下并不实用。但是,有一种情况很有用,那就是执行目录不变。
如果你的程序是作为npm包发布的,例如:
vite.config.js中引入的插件,所有插件安装位置都在node_module中,vite.config.js调用插件函数,只有用
process.cwd()才能准确定位到项目根目录的vite.config.js文件,方便插件来操作项目下的其他文件jsconst path =require('path') fs.readFileSync(path.resolve(process.cwd(),'./data'))现在推荐使用ESM模块化规范, 浏览器环境没有
__dirname,但是浏览器、node 中都支持 import.meta.url其作用是获取当前模块的路径( file:///xxx/xxx/xxx.js)如果真的需要在 node 环境中模拟
__dirname,可以使用下面方式jsimport { fileURLToPath } from 'url'; const __filename = fileURLToPath(import.meta.url); // 把 file 协议的路径转化为绝对路径 const __dirname = dirname(__filename); // 如果需要获取特定路径。比如在根目录模块中使用下面代码,可定位到 src 目录下 const targetPath = url.fileURLToPath(new URL("./src", import.meta.url))
文件
fs.readFileSync、**fs.writeFileSync ** 读写文件
const mainJS=fs.readFileSync(path.resolve(__dirname,'./main.js'),{ encoding: 'utf8' })
fs.writeFileSync(path.resolve(__dirname, '../data/audio.ass'), data)读不存在的目录、文件会报错
写不存在的目录会报错,写不存在的文件会新建一个文件后写入,如果同名文件存在,默认会覆盖原有文件内容
文件存在时不希望覆盖原有内容,可以先使用fs.exists()或fs.promises.access()(推荐使用,因为fs.exists()已被废弃)来检查文件是否存在,然后决定是否写入或以追加模式写入。例如,使用追加模式(a)写入内容而不覆盖原文件:
判断目录不存在,创建目录
const { existsSync, mkdirSync } = require("fs");
if (!existsSync(filePath)) {
mkdirSync(filePath,{ recursive: true });
}文件流
https://juejin.cn/post/7190563380900397117fs.readdirSync 读取目录下的目录名+文件名(仅仅返回第一层级)
const resArr=fs.readdirSync(path.resolve(__dirname,'./src'))
// [ 'assets', 'components', 'test.js' ]如果目录不存在,会直接报错
//可以判断文件、目录是否存在
const isExist = existsSync(path.join(rootAbsPath, './dist'));
if (isExist) {
console.log('删除dist目录...'); //包括dist及其子目录
process.execSync(`rm -rf dist`, {
cwd: rootAbsPath,
});
}fs.statSync 获取指定路径的文件夹、文件的描述信息
let statInfo=fs.statSync(path.resolve(__dirname,'./src/test.js'))查看test文件,返回的结构
statInfo Stats {
dev: 16777220,
mode: 16877,
nlink: 3,
uid: 503,
gid: 20,
rdev: 0,
blksize: 4096,
ino: 154375193,
size: 96,
blocks: 0,
atimeMs: 1689610080350.9265,
mtimeMs: 1689610078085.3977,
ctimeMs: 1689610078085.3977,
birthtimeMs: 1689609893659.2727,
atime: 2023-07-17T16:08:00.351Z,
mtime: 2023-07-17T16:07:58.085Z,
ctime: 2023-07-17T16:07:58.085Z,
birthtime: 2023-07-17T16:04:53.659Z
}判断是否为目录
statInfo.isDirectory() //返回布尔值目录
mkdir
只能创建一层目录
// 从 Node.js v10.12.0 开始,支持递归创建多级目录
fs.mkdirSync('path/to/new/directory', { recursive: true });执行Shell命令
同步:child_process.execSync(command[, options])
异步:child_process.exec(command[, options][, callback])
Node会新开一个子线程调用shell命令
var process = require('child_process');
process.exec('shell命令', function(err, stdout, errout){
// err是执行结果,是否有错
// stdout是标准输出,即shell命令执行后的结果
// errout是错误输出
});var process = require('child_process');
let res=process.exec('shell命令',{
encoding: 'utf-8', //指定编码方式,res才会输出string
cwd:'执行命令所在的路径' //默认工作路径为运行脚本所在的路径
});同步方式
execSync(`git log -1 HEAD --pretty='%s'`,{
encoding: 'utf-8',
cwd:'执行命令所在的路径'
})全局捕获Error
process.on('uncaughtException', function (err) {
console.error('捕获到全局异常:', err.message);
});
process.on('unhandledRejection', function (err) {
console.error('捕获到全局 Promise 异常:', err.message);
})网络与浏览器
Http与Https
HTTP是超文本传输协议,HTTP的初衷是为了提供一种发布和接收HTML页面的方法。
HTTPS使用的主要目的是提供对网站服务器的身份认证,同时保护交换数据的隐私与完整性。
TLS是传输层加密协议,前身是SSL协议,由网景公司1995年发布,有时候两者不区分。
HTTP
HTTP/1.0、HTTP1.1
HTTP/2
基于TCP协议
在HTTP/1的基础上增加了 多路复用(多请求可以复用一个TCP连接)、服务器推送、头信息压缩、二进制分帧
HTTP/3
基于QUIC协议
HTTP/2使用TCP协议+多路复用,所以当多个请求复用一个TCP时,如果某个请求出现丢包,由于TCP的滑动窗口,会一直等待丢失的包重传,导致多个请求受阻。所以提出来HTTP/3
V8引擎内存机制
JS 引擎中对变量的存储主要有两种位置,栈内存和堆内存,栈内存存储基本类型数据以及引用类型数据的内存地址,堆内存储存引用类型的数据

- 栈内存的回收:栈内存调用栈上下文切换后就被回收,比较简单
- 堆内存的回收:V8 的堆内存分为新生代内存和老生代内存,新生代内存是临时分配的内存,存在时间短,老生代内存存在时间长

新生代内存回收机制:
新生代内存容量小,64 位系统下仅有 32M。新生代内存分为 From、To 两部分,进行垃圾回收时,先扫描 From,将非存活对象回收,将存活对象顺序复制到 To 中,之后调换 From/To,等待下一次回收。
老生代内存回收机制:
- 晋升:如果新生代的变量经过多次回收依然存在,那么就会被放入老生代内存中
- 标记清除:老生代内存会先遍历所有对象并打上标记,然后对正在使用或被强引用的对象取消标记,回收被标记的对象
- 整理内存碎片:把对象挪到内存的一端
为什么限制内存大小?
