Go学习笔记
配置环境
下载
官网下载 我使用的是mac系统,安装器会将Go自动安装到 /usr/local/go文件夹

配置环境变量
如果你对本节中对于环境变量含义的解释不能理解,建议阅读到【Go Module】章节后,在回来重新阅读
mac上配置环境变量直接在~/.zshrc文件中添加配置
GOROOT:默认是我们安装Go开发包的路径,不需要配置(Mac/Linux默认安装到usr/local/go这个位置)
GOPATH:
从Go 1.8版本开始,GOPATH默认为~/go,不需要配置
export GOROOT=/usr/local/go #Go默认的安装位置GOPATH有什么用?
Go项目中的依赖(module)并不会安装在项目下,而是默认安装到GOPATH下的目录。所以我们可以在自己的项目代码中,可以直接使用GOPATH下的目录中的模块(module)
比如,src目录下就有Go语言的标准库,所以我们可以在自己的项目代码中,可以直接使用Go的标准库(Go的标准库就是一个module)
GOPROXY:
安装依赖的源地址,默认GOPROXY配置是:GOPROXY=https://proxy.golang.org,direct(国内无法访问)
可以设置多个代理地址,用英文逗号分隔
最后的 “direct” 是一个特殊指示符,用于指示 Go 回到源地址去抓取(比如 GitHub 等)。当配置有多个代理地址时,如果第一个代理地址返回 404 或 410 错误时,Go 会自动尝试下一个代理地址,当遇见 “direct” 时回到源地址去抓取
可以换用国内源
shellexport GOPROXY=https://goproxy.cn,direct #或者 go env -w GOPROXY=https://goproxy.cn
GOPRIVATE:
安装的依赖包地址只支持Github.com等等(【Go Module】章节会详细据介绍依赖的地址)
但是,如果项目中引入了非公开的依赖,比如公司内部git仓库,依赖地址以 xxxx开头的,如果不配置这个字段Go是不支持拉取的
export GOPRIVATE=xxxxx查看配置是否生效
go env运行GO代码
推荐使用GoLand编辑器(破解方法,自行查找)
找个地方,建立Go项目目录,以后的代码都写在这个项目下
textGoProject项目根目录下,初始化go module
shellgo mod init 项目名 //我这里项目名是GoProject 会在根目录生成一个go.mod
新建main目录,main目录下新建一个
hello.go在main目录下,可以新建多个任意名字的go文件,但是每个go文件第一行,都会默认生成
package main,用来表示这些文件都属于main包(包名也可以和文件夹名不同,但是我强烈不建议这么做)gopackage main // 声明该文件属于 main 包修改
hello.go文件gopackage main // 声明 main 包 import "fmt" // 导入Go内置 fmt 包 func main(){ // main函数,是程序执行的入口 fmt.Println("Hello World!") // 在终端打印 Hello World! }main目录下,运行代码
go build 文件夹下的Go文件中必须属于main包,且有main函数入口
shellgo build //将文件夹内的Go文件,编译为可执行文件(文件名为目录名,即main) ./main //运行可执行文件 shell
shellgo build -o hello //指定输出的可执行文件名为hello go build -o ./dist/hello //指定输出可执行文件到dist目录下,文件名为hello根据自己的平台,生成的文件类型也有所不不同:win下为
*.exe; mac/Linux下为*.exec如果不想产生编译后文件,可以使用:
shellgo run xxx.go//直接运行xxx.go,不产生可执行文件注意:
build命令可以直接指定,编译、运行某个go文件
go build xxx.go其他命令
shellgo install //将编译后的代码放到GOPATH/bin目录 , 默认的GOPATH是~/go目录下的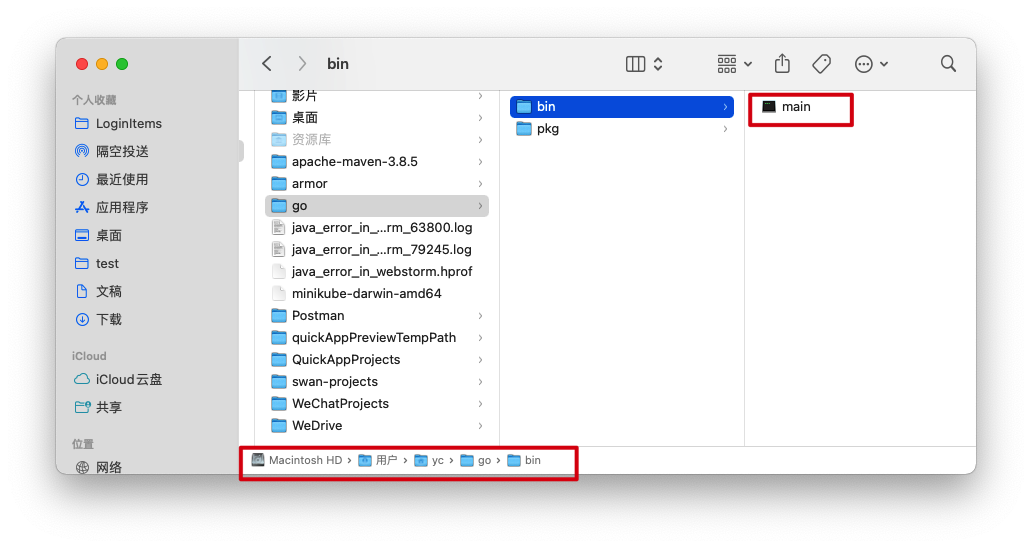
可执行文件main,被输出到bin下了。Go把GOPATH下的bin目录添加到了PATH环境变量中,所以当可执行文件被输入到了这里,就可以全局任何目录下,使用这个可执行文件
main //输出 Hello World!
交叉编译
上面讲过go build 只能编译生成本平台的可执行文件
交叉编译,就是产生其他平台的可执行文件 详情请参考
编译Linux平台可执行文件:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build编译window平台可执行文件:
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build编译mac平台可执行文件:
CGO_ENABLED=0 GOOS=darwin GOARCH=amd64 go build- CGO_ENABLED 0为禁用CGO
- GOOS 目标平台
- **GOARCH ** 目标平台机器处理器架构
Package(包)
同一个目录下只能有一个包,同一目录下有多个文件他们的package名相同
包
问题1:同一个包(package)内有多个Go文件,两个文件怎么调用对方的函数或者变量
问题2:同一个项目(module)中,不同包之间的两个文件,怎么调用对方的函数或者变量
前置规则
包中Go文件中要导出的变量/函数,首字母必须大写。首字母小写的是包的内部数据
导出的变量/函数,上添加的固定格式的注释,可以被编辑器读取,作为提示。
注释格式注意:函数名与解释之间,间隔1个英文空格
go// Myadd 两数相加 func Myadd(a, b int) int { return a + b }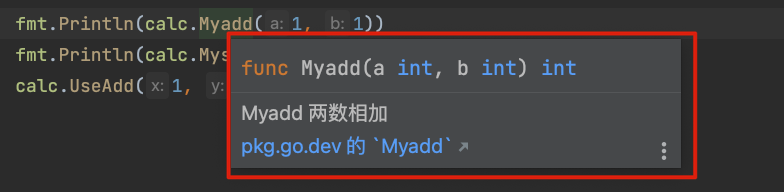
问题1
在GoProject这个项目下,新建文件夹calc文件夹,新建add.go、subtract.go(默认这个文件夹下的所有go文件就是在calc包下的)

add.go
package calc
//Myadd 两数相加
func Myadd(a, b int) int {
return a + b
}subtract.go
package calc
import "fmt"
//Mysubtract 两数相减
func Mysubtract(a, b int) int {
return a - b
}
func UseAdd(x, y int) {
fmt.Println(Myadd(x, y))
}结论:同包文件可以不用导出(首字母不需要大写)、导入,直接调用另一个文件的函数/变量,
问题2
在main包中的main函数中调用同一个项目下的cacl包中的函数
subtract.go
在main包中使用import导入项目下的cacl包,才能调用其中的方法
package main // 声明 main 包
import (
"GoProject/calc" //导入
"fmt"
)
func main() { // main函数,是程序执行的入口
fmt.Println(calc.Myadd(1, 1)) //2
fmt.Println(calc.Mysubtract(2, 1)) //1
calc.UseAdd(1, 1) //2
}在main中使用calc包中的函数Myadd,如果用变量作为参数传入,该变量大小写都可以
如果要传入结构体参数,结构体的字段必须大写,因为其他包内部需要处理结构体字段,必须大写才能访问到
type user struct{
Name string
Age int
}结论:不同包文件,一个包使用另一个包的函数/变量,需要导出(首字母大写)、导入包,才能调用
import导入包
//导入1个库
import "fmt"
//导入多个库,把flag起一个别名aa
import (
"fmt"
aa "flag"
)
//导入库不使用,会报错。但是有些驱动库,导入后会执行库的init方法(后面会讲到),初始化,不必调用,所以我们可以起别名为"_",就不会报错了
import (
_ "xxxx"
)import导入的是路径(习惯上我们在目录xx下,所有的Go文件都在文件开头声明为package xx)
import "a/b/c" // a/b/c是包所在的路径。一般情况下,包名与文件夹名一样。所以会给人import后是包的错觉
c.xxx() //调用包c中的xxx方法如果路径和路径下的包名不一致如何?
import d "a/b/c" //使用别名d
d.xxx() //使用别名d调用包中的xxx方法init函数
在每一个Go源文件中,都可以定义任意个如下格式的特殊函数:
func init(){
// ...
}这种特殊的函数不接收任何参数也没有任何返回值,我们也不能在代码中主动调用它
包内部,init先执行,再执行其他代码
包之间,按照下图规则,以保证main函数执行时,所有init函数已经执行完毕
Go语言不允许循环依赖,即 a依赖b,b依赖a的情况

Go Module(module)
很多教程中,将module和package都翻译成包,这会造成极大的混淆
这里,module指模块,package指包
go module是官方推出的版本管理工具,Go1.16版本以后已经成为默认开启的依赖管理工具
- 一个项目就是一个模块(module),根目录下要有一个
go.mod - 一个module下可以有多个包(package)
- Go标准库就是一个模块(module)
- 项目中的依赖是第三方模块(module)
所以,你应该反应过来,一个Go项目既可以单独的作为Go项目开发,也可以直接作为别人的Go项目中依赖
模块管理
相关命令
| 命令 | 介绍 |
|---|---|
| go mod init 项目名 | 初始化项目依赖,生成go.mod文件 |
| go get | 拉取远程的第三方模块(模块会被下载到GOPATH下/mod目录) |
| go mod download | 根据go.mod文件下载依赖 |
| go clean -modcache | 清理GOPATH下的mod目录 |
| go mod tidy | 新建go.mod文件后,可以用这个命令将项目中使用的第三方依赖,写到go.mod文件中 |
| go mod graph | 输出依赖关系图 |
| go mod edit | 编辑go.mod文件 |
| go mod verify | 检验一个依赖包是否被篡改过 |
| go mod why | 解释为什么需要某个依赖 |
go mod init
初始化项目为一个module,生成go.mod文件记录了整个项目的依赖关系
例如:
go mod init xxx生成的go.mod的一般格式,注意:indirect表示项目中没有直接用到这个依赖包,即间接依赖
//项目名
module xxx
//项目使用go语言的版本
go 1.18
//项目依赖的第三方模块
require github.com/q1mi/hello v0.1.1 // indirectgo get
这个命令主要用来拉取远程的第三方模块(module)
目前支持的模块地址有 BitBucket、GitHub、Google Code 和 Launchpad,其中最常用的就是GitHub, go get 命令会根据模块地址来使用对应的代码管理工具,如 Git、SVN等去拉取代码
以Github为例子,第三方模块地址的格式如下:
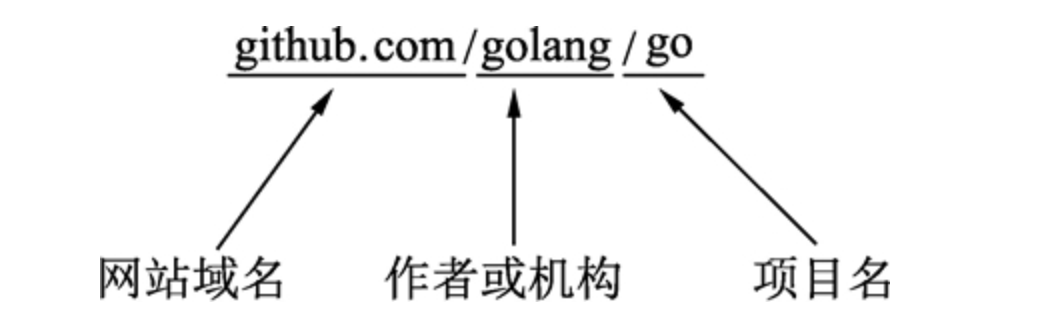
拉取安装模块:(-u参数,如果依赖发布了新的版本,就会强制本地更新依赖的版本)
# 默认拉取GitHub主分支最新的代码
go get -u github.com/q1mi/hello
# 拉去指定分支最新的代码
go get -u github.com/q1mi/hello@master
# 也可以指定版本,如果没有发布过版本,默认拉取最新代码
go get -u github.com/q1mi/hello@v0.1.0
# 也可以通过commit hash拉取
go get github.com/q1mi/hello@2ccfaddget执行分为两部分:
下载模块源代码
Go通过模块地址的域名能够判断,调用什么本地工具来进行下载,比如github的地址,Go会调用本地安装的Git来克隆源代码名,所以 go get 前,要确定是否安装了对应的工具,并把其配置到了环境变量。支持以下工具:
textBitBucket (Mercurial Git) GitHub (Git) Google Code Project Hosting (Git, Mercurial, Subversion) Launchpad (Bazaar)下载的放置的位置是 GOPATH/mod/网站域名/(默认GOPATH是~/go)
与其他语言不同,Go语言使用依赖并非是把依赖安装到自己的项目下,而是放到了GOPATH下

编译源代码,并添加到环境变量中(与go install不同,go install会将编译的可执行文件保存在GOPATH/bin目录下)
go.mod 文件
记录项目模块名,使用的Go版本,依赖的module
gomodule GoProject go 1.18 require github.com/q1mi/hello v0.1.1 // indirectindirect表示该依赖包为间接依赖,说明在当前程序中的所有 import 语句中没有发现引入这个包go.sum文件
文件会详细记录依赖的模块的详细信息
shell<module> <version> <hash>
import引入第三方模块地址的地址,调用时使用地址中项目名的部分
package main
import (
"fmt"
"github.com/q1mi/hello"
)
func main(){
hello.SayHi() // 调用hello包的SayHi函数
}自定义域名的功能:
实际是,一般企业中只会把代码托管在内部服务器上,而不是其默认支持的GitHub等网站
GOPROXY这个环境变量主要是用于设置 Go 模块的代理,其作用是用于使 Go 在后续拉取模块版本时能够脱离传统的 VCS 方式,直接通过镜像站点来快速拉取。
其默认值是:
https://proxy.golang.org,direct
//由于某些原因国内无法正常访问该地址,,目前社区使用比较多的有两个https://goproxy.cn和https://goproxy.io设置GOPAROXY的方式:
go env -w GOPROXY=https://goproxy.cn,directGOPROXY 允许设置多个代理地址,多个地址之间需使用英文逗号分隔。最后的 direct用于指示 Go 回源到源地址去抓取(比如 GitHub 等)。当配置有多个代理地址时,如果第一个代理地址返回 404 或 410 错误时,Go 会自动尝试下一个代理地址,当遇见 direct”时触发回源,也就是回到源地址去抓取
设置了GOPROXY 之后,get命令就会从配置的代理地址拉取和校验依赖包。当我们在项目中引入了非公开的包(公司内部git仓库或 github 私有仓库等),此时便无法正常从代理拉取到这些非公开的依赖包,这个时候就需要配置 GOPRIVATE 环境变量。GOPRIVATE用来告诉 go 命令哪些仓库属于私有仓库,不必通过代理服务器拉取和校验
go env -w GOPRIVATE="git.mycompany.com"GOPRIVATE 的值也可以设置多个,多个地址之间使用英文逗号分隔。我们通常会把自己公司内部的代码仓库设置到 GOPRIVATE 中,这样就可以正常拉取了
go install
go install 编译源代码,并将生成的可执行文件放置到 GOPATH/bin下,以及添加到环境变量中

发布模块
当我们想要在社区发布一个自己编写的代码模块时,我们该怎么做呢?接下来,我们就一起编写一个代码包并将它发布到github.com仓库
准备模块仓库
新建GitHub仓库,用来存储Go模块。并克隆到本地, 接下来开始编写模块内容
github.com/用户名/项目名初始化项目
初始化项目,创建go.mod文件,其格式必须为:
go mod init github.com/用户名/项目名这里,我新建了一个test-go-module仓库
go mod init github.com/heyingjiee/test-go-module生成的go.mod为
module github.com/heyingjiee/test-go-module
go 1.18编写模块
和正常的Go项目一样,我们新建pkg1目录,并新增以下Go文件。这里我们就有了一个名为pkg1的包
package pkg1
import "fmt"
func SayHi() {
fmt.Println("这里是pkg1包中的函数SayHi")
}我们也可以创建更多包(新建一个pkg2目录)
package pkg2
import "fmt"
func SayHi() {
fmt.Println("这里是pkg2包中的函数SayHi")
}推送模块到远程仓库
推送到GitHub仓库,这样就对外发布了一个Go模块(module)
git add .
git commit -m "init go module"
git push打tag,并推送到远程仓库。tag就是模块的版本号,这里就发布了一个版本号为v1.0.0的版本
git tag v1.0.0
git push origin v1.0.0
#git push origin --tags #推送所有标签Go modules建议的版本号格式如下:
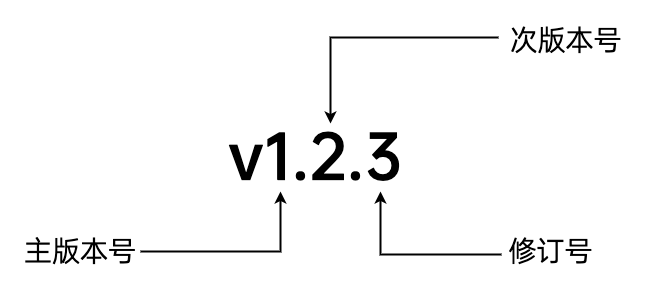
使用模块
在代码中,通过github.com/用户名/项目名的格式引入这个模块
先下载Go模块
go get -u github.com/heyingjiee/test-go-module
//-u 就是如果模块有更新,就下载最新版本的模块
go get -u github.com/heyingjiee/test-go-module@版本号go.mod就会出现这个模块
module app
go 1.18
require (
github.com/heyingjiee/test-go-module v1.0.0 // indirect
)代码中引用,这里需要注意一点,引用地址需要写到包文件所在的根目录
即,Go安装了整个模块,但是使用时只是引入某个包
//mian.go
package main
import (
"github.com/heyingjiee/test-go-module/pkg1"
"github.com/heyingjiee/test-go-module/pkg2"
)
func main() {
pkg1.SayHi()
pkg2.SayHi()
}引入时,还可以重命名模块
import (
abc "github.com/heyingjiee/test-go-module/pkg1"
)
//使用重命名后的新名字引用
abc.SayHi()发布新的不兼容版本
新版本如果是与之前版本不兼容的更新(使用方式方式了变化,比如这里新的版本调用SayHi函数需要一个参数)。例如这里修改了pkg1包中的函数
package hello
import "fmt"
// SayHi 向指定人打招呼的函数
func SayHi(name string) {
fmt.Printf("你好%s\n", name)
}在这种情况下,我们会改变发布模块的名字
例如,我们在模块后加个v2,并将代码打好新的tag: v2.0.0 ,最后推送到GitHub仓库
module github.com/用户名/项目名/v2
go 1.16这样就可以在不影响使用旧版本的用户的前提下,发布出去了新版本
//这个仍然会下载最新的v1.0.0版本
go get -u github.com/heyingjiee/test-go-module
//这里才会下载刚刚我们新增的不兼容版本,也可以在后面追加@版本号,来指定使用v2下的哪个版本
go get -u github.com/heyingjiee/test-go-module/v2通过go.mod也能看出来,其实他们已经变成了两个不同的模块地址了(代码中会保留两个版本)
module app
go 1.18
require (
github.com/heyingjiee/test-go-module v1.0.0 // indirect
github.com/heyingjiee/test-go-module/v2 v2.0.0 // indirect
)引入包时,地址需要加上v2
package main
import "github.com/heyingjiee/test-go-module/v2/pkg1"
func main() {
pkg1.SayHi("张三") // v2版本的SayHi函数需要传入字符串参数
}废弃已发布版本
如果某个发布的版本存在致命缺陷不再想让用户使用时,我们可以使用retract声明废弃的版本。修改项目下的go.mod文件,并打包推送到GitHub仓库
module github.com/用户名/项目名
go 1.16
retract v0.1.2用户使用go get下载v0.1.2版本时就会收到提示,催促其升级到其他版本
模块文档
Go官方提供的模块文档https://pkg.go.dev/
发布Go模块化,在官网上还搜不到,这是因为只有通过proxy.golang.org下载模块的时候,才会自动同步到官网上
"https://goproxy.cn/github.com/heyingjiee/test-go-module使用get拉取后,就能在官网查到了

官网也会自动提取代码中的注释和示例,然后显示在官网的文档中
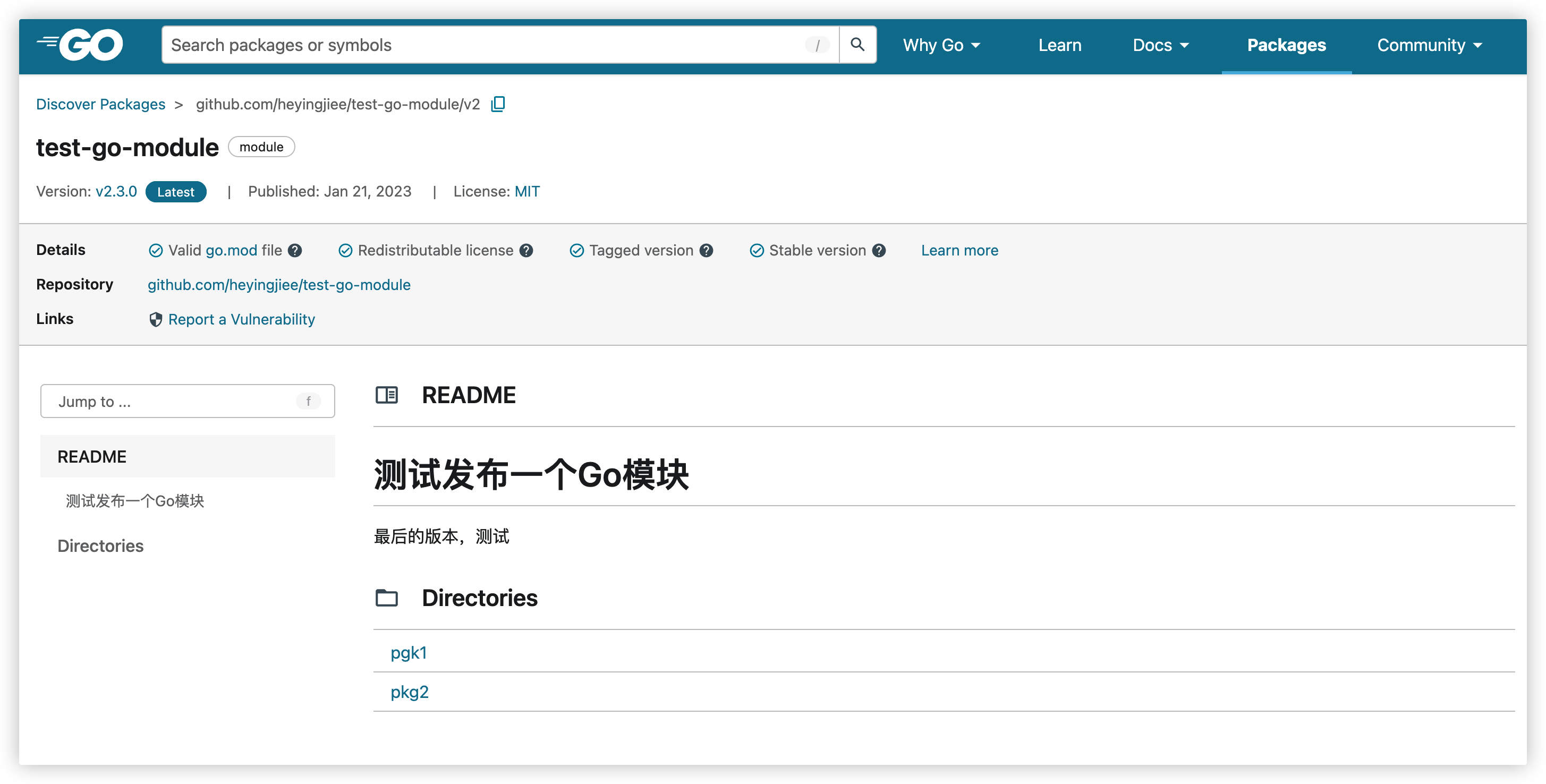
为了更好的显示文档,这里补充下需要添加的文件
添加README文件
添加LICENSE文件(必须添加许可证才能在文档上显示包内的函数等信息)
下面讲下如何在GitHub上添加
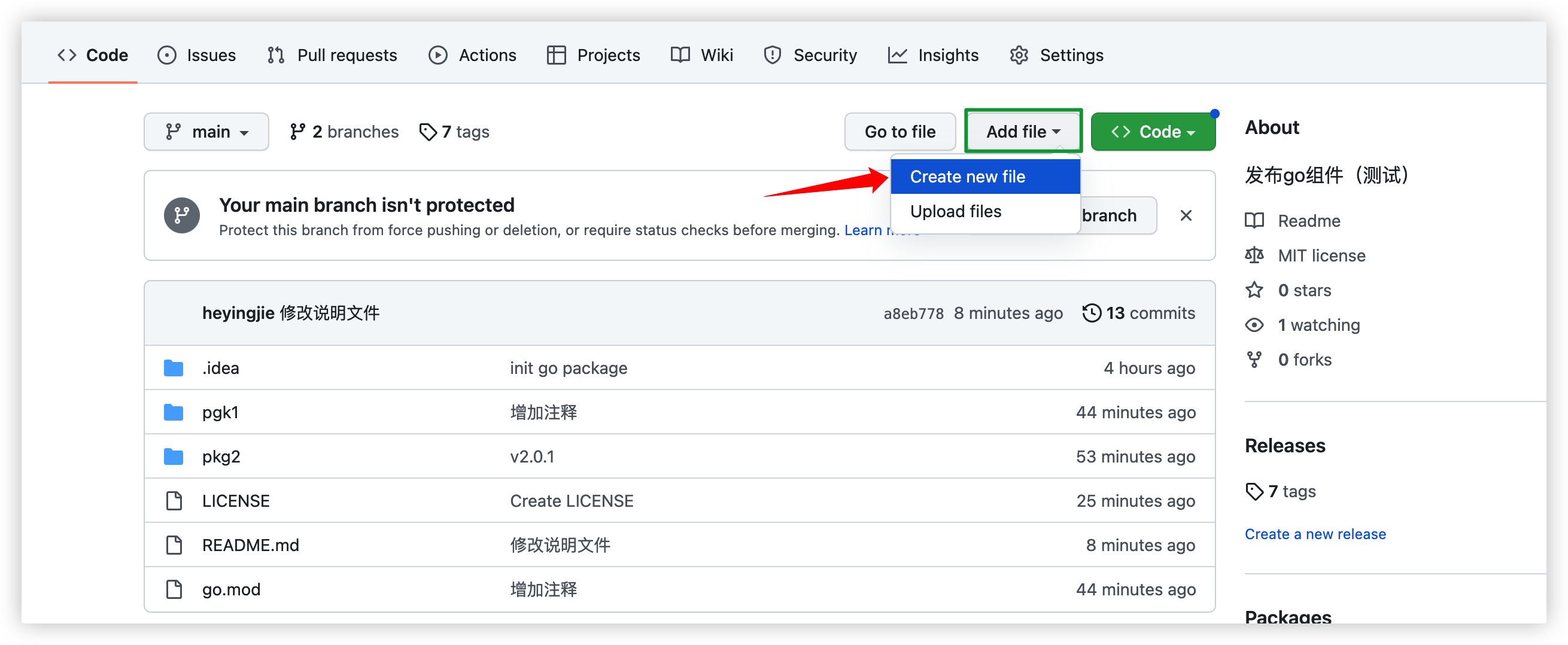
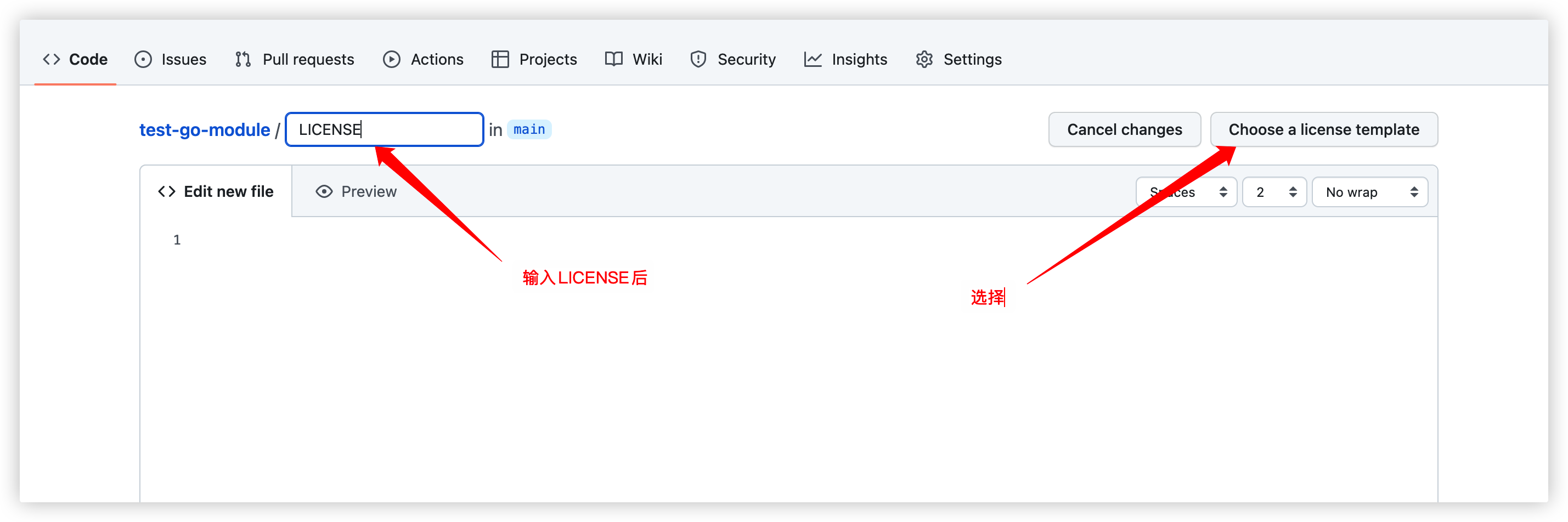
选择MIT协议,提交即可,后面就是PR的流程

本地模块
新建一个testFunc项目,并添加pkg包
go mod init testFunc
另外,新建一个项目
go mod init app在go.mod中引入sdk模块,使用replace关键字将模块执行本地
module app
go 1.18
require sdk v0.0.0
replace sdk => ../testFunc就可以使用本地的模块了
package main
import "sdk/pkg"
func main() {
pkg.GetMessage()
}注意:
本地模块不能放在根目录下,例子中是放在pkg文件夹下的
引用模块中的包时,不能引用模块的main包(一般情况下,第三方模块也不会有main包)

模块的一些理解
最近在学习GitHub上的一个项目 https://github.com/hound-search/hound
我终于弄清楚了一些问题
如果你想改这个项目的Go源码,那就用git clone可以把项目克隆下来,进一步开发
查看这个仓库的README,我发现这个仓库要去使用以下命令
gogo get github.com/hound-search/hound/cmds/... //...是通配符,表示匹配所有文件或者子目录当时,我感觉很奇怪,我整个项目的Go都已经拉到了本地,为啥还当成依赖再装一次cmd目录?
后来,我发现这个项目下的cmd目录就是项目的入口,使用go get主要是因为这个命令的第二步是go install,将目录中的两个main.go编译后,输出到GOPATH/bin目录,这样在全局就可以调用编译后的可执行文件了

如果你想把这个项目当成Go模块,集成到自己的Go项目中
自己的项目得有go.mod文件(
go intit mod)go get下载这个包 (
go get github.com/hound-search/hound/cmds/...)下载完成后,你就会发现一些变化
go.mod增加了依赖,go.sum也增加了这些依赖的详细信息
gorequire ( github.com/blang/semver v3.5.1+incompatible // indirect github.com/hound-search/hound v0.4.0 // indirect )GOPATH/mod/github.com下多了hound-search这个模块
经过对比,使用go get安装的和git clone克隆的项目,一模一样。所以,也验证了前面我提到了的
一个Go项目既可以单独的作为Go项目开发,也可以直接作为别人的Go项目中依赖
Go语言基本规则
Go文件基本规则
不能给其他库定义方法,只给自己定义的结构体,定义方法
其他
gopackage main //包 import "fmt" //引入的Go库 //全局只能声明: "变量/常量/类型/函数" func main(){ // main函数,是程序执行的入口 //函数内可以写 //1.声明 "变量/常量/类型";无法声明函数,但是可以声明匿名函数 //2.语句 //3.流程控制逻辑 //4.调用全局函数 }
Go项目基本规则
习惯上,目录名需与包名相同
--main.go --api |--member.go |--vip.go 1、main.go 是main包中,文件开头是package api 2、member.go、 vip.go 都是属于包api中,文件开头都是package api一般情况下,一个Go项目只能有一个main包,main包一般放在根目录,其中的main函数是整个项目的入口
当然也可以有多个main函数入口
很多时候,我们项目有多个入口,比如一个入口用来启动服务,另一个用来启动客户端
--cmd |--client | |--client.go // package main ,其中有main函数 |--server |--server.go // package main ,其中有main函数
常用的Go的标准库
本章节下涉及的库,凡是没有提供具体使用例子的,均在后面的章节中有使用到
Go标准库文档
builtis
这个库是默认引入的,不用手动引入
库中包括go语言中常用的类型和方法的声明
其他需要引入的库,都需要库名.方法()的形式调用,而builtin库,可直接调用方法
| 内置函数 | 介绍 |
|---|---|
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel |
| cap | 用来求容量比如array、slice、channel |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针 |
| make | 用来分配内存,主要用来分配引用类型,比如chan、map、slice |
| append | 用来追加元素到slice中 |
| copy | 复制slice(slice存储的是引用,必须使用copy才是真正的复制) |
| delete | 删除map键值对 |
| close | 关闭通道 |
| panic和recover | 用来做错误处理 |
fmt
输出
fmt.Print
直接打印
fmt.Println
可输出多个值,最后输出换行符
str := "世界"
str2:="hello"
fmt.Println("你好", str, str2)打印后,换行
fmt.Printf
格式化输出,使用%占位符来控制输出格式,如果想要输出文本%需要使用%%
package main
import "fmt"
func main() {
//---------int-------
n1 := 100
fmt.Printf("%b\n", n1) //1100100 以二进制输出数字
fmt.Printf("%d\n", n1) //100 以十进制输出数字
fmt.Printf("%o\n", n1) //144 以八进制输出数字
fmt.Printf("%x\n", n1) //64 以十六进制输出数字
//---------浮点数-------
n2 := 100.23
fmt.Printf("%f\n", n2) //100.230000 已浮点数形式输出
//---------string--------
str := "你好"
fmt.Printf("%s\n", str) //你好 输出字符串
//---------bool--------
b := true
fmt.Printf("%t\n", b) //true 输出布尔值
//----------所有类型都可以输出-----------
type Stu struct {
name string
age int
hobby []string
}
s := Stu{
name: "jack",
age: 18,
hobby: []string{"唱歌", "跳舞"},
}
fmt.Printf("%T\n", s) //main.Stu 输出变量类型
fmt.Printf("%v\n", s) //{jack 18 [唱歌 跳舞]} 原样输出变量内容,注意结构体只会输出值,不含有字段名
fmt.Printf("%+v\n", s) //{name:jack age:18 hobby:[唱歌 跳舞]} 一般只有结构体使用这个,会输出结构体的字段和值
fmt.Printf("%#v\n", s) //main.Stu{name:"jack", age:18, hobby:[]string{"唱歌", "跳舞"}} 带格式输出,这里的字符串带上了双引号,结构体的类型也会打印
}输入
空白符指:空格、回车(\r、\n )、制表符(\t) 【 在win中换行相当于输入了\r\n , 在mac中换行相当于输入了\r】
fmt.scan
输入值,如果有多个值,用空白符分隔开多个。当分隔开的值个数>参数变量个数时,回车才会结束输入,否则回车会被当做分隔的空白符
var (
name string
age int
)
fmt.Scan(&name, &age)
fmt.Println(name, age)
//输入:a 1 2 3
//输出:a 1fmt.scanln
只要输入回车就会直接结束,如果输入的值个数和参数对应不上,就会报错
var (
name string
age int
)
fmt.Scanln(&name, &age)
fmt.Println(name, age)从上面我们可以知道,空格、回车等作为空白符是不能被scan、scanln读入。所以,这里我们介绍bufio包下的方式
reader := bufio.NewReader(os.Stdin)
str, err := reader.ReadString('\n') //回车结束输入
if err != nil {
fmt.Printf("err-->%v", err)
return
}
fmt.Println(str)fmt.scanf
按照指定格式输入
输出到文件
Fprint
系列函数会将内容输出到一个io.Writer接口类型的变量w中,我们通常用这个函数往文件中写入内容。
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
func Fprintln(w io.Writer, a ...interface{}) (n int, err error)举个例子:
os.Stdout 实现了io.Writer
fmt.Fprintln(os.Stdout, "向标准输出写入内容") //输出到终端了os.File实现了io.Writer
fileObj, err := os.OpenFile("./xx.txt", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
fmt.Println("打开文件出错,err:", err)
return
}
name := "吴彦祖"
fmt.Fprintf(fileObj, "往文件中写如信息:%s", name) //写入到文件了http.ResponseWriter实现了
详见【网络编程】-【Http服务】章节注意,只要满足io.Writer接口的类型都支持写入。
其他
Sprint 、Sprintln、Sprintf
这三个返回返回值是字符串,使用与print系列的一样
res := fmt.Sprintf("name:%s", "张三")
fmt.Println(res) //name:张三Errorf
输入错误字符串 ,详见【接口】-【错误接口】
customError:=fmt.Errorf("查询数据库失败,err:%w", err) //返回值是个error对象strings
string类型字符串的处理方法,详见【类型/字符串】章节
time
当前时间
time包中的Now是构造函数,返回Time结构体。Year、Month...等是Time结构体的方法
注意Now返回的是你当前所在时区的时间
now := time.Now() //时间对象
fmt.Println(now) //2022-05-12 19:17:11.940078 +0800 CST m=+0.000130398
fmt.Println(now.Year()) //2022
fmt.Println(now.Month()) //May
fmt.Println(now.Day()) //12
fmt.Println(now.Hour()) //19(24小时制)
fmt.Println(now.Minute()) //17
fmt.Println(now.Second()) //11时间戳
把时间实例,转化为时间戳字符串
fmt.Println(now.Unix()) //当前时间结构体实例转化为时间戳(单位秒)时间戳转化为时间对象
fmt.Println(time.Unix(1673093066, 0)) //第一个参数是秒,第二个是纳秒时间格式化
Go中用传递格式时,把时间实例转化为字符串,用以下表示对应含义的变量,其他均为字符串,显示到最终格式(记忆口诀为2006 1 2 3 4 5)
2006 年
01 月
02 日
15 时 (如果希望格式化成12小时制,这里用03,结尾加AM/PM)
04 分
05 秒now := time.Now()
//默认24小时制
fmt.Println(now.Format("2006-01-02 15:04:05")) //2022-05-12 00:34:43
// 12小时制:结尾加AM/PM,小时写03
fmt.Println(now.Format("2006-01-02 03:04:05.000 PM"))将字符串转化为时间结构体对象
time.Parse(layout,str) 返回的时间对象是UTC时间,2022-05-15 05:00:00 +0000 UTC
需要使用ParseInLocation(layout,str,location),转化为东八区时间2022-05-15 05:00:00 +0800 CST
loc, err := time.LoadLocation("Asia/Shanghai")
if err != nil {
fmt.Printf("获取时区失败%v\n", err)
}
time, err := time.ParseInLocation("2006-01-02 15:04:05", "2022-05-15 5:00:00", loc)//第一个参数格式化字符串,第二个是待转换的时间字符串。第三个参数是时区
if err != nil {
fmt.Printf("时间转换失败%v\n", err)
}
fmt.Println(time) //2022-05-15 05:00:00 +0800 CST时间间隔
time.Duration是time包定义的一个类型,表示时间的间隔,单位为纳秒。同时time包定义了以下时间间隔常量
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)比如:时间间隔类型*time.Second表示秒的时间间隔,数字常量*time.Second也可以,因为Go会自动把数字常量转化为time.Duration类型
Add
在某一时刻的基础上增加时间间隔
now := time.Now()
n := 10
now.Add(time.Duration(n) * time.Second) //当前时间加10秒的时间实例。now.Add(10* time.Second) 数字会被转化为time.Duration格式Sub
求两个时刻之间的差值:
func (t Time) Sub(u Time) Duration返回一个时间段t-u。如果结果超出了Duration可以表示的最大值/最小值,将返回最大值/最小值
start := time.Now()
time.Sleep(10 * time.Second)
fmt.Println(time.Now().Sub(start)) //10.001114829sEqual
func (t Time) Equal(u Time) bool判断两个时间是否相同,会考虑时区的影响,因此不同时区标准的时间也可以正确比较。
Before
func (t Time) Before(u Time) bool如果t代表的时间点在u之前,返回真;否则返回假。
After
func (t Time) After(u Time) bool如果t代表的时间点在u之后,返回真;否则返回假。
休眠
不建议使用,因为这个函数是真的使得goroutine停止运行等待
time.sleep(时间间隔)
通道相关的时间函数、方法
详见此处
sync
详见【并发编程】章节
sync包提供了基本的同步基元,如互斥锁。除了Once和WaitGroup类型,大部分都是适用于低水平程序线程,高水平的同步使用channel通信更好一些
| 内置函数 | 介绍 |
|---|---|
| sync.WaitGroup | 常用于:控制线进程等待线程计数器为0才终止。Add、Done、Wait |
| sync.Mutex | 互斥锁,使用该结构体类型的Lock和ULock方法 |
| sync.RWMutex | 写锁Lock和ULock;读锁RLock和URLock |
| sync.Once | 涉及到只执行一次的操作 |
| sync.Map | Go中内置的Map类型并不是并发安全的,所以sync包提供了Map |
sync/atomic
类似于sync库中的Map,sync/atomic库中的(int32、uint32、int64、uint64)对于基础类型中(int32、uint32、int64、uint64)实现了并发安全的操作。并且提供了一系列函数对这些类型进行操作
当然,我们也可以不使用这些并发安全的类型,而是使用对变量加锁的方式处理
os文件夹相关
os.Mkdir
os.Mkdir用于创建文件夹
第一个参数是文件夹名
- 默认在当前文件夹创建新的文件夹
- 也可以是文件夹路径,比如
name/jack,注意路径name必须存在,才能在其下建立jack文件夹 - 如果文件夹已经存在,会返回fs.PathError类型的错误。可以使用os.IsNotExist参数为error类型,用来判断返回的错误是否是文件不存在;IsPermission用来判断是否是权限引起的错误
第二个参数是权限位,在前面【os、bufio、io/ioutil读写文件】介绍过
err := os.Mkdir("name/f", 0777)
if err != nil {
res := os.IsNotExist(err)
fmt.Printf("文件不存在:%v", res)
}os.MkdirAll
相对于Mkdir,有两点不同
- 如果name文件夹不存在,就会建立name文件夹后,在cd进去,建立ca文件夹。所以,权限为必须是7【对文件夹有x权限,才能进入文件夹。有w权限,能创建文件夹】
- 如果文件夹已经存在,不会返回err错误
err := os.MkdirAll("./name/ca", 0777)
if err != nil {
fmt.Printf("%v", err)
}例子
判断文件夹是否存在,不存在则创建该文件夹(Stat能判断文件、文件夹是否存在,但是MkdirAll只能创建文件夹)
if _, err := os.Stat("data/b"); err != nil {
if err := os.MkdirAll("data/b", os.ModePerm); err != nil { //os.ModePerm就是0777
fmt.Printf("创建文件夹出错%v\n", err)
}
}os/exec
官方文档:https://studygolang.com/pkgdoc
exec包可以用来执行外部命令
下面这个例子是用来克隆Git仓库的(电脑上必须装好Git)
func Clone(dir, url string) (string, error) {
//分隔传入的路径,filepath.Split将最后一级路径和前面的部分分开。
//本例中,par=/Users/yc/Documents ; rep=goProjec
par, rep := filepath.Split(dir)
//Command中写入执行的命令。“git clone --depth 1 仓库地址 克隆下来的代码存放的文件夹名”
cmd := exec.Command(
"git",
"clone",
"--depth", "1",
url,
rep)
//Dir指定命令的工作目录。如为空字符串,会在调用者的进程当前目录下执行
cmd.Dir = par
//执行命令并返回标准输出和错误输出合并的切片。out是执行命令返回的值,err是错误对象
out, err := cmd.CombinedOutput()
if err != nil {
log.Printf("Failed to clone %s, see output below\n%sContinuing...", url, out)
return "", err
}
}
Clone("/Users/yc/Documents/goProject","git地址")os/filepath
官方文档:https://studygolang.com/pkgdoc
处理路径的包。众所周知,Win和Mac、Linux的路径格式不同,但是为了能代码能在不同平台通用,所以要使用filepath中的函数,其会自动根据平台系统处理路径
IsAbs
IsAbs判断是否是绝对路径,返回布尔值
fmt.Printf("%v\n", filepath.IsAbs("a/b")) //false
fmt.Printf("%v\n", filepath.IsAbs("/a/b")) //trueAbs
Abs将参数拼接为绝对路径
str, err := filepath.Abs("a/b")
if err != nil {
fmt.Printf("%v\n", err)
}
fmt.Printf("%v\n", str) //转化的绝对路径是:/Users/yc/Documents/GO/Gotest/a/b如果原本就是绝对路径,就原样返回
Dir
去掉路径的最后一级和它前面的斜杠
fmt.Println(filepath.Dir("/foo/bar/baz.js")) //路径:/foo/bar
fmt.Println(filepath.Dir("/foo/bar/baz")) //路径:foo/bar特殊情况,最后一级没有目录或文件名
fmt.Println(filepath.Dir("/foo/bar/baz/")) //路径:/foo/bar/baz
fmt.Println(filepath.Dir("/dirty//path///")) //路径:/dirty/path特殊情况,相对路径
fmt.Println(filepath.Dir("dev.txt")) //路径:.
fmt.Println(filepath.Dir("../todo.txt")) //路径:..
fmt.Println(filepath.Dir("..")) //路径:.
fmt.Println(filepath.Dir(".")) //路径:.特殊情况,绝对路径
fmt.Println(filepath.Dir("/")) //路径:/特殊情况,空字符串
fmt.Println(filepath.Dir("")) //路径:.Join
拼接路径,返回的都是相对路径
出一个参数外,上下的参数
b、/b、b/、/b/是一样的,都是在原来路径的下一级gofmt.Println(filepath.Join( "a" , "b" , "c" )) //输出: a/b/c fmt.Println(filepath.Join( "a" , "b" , "/c" )) //输出: a/b/c fmt.Println(filepath.Join("a", "b", "c/")) //输出: a/b/c fmt.Println(filepath.Join("a", "b", "/c/")) //输出: a/b/cgofmt.Println(filepath.Join( "a" , "b/c" )) //输出: a/b/c fmt.Println(filepath.Join( "a" , "/b/c" )) //输出: a/b/c fmt.Println(filepath.Join( "a" , "b/c/" )) //输出: a/b/c fmt.Println(filepath.Join( "a" , "/b/c/" )) //输出: a/b/c第一个参数,决定了 返回的是不是绝对路径
gofmt.Println(filepath.Join( "a" , "b" , "c" )) //输出: a/b/c fmt.Println(filepath.Join( "/a" , "b" , "c" )) //输出: /a/b/c../../b,是在原来路径的上上级记住一个技巧,有几个点
..就把前面的路径去掉几个gofmt.Println(filepath.Join( "a/b" , "../../../xyz" )) //输出: ../xyz fmt.Println(filepath.Join("a/b", "../xyz")) //输出:a/xyz
glob
返回glob匹配的文件,类型是切片