1、够用了,js设计的初衷是浏览器脚本语言,只执行一次,便释放内存
2、如果不限制,回收一次100MB的内存大概花费3ms,V8引擎在回收垃圾时,是暂停住所有代码的执行,一旦垃圾过多,在回收内存的时候,中断的时间过长,体验不佳。
新生代内存:保存新变量,存活时间短的 老生代内存:保存老变量,存活时间长的(老变量:经过几次垃圾回收也没有被杀死的变量)
新生代变量晋升老生代变量的条件:①这个变量经历过内存回收,当未被回收 ②新生代内存空间一旦超过占用临界值,①中的变量就会被移到老生代内存中 新生代内存特点:内存回收频率快,因为频率快,所以要求回收这个动作要快,即持续时间短,所以采用了牺牲空间换取时间的算法。
新生代内存回收机制
 假设所有新变量都存在From中,那么在回收的过程中,会先标记活变量,将活着的变量全部复制到To当中,清空From,第二次回收时,标记活变量,将活着的变量全部复制到From当中,清空To 也就是:标记-复制-清空的过程 老生代内存回收机制 假设在内存中有一片连续的区域:1,2,3,4,5 此时2,4死亡,标记并删除后,内存变为:1,-,3,-,5 这时内存空间会不连续,也就是所谓的内存碎片,如果不进行修补,有可能会放不进数组,因为在数据结构中,数组中的元素是储存在内存中的连续一片地址中的。所以在V8引擎中,老生代内存在标记-删除之后,还要进行一次排列,整理内存碎片。 标记死亡变量,删除死亡变量,整理内存空间 也就是标记-删除-整理的过程
假设所有新变量都存在From中,那么在回收的过程中,会先标记活变量,将活着的变量全部复制到To当中,清空From,第二次回收时,标记活变量,将活着的变量全部复制到From当中,清空To 也就是:标记-复制-清空的过程 老生代内存回收机制 假设在内存中有一片连续的区域:1,2,3,4,5 此时2,4死亡,标记并删除后,内存变为:1,-,3,-,5 这时内存空间会不连续,也就是所谓的内存碎片,如果不进行修补,有可能会放不进数组,因为在数据结构中,数组中的元素是储存在内存中的连续一片地址中的。所以在V8引擎中,老生代内存在标记-删除之后,还要进行一次排列,整理内存碎片。 标记死亡变量,删除死亡变量,整理内存空间 也就是标记-删除-整理的过程
**总结:**新生代内存:标记-复制-清空(省时,费空间) 老生代内存:标记-删除-整理
内存回收时机
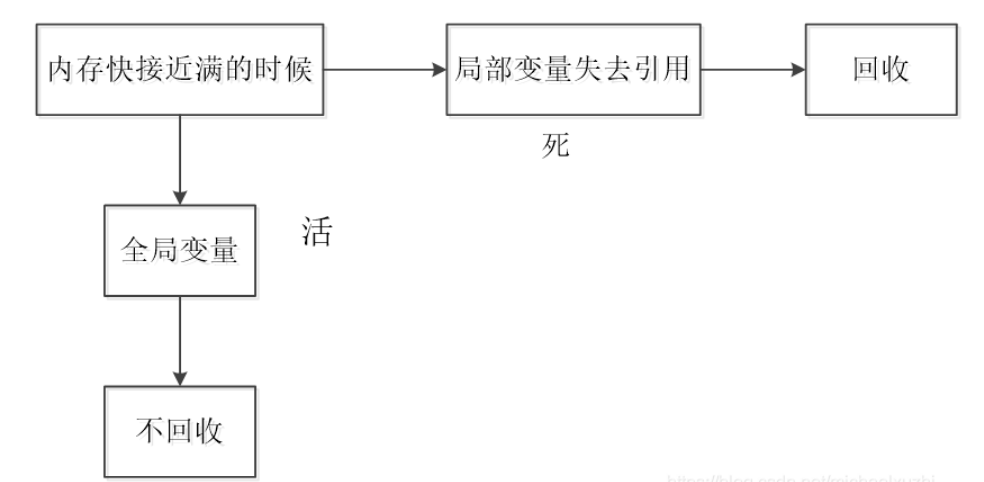
在内存占用接近临界值的时候,开始回收内存 全局变量:只在程序执行完成才会被回收,否则永久保留
http状态码
1开头 代表请求已被接受,需要继续处理。这类响应是临时响应
2开头 (请求成功)
200 (成功) 服务器已成功处理了请求。
3开头 (请求被重定向)
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
304 协商缓存
4开头 (请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
401 Unauthorized, 表示未经授权
403 forbidden,表示对请求资源的访问被服务器拒绝
404 not found,表示在服务器上没有找到请求的资源
5开头(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。 501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。 502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。 503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。 504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。 505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
浏览器静态资源缓存
强缓存
服务端主动在respone header里面通过字段通知浏览器需要进行缓存的方式 respone header 的cache-control字段,常见的值有max-age, public ,private ,no-cache ,no-store等
如下图respon header中,cache-control:max-age=31536000,public,immutable

max-age表示缓存的时间是31536000秒(1年)
public表示可以被浏览器和代理服务器缓存,代理服务器一般可用nginx来做。
immutable表示该资源永远不变,但是实际上该资源并不是永远不变,它这么设置的意思是为了让用户在刷新页面的时候不要去请求服务器!如果你只设置了cahe-control:max-age=31536000,public 这属于强缓存,每次用户正常打开这个页面,浏览器会判断缓存是否过期,没有过期就从缓存中读取数据;但是有一些用户会点击浏览器的刷新按钮去刷新页面,这时候就算资源没有过期,浏览器也会直接去请求服务器,这就是额外的请求消耗了,这时候就相当于是走协商缓存的流程了。如果cahe-control:max-age=315360000,public再加个immutable的话,就算用户刷新页面,浏览器也不会发起请求去服务,浏览器会直接从本地磁盘或者内存中读取缓存并返回200状态,看上图的红色框(from memory cache)
总结
cache-control: max-age=xxxx,public 客户端和代理服务器都可以缓存该资源;客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,如果用户做了刷新操作,就向服务器发起http请求
cache-control: max-age=xxxx,private 只让客户端可以缓存该资源;代理服务器不缓存。客户端在xxx秒内直接读取缓存,statu code:200
cache-control: max-age=xxxx,immutable 客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,即使用户做了刷新操作,也不向服务器发起http请求
cache-control: no-cache 跳过设置强缓存,但是不妨碍设置协商缓存;一般如果你做了强缓存,只有在强缓存失效了才走协商缓存的,设置了no-cache就不会走强缓存了,每次请求都回询问服务端。
cache-control: no-store 不缓存,这个会让客户端、服务器都不缓存,也就没有所谓的强缓存、协商缓存了。
协商缓存
客户端主动请求资源,如果服务端发现该静态资源未发生变化,则直接返回304,客户端使用缓存的静态资源。如果发生变化,返回新的静态资源
怎么设置协商缓存?
response header里面的设置etag和last-modified两个字段
etag: '5c20abbd-e2e8'
last-modified: Mon, 24 Dec 2018 09:49:49 GMTetag:每个文件有一个,改动文件了就变了,就是个文件hash,每个文件唯一
last-modified:文件的修改时间,精确到秒
也就是说,每次请求返回来 response header 中的 etag和 last-modified,在下次请求时在 request header 就把这两个带上,服务端把你带过来的标识进行对比,然后判断资源是否更改了,如果更改就直接返回新的资源,和更新对应的response header的标识etag、last-modified。如果资源没有变,那就不变etag、last-modified
协商缓存流程
服务端发现资源没有改变的时候,会走如下流程:
发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否改变(通过对比 etag)-->没改变->返回304状态码-->客户端用缓存的老资源。
服务端发现资源改变的时候,会走如下流程:
发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否改变(通过对比 etag)-->改变-->返回200状态码-->客户端如第一次接收该资源一样,记下它的cache-control中的max-age、etag、last-modified等。
总结
请求资源时,把用户本地该资源的 etag 同时带到服务端,服务端和最新资源做对比。 如果资源没更改,返回304,浏览器读取本地缓存。 如果资源有更改,返回200,返回最新的资源。
补充
response header中的etag、last-modified在客户端重新向服务端发起请求时,会在request header中换个key名:
// response header
etag: '5c20abbd-e2e8'
last-modified: Mon, 24 Dec 2018 09:49:49 GMT
// request header 变为
if-none-matched: '5c20abbd-e2e8'
if-modified-since: Mon, 24 Dec 2018 09:49:49 GMT为什么要有etag? 你可能会觉得使用last-modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要etag呢?HTTP1.1中etag的出现(也就是说,etag是新增的,为了解决之前只有If-Modified的缺点)主要是为了解决几个last-modified比较难解决的问题:
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新get;
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),if-modified-since能检查到的粒度是秒级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
某些服务器不能精确的得到文件的最后修改时间。
跨域
浏览器的同源策略:同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互。
**同域的概念:**简单的解释就是相同域名,端口相同,协议相同
| 当前网页URL地址:study.cn/json/jsonp/jsonp.html | ||
|---|---|---|
| 请求地址 | 形式 | 结果 |
| http://study.cn/test/a.html | 同一域名,不同文件夹 | 成功 |
| http://study.cn/json/jsonp/jsonp.html | 同一域名,统一文件夹 | 成功 |
| http://a.study.cn/json/jsonp/jsonp.html | 不同域名,文件路径相同 | 失败 |
| http://study.cn:8080/json/jsonp/jsonp.html | 同一域名,不同端口 | 失败 |
| https://study.cn/json/jsonp/jsonp.html | 同一域名,不同协议 | 失败 |
跨域:
浏览器对于javascript的同源策略的限制,例如a.cn下面的js不能调用b.cn中的js,对象或数据(因为a.cn和b.cn是不同域),所以就出现了跨域的概念
跨域的解决方案
JSONP
**核心思想:**Web 页面上直接使用Ajax受到同源策略的影响。但是,通过
<script>调用js文件不受浏览器同源策略的影响,所以通过 Script 便签可以进行跨域的请求。通过script标签加载JS脚本,在JS脚本中发起请求**优点:**简单适用,兼容性好(兼容低版本IE)