strSlice, err := filepath.Glob("data/**/*.txt")
if err != nil {
fmt.Printf("%v\n", err)
}
fmt.Printf("%v\n", strSlice) //[data/B/b.txt data/B/c.txt]Split
filepath.Split(dir)例子
import "path/filepath"
if !filepath.IsAbs(c.DbPath) {
path, err := filepath.Abs(
filepath.Join(filepath.Dir(filename), c.DbPath))
if err != nil {
return err
}
c.DbPath = path
}如何用?
func xx(){
//-----获取文件路径(类似node的__filename)-----
// 参数 0 表示,当前函数调用者(如果参数是1,表示当前函数调用者的调用者)
// 参数为0时,file是就是函数所在文件的决定路径。
_, file, _, ok := runtime.Caller(0)
if !ok {
fmt.Println("Could not retrieve caller information")
return
}
//-----获取文件所在目录(类似node的__dirname)-----
filepath.Dir(file) // Dir函数会裁剪文件的最后一级
//-----获取项目根目录-----
filepath.Abs('.')
filepath.Abs('src')// (项目根目录 + src)的绝对路径
}os/signal
接收信号
用一个容量是1的通道接收信号量
Notify
- 第一个参数为通道,将后面参数指定的信号量转发到该通道
- 第二个、三个、四个...指定可被转发的信号量(如果接收到的是这里指定的信号量,才能被转发到通道)
func registerShutdownSignal() <-chan os.Signal {
shutdownCh := make(chan os.Signal, 1)
signal.Notify(shutdownCh, gracefulShutdownSignal) //gracefulShutdownSignal就是syscall.SIGTERM
return shutdownCh
}处理信号
func handleShutdown(shutdownCh <-chan os.Signal, searchers map[string]*searcher.Searcher) {
go func() {
<-shutdownCh
info_log.Printf("Graceful shutdown requested...")
//在这里要把项目的多线程任务全部结束
//for _, s := range searchers {
// s.Stop()
//}
os.Exit(0)
}()
}runtime
获取go运行时环境的相关信息
GOMAXPROCS
设置并发的最大线程数,并返回先前的设置。 若 n < 1,它就不会更改当前设置。
NumCPU 可查询本地机器的逻辑CPU数
runtime.GOMAXPROCS(runtime.NumCPU()) //根据当前cup个数,将goroutine跑在多个系统线程上注意: GOMAXPROCS 默认值为CPU数,但是在容器中 runtime.GOMAXPROCS() 获取的是 宿主机的 CPU 核数 。这样会导致 P 值设置过大,导致生成线程过多。使用 uber 的 automaxprocs 库
Caller
Caller报告当前go程调用栈所执行的函数的文件和行号信息。可用于用户记录日志时,记录当前位置的信息
参数:skip为上溯的栈帧数,skip=0表示Caller的调用者(Caller所在的调用栈)
返回值:调用栈标识符、文件名、该调用在文件中的行号。如果无法获得信息,ok会被设为false
func Caller(skip int) (pc uintptr, file string, line int, ok bool)log
用于日志收集
net、net/http、net/url
使用详见【网络编程】章节
errors
详见【接口类型】下的【错误接口】章节
reflect
详见【反射】章节
crypto/md5、crypto/sha256
这两个库是用来进行签名的
MD5加密一条数据
package main
import (
"crypto/md5"
"fmt"
)
func MD5(str string) string {
data := []byte(str) //切片
has := md5.Sum(data)
md5str := fmt.Sprintf("%x", has) //将[]byte转成16进制
return md5str
}
func main() {
MD5("go语言学习笔记")//08aae6d0d841eff8ba8772ddf8551157
}MD5加密多条数据
package main
import (
"crypto/md5"
"fmt"
"io"
)
func main() {
hasher := md5.New()
//只写一个内容,和上面加密一条是一样的。这里可以通过io.WriteString写入多个数据
io.WriteString(hasher, "go语言学习笔记") //把内容写入Hash实例里
md5str := fmt.Sprintf("%x", hasher.Sum(nil))
fmt.Println(md5str) // //08aae6d0d841eff8ba8772ddf8551157
}MD5加密文件
本质仍然是将内容添加到hasher,因为是加密文件所以,使用Copy函数写入
f, err := os.Open("file.txt")
if err != nil {
log.Fatal(err)
}
defer f.Close()
hasher := md5.New()
if _, err := io.Copy(hasher, f); err != nil {
log.Fatal(err)
}
fmt.Printf("%x", hasher.Sum(nil))sha256签名
补充知识:
HMAC(Hash-based Message Authentication Code)算法是一种基于密钥的消息认证码算法,可以简单理解为给哈希算法加了"盐"
HMAC-SHA256,即使用SHA256作为散列函数的HMAC算法
func Sign(secret, data string) {
hasher := hmac.New(sha256.New, []byte(secret))
//hash实例提供了实现了io.Writer
_, err := hasher.Write([]byte(data))
if err != nil {
fmt.Printf("err-->%v", err)
return
}
res := hasher.Sum(nil)
fmt.Printf("%x\n", res)
}判断两个HMAC签名是否相同
hmac.Equal(signA, signB)base64
sig, err := base64.RawURLEncoding.DecodeString("1234")golang.org/x/ 系列包和标准库包有什么区别?
在开发过程中可能会遇到这样的情况,我们会遇到一些特殊的包,例如:
golang.org/x/net/html和net/htmlgolang.org/x/crypto和crypto
为什么会存在两种包?
Go 标准库的包对向前兼容性有严格的标准
而 golang.org/x/... 系列包虽然也是 Go 项目的一部分,但是它使用了比 Go 标准库包更宽松的兼容性标准。作为官方的辅助包,是一种具有官方试验性质的包,可能存在BUG, 或者可能健壮性不好,但是其中成熟的功能,也会慢慢的放到标准库包里
标识符
GO语言变量编译规则
函数内声明的变量必须使用,否则报错
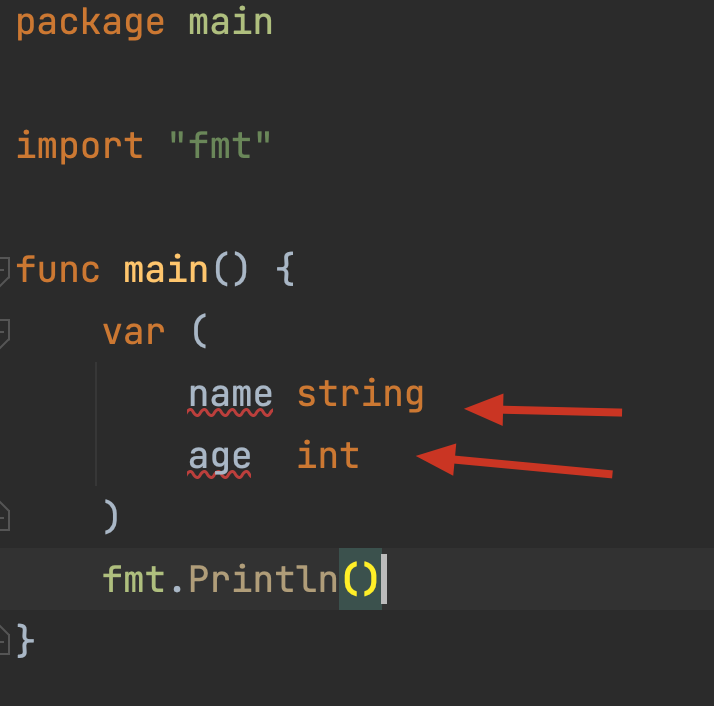
全部声明的变量,可以不使用【因为可能这个文件可能作为包,其中的全局声明被其他文件使用】
变量
声明变量
注意:go变量在声明时,就初始化了默认值的零值
字符串默认为空字符串,
整型和浮点型数字默认 0
布尔值默认为false
指针、函数、接口、切片、映射、通道类型的零值默认为nil
一般变量声明
var name string多个同类型变量一起声明
var age, stuNum int //同时定义两个变量为int批量声明
var (
name string
age, stuNum int
)初始化
一般形式(变量声明的3种方式,初始化我都写了一遍)
var name string= "jack"
var age, stuNum int =18,1220 //分别赋值给了age=18,stuNum=1220
var (
name string="jack"
age, stuNum int =10,1220
)右值推导(变量声明的3种方式,都可以用)
var name = "jack" //根据值推断name为string类型
var age, stuNum =18,1220
var (
name ="jack"
age, stuNum =10,1220
)简短变量初始化
name := "jack"**匿名变量 **
多用于接收,函数返回值中某个不想使用的值
var _ string = "jack"注意:shadow 变量
package main
import "fmt"
func main() {
var v int=0
condition := true
if condition {
// 内层使用:=,相当于创建了新的变量 。应该直接使用 v = 2
v := 2
fmt.Println(v) // 2
}
fmt.Println(v) // 0
}常量
常量使用关键字const,基本与var一样 ,只有以下区别:
- 常量定义后不能修改
- 常量声明时,必须初始化
- 常量的有''批量声明'语法
- 常量不能使用' 简短变量声明 '语法
初始化
一般形式
const name string = "jack"
const age, stuNum int =18,1220
const (
name string = "jack"
age, stuNum int = 18, 1220
)右值推导
就是上面的代码,省略类型批量声明注意点:
批量声明中不赋值,默认继承上一个值
goconst ( n1 =100 n2 n3 //n2、n3默认为100 n4 =200 n5 //n5默认为200 )iota常量
这里列举的用法比较全面:https://zhuanlan.zhihu.com/p/372117921
go//iota=行数-1 //随后的每行iota的值加1 const ( n1 = 10 //10 n2 //10 n3 = iota //2 n4 //20 n5 = iota //默认为iota,其值为4。第5行 )模拟枚举类型
这种用法在time标准库用到了,定义了一些了time的常量,可以在作为参数传入time包中的函数
gopackage Calc type Level uint8 const ( INFO Level = iota //0 WARNING //1 ERROR //2 ) func xx(le Level){ if le>WARNING{ //这里就变成了数字的比较 //提示 } } //使用 import "Calc" Calc.xx(Calc.ERROR)
**匿名变量 **
多用于接收,函数返回值中某个不想使用的值
const _ string = "jack"基本类型
整型
有符号 :int8、int16、int32 、 int64
无符号 :uint8、uint16、uint32 、 uint64
特殊
- int #系统是32位就与int32一样,系统是64位就与int64一样
- unit #同上
- uintptr # uintptr 类型只有在底层编程时才需要,特别是Go语言和C语言函数库或操作系统接口相交互的地方。不同类型仅仅是占用bit大小不同,存储的数字上下限范围不同。例如
int64,有64个二进制位,但是其最高位为符号位,1表示负数,0表示正数
故,剩下的有2^63个组合(每个位置有0、1两种可能,共63个位置,所以是2^63)
范围-2^63到(2^63)-1uint64,有64个二进制位,
故,可以表示2^64个数字,即0到(2^64)-1通常int的范围已经足够我们使用了,但是因为int变量占据的内存大小,会随着运行平台而变化,可能会出现平台运行差异
- 在 32 位架构上,
int通常是 32位。 - 在 64 位架构上,
int通常是64位。
类型推断默认将整数推断为int
package main
import "fmt"
func main() {
n1 := 10
fmt.Printf("%T\n", n1) //int 补充%T可以看到变量类型
}赋值不同进制的数字
package main
import "fmt"
func main() {
n1 := 12
n2 := 077 //八进制,以0开头,后面的77是八进制数
n3 := 0xfff //十六进制,以0x开头,后面的fff是十进制数
fmt.Printf("%d--%d--%d\n", n1, n2, n3) //按照十进制输出 12--63--4095
//%d是把数字按十进制输出
//%b是把数字按二进制输出
//%o是把数字按八进制输出
//%x是把数字按十六进制输出
}数字与字符串基础
通常在各种语言中,为了区分数字的进制,使用不同前缀开头代表不同的进制
2:表示是十进制数字
02:表示是八进制数字(0为前缀)
0x2:表示十六进制数字(0x为前缀)
0b1010:表示二进制数字(0b为前缀)
数字2,在三种进制中区别不大,再换一个明显点的数字19
19=023=0x13我们知道字符底层是使用数字表示的,所以,我们也可以直接在代码中使用("前缀+十六进制数字")的形式表示某个字符
\x:表示一个ASCII字符的十六进制编码。后面必须跟两个十六进制数字,且只能表示ASCII字符范围内的字符"\x41" => 十六进制41 => 对应字符 "A" (查询ASCII表)
\u:表示一个Unicode字符的十六进制编码。后面必须跟四个十六进制数字"\u0041"表示字符"A" "\u00A9"表示版权符号"©" \u开头标识为一个字符,后面接十六进制的Unicode编码(一个Unicode编码对应一个字符,也称为一个码点)
下面是等价对应关系
字符在ASCII范围内:
"A" = "\x41" = "\u0041"
字符超出ASCII范围:
"世" = "\xe4\xb8\x96" = "\u4e16" (十六进制数字4e16)
汉字 "世" ,已经超出了ASC码的编码范围,所以它用了多个码点标识这一个汉字还有一点极易混淆
"A"、"\u0041"、"\x41"都是是字符,代码里想用数字表示字符,需要用引号
str := "\u0041"
fmt.Printf("%v\n", str)而直接把字符按照十六输出的是数字,而不是字符,所以也不会有\x、\u的前缀
str := "A"
fmt.Printf("%x\n", str) // 41浮点型
float32
float64类型推断默认将浮点型推断为float64
package main
import "fmt"
func main() {
n1 := 10.1
fmt.Printf("%T\n", n1) //float64
}布尔型
bool只有true、false两个值
package main
import "fmt"
func main() {
n1 := false
}字符串
基本概念
- 字节:存储单位(B)
- 字符:字符串中的每一个元素叫做“字符”,例如一个汉字、一个字母
一个字符,可能占用多个字节的存储空间
字符编码问题
基础:GO使用的是Unicode编码集,按照UTF-8编码存储,UTF-8是可变长度的,1个UTF-8字符,占据1~4个字节(byte)
一个汉字是1个UTF-8字符,占据3个字节
一个英语字母/数字是1个UTF-8字符,占据1个字节(Unicode完全包含了ASCII码集,英语字母都在ASCII码集的范围内,存储ASCII码集只需要一个字节)
与其他语言类型基本相同,Go语言中凡是涉及字符串长度和索引的方法,实际上都是按照字节(byte、B)计算的,所以字符串中出现汉字就会造成不准确的问题
字符串中的每一个元素叫做“字符”,在遍历或者单个获取字符串元素时可以获得字符。字符串使用"",字符使用''
Go语言的字符有以下两种:
- 一种是 byte 类型(1字节,byte是uint8类型的别名。byte类型为啥本质是uint8呢?想下8个bit位刚好是一个字节大小)
- 另一种是 rune 类型(1~4字节,rune是 int32 类型的别名),代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型
日常我们处理的字符串往往是 汉字和字母 的,所以全部使用rune
package main
import "fmt"
func main() {
n1 := "hello"
//原样输出
n2:=`
hello
world
`
}反引号中不能放置变量,只能是常量。与JS中的模版字符不同,如果想要字符串中放置变量,必须使用Sprintf
Sprintf
返回格式化后的字符串
name := "jack"
str := fmt.Sprintf("你好%v", name)
fmt.Println(str)字符串基本使用
注意:Go中字符串可以使用索引访问,但是不允许修改,所以经常转化为切片处理
package main
import (
"fmt"
)
func main() {
str := "你好"
//长度(字节长度)
fmt.Println(len(str)) //6
//+拼接
fmt.Println(str + "123") //你好123
//访问(索引指的是几个字节)
fmt.Printf("%v\n", str[0]) //0xe4 (0xe4是一个十六进制数,对应十进制的228)因为汉字是由多个字节组成,这里只能访问到第一个字节
//字符串可以截取切片,注意[0:1]是左闭右开,取得是第一个字节。截取的类型是字符串
fmt.Printf("%T\n", str[0:1])//string
fmt.Printf("%x\n", str[0:1]) //e4 ,这里如果使用%v占位符就会输出乱码,所以使用%x输出第一个字节的16进制数字
fmt.Printf("%v\n", str[0:3]) //你 ,这里如果使用%v占位符就会输出乱码
//修改,注意:Go中的字符串是不允许修改的,所以返回一个字符串转化的rune切片,rune切片的每个元素是一个UTF8字符,对切片进行处理。(原字符串不变)
runeArr := []rune(str) //类型(变量)这是强制转换的语法
runeArr[0] = '我'
fmt.Println(string(runeArr)) //我好
println(str) //你好
}字符串的相关方法
package main
import (
"fmt"
"strings"
)
func main() {
str := "hello,world你好"
fmt.Println(len(str)) //17
//分割成切片
arr := strings.Split(str, ",")
fmt.Printf("%v\n", arr) //[hello world你好]
//是否包含
fmt.Println(strings.Contains(str, "h")) //true
//是否是前缀
fmt.Println(strings.HasPrefix(str, "he")) //true
//是否是后缀
fmt.Println(strings.HasSuffix(str, "ld")) //false
//查找,返回索引
fmt.Println(strings.Index(str, "ld")) //9
fmt.Println(strings.LastIndex(str, "好")) //14
//把切片拼接成字符串。注意,第一个参数类型是字符串切片[]string
fmt.Println(strings.Join(arr, "+")) //hello+world你好
//去除空行
fmt.Println(strings.TrimSpace(" aa ")) //aa
}上面说了len统计的是字节数,一个汉字字符占位多个字节。那么如何精确统计字符数量
str := "你好"
fmt.Println(len(str)) //6 ,字节
fmt.Println(utf8.RuneCountInString(str)) //2
//转成rune切片,计算切片长度
fmt.Println(len([]rune(str))) //2类型转换
JS中令我最为头疼的就是它的类型转换,各种类型之间都可以随意转换(感觉很多转换完全没有实际意义),还存在各种隐形转换
Go语言中,必须显式的转换,而且某个类型只能转换到其他的几个特定类型
数字型
int与uint
Go语言默认的数字是十进制的int型(有正负),仅可以将正数int转化为uint类型
uint类型可直接转化为正数int
fmt.Println(uint(111))int float 相关的类型可以互相转换,注意:可能会造成精度丢失
i := 12.56
fmt.Println(int(i)) //12j := 12
fmt.Printf("%T , 结果:%v\n", float32(j), float32(j)) //float32 , 结果:12
fmt.Printf("%T , 结果:%v", float64(j), float64(j)) //float64 , 结果:12字符串
转换的意义:在Go中字符串底层一旦创建是不可改变的,而切片是可以自由截取修改的,所以我们时常将字符串转化为切片处理,然后再转换回字符串。请阅读:关于切片的操作技巧
string --> []rune 或者 []byte
str := "你好"
//注意:0x开头表示是16进制数据
//两个汉字占了6个字节,所以byte数组有6位。
fmt.Printf("%#v\n", []byte(str)) //[]byte{0xe4, 0xbd, 0xa0, 0xe5, 0xa5, 0xbd}
//两个汉字是两个UTF8字符,所以rune数组有2位。对于两个字符的Unicode编码
fmt.Printf("%#v\n", []rune(str)) //[0x4f60 0x597d]string <-- []rune 或者 []byte
str := "你好"
fmt.Printf("%#v\n", string([]byte(str))) //"你好"
fmt.Printf("%#v\n", string([]rune(str))) //"你好"string --> []string
//字符串可以截取切片,注意[0:1]是左闭右开,返回值是string类型
fmt.Printf("%x\n", str[0:1]) //e4
//然后将字符串推入一个字符串切片即可
append()string <-- []string
字符串切片不能通过string函数直接转化为字符串,需要使用Join函数
strSlice := []string{"你", "好"}
fmt.Printf("%#v\n", strings.Join(strSlice, "")) //"你好"额外的关于底层的一些介绍:
string的底层是byte array(不可变字节数组),并不是slice或者数组,所以string与slice的转换是拷贝,会损耗性能
s := "abc"
b := []byte(s) // 做了一次拷贝,分配了一个新的字节切片。所以修改b不会影响s
s2 := string(b) //构造一个字符串拷贝可以看出转换的过程中涉及大量的内存分配,所以Go提供 strings 提供了许多实用函数,这些函数可以直接处理字符串,而不需要转化为切片处理后再转化为字符串。详见这里
bytes 包还提供了 Buffer 类型用于字节 slice 的缓存。一个 Buffer 开始是空的,但是随着 string 、 byte 或 []byte 等类型数据的写入可以动态增长,一个 bytes.Buffer 变量并不需要初始化,因为零值也是有效的:
- WriteByte 写入一个字节,
ASCII字符是一个字节,因此这个函数多用于写入ASCII字符 - WriteString 写入字符串
package main
import (
"bytes"
"fmt"
"strconv"
)
func intsToString(values []int) string {
var buf bytes.Buffer
buf.WriteByte('[')
for i, v := range values {
if i > 0 {
buf.WriteString(",")
}
buf.WriteString(strconv.Itoa(v)) //数字转成字符,才能作为WriteString的参数
}
buf.WriteByte(']')
return buf.String()
}
func main() {
fmt.Println(intsToString([]int{1, 2, 3})) // "[1, 2, 3]"
}字符串与数字之间
大多使用strconv这个Go标准库
数字-->字符串
i := 12
//方法1:
fmt.Printf("类型:%T,值:%v \n", strconv.Itoa(i), strconv.Itoa(i)) //类型:string,值:12
//方法2:Sprintf返回值就是字符串,甚至能通过指定占位符%b、%o、%x转换进制
res := fmt.Sprintf("%d", i)
fmt.Printf("类型:%T,值:%v \n", res, res) //类型:string,值:12数字<--字符串
两种方案参数必须是整数字符串,否则就会抛出err
方案1:
package main
import (
"fmt"
"strconv"
)
func main() {
x, err := strconv.Atoi("123")
if err != nil {
fmt.Printf("err:%v\n", err)
return
}
fmt.Printf("类型:%T,值:%v \n", x, x) //类型:int,值:123
}方案2:
package main
import (
"fmt"
"strconv"
)
func main() {
//参数1:为待转换的字符串
//参数2:指定把字符串当成是进制的数字
//参数3:为字符串转换的int类型。0表示int,16表示int16。最后会转化为int64返回
//返回结果为:int64 类型
x, err := strconv.ParseInt("12", 3, 64)
if err != nil {
fmt.Printf("err:%v\n", err)
return
}
fmt.Printf("类型:%T,值:%v \n", x, x) //类型:int64,值:5
}千万不要:
//直接强制转换实际是做了Unicode的解码、编码
fmt.Println(string(65)) //A
fmt.Printf("%x", int('啊')) //554A流程控制
if
package main
import "fmt"
func main() {
age := 18
if age <= 18 {
fmt.Println("青年") //青年
} else if age < 60 {
fmt.Println("中年")
} else {
fmt.Println("老年")
}
}Go中还允许,在 if 表达式之前添加一个执行语句,再根据变量值进行判断
package main
import "fmt"
func main() {
if age := 18; age <= 18 { //注意这种写法,只有if内部能访问到该age变量
fmt.Println //青年
} else if age < 60 {
fmt.Println
} else {
fmt.Println("老年")
}
//age在外面访问不到
}死循环,会一直循环
for{}for
break、continue 与其他语言相同,注意:break只能结束一层for循环
一般形式
package main
import "fmt"
func main() {
for i := 1; i < 10; i++ {
fmt.Println(i)
}
for true{
fmt.Println("无限循环")
}
}类while
Go中不支持while关键字,for可以到达相同的效果
for{
// xxx
}for range
Go语言中可以使用for range遍历数组、切片、字符串、map 、通道(channel)
- 数组、切片、字符串返回
索引、值。 - map返回
键、值。 - 通道只返回通道内的
值
支持数字
for i := range 10 {
fmt.Printf("%d\n", i) // 输出 0 ~ 9
}遍历字符串、切片
package main
import "fmt"
func main() {
// 字符串
str := "a它e"
for index, value := range str {
fmt.Printf("%v-%v\n", index, value)
}
// 切片
s := []int{5, 2, 3}
for index, value := range s {
fmt.Printf("%v-%v\n", index, value)
}
}遍历map
m := map[string]interface{}{
"name": "tom",
"age": 18,
}
for key, value := range m {
fmt.Printf("%v:%v\n", key, value)
}注意点:
便利过程中,重新赋新值不会影响源数据
type account struct {
balance float32
}
accounts := []account{
{balance: 100},
{balance: 200},
{balance: 300},
}
for _, a := range accounts {
a.balance += 1000
}
// [{100} {200} {300}]如果想要修改,必须直接修改源数据
for i := range accounts {
accounts[i].balance += 1000
}slice的话,也是需要修改源数据
func main() {
nameList := []string{"tom", "jack"}
for index, item := range nameList {
nameList[index] = item + "1"
}
fmt.Println(nameList)
}
//[tom1 jack1]switch
- 与if相同,switch也可以添加一个执行语句,再根据变量值进行判断
- case
- 一个case可以有多个值,用逗号隔开(一般其他语言,case只能有一个值)
- 如果某个case符合,就走到该case中,执行完毕,就结束(不用break关键字)
- case执行体中只有一句
{}可以省略
- 只能有一个default,当所有case都不符合,则走到default
func testSwitch3() {
switch n := 7; n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
case 2, 4, 6, 8:
fmt.Println("偶数")
default:
fmt.Println(n)
}
}运算符
累加
在Go里面i++、i--是独立的语句,不再是运算符
所以,以下写法是错误的
i=i++C语言中的++i、--i的用法,在Go中不存在
算数运算符
加、减、乘、除、取余
关系运算符
返回布尔值
==
!=
>
>=
<
<=逻辑运算符
| 运算符 | 描述 |
|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则为 True,否则为 False。 |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则为 True,否则为 False。 |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则为 False,否则为 True。 |
位运算符
日常开发业务极少使用,但是涉及底层的库经常会用到
位算法符是二进制计算符号,只不过我们代码中一般只写十进制。下面的例子都是使用5、3做运算,也可以使用对应的二进制0b0101、0b0011
位运算符包括:
+二进制加法规则:0+0=0,0+1=1, 1+1=0向高位进1
go5+3 = 8 // 底层二进制表示是 0101 0011 ------ 1000-二进制减法法规则:0-0=0,1-0=1,1-1=0,0-1=1从高位借1
go5+3 = 2 // 底层二进制表示是 0101 0011 ------ 1000&(与)二进制对应位都为1,结果为1。否则为0
go5&3 = 1 // 底层二进制表示是 0101 0011 ----- 0001实际意义:x&0011表示:保留x后两位,其余位置为0
|(或)对应位只要一个为1,结果为1。否则为0
go5&3 = 7 // 底层二进制表示是 0101 0011 ----- 0111实际意义:x|0000表示:低4位全部保留
^(异或)位于两数之间,对应位不相同,结果为1。否则为0;
位于一个数之前,则按位取反
go5^3 = 6 // 底层二进制表示是 0101 0011 ----- 0110>>(右移)x>>y,表示x的二进制位右移y位
数高位补0,负数高位补1。结果正数仍然为正数,负数仍然为负数
go12 >> 2 // 右移2位 ,输出: 3 12对应的二进制为 1100 => 右移2位得 11 =>高位补0得 0011 => 转化为十进制 3 // 实际上:删除低y位,在剩余高位补0<<(左移)x<<y,表示x的二进制位右移y位,低位补0
go1<<2 // 左移2位 100 // 实际上:在低位不出y位实际意义: for循环中使用1<<2,可以每次读入两位,然后<<2就会把读入的数据推到高位上,剩下低两位继续读入数据
&^(按位清零)对于两个相应的二进制位,如果
&^右侧的位是 1,则结果中的相应位为0(清零),否则保留左侧的值
还有一个二进制计算,取负数。
十进制取负数:
5 取负为 -5
二进制如何取负数:
0b00000101 取负为 0b11111011
计算:
第一点8位表表示一个数字 => 每位都取反后,最后一位+1
注意:
可通过最高位判断正负,0表示正数,1表示负数二进制位运算最有意思的是:一大片看起来似乎没有意义的位运算,居然有实际的含义
1<<n - 1取 n 位都是1的二进制数go// 1<<24 => 1后低位补24个0 =>00000001 00000000 00000000 00000000 // 1<<24-1 => 0-1向高位借1 => 00000000 11111111 11111111 11111111 1<<24 - 1 // 取24位都是1滑动窗口
例子窗口为3个字节(24位)
例如文件内容为 abcde ,读取结果为 abc、bcd、cde
gotv := uint32(0) n :=0 // (1<<24 - 1) 表示24位都是1的二进制数 // x&(1<<24 - 1) 表示保留x的低24位,剩余高位置为0 for{ // 读入文件(暂时不考虑错误处理) temp=make([]byte,10) n,_:=f.Read(temp) temp=temp[:n] // 保留24位,低8位0 tv = (tv << 8) & (1<<24 - 1) // x|0000,表示保留x的低4位。这里表示 将temp的第一个字节(8位)赋值给tv的低8位 tv=tv|temp[0] // 下一次循环 ,tv会把这一次读入的8个字节推到高位,留出来低8位继续放置读入的字节 if n++; n > 3 { // 读入了3个字节,把数据处理下 } }
数组类型
数组声明
[数组长度] 元素类型
var arr [10]int
fmt.Printf("%T\n", arr) //[10]intGo语言与其他大多数语言一样,都是定长数组。这一点不如JS的可变长度数组使用的方便
数组初始化
不初始化,数组元素默认为零值
字符串默认为空字符串,
整型和浮点型数字默认 0
布尔值默认为false
初始化
arr1 := [4]int{1, 2, 3, 4}
fmt.Println(arr1) //[1 2 3 4]
arr2 := [4]int{1, 2}
fmt.Println(arr2) //[1 2 0 0]
arr3 := [4]int{0: 1, 3: 2}
fmt.Println(arr3) //[1 0 0 2]
arr4 := [...]int{1, 2, 3, 4, 5, 6}
fmt.Println(arr4) //[1 2 3 4 5 6]数组长度
len()数组遍历
package main
import "fmt"
func main() {
arr := [4]int{1, 2, 3, 4}
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}
//1
//2
//3
//4
for index, value := range arr {
fmt.Printf("%d--%d\n", index, value)
}
//0--1
//1--2
//2--3
//3--4
}数组是值类型
与JS中不同,Go中的数组是值类型的
这也就意味着,赋值给其他变量,就是直接把数组复制了一份给其他变量
package main
import "fmt"
func main() {
arr1 := [4]int{1, 2, 3, 4}
arr2 := arr1
arr2[0] = 10
//1
//2
//3
//4
for index, value := range arr1 {
fmt.Printf("%d--%d\n", index, value)
}
//0--1
//1--2
//2--3
//3--4
}切片类型
补充:关于切片的操作技巧
切片(Slice)是基于数组类型做的一层封装,是一个拥有相同类型元素的可变长度的序列。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合
与JS中的数组基本相同,区别是只能存储相同类型的数组元素
初始化
四种方式:
func main() {
// 方式1: 值为nil ,长度为0。 这种方式来的好处就是不用指定初始slice大小,使用append追加元素(用的最多)
var s []string
log(1, s)
// 方式2: 值为nil ,长度为0。 用得少
s = []string(nil)
log(2, s)
// 方式3:值为[],长度为0。比较适合初始化一个已知元素的 slice
s = []string{} // 这种其实就是字面量,s= []string{1,2,3}
log(3, s)
// 方式4:值为[],长度为2
s = make([]string, 0)
log(4, s)
}
func log(i int, s []string) {
fmt.Printf("len=%v nil=%t\n", len(s) , s == nil)
}
// 输出
len=0 nil=true
len=0 nil=true
len=0 nil=false
len=0 nil=false从上面例子可知,判断切片为空应该使用
通过 len(切片)==0 来判断,是否切片为空 ( 值为 nil、[] 两种情况)四种方式使用场景不同:
方式1:初始化一个空的切片,然后后续通过append追加元素
str := "你好"
var slice1 []string
res := append(slice1, str[0:3]) //append向空切片中追加元素,后面会讲到
fmt.Printf("%v\n", res) //[你]方式2:不常用
方式3:字符值字面量,可以直接赋值给变量
s := []string{"a","b"}注意:切片子元素是结构体的情况
type Stu struct {
Name string
Age int
}
func main() {
var StuCollection=[]Stu{
Stu{Name:"tom",Age:12},
Stu{Name:"jack",Age:19}
}
// 简写
var StuCollection = []Stu{
{Name: "tom", Age: 12},
{Name: "jack", Age: 19},
}
// 或者
var StuCollection=[]Stu{
{"tom",12},
{"jack",19}
}
}方式4:
make(切片类型,长度,容量),返回切片,make会默认把切片元素初始化为零值(下面例子是[]int,所以默认的零值是0)
slice1 := make([]int, 5, 10)
fmt.Println(slice1) //[0 0 0 0 0]
slice1 := make([]int, 5) //一个参数,就 默认长度和容量都为5
fmt.Println(slice1) //[0 0 0 0 0]这种很适合知道切片大小,但是不知道初始值的情况。具体来说就是赋值场景,提前用make申请一块空间,将其他切片存进来(copy会在后面讲到)
slice1=[]int{1,2,3,4,5,6}
slice2=make([]int,2)
copy(slice2,slice1[0:2]) // 截取2位拷贝到slice2的空间里从数组截取切片
数组[开始位置索引:结束位置索引的下一个],一个左闭右开的集合
arr1 := [...]int{1, 2, 3, 4, 5} //数组
fmt.Println(arr1[1:3]) //[2 3]
fmt.Println(arr1[1:]) //[2 3 4 5]
fmt.Println(arr1[:]) //[1 2 3 4 5]从字符串截取切片
str := "123789"
fmt.Printf("%v", str[2:])//3789从切片截取切片
切片的切片,底层仍然是最初的数组,所以容量是4
arr1 := [...]int{1, 2, 3, 4, 5} //数组
slice1 := arr1[1:3]
fmt.Println(slice1) //[2 3]
slice2 := slice1[0:1]
fmt.Println(slice2) //res是[2]
fmt.Println(cap(slice2)) //4切片的长度和容量
直接初始化的切片,底层数组就是初始的切片大小,所以容量和长度一样大
从数组截取的切片,底层数组的从截取开始位置到数组结束位置的大小为容量
切片可以扩容的,所以容量是可以大于底层数组的限制的
len() //切片的长度
cap() //容量 底层数组的从截取开始位置到数组结束位置的大小举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图如下。切片s2 := a[3:6],相应示意图如下:
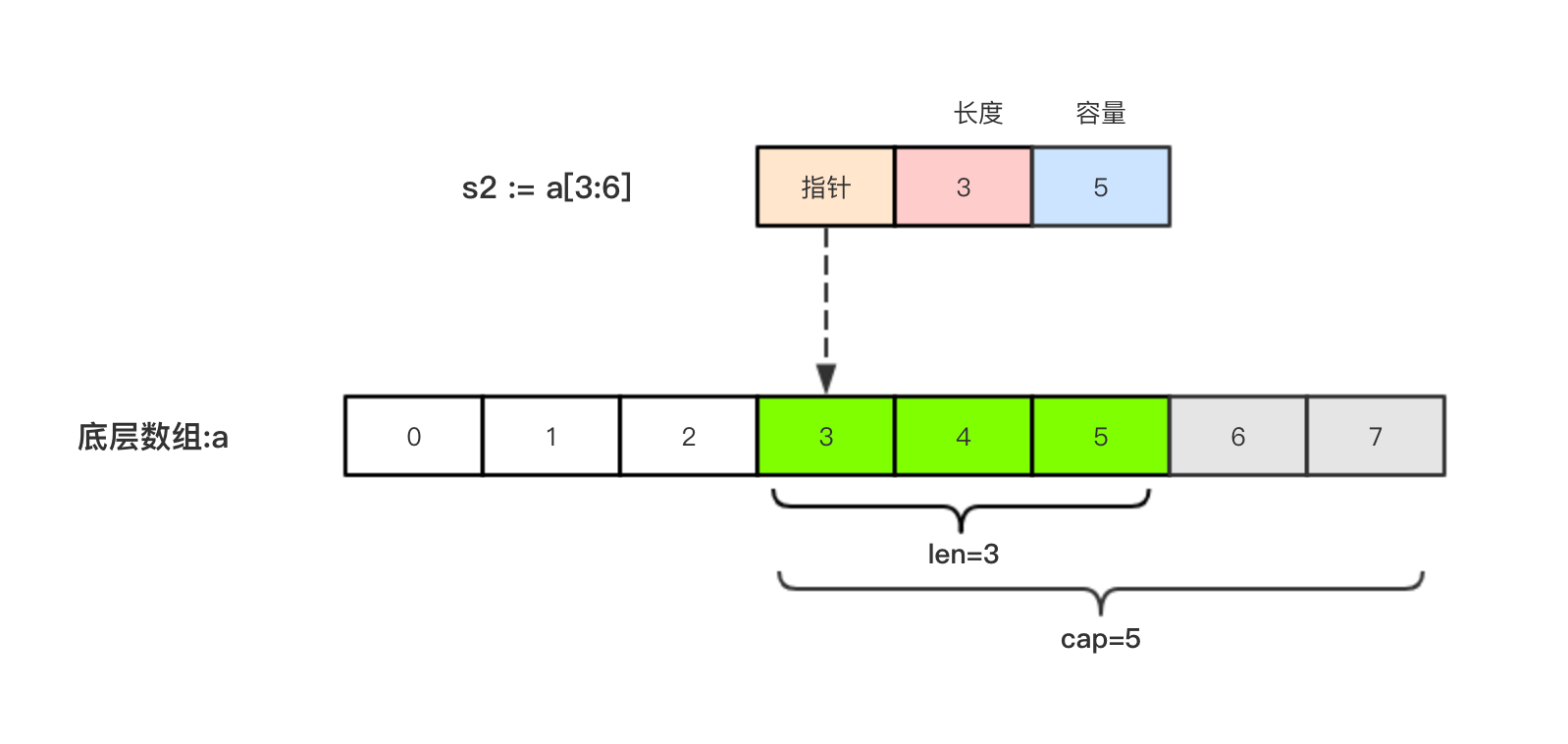
切片是引用类型
切片只是底层数组的引用,所以修改切片/底层数组,所以相关的值也会一起改变
//例子展示的是两个使用同一底层数组的切片,修改其一,都会跟着变
slice1 := []int{1, 2, 3, 4}
slice2 := slice1
slice2[0] = 100
fmt.Println(slice1) //[100 2 3 4]我们可以使用copy函数,实实在在的拷贝一份新的数据
切片的遍历
依然是for和for range两种 。⚠️slice 是 nil 也不会报错而是直接结束 for 循环
for index, value := range slice {
// 在这里处理每个元素的索引和值
}append:切片的追加
下面的例子可以看出来,append是对底层数组进行了扩容
⚠️slice1 是 nil 也能扩容
slice1 := []int{1, 2, 3}
slice2 := append(slice1, 4, 5) //追加元素
fmt.Println(slice1) //[1 2 3]
fmt.Println(cap(slice1)) //3
fmt.Println(slice2) //[1 2 3 4 5]
fmt.Println(cap(slice2)) //6 //这里可以看出来,新的切片底层数组,把原来的底层数组扩容了还可以将切片追加到另一个切片
slice1 := []int{1, 2, 3}
slice2 := []int{4, 5, 6}
slice3 := append(slice1, slice2...) //...是展开语法
fmt.Println(slice3) //[1 2 3 4 5 6]思考:切片不存储值,永远是底层数组存储值
slice1 := []int{1, 2, 3, 4, 5}
slice2 := slice1
//更改slice2,删除2,实际上还是在底层数组[1 2 3 4 5]上操作
slice2 = append(slice2[0:1], slice2[2:]...)
fmt.Println(slice1) //[1 3 4 5 5]copy:切片复制
直接赋值,只是把地址赋值过去了。copy(dest,src),是将src复制值后,覆盖到dest中,返回值是覆盖的元素个数,dest切片发生改变
slice1 := []int{1, 2, 3}
slice2 := []int{4, 5}
slice3 := []int{4, 5, 6, 7}
fmt.Println(copy(slice2, slice1)) //2
fmt.Println(slice2) //[1 2]
fmt.Println(copy(slice3, slice1)) //3
fmt.Println(slice3) //[1 2 3 7]合并两个slice(这种用法非常常见)
slice1 := []int{1, 2, 3}
slice2 := []int{4, 5, 6}
finalLen := len(slice1) + len(slice2)
finalSlice := make([]int, finalLen)
copy(finalSlice, slice1)
copy(finalSlice[len(slice1):], slice2)
fmt.Printf("%v\n", finalSlice)注意截取操作导致的内存泄露
如果arr很大,我们虽然只持有res,但是底层的数组仍然无法释放,会造成内存泄露
res := arr[:36]
// 后面一直持有res变量可以使用copy拷贝arr的数据,存储到res中
res:=make([]int,16)
copy(res,arr[:36])同理,虽然Go中的string底层不是数组,而是固定字节数组,但是截取字符串仍然可能造成内存泄露
可是内置的Clone方法拷贝字符串
str := "cascascsaasa"
str2 := strings.Clone(str[:3])切片删除
Go中没有提供切片和数组的删除,我们只能自己实现
思路就是: 数组——>切片——>截取需要保留的切片部分——>append拼接
补充
入参
func f(args ...string){
//args未切片,[]string
}展开
res=append(args...) //展开切片args指针类型
Go语言中指针没有指针的运算
//1.返回类型是指针类型(指针存储了变量的地址)
&普通变量 //返回变量的地址,类型是指针
new(类型) //返回变量的地址,类型是指针
//2.指针类型的变量
*变量 //*变量=1中返回的地址
//3.声明指针时,不初始化,默认初始化为nil
var ptr *int指针的类型
*存储的类型
//例如:
*int
*stringnew和make的区别
- new和make都是用来申请内存的,,make申请内存后返回
- new用来给基本数据类型和结构体(Struct)申请内存,例如:
string、int。new申请内存后返回指针,例如:*int、*string - make用来给
slice、map、channel类型申请内存,make申请内存后,返回对应类型本身
map类型
也叫映射,是无序的key-value的形式
是一种引用类型(和切片一样),但是 map 必须要初始化后才能使用
声明map类型变量
map初始化时,是nil
var a map[string]int //key是string,value是int类型的map
fmt.Println(a == nil) //true想要在map中保存数据,必须初始化(回忆下前面,切片不初始化也可以保存数据)
初始化map类型变量
初始化内存空间两种方式
指定容量
m := make(map[string]int, 8) //容量是8个键值对,可以省略第二个参数
fmt.Println(m == nil) //false,开辟内存空间后就不再nil不指定容量
m := make(map[string]int)
fmt.Println(m == nil) //false,开辟内存空间后就不再nil初始化值(默认就分配了内存空间)
//初始化为空map
m := map[string]string{}
m["name"] = "jack"
//初始化的时候map中已经有了键值对
m2:= map[string]int{"姓名": 1,"年龄": 10}添加键值对
初始化后,就可以向map中添加键值对了
- 必须初始化空间才能存储
- 空间不足,会自动扩容
m["年龄"] = 12自动扩容
m := make(map[string]int, 1)
m["1"] = 1
m["2"] = 2
m["3"] = 3
fmt.Println(m) //map[1:1 2:2 3:3]删除键值对
删除m中键值为"姓名"的键值对
delete(m, "姓名") // ⚠️m 为 nil 执行 delete 也不会报错,只是静默失败判断是否存在key
m := map[string]int{
"姓名": 1,
"年龄": 10,
}
value, ok := m["姓名"]
if ok {
fmt.Printf("存在value:%v\n", value) //存在value:1
} else {
fmt.Println("不存在")
}遍历
只有for range遍历
m := map[string]int{
"姓名": 1,
"年龄": 10,
}
for key, value := range m {
fmt.Printf("%v:%v\n", key, value)
}
//姓名:1
//年龄:10嵌套
map就像是JS中的对象,slice就像是JS中的数组,两者可以组合拼凑出各种形式来存储数据。但是远没有JS灵活
形式一 :切片内部是多个map
JS中如下的形式
jsarr=[{name:"tom",age:20},{name:"jack",age:19}]go[]map[string]int //这是一个切片类型,切片内元素的类型是map初始化一个这种类型的变量,可以分别使用make申请内存
goslice := make([]map[string]int, 0, 8) slice[0] = make(map[string]int, 10) //元素是map,仍然需要再次申请内存 slice[0]["年龄"] = 18也可以,以初始化值的方式申请map的内存
goslice := make([]map[string]int, 0, 8) slice[0] = map[string]int{ "年龄": 18, }当然也可以,全部使用初始化值的方式(我更推荐这种)
goslice := []map[string]int{ {"年龄": 18, "身高": 180}, {"年龄": 19, "身高": 185}, } fmt.Println(slice) //[map[年龄:18 身高:180] map[年龄:19 身高:185]]形式二:map内部的value部分是切片
这里演示使用值初始化
gom := map[string][]string{ //map的键是string,值是切片 "姓名": {"tom", "jack"}, "性别": {"男", "男"}, }
技巧:记住Go中使用值初始化map和切片,都用的{}
m := map[string][]string{ //第一层花括号是初始化map的,元素用逗号分隔
"姓名": {"tom", "jack"},//这一层花括号是初始化切片的,元素用逗号分隔
"性别": {"男", "男"},//这一层花括号是初始化切片的,元素用逗号分隔
}函数类型
声明函数
Go中函数没有默认参数,GO语言设计者认为,所有东西在Go中应该是明确的,包括参数
Go语言的参数,是把实参的值拷贝到形参
Go语言支持多返回值
函数定义的位置(回忆下),记住:函数体内部可以调用其他函数,但是不能在函数体内定义其他函数
我们在main函数外定义函数,在main中调用