**缺点:**只支持get请求,不支持post请求。它只支持跨域 HTTP 请求这种情况,不能解决不同域的两个页面或 iframe 之间进行数据通信
**过程:**网页通过添加一个
<script>元素,向服务器请求 JSON 数据,服务器收到请求后,将数据放在一个指定名字的回调函数的参数位置传回来。例子:
前端
js// 拼接url的 function stringify (data) { const pairs = Object.entries(data) const qs = pairs.map(([k, v]) => { let noValue = false if (v === null || v === undefined || typeof v === 'object') { noValue = true } return `${encodeURIComponent(k)}=${noValue ? '' : encodeURIComponent(v)}` }).join('&') return qs } function jsonp ({ url, onData, params }) { const script = document.createElement('script') // 一、为了避免全局污染,使用一个随机函数名 const cbFnName = `JSONP_PADDING_${Math.random().toString().slice(2)}` // 二、默认 callback 函数为 cbFnName script.src = `${url}?${stringify({ callback: cbFnName, ...params })}` // 三、使用 onData 作为 cbFnName 回调函数,接收数据。JSONP回调函数必须挂载到全局 window[cbFnName] = onData; document.body.appendChild(script) }服务
jsconst http = require('http') const url = require('url') const qs = require('querystring') const server = http.createServer((req, res) => { const { pathname, query } = url.parse(req.url) const params = qs.parse(query) const data = { name: 'shanyue', id: params.id } if (params.callback) { str = `${params.callback}(${JSON.stringify(data)})` res.end(str) } else { res.end() } }) server.listen(10010, () => console.log('Done'))CORS
CORS是一个 W3C 标准 ,全称是跨域资源分享(Cross-Origin Resource Sharing),它允许浏览器向跨源服务器,发出 XMLHttpRequest 请求,从而克服了 Ajax 只能同源使用的限制。实现 CORS 通信的关键是服务器。只要服务器实现了 CORS 接口,就可以跨源通信。
CORS 的优缺点:使用简单方便,更为安全;支持 POST 请求方式;CORS 是一种新型的跨域问题的解决方案,存在兼容问题,仅支持 IE 10 以上
1、普通跨域请求:只需服务器端设置Access-Control-Allow-Origin
2、带cookie跨域请求:前后端都需要进行设置
javascript//前端axios axios.defaults.withCredentials = truejavascript//后端Node.js var http = require('http'); var server = http.createServer(); var qs = require('querystring'); server.on('request', function(req, res) { var postData = ''; // 数据块接收中 req.addListener('data', function(chunk) { postData += chunk; }); // 数据接收完毕 req.addListener('end', function() { postData = qs.parse(postData); // 跨域后台设置 res.writeHead(200, { // 后端允许发送Cookie 'Access-Control-Allow-Credentials': 'true', // 允许访问的域(协议+域名+端口) 'Access-Control-Allow-Origin': 'http://www.domain1.com', /* * 此处设置的cookie还是domain2的而非domain1,因为后端也不能跨域写cookie(nginx反向代理可以实现), * 但只要domain2中写入一次cookie认证,后面的跨域接口都能从domain2中获取cookie,从而实现所有的接口都能跨域访问 */ 'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly的作用是让js无法读取cookie }); res.write(JSON.stringify(postData)); res.end(); }); }); server.listen('8080'); console.log('Server is running at port 8080...');Server Proxy
即,服务器代理,当你需要有跨域的请求操作时发送请求给后端,让后端帮你代为请求,然后最后将获取的结果发送给你。
假设有这样的一个场景,你的页面需要访问https://cnodejs.org/api/v1/topics,当时因为不同域,所以你可以将请求后端,让其对该请求代为转发。
代码如下:
jsconst url = require('url'); const http = require('http'); const https = require('https'); const server = http.createServer((req, res) => { const path = url.parse(req.url).path.slice(1); if(path === 'topics') { https.get('https://cnodejs.org/api/v1/topics', (resp) => { let data = ""; resp.on('data', chunk => { data += chunk; }); resp.on('end', () => { res.writeHead(200, { 'Content-Type': 'application/json; charset=utf-8' }); res.end(data); }); }) } }).listen(3000, '127.0.0.1'); console.log('启动服务,监听 127.0.0.1:3000');通过代码你可以看出,当你访问 http://127.0.0.1:3000 的时候,服务器收到请求,会代你发送请求https://cnodejs.org/api/v1/topics 最后将获取到的数据发送给浏览器。
DNS
用户访问网站的过程
从浏览器打开http://www.baidu.com地址回车发送请求到看到页面的过程:
主要分成 两个 步骤:
第一步:DNS服务器将域名解析成IP
具体来说:
- 客户端用户从浏览器输入 www.baidu.com 网站网址后回车后,浏览器会查询浏览器缓存,查找是否存在网址对应的IP解析记录。如果有,就直接获取到IP地址,然后访问网站;
- 如果浏览器缓存没有该记录,则在操作系统缓存即本地hosts文件中查找对应的IP;
- 如果还是没有,则将查询请求发给路由器,查看路由器缓存里是否有该IP地址的缓存;
- 如果依然没有,向本地域名服务器(Local DNS:一般是网络服务提供商,比如电信,移动,联通服务商)发出请求,获取IP;
- 以上都失败的话,LDNS会从DNS系统的“.”根开始(根域名服务器)请求www.baidu.com域名的解析,经过一系列的查找各个层次DNS服务器,最终会查找到www.baidu.com域名对应的授权DNS服务器,而这个授权DNS服务器,正是该企业购买域名时用于管理域名解析的服务器。这个服务器有www.baidu.com对应的IP解析记录,如果此时都没有,就表示企业的运维人员么有给www.baidu.com域名做解析;
- LDNS把收到来自授权DNS服务器关于www.baidu.com对应的IP解析记录发给客户端浏览器,并且在LDNS本地把域名和IP的对应解析缓存起来,以便下一次更快的返回相同的解析请求的记录;
第二步:客户端浏览器获取到了www.baidu.com的对应IP地址,接下来浏览器会请求获得的IP地址对应的Web服务器,Web服务器接收到客户的请求并响应处理,将客户请求的内容返回给客户端浏览器;
暂未分类
节流防抖:
https://segmentfault.com/a/1190000018428170
防抖:第一次触发后,在delay内再次再次触发会重新计时
function debounce(fn,delay){
let timer = null //借助闭包
return function() {
if(timer){
clearTimeout(timer)
}
timer = setTimeout(fn,delay) // 简化写法
}
}节流:第一次触发后,在delay内再次触发无效,在delay时间后执行函数fn
function throttle(fn,delay){
let valid = true
return function() {
if(!valid){
//休息时间 暂不接客
return false
}
// 工作时间,执行函数并且在间隔期内把状态位设为无效
valid = false
setTimeout(() => {
fn()
valid = true;
}, delay)
}
}解惑
1、基本类型的属性和方法
为什么基本类型,会有.操作符
我们常听说的两句话:1.JS 中全都是对象呢 ;2.JS 中对于基本类型,变量只存储值 ;对于引用类型,变量存储地址,实际其存储在堆中。
看完这两句,会不会有些疑惑,
如果 1 成立,那基本类型的变量也应该是对象,变量应该也是存储堆的地址,为什么说只存储其值
如果 2 成立,基本类型的变量,只存储一个值,为什么有对象中才有的属性
看下面代码,变量 a 为 int 型,是基本类型,有属性 length,有方法 toUpperCase()
let str = "hello";
console.log(str.length); //5
console.log(str.toUpperCase()); //HELLO答:
JS 中的数据类型分两大类,基本类型(或者说是原始类型)和引用类型。基本类型的值是保存在栈内存中的简单数据段,共有五种,按值访问,分别是undefined、 null、 boolean、 number、 string;而引用类型的值则是保存在堆内存中的对象,按引用访问,有 Object 、Array 、Function以及其他内置的类型,比如RegExp、Date、Math等,