函数声明
func 函数名(形式参数列表)(返回值列表){
函数体
}匿名函数
func (形式参数列表)(返回值列表){
函数体
}函数类型
var f func(int) int //定义变量f的类型是 入参、反参都是int的函数
f = func(i int) int {
return i
}参数列表
func f1(x int, y int) int {
return 1
}简写:x、y是int,z是string
func f1(x, y int, z string) int {
return 1
}展开语法:使用展开语法的函数必须放在最后
package main
import "fmt"
func f1(x string, y ...int) { //y的类型是切片
fmt.Println(x)
fmt.Println(y)
return
}
func main() {
f1("a", 1, 2, 3, 4)
//a
//[1 2 3 4]
}返回值列表
当没有返回值时,返回值列表可以省略
类型返回值和明明返回值,不能混用
类型返回值
gofunc f1() int { //一个可以省略括号 return 1 } func f1() (int, string) { return 1, "a" }命名返回值
相当于在返回值部分就已经声明了要返回的变量名
最后写一个return即可,就会按照返回值列表顺序,返回所有的值
gofunc f1() (x int) { //注意:括号不可省略 x = 2 return } //定义多个命名返回值,与参数一样,也支持简写 func f1() (x, y int, z string) { x = 2 y = 2 z = "a" return } //返回 2,2,a遇到这种情况也要知道,用户可以在return时,手动设置返回的值
gofunc f1() (x,y int) { x = 1 y = 2 return 3,4 //将x赋值为3,y赋值为4 } f1() //返回3,4如果手动设置,必须将所有返回值都设置了
go//这种写法是错的 func f1() (x,y int) { x = 1 y = 2 return 3 }
立即执行函数
func 函数名(参数列表)(反参列表){
}(传入的参数列表)例子
func f(i int) {
fmt.Printf("%d\n", i)
}(i)
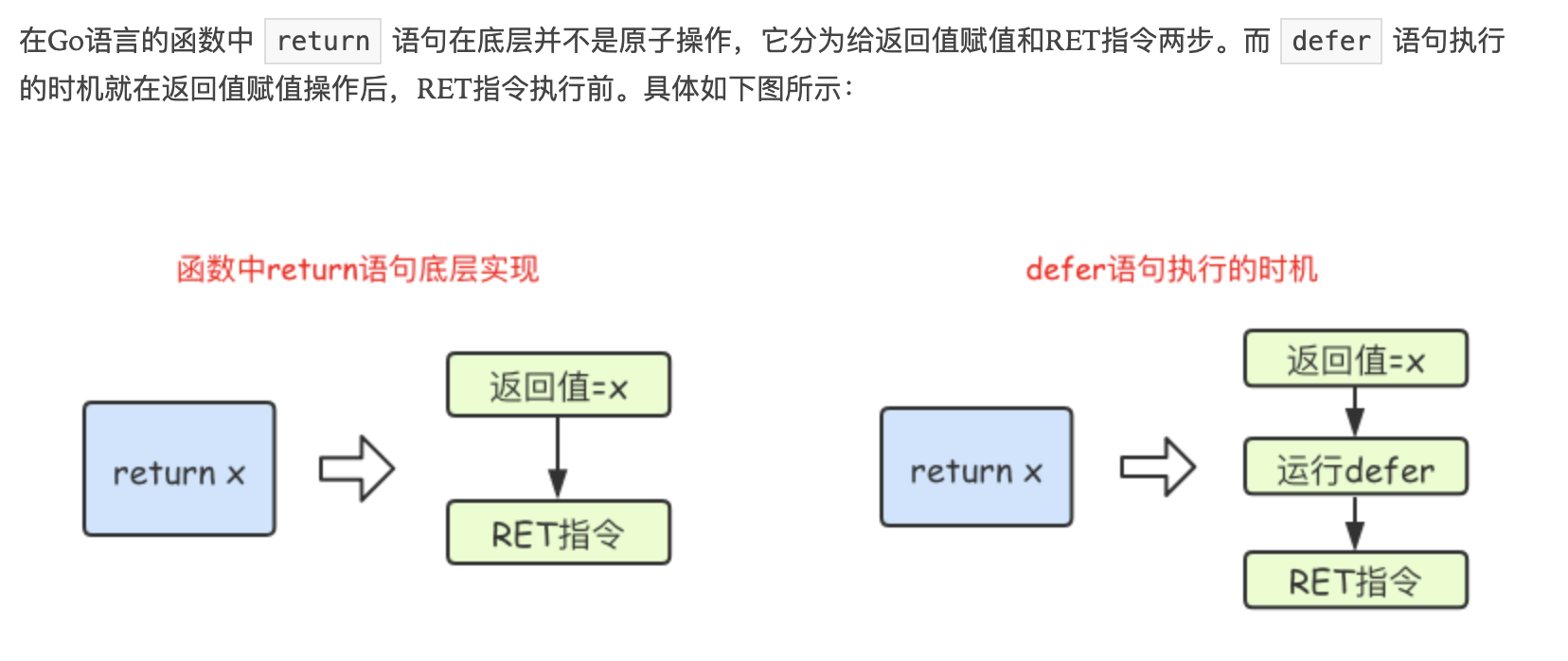
f(1) //1defer
将语句延迟到return时执行(不写return,函数会有默认的return),多个defer语句,按照"后来先执行"的顺序执行
package main
import "fmt"
func fun1() {
fmt.Println("1")
defer fmt.Println("2")
fmt.Println("3")
defer fmt.Println("4")
}
func main() {
fun1()
//1
//3
//4
//2
}defer 被调用的时候就已经确定了,而不是在 defer执行的时候
// 这里调用defer时i=0
func main() {
i := 0
defer fmt.Println(i) //0
i++
return
}
// 这里调用defer时传入的是一个函数调用。函数在最后执行时读取的i=2
func main() {
i := 0
defer func() {
fmt.Println(i + 1) //2
}()
i++
return
}return后如果是表达式,会先执行 return的表达式 ==> defer ==> return 值
package main
import "fmt"
func A() (int, error) {
defer fmt.Println(2)
return fmt.Println(1)
}
func main() {
A()
}
//1
//2应用场景:提前设置关闭
func fun1() {
链接数据库
defer 关闭数据库链接
数据库操作1
数据库操作2
return
}
函数类型
var f1 func(x int) int //定义变量f1为函数类型,这个函数参数是int,返回值是int
var f2 func() //定义变量f2为函数类型,这个函数无参数,无返回值函数参数和函数返回值
既然函数是一种变量类型,所以也可以作为其他函数的参数,也可以作为其他函数的返回值
作为参数:类似于JS中的回调函数,但是Go中没有JS的箭头函数这种简写方式
govisit([]int{1, 2, 3, 4}, func(v int) { //xxxx })作为返回值:类似JS中的闭包概念
自定义类型
自定义类型
type 自定义类型名 类型定义类型别名
type 别名 = 类型两者区别
别名可以看成起了一个乳名,判断变量类型输出的还是大名
func main() {
type test = int
var a test = 1
fmt.Printf("%T\n", a) //int
}自定义类型,是真的定义了一个全新的类型
func main() {
type test int
var a test = 1
fmt.Printf("%T\n", a) //main.test
}结构体类型
与C语言的结构体一样,其实就是帮助我们构造一些复杂的类型
结构体
结构体
一般结构体与type一起使用,定义新类型
type Stu struct {
name string
age int
score []float64
}匿名结构体
// 变量user的类型为一个匿名的结构体
var user struct{Name string; Age int}初始化结构体实例
package main
import "fmt"
type Stu struct {
name string
age int
}
func main() {
// 1、初始变量为 空的Stu实例,Stu字段值为默认零值
var s1 Stu
// 2-1、与1效果相同
s2:=Stu{}
// 2-2 初始化带值的实例
// 按字段顺序 (用的少)
s3 := Stu{
"男",
18,
}
// 按字段名 (用的多)
s := Stu{
name: "tom",
age: 20,
}
}通过结构体字段名,访问结构体实例
p := Stu{
name: "jack",
age: 14,
}
// 获取
fmt.Printf("%v\n", p.name) //jack
// 修改
p.name="tom"特殊情况
下面的写法很少见到,但是也确实是正确的语法
结构体字段也支持匿名字段,也支持匿名字段可以和命名字段混合使用,Go中匿名字段用类型当作key名
//注意:因为匿名字段是以类型作为区分的,所以同一个类型只能充当一个匿名字段
type Stu struct {
int //匿名字段
string //匿名字段
name string //命名
}初始化匿名字段的方式
// 按字段顺序
res := Stu{
18,
"男",
"jack",
}
// 按字段名
res := Stu{
int:18,
string:"男",
name:"jack",
}访问匿名字段(以类型名作为key,所以使用类型名)
Stu.int // 18struct也支持简写
type Stu struct {
name,age int //name和age都为int类型
score []float64
}嵌套结构体
结构体内部字段的类型除了基本类型,还可以是函数类型(后面讲到方法时,会提到这个情况)、其他结构体类型甚至结构体指针
嵌套子结构体
package main
import "fmt"
type Address struct {
city string
}
type Stu struct {
name string
age int
Address //这里是混用匿名字段,嵌套了子结构体
}
func main() {
//键值对赋值
res := Stu{
name: "jack",
age: 18,
Address: Address{
city: "北京",
},
}
// 使用类型名Address作为字段名 ,访问子结构体内部的属性
fmt.Println(res.Address.city) //北京
// 直接访问子结构体内部的属性,当结构体中没有这个字段,就回去子结构体查找
fmt.Println(res.city) //北京
}如果结构体属性和子结构体属性名重复了,怎么访问子结构体属性?
//必须使用类型名Address作为字段名 ,访问子结构体内部的属性
fmt.Println(res.Address.city) //北京嵌套指针
访问字结构体的规则同上
type Address struct {
city string
}
type Stu struct {
name string
age int
*Address //这里是混用匿名字段 , 字段的类型是指针
}
//赋值
res := Stu{
"jack",
18,
&Address{
city:"北京",
},
}
//访问嵌套在内部的结构体
fmt.Println(res.Address.city) //北京结构体指针
& 变量取变量的地址
s =&Stu{
name:"tom",
age: 20,
},* 类型、* 变量
指针类型
var s *Stu取地址的值,要求变量存的必须为地址
p:=&Stu{
Name:"tom"
}
fmt.Println(*p)new(变量)返回空实例的地址(等价于创建空的实例,然后取其地址)
s :=new(Stu)
//等价于
s :=&Stu{},
//等价于
var temp Stu //创建一个空的实例
var a = &temp //取地址注意:按道理必须 (*p)才是变量值,才能使用.取成员,但是Go语言做了简化,允许直接使用指针使用.取成员
拷贝
赋值
package main
import "fmt"
func main() {
type Stu struct {
name string
age int
}
//实例tom
tom := &Stu{
name: "tom",
age: 20,
}
//赋值tom实例的地址
temp := tom
//修改temp,tom也会一起更改
temp.name = "jack"
fmt.Printf("%v,%v\n", tom, temp) //&{jack 20},&{jack 20}
}浅拷贝。仅仅拷贝值类型,如果结构体存在指针字段则仍然是赋值地址
package main
import "fmt"
func main() {
type Stu struct {
name string
age int
}
tom := &Stu{
name: "tom",
age: 20,
}
temp := new(Stu)
//赋值tom实例的值
*temp = *tom
//修改temp,tom不会变化
temp.name = "jack"
fmt.Printf("%v,%v\n", tom, temp) //&{tom 20},&{jack 20}
}方法
https://blog.csdn.net/zy_dreamer/article/details/132795614
接触过面向对象语言的人,都知道方法指的就是,实例的函数。但是,在Go无论结构体是否实例化,都可以调用其方法
Go中提供的方法,以一种新的形式为Struct注册函数,这种方式把Struct的定义和注册函数分开成了两部分,个人觉得不够直观。看下面的形式,就能看出来,通过给函数定义加了一个(结构体类型首字母小写 结构体类型)【称之为接收者】,来将其绑定到一个结构体上
注意:
- 相同点:结构体实例、结构体实例指针,均可以两种调用方法(接收者是结构体类型、结构体指针类型)
- 不同点:接收者和参数一样都是值传递,所以指针接收者,可以修改结构体实例的值
func(结构体类型首字母小写 结构体类型)方法名(参数列表)(返回值列表){
}package main
import "fmt"
type Stu struct {
name string
age int
}
//Stu 结构体
func newStu(name string, age int) *Stu {
return &Stu{
name,
age,
}
}
//getAge 定义Stu结构体的方法,接收体是指针
func (s Stu) getAge() int {
return s.age
}
//setAge 定义Stu结构体的方法,接收者是结构体指针,这样才能修改结构体的age字段
func (s *Stu) setAge(age int) {
s.age = age
}
func main() {
//结构体实例调用方法
stu1 := Stu{
name: "jack",
age: 18,
}
stu1.setAge(20)
fmt.Println(stu1.getAge()) //20
//结构体实例指针调用方法
stu2 := &Stu{
name: "tom",
age: 18,
}
stu2.setAge(30)
fmt.Println(stu2.getAge()) //30
}还需要,注意一点,未实例化的结构体,也可以调用其方法
func (s *Stu) p() {
fmt.Println("123")
}
func main() {
var x Stu
x.p() //123
}经过实验,我发现Go的Struct中的类型,也可以是函数类型。
package main
import "fmt"
type Stu struct {
name string
age int
getAge func() int
setAge func(age int)
}
func newStu(name string, age int) *Stu {
return &Stu{
name,
age,
func() int { return age },
func(Myage int) { age = Myage },
}
}
func main() {
res := newStu("jack", 12)
res.setAge(20)
fmt.Printf("%v\n", res.getAge()) //20
}Go语言规则:
不能给其他库定义方法,只给自己定义的结构体,定义方法
模拟继承
利用结构体的嵌套和方法,实现继承效果。结构体可直接调用 ,其内部的子结构体的属性和方法
尤其注意,有时候,我们在看别人代码时会发现,某个结构体实例调用的方法,在代码中找不到这个结构体的方法的实现,这时候,考虑下这个方法是不是其中嵌套的某个结构体实现的方法
package main
import "fmt"
//父结构体 animal
type animal struct {
catogory string
}
func (a animal) run() {
fmt.Printf("父结构的方法:奔跑\n")
}
//子结构体 cat
type cat struct {
feetNum int
animal //匿名字段
}
func (c cat) say() {
fmt.Printf("子结构的方法:喵喵叫\n")
}
func main() {
//实例化父结构体cat
c := cat{
feetNum: 4,
animal: animal{
catogory: "猫科",
},
}
//1、父结构体,调用自己的属性
fmt.Printf("%v\n", c.feetNum) //4
//2、父结构体,调用自己的方法
c.run() //父结构的方法:奔跑
//3、父结构体,调用子结构体的属性(必须省略子结构体嵌入父结构体时,指定的key)
c.say() //子结构的方法:喵喵叫
//4、父结构体,调用子结构体的方法 (如果没有命名冲突可以省略key)
fmt.Printf("%v\n", c.animal.catogory) //猫科
fmt.Printf("%v\n", c.catogory) //猫科
}结构体的包导出
前面在【Go Module】章节,已经学过了声明标识符首字母大写,就可以被导出
这里强调下:
package student
type Stu struct{
Name string
age int
}这里强调下,Stu被导出,其中只有Name能访问
Student.Stu.NameJSON
JSON对于一个前端来说最熟悉不过了,JS中的对象字面量可以很轻易的转化为JSON字符串
一般,使用结构体定义数据格式,然后创造出符合结构体结构的数据,这个数据本身就具有和JSON一样的数据层次,所以才能转化
注意:这里有一个大坑,定义的结构体名和结构体字段,必须首字母大写,否则encoding/json库(序列化与反序列化的函数,都是用的这个库)中的方法不能接收到这个参数结构体
总结:
- 序列化、Marshal、Encoder,转化为JSON
- 反序列化、UnMarshal、Decoder,转化为GO语言的变量结构
序列化
将Go中的数据转化为JSON格式的字符串,这个过程叫做序列化
Marshal
v可以是值、指针,对于复杂结构体推荐使用指针类型,减少拷贝v带来的性能损耗
gofunc Marshal(v interface{}) ([]byte, error)例子:前面讲过的切片(slice)和映射(map),组合的数据就符合JSON的结果,能成功转化为JSON字符串
gom := map[string][]string{ "姓名": {"tom", "jack"}, "性别": {"男", "男"}, } data, err := json.Marshal(m) if err != nil { fmt.Println("err") return } fmt.Printf("%s", data) //{"姓名":["tom","jack"],"性别":["男","男"]}例子:切片(slice)和 结构体(struct)【实例化的结构体和map相似】也能达成这种效果
gopackage main import ( "encoding/json" "fmt" ) //Student 学生 type Student struct { Name string Age int } //Class 班级 type Class struct { Title string Students []*Student } func main() { c := &Class{ Title: "101", Students: make([]*Student, 0, 200), } stu := &Student{ Name: "jack", Age: 18, } c.Students = append(c.Students, stu) //JSON序列化:结构化数据-->JSON格式的字符串 data, err := json.Marshal(c) //结构体一般使用地址,而不是值,以减少赋值带来的性能损失 if err != nil { fmt.Println("err") return } fmt.Printf("%s\n", data) //{"Title":"101","Students":[{"Name":"jack","Age":18}]} }Encoder 将Go语言中的结构对象编码成 JSON 数据,并写入输出流
与Marshal不同,Encoder使用Encode方法读取变量,并写入Encoder实例。Encoder实例是一个io.Writer
gopackage handler import ( "encoding/json" "net/http" ) type User struct { FirstName string `json:"firstname"` LastName string `json:"lastname"` Age int `json:"age"` } func WriteJsonResponseHandler(w http.ResponseWriter, r *http.Request) { p := User{ FirstName: "John", LastName: "Doe", Age: 25, } // Set response header w.Header().Set("Content-Type", "application/json") err := json.NewEncoder(w).Encode(&p) if err != nil { //... handle error } } // router/router.go indexRouter.HandleFunc("/get_json_response", handler.WriteJsonResponseHandler)
反序列化
反JSON序列化:JSON格式的字符串->结构化数据
UnMarshal
将data写入v指向的变量,v必须符合JSON的格式,否则会报错
注意:v应该是一个指针
gofunc Unmarshal(data []byte, v interface{}) error例子
gostr := `{"Title":"101","Students":[{"Name":"jack","Age":18}]}` var tempClass Class err := json.Unmarshal([]byte(str), &tempClass) if err != nil { fmt.Println(err) } fmt.Printf("%#v\n", tempClass) //main.Class{Title:"101", Students:[]*main.Student{(*main.Student)(0xc00000c198)}}Decoder
与UnMarshal不同,Decoder从io.Reader读取json字符串,再写入变量
注意:v应该是一个指针
go// 从io.Reader创建一个Decoder func NewDecoder(r io.Reader) *Decoder // 从Decoder中反序列化到变量v中 func (dec *Decoder) Decode(v interface{}) error常用在读取request.body的数据
gopackage handler import ( "encoding/json" "fmt" "net/http" ) type Person struct { Name string Age int } func DisplayPersonHandler(w http.ResponseWriter, r *http.Request) { var p Person // 将请求体中的 JSON 数据解析到结构体中 // 发生错误,返回400 错误码 err := json.NewDecoder(r.Body).Decode(&p) if err != nil { http.Error(w, err.Error(), http.StatusBadRequest) return } fmt.Fprintf(w, "Person: %+v", p) } // router/router.go indexRouter.HandleFunc("/parse_json_request", handler.ParseJsonRequestHandler)
结构体标签
因为调用要求结构体字段全部必须大写,这也就意味着转化为的JSON的字段名也是大写的
但是,很多时候我们需要返回的字段名是小写的,或者返回的字段名和结构体字段名不一样,就用到结构体标签(Tag)
Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
`key1:"value1" key2:"value2,value3"`不同函数或者工具会读取不同的key,得到对应的value,来实现其功能
JSON
使用Go内置的json/encoding库序列化函数时,读取key=json的tag
| 标签值 | 含义 |
|---|---|
| - | 该字段不进行序列化 例:json:"-" |
| omitempy | 该字段为类型零值或空值,序列化时忽略该字段 例: json:"omitempy" 字段名省略的话用结构体字段名 |
| 别名 | 重新字段别名 例:json:"age",给字段其别名 |
| 类型 | 见例子2 |
例子1:
package main
import (
"encoding/json"
"fmt"
)
type Student struct {
Name string `json:"name"` // 序列化结果中字段名为name,反序列化把name放到结构体Name字段中
Age int `json:"age"`
}
func main() {
// 序列化
s := &Student{
Name: "tom",
Age: 20,
}
dataJSON, _ := json.Marshal(s)
fmt.Printf("%s\n", dataJSON) // {"name":"tom","age":20}
// 反序列化
var temp Student
if err := json.Unmarshal(dataJSON, &temp); err != nil {
fmt.Printf("%v", err)
}
fmt.Printf("%#v", temp) //main.Student{Name:"tom", Age:20}
}例子2:
type Student struct {
Age int `json:"age,string"` //Age字段对应json中age字段。且json中的age需为string,否则就会读入0(int类型的零值)
}其他工具的tags
参见:https://juejin.cn/post/7208736503520886843#heading-3
接口类型
接口的形式
接口名一般是*er ,其他语言中接口中还可以有变量,Go中只能是函数
接口实例内部的这种形式叫方法签名
gotype Runer interface{ 函数名(参数列表)(反参列表) //函数类型 函数名(参数列表)(反参列表) }接口实例内部可以是其他接口
例子:
gotype Reader interface { Read() () } type Writer interface { Write() () } // ReadWriter 是组合Reader接口和Writer接口形成的新接口类型 type ReadWriter interface { Reader Writer }
结构体实现接口
结构体的方法中有接口中定义的所有方法,就称为结构体实现了这个接口
GoLand工具
GoLand中这个标志代表,这个Engine结构体实现了一些接口
点击图标,出现弹窗,可以看到Engine都实现了3个接口
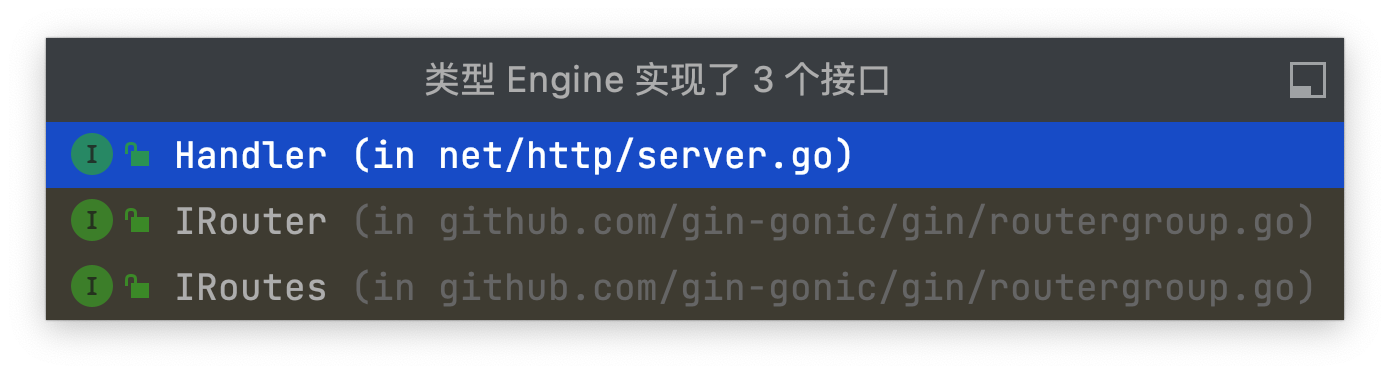
实现接口的用处
例如,这里的两个结构体都实现了接口中全部函数类型(这里只有一个run函数),所以两个结构体实例化都属于Runner类型
多个结构体实现一个接口
当对于同一个业务MakeRun时,只要定义其参数是接口Runner,就可以穿入两个不同类型的结构体实例,在MakeRun中调用run()方法,两个结构体就会按照自己的实现去做run
这非常有用处,比如,一个支付业务流程中的参数就可以是一个接口,然后支付宝、微信两个结构体可以实现一个支付方法。以后如果还需要接入其他支付方法,也不需要动症个支付业务流程,只需要新实现一个方法即可
package main
import "fmt"
type Runer interface {
run()
}
type Dog struct {
}
func (d Dog) run() {
fmt.Println("狗跑")
}
type Cat struct {
}
func (c Cat) run() {
fmt.Println("猫跑")
}
func MakeRun(r Runer) {
r.run()
}
func main() {
//Dog{}、Cat{}是实例化结构体,只不过没有属性,所以空的
MakeRun(Dog{}) //狗跑
MakeRun(Cat{}) //猫跑
}一个结构体实例可以实现多个接口
type Runer interface {
run()
}
type Sayer interface {
say()
}
type Cat struct {
}
func (c *Cat) run() {
fmt.Println("猫跑")
}
func (c *Cat) say() {
fmt.Println("猫叫")
}补充
如果Cat结构体没有实现了Runer接口,编辑器就会报错,无法编译
var _ Runer = &Cat{}值接收者和指针接收者
当结构体实现接口的方法时,使用:
- 值接收者。实例化结构体实例,无论取值还是指针,都可以传入以该接口为参数的函数中
- 指针接收者。实例化结构体实例,只能是指针,才可以传入以该接口为参数的函数中
package main
import "fmt"
type Runer interface {
run()
}
type Dog struct {
}
func (d *Dog) run() {
fmt.Println("狗跑")
}
type Cat struct {
}
func (c *Cat) run() {
fmt.Println("猫跑")
}
func MakeRun(r Runer) {
r.run()
}
func main() {
MakeRun(&Dog{}) //狗跑
MakeRun(&Cat{}) //猫跑
MakeRun(Cat{}) //会报错
}空接口
定义一个空接口类型(相当任何类型不用实现其方法签名,就能属于空接口类型),能存储任意类型的值
本质就是一个匿名接口,且其中没有任何函数签名
两个重要应用
当作参数
fmt.Println()为什么能接收所有类型,并打印出来?就是因为其参数是空接口类型gofunc f(a ...interfer{}){ //a是切片 }当作map的value
gom := make(map[string]interface{}, 10) m["姓名"] = "jack" m["年龄"] = 18 m["爱好"] = []string{"唱歌", "跳舞"}
接口的零值
type animal interface {
run()
}
var a animal
fmt.Print(a == nil)//true空接口原理
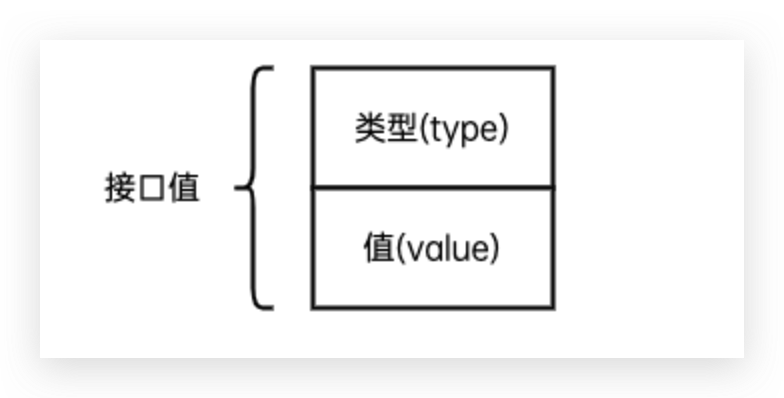
空接口的内部结构分为两个部分,当存入不同值时,type字段会记录存入值的类型,而value字段就是存入值
断言判断接口类型
value:ok=接口类型的变量.(类型)
//如果猜的类型和实际类型一样,ok为true,value为其值
//如果猜的类型和实际类型不一样,ok为false,value为空字符串例子
package main
import "fmt"
type Runer interface {
run()
}
type Dog struct {
}
func (d Dog) run() {
fmt.Println("狗跑")
}
func MakeRun(r Runer) {
value, ok := r.(Runer)
if ok {
fmt.Printf("是runner接口类型:%v", value)
r.run()
}
}
func main() {
MakeRun(Dog{}) //是runner接口类型:{}狗跑
}必须搭配switch的用法
类型=接口类型的变量.(type)例子
package main
import "fmt"
func getInterfaceType(n interface{}) {
switch n.(type) {
case int:
fmt.Println("int")
case string:
fmt.Println("string")
default:
fmt.Println(n)
}
}
func main() {
getInterfaceType(1)//int
}错误接口
error的本质
Go 语言中使用一个名为 error 接口来表示错误类型。这个接口只包含一个方法——Error,这个函数需要返回一个描述错误信息的字符串
type error interface {
Error() string
}当一个函数或方法需要返回错误时,我们通常是把错误作为最后一个返回值。例如下面标准库 os 中打开文件的函数。
func Open(name string) (*File, error) {
return OpenFile(name, O_RDONLY, 0)
}由于 error 是一个接口类型,默认零值为nil。所以我们通常将调用函数返回的错误与nil进行比较,以此来判断函数是否返回错误。例如你会经常看到类似下面的错误判断代码。
file, err := os.Open("./xx.go")
if err != nil {
fmt.Println("打开文件失败,err:", err)
return
}注意:使用fmt包打印错误时会自动调用 error 类型的 Error 方法,也就是会打印出错误的描述信息
自定义error
使用标准库
errors,自定义错误对象中包含的文本gopackage main import ( "errors" "fmt" ) func option() error { return errors.New("这是一个错误") } func main() { err := option() fmt.Printf("%v\n", err) //这是一个错误 }包装错误对象(error wrap)
向上面一样使用
fmt.Printf可以 直接获取错误对象中的文本,但是丢失了错误对象的结构。如果想对一些Go标准库函数返回的错误对象再次包装,成为新的错误对象,应该使用下面的函数gofmt.Errorf("查询数据库失败,err:%w", err) //%w是err对象的位置,返回一个新的错误在option函数返回的error的基础上
goerr := option() newErr := fmt.Errorf("这是再次封装的错误【%w】", err) fmt.Printf("%v\n", newErr) //这是再次封装的错误【这是一个错误】
错误的判断
1、使用断言
我们已经知道了错误其实就是一个接口
所以,在程序中出现错误,我们也可以通过断言来判断是否是某种错误,然后做出处理
例子是Viper库中定义的一个错误
if _, ok := err.(viper.ConfigFileNotFoundError); ok {
//fmt.Printf("找不到配置文件,err:%v\n", err.Error())
return
}2、Is方法
如果错误err1,使用Errorf包装了一层或多次最终返回了错误err2
使用断言是无法判断err2中包含err1的
判断err内部是否包含target类型的错误
func Is(err, target error) bool例子:
err1 := errors.New("错误")
err2 := fmt.Errorf("%w", err1)
fmt.Println(errors.Is(err2, err1)) //trueif ok:=errors.Is(err,targetError);ok{
//处理该错误
}3、As方法
判断err中是否包含变量target对应类型的错误,如果包含返回true,且将这个错误对象写入变量target
func As(err error, target any) bool例子
package main
import (
"errors"
"fmt"
)
type MyError struct {
Message string
}
func (e *MyError) Error() string {
return e.Message
}
func main() {
err1 := &MyError{"Error 1"}
err2 := errors.New("Error 2")
// 创建一个错误链
errChain := fmt.Errorf("Wrapper: %w", err1)
// 使用 errors.As 提取错误
var targetErr *MyError
if errors.As(errChain, &targetErr) {
fmt.Println("成功提取错误:", targetErr)
} else {
fmt.Println("提取错误失败")
}
// 使用 errors.As 提取错误
var targetErr2 *MyError
if errors.As(err2, &targetErr2) {
fmt.Println("成功提取错误:", targetErr2)
} else {
fmt.Println("提取错误失败")
}
}类型声明总结
字面量
在 JS 与 GO
// 数组
var a=[1,2,3] // JS 用[]
a:=[]int{1,2,3} // Go 用 `类型{}`
// map
var m=new Map() // JS map不支持字面量,只能通过 new 创建
m:=map[string][string]{1,2,3} // Go 用 `类型{}`
// 对象/结构体
var o={ //对象用{}
name:'tom',
age:20
}
o:Student{ // Go 用 `类型{}` 注意需要先定义好 Student 的结构
name:'tom',
age:20
}
// 嵌套
// JS的嵌套很简单直接组合就行,这里只写 Go 的
list:[]Student{
{name:'tom',age:20}, // Student实例的自变量可以省略,声明切片时已明确元素类型了
{name:'jack',age:20}
}关于nil
nil 可以立即为 Go 中一个特殊的值。只需记住:
不能比较
gopackage main import "fmt" func main() { fmt.Print(1 == 1) // true fmt.Print(nil == nil) // 报错 :invalid operation: nil == nil (operator == not defined on untyped nil) }不能打印
gopackage main import "fmt" func main() { print(nil) } //报错 :use of untyped nil in argument to print
值与类型
Go 中变量的值、类型是分开的
s:=[]int
m:=map[string][int]s、m 的值都是 nil,但是他们的类型是不同的
所以遍历变量时,如果 xx 是切片、map、channel 都可以,但是如果 xx 是接口那就直接报错了
因为编译器不知道如何遍历一个未知类型
for _,val:=range xx{
}panic
在Go语言中,异常是指会引发程序崩溃无法继续运行的错误,比如数组越界或者空指针引用等情况,这时候会触发 panic异常。(注意:无论是在主协程还是子协程中,一旦触发 panic异常,整个程序都会终止运行)
除了自动触发,我们也可以手动调用 panic函数触发异常来终止程序的运行
panic("出现了错误")不过,一个良好的程序最好不要主动调用 panic函数,尤其是开发类库的时候,最好通过返回 error类型来告诉调用者发生了什么错误,而不是触发 panic导致程序终止运行
recover函数
发生 panic异常时,如果不捕获得异常,那么程序就是终止运行,在Go语言中,可以用 defer语句和 recover函数的模式来捕获 panic异常:
package main
import (
"fmt"
"log"
)
func main() {
// 数组越界
n1 := FindElementByIndex(10)
}
func FindElementByIndex(index int) int {
// 一般写在函数的efer中
defer func() {
if e := recover(); e != nil {
log.Fatal(e)
}
}()
s := []int{1, 2, 3, 4}
return s[index]
}反射
需要使用reflect标准库
反射是建立在接口的基础上的。Go是一门静态语言,除接口类型外,其他类型的变量在代码运行前就已经确定了(例如一个int、string类型的变量),且不会改变
唯独接口类型的变量,会在运行时,随着赋值不同而发生变化,所以更多时候,我们使用反射来查看接口类型变量在运行时的类型、值
前面提到过,空接口的内部结构分为两个部分,当存入不同值时,type字段会记录存入值的类型,而value字段就是存入值。
反射可以帮助我们在程序运行时,动态的获取接口类型变量中存储的值(value)、值的类型(type)
使用流程