其实 JS 中,还有三种特殊的引用类型 Boolean、、Number 、String ,方便我们操作与其对应的基本类型,而它们就是基本包装类型。当在尝试调用类的方法或属性之前,一直使用原始数据类型。如果调用类的方法或属性,JS 会在幕后为字面量值创建一个包装器对象,以便将该值视为一个对象。调用完成后,JS 即抛弃包装器对象
变量 str 作为一个基本类型变量是没有 length 属性的,但是它的基本包装类型 String 有啊,当调用对象的 length 属性时,会使用new String("hello")自动创建一个对象,然后再调用 length 属性,返回值后,销毁这个对象。调用 toUpperCase()方法同理
let str = "hello";
console.log(str.length); //5
//等价于
var str = "string";
var _str = new String(str);
var len = _str.length;
_str = null;
console.log(len); //5活学活用:
var str = "string";
//给包装类创建的对象添加属性pro,然后销毁
str.pro = "hello";
//再次创建新的类,已经没有pro属性了
console.log(str.pro + "world"); //undefinedworldJS 最佳实践总结
最佳实践的核心目标:
- 代码简洁优雅
- 足够健壮,对于异常/错误输入有一定的承受能力
schme实现方案(需要与原生协商一致)
关注点放在实现思路上
const callbackMap = {};
// 全局唯一方法,提供给APP调用
window.invokeJsMethod = (module, method, params) => {
console.log("invokeJsMethod参数:", module, method, params);
if (callbackMap[method] && typeof callbackMap[method].fn === "function") {
callbackMap[method].fn(params);
// 删除已执行过的方法,并且只需要执行一次的。防止多次页面返回的时候再次调用
if (callbackMap[method].callOnce) {
delete callbackMap[method];
}
}
};
const JSBridge = {
/**
* 注册回调函数
* @param mapKey {string} 注册的回调名称,将在callbackMap中注册此名称的key,该key指向一个对象,包含fn和callOnce属性
* @param fn {function} 你的回调,当APP方法执行完后,将执行此函数,接收APP回传的参数
* @param callOnce {boolean} 该回调是否仅允许执行一次,true是,false否
*/
registCallback(mapKey, callback, callOnce = false) {
if (!mapKey || !callback || typeof callback !== "function") {
return;
}
callbackMap[mapKey] = { fn: callback, callOnce };
},
/**
* 注销回调函数
* @param mapKey {string} 已注册的回调名称
*/
unRegistCallback(mapKey) {
if (callbackMap[mapKey] && typeof callbackMap[mapKey].fn === "function") {
delete callbackMap[mapKey];
}
},
//写法一:callback
isApp(callback) {
const mapKey = "onGetInstalledApp";
this.registCallback(mapKey, callback());
window.location.href = `fusion://invokeNative?module=LocModule&method=getInstalledApp&arguments=null&callback=${mapKey}`;
},
//写法二:promise
onGetPfrom() {
const mapKey = "onGetPfrom";
return new Promise((resolve, reject) => {
this.registCallback(mapKey, resolve);
window.location.href = `fusion://invokeNative?module=LocModule&method=getPfrom&arguments=null&callback=${mapKey}`;
});
}
export default JSBridge;解构赋值
取值
接到参数返回的数据res后,一般用解构的方式取出值,想比与通过res.*的方式,解构的方式有几个明显的好处
代码更加简洁
可以设置默认值。如果使用
res.data.author,当后台返回的data是null或者不存在(undefined),再去取author时,就会报错 。而我们这里将userInfo的默认值设置为{},所以不会报错jslet res={ code:0, message:'', data:{ userInfo:{ // name:'jack', age:18 }, author:'HDD' }, } //注意: //1. userInfo:{name}这部分已经解构到了userInfo对象内部了,所以并不能获取userInfo,只能获取其中的name,如果希望获取整个userInfo对象,不要再写:{name,name}就可以了 //2. =是为了设置默认值,当字段不存在时,会返回默认值 const { code, data:{ author='默认作者', userInfo:{ name='默认名字', age }={} }={} } = res||{} console.log('code --> ',code) //code --> 0 console.log('author --> ',author) //author --> HDD console.log('name --> ',name) //name --> 默认名字 console.log('age --> ',age) //age --> 18解构不存在的参数,未设置默认值时,参数值为undefind
jslet obj={ name:"jack" } const {name,age}=obj||{} console.log(name,age)//jack undefined
函数可选参数
其实就是结构赋值的灵活运用
function getUserInfo(params){
const {name,age=100}=params //如果不传递age,给定默认值
console.log(`名字是${name},年龄是${age}`)
}
getUserInfo({name:"jack",age:19})//名字是jack,年龄是19
getUserInfo({name:"tom"})//名字是tom,年龄是100比如,我将常遇到常见,随意找到一个微信小程序开发者文档的api,以wx.showToast(Object object)为例
可以看到函数showToast的参数是一个对象,这些对象的key:
- 有些是必填,有些是可选
- 不写对应的key,还会有默认值
- key还可以是回调函数
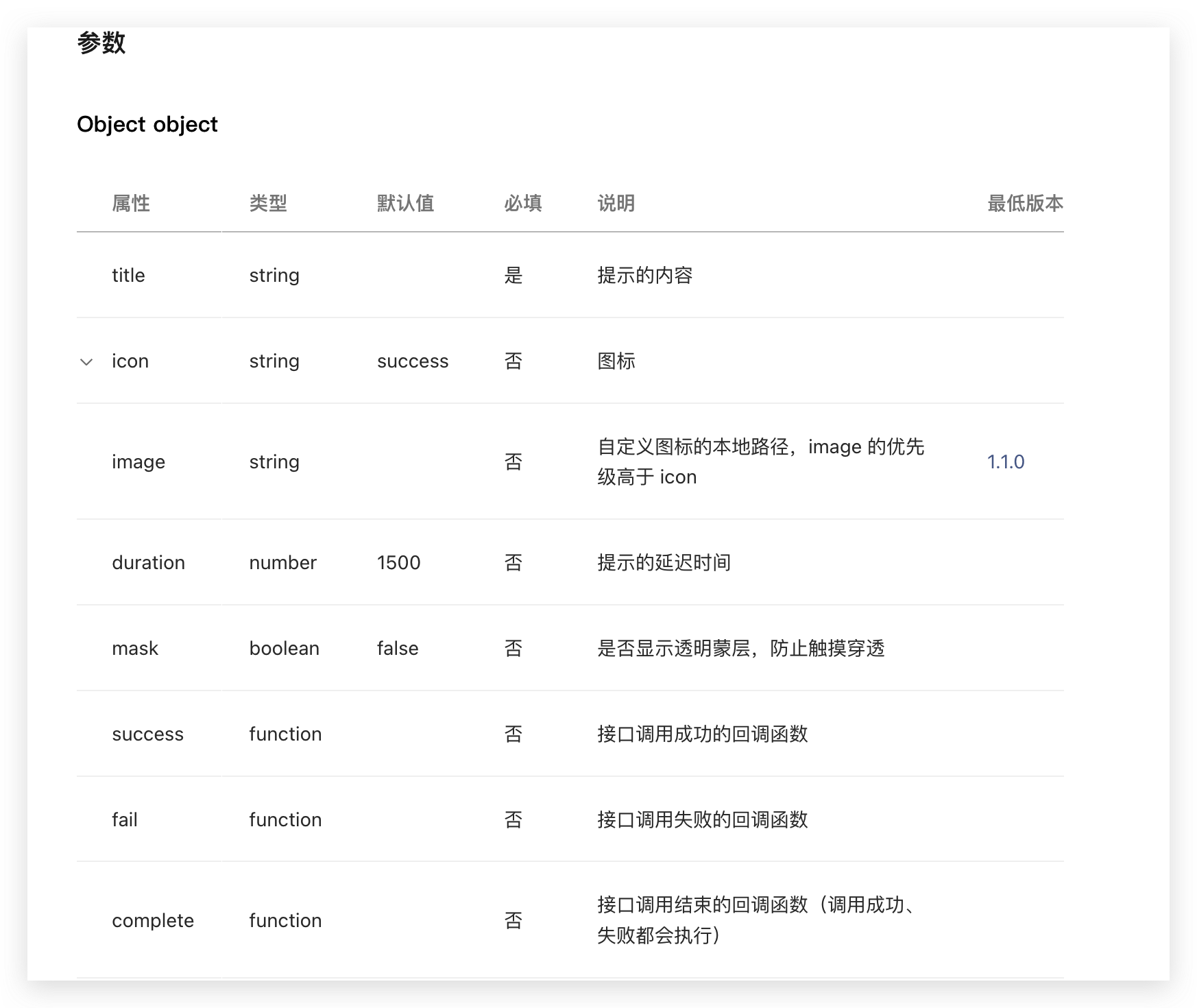
参数 icon的可选值

简单模拟下这个函数
class WX {
navigateTo(params){
//1、解构参数
const{title,icon="success",success,fail,complete}=params
//2、判断必填值
if(title===undefined){
throw new Error("title为必填字段")
}
//3、判断下icon字段是否在可选范围
let iconList=["success","error","loading","none"]
if(iconList.indexOf(icon)===-1){
throw new Error("icon字段填写有误")
}
//4、api内部逻辑忽略(微信应该的api可以看作是一个大的JSBridge,来调用原生能力)
if(1){//默认成功
this.callBackFunction(success,{msg:"成功了",data:{title,icon}})
}else{
this.callBackFunction(fail,{msg:"失败了"})
}
this.callBackFunction(fail,{msg:"最后执行的"})
}
callBackFunction(callback,params){ //判断下是不是函数,然后执行
if(callback!==undefined&&typeof callback==="function"){
callback(params)
}
}
}
const wx =new WX()
wx.navigateTo({
title:"你好",
success(res){
console.log("成功的回调函数",res) //成功的回调函数 { msg: '成功了', data: { title: '你好', icon: 'success' } }
}
})且、或以及其他高级用法
&& 和 ||
且/或组成的是表达式
与其他语言不同,js中的且/或表达式,是可以作为语句的执行的
jslet a=true function func1(){ console.log("函数执行") return false } let res=a&&func1() //函数执行&&从左向右将找到的值,转化为布尔值,如果为假,则返回其原值,不再继续执行了。找不到为假的,则返回最后一个值
js1&&2&&''&&3 //'' 1&&2&&3 //3||从左向右将找到的值,转化为布尔值,如果为真,则返回其原值。找不到为真的,则返回最后一个值
**||的升级版本=>空值合并运算符 ?? **
上面的运算有一个潜在的问题,就是以下6个值,都会被认为是假的
0 、NaN 、 "" 、false 、null 、undefined??是||的升级版,??只认为null和undefined为假
找到第一个不为null和undefined的值,返回。找不到,返回最后一个值常见用法例子:||最常见的用法就是赋值
height=height||170 //第二个height是接口返回的值,如果接收到数据中没有这个字段,其值就为undefind。这种写法第一个height最终值就是170。可是如果height接收到的值是0,那第一个height也会被赋值为170
height=height??170 //就能有效避免非null、非undefined的隐式转换的问题升级用法例子:如果对象result中有groupName属性,就直接恢复其为空字符串
使用
||,如果result["groupName"]是0,仍然会初始化jslet result={} for(value of list){ result["groupName"] || (result["groupName"] =""); }使用
??,只有result["groupName"]是null或者undefined,才会初始化jslet result={} for(value of list){ result["groupName"] ?? (result["groupName"] =""); }
&&的升级版=>可选链?.