实例转化为reflect.Type、reflect.Value
使用反射,一般会将接口类型的变量先转化为 reflect.Type 、reflect.Value 类型实例。然后通过他们的方法完成逻辑
reflect.Type
是一个接口类型,其实例实现了接口规定的方法
type Type interface {
// Kind返回该接口的具体分类
Kind() Kind
// Name返回该类型在自身包内的类型名,如果是未命名类型会返回""
Name() string
// PkgPath返回类型的包路径,即明确指定包的import路径,如"encoding/base64"
// 如果类型为内建类型(string, error)或未命名类型(*T, struct{}, []int),会返回""
PkgPath() string
// 返回类型的字符串表示。该字符串可能会使用短包名(如用base64代替"encoding/base64")
// 也不保证每个类型的字符串表示不同。如果要比较两个类型是否相等,请直接用Type类型比较。
String() string
// 返回要保存一个该类型的值需要多少字节;类似unsafe.Sizeof
Size() uintptr
// 返回当从内存中申请一个该类型值时,会对齐的字节数
Align() int
// 返回当该类型作为结构体的字段时,会对齐的字节数
FieldAlign() int
// 如果该类型实现了u代表的接口,会返回真
Implements(u Type) bool
// 如果该类型的值可以直接赋值给u代表的类型,返回真
AssignableTo(u Type) bool
// 如该类型的值可以转换为u代表的类型,返回真
ConvertibleTo(u Type) bool
// 返回该类型的字位数。如果该类型的Kind不是Int、Uint、Float或Complex,会panic
Bits() int
// 返回array类型的长度,如非数组类型将panic
Len() int
// 返回该类型的元素类型,如果该类型的Kind不是Array、Chan、Map、Ptr或Slice,会panic
Elem() Type
// 返回map类型的键的类型。如非映射类型将panic
Key() Type
// 返回一个channel类型的方向,如非通道类型将会panic
ChanDir() ChanDir
// 返回struct类型的字段数(匿名字段算作一个字段),如非结构体类型将panic
NumField() int
// 返回struct类型的第i个字段的类型,如非结构体或者i不在[0, NumField())内将会panic
Field(i int) StructField
// 返回索引序列指定的嵌套字段的类型,
// 等价于用索引中每个值链式调用本方法,如非结构体将会panic
FieldByIndex(index []int) StructField
// 返回该类型名为name的字段(会查找匿名字段及其子字段),
// 布尔值说明是否找到,如非结构体将panic
FieldByName(name string) (StructField, bool)
// 返回该类型第一个字段名满足函数match的字段,布尔值说明是否找到,如非结构体将会panic
FieldByNameFunc(match func(string) bool) (StructField, bool)
// 如果函数类型的最后一个输入参数是"..."形式的参数,IsVariadic返回真
// 如果这样,t.In(t.NumIn() - 1)返回参数的隐式的实际类型(声明类型的切片)
// 如非函数类型将panic
IsVariadic() bool
// 返回func类型的参数个数,如果不是函数,将会panic
NumIn() int
// 返回func类型的第i个参数的类型,如非函数或者i不在[0, NumIn())内将会panic
In(i int) Type
// 返回func类型的返回值个数,如果不是函数,将会panic
NumOut() int
// 返回func类型的第i个返回值的类型,如非函数或者i不在[0, NumOut())内将会panic
Out(i int) Type
// 返回该类型的方法集中方法的数目
// 匿名字段的方法会被计算;主体类型的方法会屏蔽匿名字段的同名方法;
// 匿名字段导致的歧义方法会滤除
NumMethod() int
// 返回该类型方法集中的第i个方法,i不在[0, NumMethod())范围内时,将导致panic
// 对非接口类型T或*T,返回值的Type字段和Func字段描述方法的未绑定函数状态
// 对接口类型,返回值的Type字段描述方法的签名,Func字段为nil
Method(int) Method
// 根据方法名返回该类型方法集中的方法,使用一个布尔值说明是否发现该方法
// 对非接口类型T或*T,返回值的Type字段和Func字段描述方法的未绑定函数状态
// 对接口类型,返回值的Type字段描述方法的签名,Func字段为nil
MethodByName(string) (Method, bool)
// 内含隐藏或非导出方法
}
reflect.Value
是一个结构体类型,截图是该结构体的一部分部分方法
type Value struct {
// 内含隐藏或非导出字段
}
获取Type、Value实例
//TypeOf返回接口中保存的值的类型,TypeOf(nil)会返回nil。
func TypeOf(i interface{}) Type
//返回一个初始化为接口类型的变量i,它的具体值的Value,ValueOf(nil)返回Value零值。
func ValueOf(i interface{}) Value这里用一个静态变量做一个展示(静态变量不会变化,但是如果是接口类型的变量就会随着赋值一直变化)
package main
import (
"fmt"
"reflect"
)
func main() {
//静态类型的变量
var x float32 = 3.4
fmt.Println("类型是", reflect.TypeOf(x)) //类型是 float32
fmt.Println("值是", reflect.ValueOf(x)) //值是 3.4
//通过ValueOf拿到的Value类型(即存储的值),能判断更多信息
v := reflect.ValueOf(x)
fmt.Println(v.Kind() == reflect.Float32) //true
fmt.Println(v.Type()) //float32
fmt.Println(v.Float()) //3.4000000953674316
}获取实例
package main
import (
"fmt"
"reflect"
)
type Stu struct {
Name string
Age int
}
func (s Stu) Run() {
fmt.Println("run")
}
func (s Stu) Say() {
fmt.Println("say")
}
func getMessage(input interface{}) {
//---reflect.Type实例---
getType := reflect.TypeOf(input)
fmt.Println(getType) //main.Stu
fmt.Println(getType.Kind()) //struct
fmt.Println(getType.Name()) //Stu
//---reflect.Value实例---
getValue := reflect.ValueOf(input)
fmt.Println(getValue) //{jack 19}
fmt.Println(getValue.Kind()) //struct
fmt.Println(getValue.Type()) //main.Stu 获取Vaule对应的Type,和typeOf(input)返回值一样
//---获取实例的字段信息---(注意:只有实例是结构体类型时,才能遍历,否则NumField()会造成panic)
if getType.Kind() == reflect.Struct {
for i := 0; i < getType.NumField(); i++ {
field := getType.Field(i) //根据索获取结构体字段的StructField实例
value := getValue.Field(i).Interface()
fmt.Printf("字段名:%v,字段类型:%v,值是:%v\n", field.Name, field.Type, value)
}
//字段名:Name,字段类型:string,值是:jack
//字段名:Age,字段类型:int,值是:19
//补充下:getType.FieldByName("Age") 可以通过Struct字段名字来获取字段对应的值,它的Value对象
}
//---获取实例的方法信息(方法首字母必须大写,否则NumMethod获取不到这个方法)---
for i := 0; i < getType.NumMethod(); i++ {
method := getType.Method(i) //获取Method实例
fmt.Printf("方法名:%v,方法类型:%v\n", method.Name, method.Type)
}
}
func main() {
getMessage(Stu{
Name: "jack",
Age: 19,
})
}Field(index int)返回的StructField类型的组成:
type StructField struct {
Name string //Name是字段的名字
PkgPath string //PkgPath是非导出字段的包路径,对导出字段该字段为""
Type Type // 字段的类型
Tag StructTag // 字段的标签
Offset uintptr // 字段在结构体中的字节偏移量
Index []int // 用于Type.FieldByIndex时的索引切片
Anonymous bool // 是否匿名字段
}Method(index int)返回的Method类型的组成
type Method struct {
Name string
PkgPath string
Type Type
Func Value
Index int
}Type的Kind()、Name()方法区别
上面例子可以看出,当实例是结构体时
Kind() 返回的是Struct
Name() 返回的是Stureflect包中定义的一些类型常量(Kind的返回值)
type Kind uint
const (
Invalid Kind = iota // 非法类型
Bool // 布尔型
Int // 有符号整型
Int8 // 有符号8位整型
Int16 // 有符号16位整型
Int32 // 有符号32位整型
Int64 // 有符号64位整型
Uint // 无符号整型
Uint8 // 无符号8位整型
Uint16 // 无符号16位整型
Uint32 // 无符号32位整型
Uint64 // 无符号64位整型
Uintptr // 指针
Float32 // 单精度浮点数
Float64 // 双精度浮点数
Complex64 // 64位复数类型
Complex128 // 128位复数类型
Array // 数组
Chan // 通道
Func // 函数
Interface // 接口
Map // 映射
Ptr // 指针
Slice // 切片
String // 字符串
Struct // 结构体
UnsafePointer // 底层指针
)例如,可以通过下面的方式判断是否是结构体
if getType.Kind() == reflect.Stuct通过reflect.Value修改实例
package main
import (
"fmt"
"reflect"
)
func main() {
num := 1.23
//1、参数必须是指针类型,才能被修改
ptr := reflect.ValueOf(&num)
//参数是指针类型类型,才进行下面的步骤
if ptr.Kind() == reflect.Ptr {
//2、获取指针指向的值的Value实例。前提是:第一步,传入的必须是指针类型,否则panic
value := ptr.Elem()
//3、CanSet返回值为true,即可修改,通过setXXX函数进行修改。前提是:第一步,传入的必须是指针类型,否则panic
if value.CanSet() {
value.SetFloat(3.15)
}
fmt.Printf("修改后的值:%v\n", num) //修改后的值:3.15
}
}修改结构体字段的例子,仅需传入结构的地址,修改结构体字段时,就可以可直接对字段值的Value使用SetXXX方法修改了
package main
import (
"fmt"
"reflect"
)
type Stu struct {
Name string
Age int
}
func main() {
s := Stu{
Name: "tom",
Age: 20,
}
ptr := reflect.ValueOf(&s)
if ptr.Kind() == reflect.Ptr {
structValue := ptr.Elem()
filed1 := structValue.FieldByName("Name")
filed1.SetString("jack")
}
fmt.Println(s) //{jack 20}
}通过reflect.Value调用方法
package main
import (
"fmt"
"reflect"
)
type Stu struct {
Name string
Age int
}
func (s Stu) Run() {
fmt.Println("run")
}
func (s Stu) Say(word1, word2 string) {
fmt.Println("say", word1, word2)
}
func main() {
value := reflect.ValueOf(Stu{
Name: "tom",
Age: 20,
})
//MethodByName的参数指定的方法不存在,返回零值,即<invalid reflect.Value>,在调用Call回触发panic
methodValue := value.MethodByName("Run")
if methodValue2.Kind() != reflect.Func {
return
}
fmt.Printf("Value的类型是:%v,Value的Type实例%v\n", methodValue.Kind(), methodValue.Type()) //Value的类型是:func,Value的Type实例func()
//无参数的函数在调用时,传入nil或者空切片
methodValue.Call(nil) //run
methodValue.Call(make([]reflect.Value, 0)) //run
//MethodByName的参数指定的方法不存在,返回零值,即<invalid reflect.Value>,在调用Call回触发panic
methodValue2 := value.MethodByName("Say")
if methodValue2.Kind() != reflect.Func {
return
}
fmt.Printf("Value的类型是:%v,Value的Type实例%v\n", methodValue2.Kind(), methodValue2.Type()) //Value的类型是:func,Value的Type实例func(string, string)
//有参数的需要以切片的形式传入。切片元素的类型为reflect.Value
methodValue2.Call([]reflect.Value{
reflect.ValueOf("你好"),
reflect.ValueOf("世界"),
}) //say 你好 世界
}读取结构体最常用的思路就是获取字段/方法个数,然后遍历,把索引传给Field、Method,获取对应值和方法
通用字段
补充下:下面t.Field(i)的tag属性,返回的是该字段的所有的tag,field.Tag.Get(json)只返回json后的字段
package main
import (
"fmt"
"reflect"
)
type Stu struct {
name string `json:"stuName"`
age int `json:"stuAge"`
score int `json:"stuScore"`
hobby []string `json:"stuHobby"`
}
func (s *Stu) run() {
fmt.Println("学生跑步")
}
func main() {
s := Stu{
name: "jack",
age: 18,
score: 100,
hobby: []string{"唱歌", "学习"},
}
t := reflect.TypeOf(s)
for i := 0; i < t.NumField(); i++ {
field := t.Field(i) //field是 StructField 类型
fmt.Printf("name:%v ,type:%v -- tag: %v -- PkgPath:%v -- Offset:%v -- Anonymous:%v\n", field.Name, field.Type, field.Tag, field.PkgPath, field.Offset, field.Anonymous)
}
//name:name ,type:string -- tag: json:"stuName" -- PkgPath:main -- Offset:0 -- Anonymous:false
//name:age ,type:int -- tag: json:"stuAge" -- PkgPath:main -- Offset:16 -- Anonymous:false
//name:score ,type:int -- tag: json:"stuScore" -- PkgPath:main -- Offset:24 -- Anonymous:false
//name:hobby ,type:[]string -- tag: json:"stuHobby" -- PkgPath:main -- Offset:32 -- Anonymous:false
}反射的缺点
- 基于反射的代码是极其脆弱的,反射中的类型错误在运行前不会被检查,在真正运行的时候可能引发panic
- 大量使用反射的代码通常难以理解
- 反射的性能低下,基于反射实现的代码通常比正常代码运行速度慢一到两个数量级
并发编程
并发知识基础
这里的很多内容,其实都是《计算机操作系统》这门大学课程中的内容,这里只是简略介绍
并发概念
进程(process):操作系统进行资源分配和调度的最小单位,在内核态
线程(thread):操作系统基于进程开启的轻量级进程,一个进程里至少有一个线程,线程是操作系统调度执行的最小单位,在内核态
协程(coroutine):非操作系统提供而是由用户自行创建和控制的,比线程更轻量级,在用户态
总结下:进程、线程是由系统调度的,协程是用户实现的,在大多数语言中都是对内核线程的封装
系统进程通讯
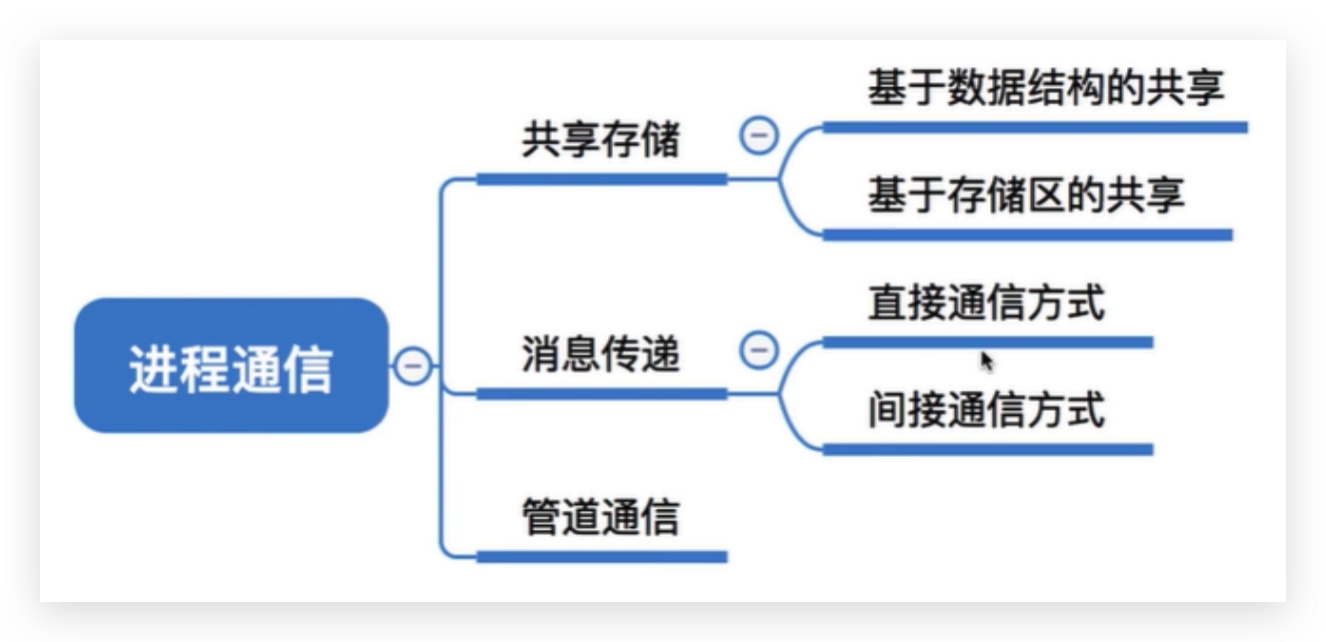
语言基本的并发模型
只有内核线程能操作系统资源,各个语言基本都是创建用户态的协程,通过和内核线程建立映射来实现并发
一对一模型
1个内核态线程对于1个用户态的协程
缺点是销毁、创建这种协程以及多个协程的上下文切换,都是都是直接由操作系统层面来做需要损耗大量性能
一对多模型
1个内核态线程对于多个用户态的协程,很多语言都是采用的这种实现方案
缺点是
一个用户态协程调用阻塞式的系统调用时,其他内核线程的协程就会被阻塞。对于这个问题很多语言提出了解决方案:
它们的协程库会把一些阻塞的操作重新封装为完全的非阻塞形式,然后在要阻塞的点上,主动让出自己,并通过某种方式通知或唤醒其他待执行的协程运行,从而避免了其他协程被阻塞
同属于一个内核线程的协程只能运行在一个CPU上,无法在多核CPU上执行