如果可选链 ?. 前面的值为 undefined 或者 null,它会停止运算并返回 undefined。
换句话说,例如 value?.prop:
- 如果
value存在,则结果与value.prop相同, - 否则(当
value为undefined/null时)则返回undefined
常见用法例子1
假设,后端一定返回res,res中也一定包含data,但是data可能为null且address是否存在是不确定的(有些数据有地址,有些则没有)
if(res&&res.data&&res.data.address){
//需要取name字段,就需要一步一步判断下来。否则如果data就是undefined时,再取name字段,就会报错
}使用可选链(不可滥用可选链,res一定是存在的,如果不存在就证明返回出错了,如果使用res?.data就会掩盖这个的错误)
if (res.data?.address === undefined) {//有效避免data是null的情况
return
}
const { data } = res.data函数的回调与Promise风格
我们有时候再查看一些文档时,时常发现文档中的某些函数往往标注着,是否支持Promise风格
其实,这些函数都是异步函数,通常面对异步函数,一般就两种风格,一种是回调函数,一种就是promise
如何让改造一个回调函数风格的函数,使其支持Promise呢?我们称这种方式为Promise化
function getCity(cb){
//获取城市数据逻辑 ,cityName,cityId
cb(cityName,cityId)
}回调函数风格
//假设函数原本的使用方式
getCity((cityName,cityId)=>{
//处理
})将回调风格改造为Promise风格
function getCity(){
//获取城市数据逻辑 ,cityName,cityId
let cityName='北京',cityId=201
return new Promise((resolve,reject)=>{
if(cityName&&cityId){
resolve({cityName,cityId})
}else{
reject(new Error('"获取失败"'))
}
})
}
//----链式调用----
getCity().then(res1=>{
console.log('res1-->',res1)
}).catch(err1=>{
console.log('err1-->',err1)
})//res1--> { cityName: '北京', cityId: 201 }
//----await调用----
try {
let res2=await getCity()
console.log('res2-->',res2)//res2--> { cityName: '北京', cityId: 201 }
}catch (err2){
console.log('err2-->',err2)
}兼容性改造【将原函数改造为同时支持回调和Promise风格】
function getCity(cb){
//获取城市数据逻辑 ,cityName,cityId
let cityName='北京',cityId=201
return new Promise((resolve,reject)=>{
if(cityName&&cityId){
cb&&cb(cityName,cityId)
resolve({cityName,cityId})
}else{
cb&&cb(null,null)
reject(new Error('"获取失败"'))
}
})
}
getCity((cityName,cityId)=>{
console.log(' 回调方式结果--> ',cityName,cityId)
})
//----链式调用----
getCity().then(res1=>{
console.log('res1-->',res1)
}).catch(err1=>{
console.log('err1-->',err1)
})//res1--> { cityName: '北京', cityId: 201 }
//----await调用----
try {
let res2=await getCity()
console.log('res2-->',res2)//res2--> { cityName: '北京', cityId: 201 }
}catch (err2){
console.log('err2-->',err2)
}Promise化的场景
很多时候,我们并不能直接对支持回调的异步函数进行修改。尤其是,修改别人的代码时,很有可能会改出新的bug,所以 ,我们可以把原本的回调函数继续封装一层,让这个新函数支持Promise
//核心:在回调函数外面加一层Promise,在回调函数成功拿到数据后,resolve数据
NewGetCity(){
return new Promise((resolve,reject)=>{
getCity((cityName,cityId)=>{
if(cityName&&cityId){ //这里判断的也许不太严谨,主要含义还是说,区分出来Promise的成功和失败状态
resolve({cityName,cityId})
}else{
reject("失败了")
}
})
})
}回调风格的深层次思考一
场景1
下面的是微信提供的弹窗API
wx.showModal({
title: '提示',
content: '这是一个模态弹窗',
success (res) {
if (res.confirm) {
console.log('用户点击确定')
} else if (res.cancel) {
console.log('用户点击取消')
}
}
})在函数中调用即可在页面展现弹窗,同时当点击确定或取消按钮触发success回调函数

场景2
这是element UI提供的调用方式
this.$alert('这是一段内容', '标题名称', {
confirmButtonText: '确定',
callback: action => {
console.log('点击了确定')
}
});
实现
我一直十分好奇上面两种方式的实现,如何能够做到在一个函数中,调用API打开弹窗,点击按钮后还能在同一个函数中接收返回值
直到我在网上偶然间看到了大佬的实现(微信小程序代码片段:https://developers.weixin.qq.com/s/UmDTWhmu7Vgk,需下载微信开发者工具),才从另一个角度重新认识了回调函数
小程序实现
子组件JS逻辑:
Component({
data:{
visible:false
},
methods: {
cancel() {
this.data.success({confirm:false})
this.close()
},
confirm() {
this.data.success({confirm:true})
this.close()
},
close() {
this.setData({
visible:false
})
},
//打开弹窗函数
open(params={}){
const {success,title='提示',desc='描述',cancelText='取消',confirmText='确定'}=params
//设置弹窗展示
this.setData({
visible:true
})
//设置弹窗的参数
this.setDialogData('title',title)
this.setDialogData('desc',desc)
this.setDialogData('cancelText',cancelText)
this.setDialogData('confirmText',confirmText)
//------关键:将参数success函数,保存下来,在点击确定/取消按钮时在调用-----
this.data.success=success
},
//设置数据的函数
setDialogData(key,value){
this.setData({
[`${key}`]:value
})
}
}
});父级引入子组件后:
<view class="intro" bindtap="tap">点击</view>open(){
//获取子组件实例
let dialog=this.selectComponent('#dialog')
//弹窗open方法
dialog.open({
title:'提示',
desc:'描述描述描述描述描述',
success:(res)=>{
if(res.confirm){
console.log('点击了确定')
}else{
console.log('点击了取消')
}
}
})
},Promise风格
回调函数在逻辑处理上很同意造成嵌套。比如弹窗点击确定执行逻辑A,取消执行逻辑B
就必须写在success的回调函数中
我更喜欢同步化,给人一种代码在的等待用户做出选择的感觉
promisfyOpen(){
return new Promise((resolve,reject)=>{
let dialog=this.selectComponent('#dialog')
dialog.open({
title:'提示',
desc:'描述描述描述描述描述',
success:(res)=>{
if(res.confirm){
//console.log('点击了确定')
resolve(true)
}else{
//console.log('点击了取消')
resolve(false)
}
}
})
})
}
//调用open,会给人一种代码在的等待用户做出选择的感觉
async open(){
let res=await this.promisfyOpen()
console.log('用户点击了',res)//true是确定,false是取消
},感悟
第一次知道,作为参数的回调函数可以被保存下来,在任意时机调用传参
当调用时,会在传入处立即触发执行
回调风格的深层次思考二
在我彻底接受了同步风格后,我尝试将所有场景的回调风格代码promisify
刚开始一切都很顺利,将代码优化为同步形式,使得页面逻辑更加清晰
但是,我慢慢的遇到了一些场景,在这些场景下根本无法使用同步风格。我将这些场景分为两类
从嵌套函数中拿取结果到外层
介入主逻辑的钩子
等待未来的某个时机触发(重点)
从嵌套函数中拿取结果到外层
这种最常见
function f1(callBack){
f2(callBack)
}
function f2(callBack){
callBack(data)
}
f1((data)=>{
//拿到数据
})介入主逻辑的钩子
最常见的就是生命周期钩子
function mainProcess({preLoad,afetrLoad}){
//钩子
if(preLoad instanceof Function){
preLoad()
}
//主流程
if(afetrLoad instanceof Function){
afetrLoad()
}
}同理,也可以作为兜底逻辑,来介入主逻辑
function mainProcess({handleException}){
if(主流程出现了特殊场景 && handleException instanceof Function){
handleException()
}
}等待未来的某个时机触发
讲一个目前遇到的案例吧
request({
data,
success(data){
//请求成功的数据
},
fail(){
}
})Promise的一些细节
resolve和reject并不会结束函数
function getCity(){
return new Promise((resolve,reject)=>{
if(1){
resolve(1)
console.log(1)
}else{
reject(new Error('失败'))
console.log(2)
}
})
}
getCity() //1终止当前函数要用return
function getCity(){
return new Promise((resolve,reject)=>{
if(1){
resolve(1)
return
console.log(1)
}else{
reject(new Error('失败'))
console.log(2)
}
})
}
getCity() //无打印throw抛出错误,会向上终止每一层函数,直到被捕获(如果自己没有捕获整个程序就会结束)
Promise.all
//3.Promise.all的使用
//3.1全部fufilled状态,会以数组的形式返回结果
// function all(){
// let taskList=[]
// //推入数组时,就调用了函数。只不过没有立即执行
// taskList.push(f1(true))
// taskList.push(f2(true))
// Promise.all(taskList).then(res=>{
// console.log('all -->',res)
// })
// }
// all() //all --> [ { name: 'f1' }, { name: 'f2', age: 2 } ]
//3.2 rejected状态不会阻塞剩下的函数执行,如果有多个rejected状态的,则只返回第一个
function f3(params){
return new Promise((resolve,reject)=>{
if(params){
resolve({name:"f3"})
}else {
reject({name:"f3"})
}
console.log('f3执行了')
})
}
function all(){
let taskList=[]
//推入数组时,就调用了函数。只不过没有立即执行
taskList.push(f1(false))
taskList.push(f3(true))
taskList.push(f2(false))
Promise.all(taskList).then(res=>{
console.log('all -->',res)
}).catch(err=>{
console.log('all err-->',err)
})
}
all() //f3执行了 all err--> { name: 'f1' }async与await的一些细节
这里写了3个函数,参数为真则返回fulfilled状态的Promise对象,否则返回rejected状态。后面的例子大部分使用这三个函数模拟各种场景
function f1(params){
return new Promise((resolve,reject)=>{
if(params){
resolve({name:"f1",age:2})
}else {
reject({name:"f1",age:4})
}
})
}
function f2(params){
return new Promise((resolve,reject)=>{
if(params){
resolve({name:"f2",age:2})
}else {
reject({name:"f2",age:4})
}
})
}
function f3(params){
return new Promise((resolve,reject)=>{
if(params){
resolve({name:"f3",age:2})
}else {
reject({name:"f3",age:4})
}
})
}await
第一个await后的函数返回的了rejected状态的promise对象,后面的代码不会再执行了
这段代码由于没有处理rejected状态的promise对象,还会报错
jsasync function lmn(){ console.log('开始') const res1 = await f1(false) console.log('中间') const res2 = await f2(false) console.log('最后') } lmn() //开始注意:await后面的代码虽然不执行了,但是结构赋值还是会执行的
const {name} = await f1(false)捕获rejected状态的Promise对象
使用try...catch。这种处理方案多是为整体流程做兜底处理,由于f1失败,后面的流程都不会被执行
jsasync function lmn(){ try{ const res1 = await f1(false) const res2 = await f2(false) }catch (err){ console.log("err --> ",err) } } lmn() // err --> { name: 'f1', age: 4 }使用promise的链式方法catch。这种方案适合单独处理每一步的错误,避免一步错误导致整体流程终止。我们可以看到例子中f1使用catch处理后,会继续运行下面的流程f2。同时需要注意到,因为f1的错误已经被处理了,外部的try...catch就不能继续捕获到这个错误了
jsasync function lmn(){ try{ const res1 = await f1(false).catch(err=>{ console.log("f1错误",err) }) const res2 = await f2(false) }catch (err){ console.log("err --> ",err) } } lmn() //f1错误 { name: 'f1', age: 4 } //err --> { name: 'f2', age: 4 }promise函数的返回值
假如有一个顶层的函数(没有其他函数在内部调用)test。在其中调用了两个异步函数,两个异步函数都做了错误处理(出现错误抛出错误或者return Promise.reject),所以一旦出现错误test函数就会结束
jsasync function test(){ await lmn() await opq() }我们需要继续在test函数中做错误处理,比如输出内部抛出的错误,然后再结束函数
可是Promise的链式调用中使用return是不能停止顶层函数的,只能将值传递给下一个then。所以,我常用的是返回
{err:err;data:null}结构,错误对象如果没有就赋值为null。通过接收其最终值,来实现控制顶层函数的目的。(其思路类似于Go语言的处理思路)jsasync function test(){ let {err,data}=await lmn().catch(err=>{ console.log(err) return {err:err;data:null} }) if(err!==null){ return } await opq() }一般的错误处理逻辑:在await后直接catch处理已知的错误,不能识别的错误,直接throw再次抛出,最后在全局try...catch错误做一错误的兜底逻辑
try...catch无法捕获到异步的错误
这是我经常犯得一个错误,必须在异步函数前加上await,使得函数同步化,否则无法捕获到错误
jsasync openScanCode() { try { await openWxScanCode(); //异步任务 } catch (err) { console.log('openScanCode err-->', err); } },函数内部捕获错误,无法使用try catch捕获失败的promise
jsasync function f(){ try{ //请求数据 await apiResult() //code为0,且data有数据,即为成功状态的Promise if(res?.code===0&&res?.data){ return res.data } //code不为0,则是业务错误。 //正确方式:这里抛出的错误也可以被catch捕获 throw Error('业务错误') //错误方式:这里是结束函数且结果是失败的Promim。并不会内部的catch捕获到 return Promise.reject() }catch(err){ //这里可以捕获到业务错误 } }但是使用try catch捕获返回值是失败promise的函数
jstry{ await f() }catch(err){ }
错误处理
上面已经使用过try...catch和promise的catch方法了
这里再进行一些补充,两种方式都是既可以捕获Error对象,也可以捕获rejected状态的Promise。但是,catch方法作为promise链上的方法,只能捕获其promise作用链上的Error对象或rejected状态的Promise
catch作为promise链上的方法,只能捕获其promise作用链上传递的rejected、错误对象
function lmn(){
f1(true).then(resf1=>{
f2(false) // 这里需要加上await,catch才能捕获到
}).catch(err=>{
console.log("外层捕获",err)
})
}
lmn() //报错,未捕获rejected状态的Promisefor循环中使用await
for循环按照promise数组的顺序执行。且上一个promise执行完毕后,下一个才会执行
jsfunction f1(){ return new Promise((resolve)=>{ setTimeout(()=>{ resolve('f1执行') },1000) }) } function f2(){ return new Promise((resolve)=>{ setTimeout(()=>{ resolve('f2执行') },2000) }) } async function test(){ let promiseList=[f1(),f2()] for(let item of promiseList){ const res= await item //item就已经是promise了 console.log(res) } } test() // f1执行 // f2执行await结果是reject,会中断整个for循环
从结果看出第二次循环,到await处直接被结束了
jsfunction f(params){ return new Promise((resolve,reject)=>{ if(params){ resolve({name:"f"}) }else { reject({name:"f"}) } }) } async function test(){ let temp=[true,false,true] for(let index in temp){ console.log(index) await f(temp[index]) console.log(index) } } test() // 0 // 0 // 1catch能够捕获当前错误,这样for就不会直接中断了
jsfunction f(params){ return new Promise((resolve,reject)=>{ if(params){ resolve({name:"f"}) }else { reject({name:"f"}) } }) } async function test(){ let temp=[true,false,true] for(let index in temp){ console.log(index) await f(temp[index]).catch(err=>{ console.log('err -->',err) }) console.log(index) } } test() // 0 // 0 // 1 // err --> { name: 'f' } // 1 // 2 // 2如果只想结束当前循环
下面的写法是有语法错误的
jsasync function test(){ let temp=[true,false,true] for(let index in temp){ console.log(index) let res=await f(temp[index]).catch(err=>{ console.log(err) continue //这里错误了,因为continue必须在for循环的作用域内 }) console.log(index) } } test()正确的写法是
jsasync function test(){ let temp=[true,false,true] for(let index in temp){ console.log(index) let res=await f(temp[index]).catch(err=>{ console.log(err) return false }) if(res===false){ continue } console.log(index) } } test() // 0 // 0 // 1 // err --> { name: 'f' } // 2 // 2
async函数的返回值为Promise对象
函数内部使用await,该函数必须添加async关键字
单词async是异步的意思,async函数虽然其内部使用await关键字使得其表现像同步函数,但是其实际仍然是异步函数,其返回值是Promise对象
与Promise的then函数一样,async函数内
没有return,默认返回fulfilled状态的Promise,Promise内的值是undefined
js//无return async function lmn(){ const res=await f1(true).catch(err=>{ console.log('err ---> ',err) }) } lmn().then(res=>{ console.log(res) //undefined })return 值,默认返回fulfilled状态的Promisejsasync function lmn(){ const res=await f1(true).catch(err=>{ console.log('err ---> ',err) }) return res } lmn().then(res=>{ console.log('lmn --> ',res) //lmn --> { name: 'f1' } })return Promise.reject(值)才返回rejected状态jsasync function lmn(){ const res=await f1(true).catch(err=>{ console.log('err ---> ',err) }) return Promise.reject('失败') } lmn().then(res=>{ console.log('lmn --> ',res) }).catch(err=>{ console.log('lmn err--> ',err) //lmn err--> 失败 })
嵌套promise的没有await的执行顺序
process函数中的step没有加await
实际的执行顺序是先进入step执行同步代码,遇到await就不继续执行了,开始执行外部的代码
所以,这种执行顺序是混乱的,所以一定要保证step的执行与外部没有依赖关系
function p(){
return new Promise((resolve)=>{
setTimeout(resolve,3000)
})
}
async function step(){
console.log('step1 开始')
await p()
console.log('step1 结束')
}
function process(){
console.log('process 开始')
step()
console.log('process 结束')
}
process()
// 输出
process 开始
step1 开始
process 结束
step1 结束链式调用
// find 传入参数为原始数据(数组格式,每个元素都是对象)
// 通过进行链式调用对数据执行操作,支持的方法有
// where(predicate): 根据属性进行匹配筛选
// orderBy(key, desc): 根据 key 的值进行排列,默认升序排列,当第二个参数为 true 时降序排列
// groupBy(key): 根据 key 的值对数据元素进行分组,合并为二维数组
// execute(): 执行所有处理并返回最终结果
Array.prototype.find=function(array){
return this
}
Array.prototype.where=function(predicate){
let res=[]
for(let item of this){
if(item[predicate]!==undefined){
res.push(item)
}
}
return res
}
Array.prototype.orderBy=function(key,desc){
return this.sort((second,first)=>{
if(desc===true){ //降序:从大到小
if(first[key]>second[key])
return 1
else
return -1
}else{
if(first[key]<second[key])
return 1
else
return -1
}
})
}
Array.prototype.groupBy=function(key){
let calcArray=[]//用索引记位置
return this.reduce((preValue,curValue)=>{
let curValueGroupByKey=curValue[key]
let index= calcArray.indexOf(curValueGroupByKey)
if(index===-1){ //不存在这个key的值
calcArray.push(curValueGroupByKey)
preValue.push([curValue])
}else {//存在
preValue[index].push(curValue)
}
return preValue
},[])
}
console.log([{name:"jack",age:19},{name:"tom"},{name:"jack",age:30},{name:"tom",age:10}].find().where("age").groupBy("name"))关于业务编码上的一点反思
编写业务代码,要达成两个核心目标:
- 业务需求会随着项目不断迭代而发生变化,代码应该充分解耦,避免一处改动对其他逻辑造成影响
- 避免函数内部直接使用、更改外部变量,应该将外部变量当做参数传入,将处理结果返回。对于流程类函数(不做数据的处理,只是调用其他函数完成业务流程,例如后面场景模拟2中的submitChain函数),应当返回流程最终状态(提交最后是否成功)
场景模拟1
接口函数:getAuditStatus,参数为车型Id,返回Promise,返回参数是布尔值,表示该车型是否被用户认证
业务场景:
认证表单第一项切换车款,需要在切换时,提醒用户该车型是否认证过车主
认证表单提交,需要判断用户是否认证过该车型
常见错误写法:
//引入一个封装成Promise的请求
const { getAuditStatus } =require("../api")
function getAuditStatus(serialId){
getAuditStatus({ serialId }).then((res)=>{
//使用一个全局变量区分两种情况,将两种情况耦合在一起
})
}评价:多条业务逻辑耦合在一个getAuditStatus函数中
改进写法:
const { getAuditStatus } =require("../api")
//业务一:表单第一项切换车款
async function changeSerial(serialId){
let res=await getAuditStatus({serialId})
//继续切换车款逻辑处理
}
//业务二:认证表单提交
async function submit(serialId){
let res=await getAuditStatus({serialId})
//继续提交逻辑处理
}评价:分离业务逻辑,避免同一个函数处理多个不同的逻辑链
场景模拟2
提交按钮被点击时,逻辑链流程:订阅 -> 校验 -> 执行提交 -> 成功弹窗
常见错误写法:
function A(){
//订阅逻辑
this.B()
}
function B(){
//校验逻辑
this.C()
}
function C(){
//提交逻辑
this.D()
}
function D(){
//打开成功弹窗
}
A()点评:
业务逻辑高度耦合,调用A就会引起连锁调用

如果再同时出现场景模拟1的情况,即调用链条上的某一点在其他情境中也被调用,就会进一步加剧代码的复杂度。
假设应用场景仅需要E->B,但是因为连锁调用C与D也会一起被调用,这不符合预期
假设图中共有 : A->B->C->D 、E->B->C->D、F->C->D,三条逻辑链
但是现在需求变更,仅要求在A->B->C->D这条逻辑的B->C之间加入G,如果直接加入这条逻辑,必然会影响到原本E->B->C->D这条逻辑链
改进写法1:(引入新名词,逻辑链函数)
function A(){
//订阅逻辑
}
function B(){
//校验逻辑,调用校验用户是否提交过的接口。未提交返回true,否则false
}
async function C(){
//调用提交接口。提交成功返回true,否则false
}
function D(){
//提交成功才打开成功弹窗
}
//抽象出来提交逻辑,在其中完成一整条逻辑链,我称这种函数为"逻辑链函数"
function submitChain(){
A()
let isSubmited=await B()
if(isSubmited){
let submitRes= await C()
if(submitRes) D()
}
}改进写法2:
逻辑链可能会在某节点分叉,例如下图(但是注意一定要保证其是一个拓扑图,即单项流动,不能出现后面的状态改变前面的状态)
他们之间的A、B是共用的,我们必须将后面的代码分离成两条逻辑链。业务流程中可能会存在很多分叉,分叉的末端还会有分叉,所以需要自己权衡,如果是否需要引入新的逻辑链函数,还是直接在主逻辑链中处理

//抽象出来提交逻辑,在其中完成一整条逻辑链,我称这种函数为"逻辑链函数"
function submitChain(){
A()
let isSubmited=await B()
if(isSubmited){
let submitRes= await C()
if(submitRes){
dealSubmitSuccessChain()
}else{
dealSubmitFailChain()
}
}else{
//已提交的处理逻辑
return
}
}
function dealSubmitSuccessChain(){
D()
I()
}
function dealSubmitFailChain(){
H()
J()
}同时,需要注意,前端的特殊性,用户的页面操作可以改变逻辑链的流向。用户逻辑链执行的过程中,触发一个弹出,弹窗的不同按钮就会导致走向不同的逻辑链,这种情景就脱离主逻辑链,例如提交流程中,提交成功后弹出提示框,其中有确定、重新编辑两个按钮。主逻辑链只到打开弹窗就结束了。剩下的由用户去触发两个按钮对应的逻辑链
//弹窗的返回方法
function backTo(cb){
cb("pre")
}
//弹窗的继续提交方法
function continueSubmit(cb){
cb("continue")
}
//主流程逻辑链
function submitChain(){
A()
let isSubmited=await B()
if(isSubmited){
let submitRes= await C()
if(submitRes){
D(cb)//打开弹窗
cb()
//其他操作
}
}else{
//已提交的处理逻辑
return
}
}改进3
可以根据自己需求使用.catch来针对某些步骤进行错误的处理,也可以使用try...catch全局进行处理
function submitChain(){
A()
let isSubmited=await B().catch(err=>{
//单独对这一步的错误处理
})
if(isSubmited){
let submitRes= await C()
if(submitRes){
dealSubmitSuccessChain()
}else{
dealSubmitFailChain()
}
}else{
//已提交的处理逻辑
return
}
}
function dealSubmitSuccessChain(){
D()
I()
}
function dealSubmitFailChain(){
H()
J()
}点评:这种写法不仅可以实现不同逻辑链解耦,还可以更好的错误的捕获取处理。
场景模拟3
函数应以入参,返参数的方式使用
通过入参的方式,明确函数中使用的外部变量的状态,尽力避免在函数中直接对外部变量直接读写
常见错误写法:
在复杂业务场景中,多个函数都在内部更改了a,等到新加入的逻辑E、F使用变量a,很难判断当前的a的状态在哪条逻辑链中被更改
jsfunction A(){ this.globalData.a=1 } function B(){ this.globalData.a=2 } function C(){ this.globalData.a=3 } function E(){ //处理过程中用到了a变量 } function F(){ //处理过程中用到了a变量 }改进写法
jsfunction A(a){ return 1 } function B(a){ return 2 } function C(a){ return 3 } function E(a){ //处理过程中用到了a变量 } function F(a){ //处理过程中用到了a变量 }如果入参是对象,一般在函数内改变,只返回改变的结果。例如成功true,失false
对于一些流程类函数,例如在submitChain这条逻辑链上的函数A、B、C、D都必须有返回值,例如B、C并不是返回数据,而是调用其流程的最终结果
注意:逻辑链函数也要有返回值,例如【场景模拟2中的改进写法2】其中分叉的两条逻辑链属于主逻辑链的子节点
jsfunction A(){ //订阅逻辑 } function B(){ //校验逻辑,调用校验用户是否提交过的接口。未提交返回true,否则false } async function C(){ //调用提交接口。提交成功返回true,否则false } function D(){ //提交成功才打开成功弹窗 } //抽象出来提交逻辑,在其中完成一整条逻辑链,我称这种函数为"逻辑链函数" function submitChain(){ A() let isSubmited=await B() if(isSubmited){ let submitRes= await C() if(submitRes) D() } }
场景模拟4
对于填写表单数据,是一个非常常见的需求。
目前有一个非常复杂的表单,需要实现几套逻辑
- 首次填写并提交
- 表单被驳回,重新编辑(表单回显成上一次提交的状态)并提交
实现框架
- getFormData获取当前表单输入的数据(不同逻辑链提交表单,同样都需要表单数据)
- setFormData设置表单数据(回显数据)
- dealFormDataWithXXChain、dealFormDataWithYYChain,不同的数据处理函数,接收表单数据,返回处理结果
Promise与回调函数的另一种结合
下面的函数可以让,其他开发者在callback中处理数据
- 处理完了就return数据,然后再then中继续使用
- 处理的过程中发现错误,就throw出来,在catch中处理
function testCallBack(cb){
return new Promise((resolve,reject)=> {
try {
resolve(cb())
} catch (err){
console.log("函数内部,捕获到Error对象",err)
reject(err)
}
})
}
let res=testCallBack(()=>{
if(1){
throw new Error() //throw会终止回调函数,但是在testCallBack内部的Promise中被try...catch捕获,所以不会终止整个程序。捕获后reject这个err,就能被.catch接收到
}
return 1
}).catch(err=>{
console.log("外部调用Promise,捕获到Error对象",err)
})同步延时器
定时器是异步的,但是我们可以通过Promise化,同步调用定时器
async function f(){
//前面的操作
await new Promise((resolve)=>{
setTimeout(resolve,1000)
})
//后面的操作
}JS中的return
函数中体顶层作用域出现return,会直接结束整个函数
function f1(){
console.log(1)
return
console.log(2)
}
f1() //1if等流程函数中,也会结束整个函数
function f1(){
console.log(3)
if(true){
return
console.log(4)
}
console.log(5)
}
f1() //3回调函数中return,只能结束回调函数
function f2(){
setTimeout(()=>{
console.log(1)
return
console.log(2)
},2000)
}
f2() //1Promise中return只能将数据传递给下一个then函数。不能结束整个函数
async function f3(){
return 1
}
function f4(){
//必须在在前面加一个return
return f3().then(res=>{
return res
})
}
f4().then(res=>{
console.log(res)
})JS插件系统如何设计
推荐设计(此种设计仍然不够健全,注册的插件可以通过this访问到插件系统的配置,甚至还可以直接修改插件系统的配置,这样就破坏了插件核心的稳定性)
class HDDPlugin{
//插件系统内置属性
coreConfig={
version:'0.0.1'
}
//插件构造方法(用于配置插件系统规则,注册插件)
constructor(customCoreConfig) {
//1、校验下pluginList的格式必须是数组(数组传入多个插件)
//2、config插件系统配置(内置属性和config属性合并,用户传入的优先级高)
this.coreConfig={...this.coreConfig,...customCoreConfig}
}
//注册插件函数(用于注册插件,同时传入插件配置)
register(PluginList){ //箭头函数的写法,可以放置this丢失,这里this永远指向对象
if (!Array.isArray(PluginList)||PluginList.length===0){
console.warn('插件列表必须指定')
return
}
for (let plugin of PluginList){
const { pluginName,pluginExec } = plugin;//插件必须要有两个属性,pluginName插件名,pluginExec插件函数
if(!(typeof pluginName==='string')||pluginName===''){
console.warn('插件pluginName字段必须为非空字符串')
return
}
if(!pluginExec instanceof Function){
console.warn('插件pluginExec字段必须为函数类型')
return
}
this[pluginName] = pluginExec; //将方法添加到类中
}
}
}
//创建实例对象
let p=new HDDPlugin({version:'1.0.0',secret:'111'}) //传入插件系统配置
//在实例上注册函数
p.register([{
pluginName:'test1',
pluginExec(params){
//注意:插件函数可以读取`插件系统`的核心配置
console.log(`插件test执行,插件传入的参数${params},读取插件系统核心配置${JSON.stringify(this.coreConfig)}`)
}
}])
//
p.test1('1')另一种思路(不太推荐)
将register指定为静态方法,只能通过类调用,这种做法丧失了灵活性。推荐将插件挂载到实例上
class HDDPlugin{
//插件系统内置属性
coreConfig={
version:'0.0.1'
}
//插件构造方法(用于配置插件系统规则,注册插件)
constructor(customCoreConfig) {
//1、校验下pluginList的格式必须是数组(数组传入多个插件)
//2、config插件系统配置(内置属性和config属性合并,用户传入的优先级高)
this.coreConfig={...this.coreConfig,...customCoreConfig}
}
//注册插件函数(用于注册插件,同时传入插件配置)
static register(PluginList){ //箭头函数的写法,可以放置this丢失,这里this永远指向对象
if (!Array.isArray(PluginList)||PluginList.length===0){
console.warn('插件列表必须指定')
return
}
for (let plugin of PluginList){
const { pluginName,pluginExec } = plugin;//插件必须要有两个属性,pluginName插件名,pluginExec插件函数
if(!(typeof pluginName==='string')||pluginName===''){
console.warn('插件pluginName字段必须为非空字符串')
return
}
if(!pluginExec instanceof Function){
console.warn('插件pluginExec字段必须为函数类型')
return
}
this[pluginName] = pluginExec; //将方法添加到类中
}
}
}
let p=new HDDPlugin({version:'1.0.0',secret:'111'})
HDDPlugin.register([{
pluginName:'test1',
pluginExec:()=>{
console.log('插件test执行')
}
}])
HDDPlugin.test1()JS语法树(AST)
JS细节易混淆
迭代器索引居然是string类型的
let arr=[1,2]
for(let index in arr){
console.log(index,typeof index) //索引是String类型
console.log(arr[index],typeof arr[index]) //number类型
}let obj={
1:"第一个",
2:"第二个"
}
for(let index in obj){
console.log(index,typeof index) //key是String类型
console.log(obj[index],typeof obj[index]) //String类型
}补充
swiper官网文档中写的mySwiper.某方法/某属性
mySwiper指的是swiper实例。在.vue文件中,可以给dom元素添加ref=“swiperBlock”,然后用this.$refs.swiperBlock获取dom元素,然后.swiper来获取实例
例如:调用slideTo方法

this.$refs.swiperBlock.swiper.slideTo(index);UUID
生成唯一不重复的编码
百度百科https://baike.baidu.com/item/UUID/5921266?fr=aladdin
/*
生成UUID
@para len {Number} 长度
@para radix {Number} 算法基数
@return uuid{String} 生成的UUID
*/
function createUUID (len, radix) {
var chars = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'.split('');
var uuid = [],
i;
radix = radix || chars.length;
if (len) {
// Compact form
for (i = 0; i < len; i++) uuid[i] = chars[0 | Math.random() * radix];
} else {
// rfc4122, version 4 form
var r;
// rfc4122 requires these characters
uuid[8] = uuid[13] = uuid[18] = uuid[23] = '-';
uuid[14] = '4';
// Fill in random data. At i==19 set the high bits of clock sequence as
// per rfc4122, sec. 4.1.5
for (i = 0; i < 36; i++) {
if (!uuid[i]) {
r = 0 | Math.random() * 16;
uuid[i] = chars[(i == 19) ? (r & 0x3) | 0x8 : r];
}
}
}
return uuid.join('');
}播放器
西瓜播放器https://v2.h5player.bytedance.com/about/
video.js、mediaElement.js 等视频播放器
lottie-web制作高性能动画
https://yechuanjie.com/blog/lottie/
lottie预览网站:上传json文件,就可以直接显示结果
<template>
<div id="stareyes"></div>
</template>
<script>
import * as fish from "./lottie/fish.json"; // 引入json本地资源
import lottie from "lottie-web";//引入lottie
export default {
mounted() {
lottie.loadAnimation({
container: document.getElementById("fish"),//设置动画显示的div
renderer: "svg",
loop: true,
animationData: fish.default//使用引入的json文件
});
},
};
</script>
<style lang="less">
</style>NPM资源
时间
请求
- request-ip 尝试获取请求头中的真实 IP
字符集
- iconv-lite 字符集转换,例如 GBK 编码转化为 UTF-8
项目管理
- Lerna 多 Package 项目管理
参考资源
- 现代 JavaScript 教程——我心中排名第一的JS教程
- 红宝书
- 阮一峰的《ECMAScript 6 入门》:https://es6.ruanyifeng.com/
- ES6 视频教程:http://t.kuick.cn/RaR3