多对多模型
1个内核态线程对于多个用户态的协程,很多语言都是采用的这种实现方案,及解决了上面出现的问题

Go的GPM并发模型
Go的GPM并发模型是典型的多对多模型,Go语言内置的调度器,可以让多核CPU中每个CPU执行一个协程
详见这里
runtime包
runtime包提供和go运行时环境的互操作功能
package main
import (
"fmt"
"runtime"
)
func init() {
fmt.Printf("CPU数量:%v\n", runtime.NumCPU())
runtime.GOMAXPROCS(runtime.NumCPU())
}
func main() {
fmt.Printf("GOROOT目录:%v\n", runtime.GOROOT())
fmt.Printf("当前系统:%v\n", runtime.GOOS)
go func() {
for i := 0; i < 1000; i++ {
fmt.Println("goroutine")
}
}()
for i := 0; i < 4; i++ {
runtime.Gosched()
fmt.Println("main")
}
}
//runtime.Goexit() //结束goroutine,但是defer还是会执行goroutine
即Go语言的协程,是语言级别实现的用户级协程,开发者操作Go语言中的线程,Go语言底层再去调用系统的线程库,实现多线程。所以,Go线程的切换不需要系统内核调度,而是由Go运行时(runtime)负责调度
一个goroutine一般只需要2KB大小,所以,在Go程序中同时创建成百上千个goroutine是非常普遍的
调度goroutine的Go语言运行时,会智能地将 m个goroutine 合理地分配给n个操作系统线程
goroutine 是 Go 程序中最基本的并发执行单元。每一个 Go 程序都至少包含一个 goroutine,即main goroutine(用来执行主函数main),当 Go 程序启动时它会自动创建
在Go语言编程中,你不需要去自己写进程、线程、协程,你只需要创建一个goroutine。比如,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个 goroutine 去执行这个函数就可以了,就是这么简单粗暴,至于如何调度由Go runtime负责
线程和goroutine
操作系统线程与goroutine是多对多的关系
一个操作系统线程对应多个goroutine
多个goroutine可能被Go runtime分配到多个操作系统线程运行
主goroutine
main函数运行后,会开启一个mian-goroutine(主goroutine)
主goroutine启动后,按顺序进行如下工作:
设置每一个子goroutine所能申请的最大栈空间
32位操作系统上为250MB,64位操作系统上为1GB。如果子goroutine超出就会引发栈溢出的panic,程序也就终止了
创建一个特殊的defer语句,用于在主goroutine退出后,进行善后操作
创建后台清理内存垃圾的goroutine
执行main包中的init函数
检查主goroutine是否引发panic,如果有就进行必要的处理
主goroutine结束,并且结束当前进程
两个注意点
主goroutine结束,其中的子goroutine会直接被销毁(为了保证子进程结束后,主进程才能结束,就需要阻塞主goroutine结束,后面会讲到如何做)
gopackage main import "fmt" func sub() { fmt.Println("子goroutine") } func main() { //mian-goroutine go sub() //启动一个子goroutine }主goroutine会先运行,只有它让出资源,子groutine才能运行
所以,下面的代码无论运行多少次,都是输出main就结束了,不会输出goroutine
但是在main函数最后加一句
time.Sleep(10 * time.Second),就会在main放弃资源后不结束程序,才会继续输出goroutinegopackage main import ( "fmt" "runtime" "time" ) func init() { runtime.GOMAXPROCS(runtime.NumCPU()) } func main() { go func() { for i := 0; i < 5; i++ { fmt.Println("goroutine") } }() for i := 0; i < 4; i++ { fmt.Println("main") } }
goroutine的使用规则
使用go关键字,去执行函数,就会创建一个goroutine(由Go runtime调度何时启动)
同时存在多个goroutine,如果
GOMAXPROCS=1(设置只用一个CPU,运行多个goroutine),则能看到一个goroutine执行完后,另一个goroutine才会执行。但是,Go默认使用CPU核数作为GOMAXPROCS的值,所以,实际上可以最多GOMAXPROCS个goroutine同时执行同时存在多个goroutine,goroutine执行顺序不是创建顺序。
如果只用一个CPU运行多个goroutine,会等一个goroutine运行完,在运行下一个
gofunc init() {//运行时会先执行,限制只用一个CPU runtime.GOMAXPROCS(1) } func m() { for i := 0; i < 100; i++ { fmt.Printf("m%v\n", i) } } func w() { for i := 0; i < 100; i++ { fmt.Printf("w%v\n", i) } } func main() { go m() go w() time.Sleep(10 * time.Second) //防止主groutine直接结束 } //输出的结果是m的在一起、w的一起,只不过w和m的先后顺序不一定去掉init函数,w和m的输出就会混在一起了,因为他们在多个CPU上运行,真正的并行
与函数不同,Go不等到goroutine执行结束,所以使用go关键字启动的函数即使有返回值也会被忽略
进程执行了,就会执行完,再切换另一个进程
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func sayHello(i int) {
fmt.Printf("sayHello执行%d\n", i)
wg.Done() //消耗一个进程
}
func main() {
fmt.Println("你好")
for i := 0; i < 10; i++ {
wg.Add(1) //进程数加1,需要在go启动进程前
go sayHello(i)
}
wg.Wait() //主进程被阻塞,需要等待进程全部消耗完,主进程才能结束
}
//你好
//sayHello执行0
//sayHello执行6
//sayHello执行5
//sayHello执行9
//sayHello执行3
//sayHello执行1
//sayHello执行2
//sayHello执行7
//sayHello执行8
//sayHello执行4注意这种情况
前面是将i(0到9)传入函数
这里是运行起来线程后,再向上级作用域找i,这时候i不一定是几了
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func main() {
fmt.Println("你好")
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
fmt.Printf("sayHello执行%d\n", i)
wg.Done()
}()
}
wg.Wait()
}
//你好
//sayHello执行8
//sayHello执行10
//sayHello执行10
//sayHello执行10
//sayHello执行10
//sayHello执行10
//sayHello执行10
//sayHello执行10
//sayHello执行10
//sayHello执行10可以将i(0到9)共10值传进去
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func main() {
fmt.Println("你好")
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
fmt.Printf("sayHello执行%d\n", i)
wg.Done()
}(i)
}
wg.Wait()
}操作系统线程数
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个系统线程来同时执行 Go 代码
默认值是机器上的 CPU 核心数。例如在一个 8 核心的机器上,GOMAXPROCS 默认为 8。Go语言中可以通过runtime.GOMAXPROCS函数设置当前程序并发时占用的 CPU逻辑核心数。(Go1.5版本之前,默认使用的是单核心执行。Go1.5 版本之后,默认使用全部的CPU 逻辑核心数。)
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func a() {
for i := 0; i < 100; i++ {
fmt.Printf("a:%d ", i)
}
fmt.Println()
wg.Done()
}
func b() {
for i := 0; i < 100; i++ {
fmt.Printf("b:%d ", i)
}
fmt.Println()
wg.Done()
}
func main() {
wg.Add(2)
go a()
go b()
wg.Wait()
}以上代码中,a和b的打印交替出现
在main函数第一行加上
runtime.GOMAXPROCS(1)则,会发现打印结果是 a打印完了再打印b 或者 b打印完了再打印a,因为只有一个操作系统线程,goroutine只能执行完一个,在执行下一个
WaitGroup
同步等待组,用于解决主goroutine与子goroutine通信问题
例如:前面遇到的,由于主goroutine结束,子goroutine未结束就被终止了
程序先执行了主goroutine,然后被wg.Wait()阻塞,等待两个子goroutine结束时运行wg.Done(),计数器归零,则结束主goroutine
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func f1() {
fmt.Println("f1执行")
//计数器减1
wg.Done()
}
func f2() {
fmt.Println("f2执行")
//计数器减1
wg.Done()
}
func main() {
//计数器设置为2
wg.Add(2)
go f1()
go f2()
fmt.Println("main阻塞,等待")
//阻塞主goroutine,等待计数器归零
wg.Wait()
fmt.Println("main结束阻塞")
}
//main阻塞,等待
//f2执行
//f1执行
//main结束阻塞注意,通常我们在每次调用协程前使用wg.Add增加计数器,而不是在协程内部使用wg.Add,这可能导致协程未执行时,主进程的wg.Wait就执行了,然后结束了主程序
传统并发控制方式:锁
通过对临界资源加锁的方式,防止多个 Goroutine 同时访问临界资源
临界资源
例子
//main.go
package main
import (
"fmt"
"time"
)
func main() {
a := 1
go func() {
a = 2
fmt.Printf("子goroutine:%v\n", a)
}()
a = 3
time.Sleep(5 * time.Second)
fmt.Printf("主goroutine:%v\n", a)
}
//子goroutine:2
//主goroutine:2当a被赋值为3后,子协程开始执行,把a又修改为2
查看是否存在临界资源
go run -race main.goFound 1 data race(s) , 发现1个数据发生争抢

多个并发的协程,对一个数据进行争抢操作极有可能造成数据错误
火车票案例
多个售票口,会将票卖到0张以下
package main
import (
"fmt"
"math/rand"
"runtime"
"time"
)
//总票数
var ticketNum = 10
//售票口,开启4个goroutine,同时售票
func saleTickets(name string) {
rand.Seed(time.Now().UnixNano())//随机数发生器初始化为不同的值,rand.Intn(1000)产生的0-999的随机整数,就会不一样
for {
if ticketNum > 0 {
//goroutine抢到资源后,就睡眠让出了资源,等睡眠结束,可能ticketNum已经小于0了
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
fmt.Println(name, "售出", ticketNum)
ticketNum--
} else {
fmt.Println(name, "售罄", ticketNum)
break
}
}
}
func main() {
runtime.GOMAXPROCS(runtime.NumCPU())
go saleTickets("售票口1")
go saleTickets("售票口2")
go saleTickets("售票口3")
go saleTickets("售票口4")
//防止主goroutin结束,而直接终止未结束的子goroutine
time.Sleep(5 * time.Second)
}如何处理临界资源?我们可以通过锁机制,对资源进行加锁,就是我们接下来的要讲的
但是,Go语言更加推荐是用channel的方式
加锁机制
主要用于处理多个子 goroutine 的通讯问题
互斥锁、读写锁 概述
多个 goroutine 对同一个数据仅读取是不存在问题的,不必加锁
真正出现问题的是:写-写(互斥锁)、读-写(读写锁)
例子:
1、A读取-B修改-A修改
进程A读取值,进程B马上修改值。这样A后续的操作都是在错误的值上操作的
例子:A售票窗口读取剩余票数1,但是B售票窗口马上售出这张票,实际上票已售罄,但是A不知道还会继续售票。就出现了错误
2、A、B读取-A、B修改
进程A修改值,进程马上B修改值。这样A修改的值被覆盖
例子:A、B读取剩余票数n,A售票窗口售出1张票,剩余n-1,B售票窗口售出1张票,剩余n-1。实际上售出了两张票,应该是n-2注意:
加锁与解锁之间的代码称为临界区资源,如下临界区持有变量data,那任何一个时间点只能有一个goroutine在执行,即修复变量data
go加锁 data=1 解锁当某一goroutine对某一临界资源加锁后,如果有其他的goroutine来执行上锁操作,会被阻塞,直到当前的goroutine释放锁后其他的goroutine才会继续加锁
互斥锁更粗粒度直接阻塞 goroutine操作,而读写锁更细粒度会根据 goroutine 的具体操作阻塞 goroutine
互斥锁
当某个goroutine获得互斥锁后,其他goroutine均不可对资源进行读写
代码中mutex.Lock与`mutex.Unlock,在同一时间,只能存在一个goroutine执行这段代码
注意:加锁后一定记得解锁
相关方法:

package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
//互斥锁
var mutex sync.Mutex
var wg sync.WaitGroup
//总票数
var ticketNum = 10
//售票口,开启4个goroutine,同时售票
func saleTickets(name string) {
defer wg.Done()
rand.Seed(time.Now().UnixNano())
for {
//上锁,从这行开始,就只能有一个goroutine才能执行,其他goroutine不能执行
mutex.Lock()
if ticketNum > 0 {
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
fmt.Println(name, "售出", ticketNum)
ticketNum--
} else {
//如果走到这里,执行break后,就不会执行后面的(*)进行解锁了。所以这里需要再加一个解锁
mutex.Unlock()
fmt.Println(name, "售罄")
break
}
//解锁(*)
mutex.Unlock()
}
}
func main() {
wg.Add(4)
go saleTickets("售票口1")
go saleTickets("售票口2")
go saleTickets("售票口3")
go saleTickets("售票口4")
wg.Wait()
}读写锁
同一时间
- 上RLock读锁:所有读操作可以进行,但是不允许写操作
- 上Lock写锁:仅有当前进程可以写,不允许任何读操作
相关方法:
Lock写锁、RLock读锁

多协程读+写数据
package main
import (
"fmt"
"sync"
"time"
)
func readData(i int) {
defer wg.Done()
//读写锁,对读操作上锁
rwMutex.RLock()
fmt.Printf("编号:%v,开始read\n", i)
time.Sleep(2 * time.Second)
fmt.Printf("编号:%v,read结束\n", i)
//读写锁,对读操作解锁
rwMutex.RUnlock()
}
func writeData(i int) {
defer wg.Done()
//读写锁,对写操作上锁
rwMutex.Lock()
fmt.Printf("编号:%v,开始write\n", i)
time.Sleep(2 * time.Second)
fmt.Printf("编号:%v,write结束\n", i)
//读写锁,对写操作解锁
rwMutex.Unlock()
}
var rwMutex sync.RWMutex
var wg sync.WaitGroup
func main() {
wg.Add(4)
go writeData(1)
go readData(2)
go readData(3)
go writeData(4)
wg.Wait()
}可以看出:
- 同一协程的写操作是开始和结束都是成对出现的,不会别其他读、写打断
- 不同协程的读操作是可以同时进行的,且不会别读da

struct字段为锁类型最为常见
这个例子中,定义了一个名为Counter的结构体,其中mu字段是一个sync.Mutex类型的值
下面例子中,在加锁、解锁直接访问的变量 value 会被加锁
package main
import (
"fmt"
"sync"
"time"
)
type Counter struct {
mu sync.Mutex
value int
}
func (c *Counter) Increment() {
c.mu.Lock()
defer c.mu.Unlock()
c.value++
}
func (c *Counter) GetValue() int {
c.mu.Lock()
defer c.mu.Unlock()
return c.value
}
func main() {
counter := Counter{}
// 启动多个 goroutine 修改和读取计数器的值
for i := 0; i < 5; i++ {
go func() {
counter.Increment()
fmt.Printf("Incremented: %d\n", counter.GetValue())
}()
}
time.Sleep(time.Second) // 等待所有 goroutine 执行完毕
fmt.Printf("Final Value: %d\n", counter.GetValue())
}死锁、解饿问题
死锁
多个 Goroutine 争抢资源,在某些情况下,最后导致多个 goroutine 一直相互等待下去
死锁的具体案例:
- Goroutine 1 先运行,锁定了 Resource A
- Goroutine 2 同时运行,锁定了 Resource B
- Goroutine 1 尝试锁定 Resource B,但 Resource B 已经被 Goroutine 2 锁定,因此 Goroutine 1 进入阻塞状态,等待 Resource B 释放
- Goroutine 2 尝试锁定 Resource A,但 Resource A 已经被 Goroutine 1 锁定,因此 Goroutine 2 进入阻塞状态,等待 Resource A 释放
死锁代码案例:
// main.go
package main
import "sync"
var (
mutex1 sync.Mutex
mutex2 sync.Mutex
)
func resource1() {
mutex1.Lock()
print("resource 1")
resource2()
mutex1.Unlock()
}
func resource2() {
mutex2.Lock()
print("resource 1")
resource1()
mutex2.Unlock()
}
func main() {
resource1()
resource2()
}运行结果如下,Go 检查到发生了死锁
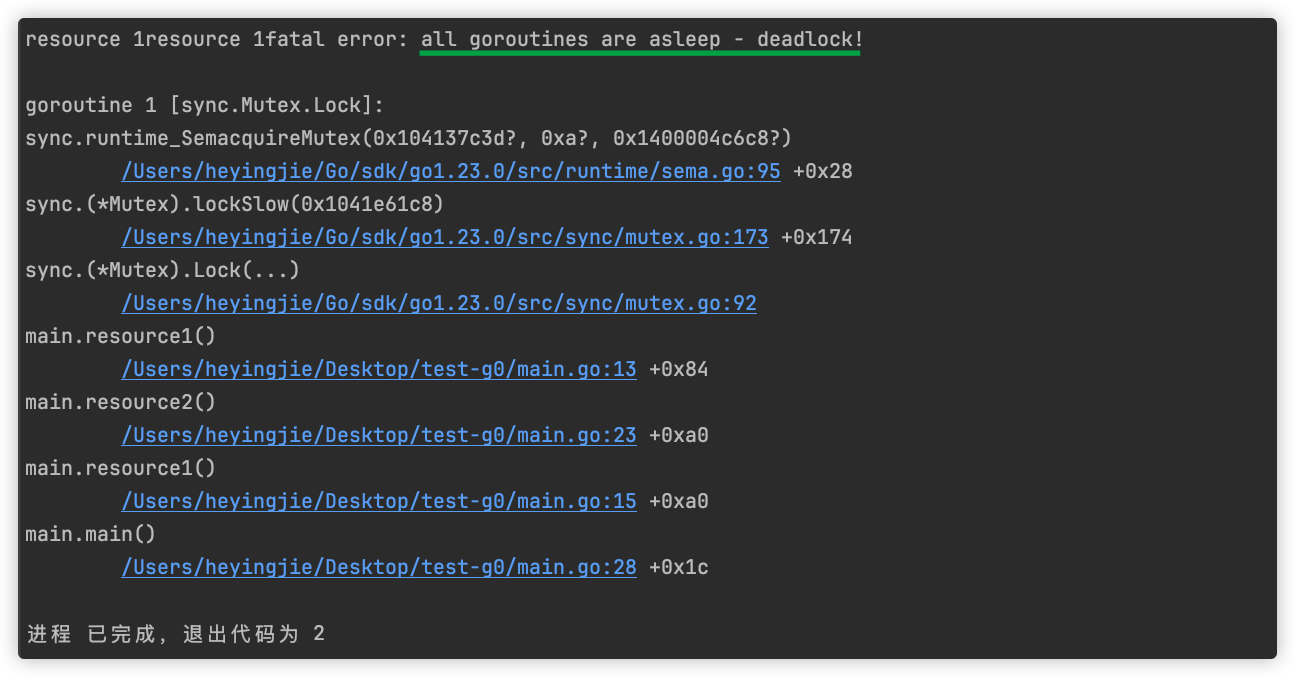
饥饿
某个协程长时间持有锁,导致其他协程在这段时间内无法获取锁而阻塞。或者多个高优先级的任务长时间持有锁,导致低优先级任务长时间无法执行
解决方案:
1、设置超时时间、手动取消Context,避免协程长时间阻塞
select {
case <-ch:
// 通道操作成功
case <-time.After(1 * time.Second):
// 超时处理
}ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
select {
case <-ctx.Done():
fmt.Println("协程超时")
case <-ch:
fmt.Println("通道操作成功")
}2、使用带缓冲区的 channel
ch := make(chan int, 10) // 带缓冲的通道3、Go 的 sync.Mutex 是非公平锁,可能会导致某些协程长时间无法获取锁。如果需要公平性,可以使用 sync.RWMutex 或其他公平锁机制。
基于CSP的并发控制方式:channel
Go社区中有一句十分经典的语录
不要通过共享内存来通信,而应该通过通信来共享内存
锁、channel 的区别:
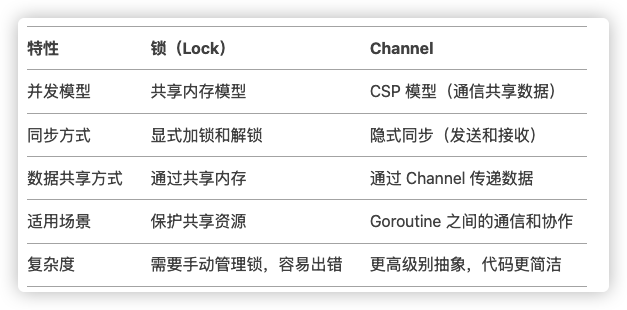
如何理解?
通信,即使用多个goroutine合作去完成一个任务,这就需要goroutine之间进行通讯
通过共享内存来通信
多个 goroutine 同时访问同一临界区数据(内存中),使用手动加锁的机制来限制多个goroutine的执行,来访问同一块内存。这种方式会造成性能问题,所以Go官方并不推荐
通信来共享内存
我们可以将数据分装成一个对象,将对象放入channel,由Go语言从语言层面保证同时只能有一个goroutine能访问channel,取出后在处理其指向的内存对象
CSP(communicating sequential processes)并发模型
通道的概念
channel是可以让一个 goroutine 发送特定值到另一个 goroutine ,从而使得两个独立的goroutine可以通信
Go 语言中的通道是一种引用类型,像一个队列,总是遵循先入先出的规则,来保证收发数据的顺序。每一个通道内部元素必须指定其中元素的具体类型
初始化
方式1:
//1-1、定义双向通道类型,通道内部元素为int
var ch1 chan int
//1-2、定向通道
var ch2 chan<- int //只能写入数据的通道
var ch3 <-chan int //只能读取数据的通道
// 默认零值为nil
fmt.Println(ch1 == nil) //true
// 容量为0
fmt.Println(cap(ch1)) //0
// 实际长度为0
fmt.Println(len(ch1)) //0方式2:使用make初始化空间
//一般直接使用:=进行类型推断
ch:=make(chan int,10) //第二个参数是通道容量,channel容量确定后不可更改
//不传第二个参数,则默认为0。
ch2:=make(chan int)
fmt.Println(ch2 == nil) // false
fmt.Println(cap(ch2)) //0
fmt.Println(len(ch2)) //0注意:
channel是引用类型,默认零值为nil,需要使用make初始化空间才能使用
无论是未初始化,还是初始化后数据为空,判断通道为空,都是判断
len(ch)==0(与切片相同)
写入和读取数据
必须make初始化后,才能从channel中读写
一旦将数据从通道读出来,数据就被移出管道了
ch := make(chan int, 10)
//向channel写
ch <- 1
//从channel读
data:=<-ch
fmt.Println(data) //1读取也支持一个额外的返回值,这个返回值一般用于判断通道是否关闭。
//ok为false的情况是,通道关闭+数据已经被读取空了
//通道未关闭+数据已经被读取空了,会阻塞
data,ok:=<-ch无缓冲区的通道
容量为0的channel比较特殊,读、写均是阻塞的,需要另一个goroutine写、读,来解除阻塞
ch := make(chan int)//不传第二个参数,则默认为0,即无缓冲区的通道死锁
就是一直阻塞,比如一个读goroutine被阻塞了,但是代码里没有任何要写数据的goroutine,则必然发生死锁

阻塞
channel是同步的,同一时刻,只能有一个goroutine读/写通道
同时又因为有阻塞的存在,才能让不阻塞的goroutine先运行,阻塞的后运行。所以,我们要巧妙运用阻塞
何种情况会发生goroutine阻塞?
当一个执行写操作的goroutine,向通道写数据,如果通道满了,就会发生阻塞,等待执行读操作的goroutine先执行
当一个执行读操作的goroutine,从通道读数据,如果通道为空,就会发生阻塞,等待执行写操作的goroutine先执行
下图介绍了,不同状态下的通道,对于读、写goroutine的反应:
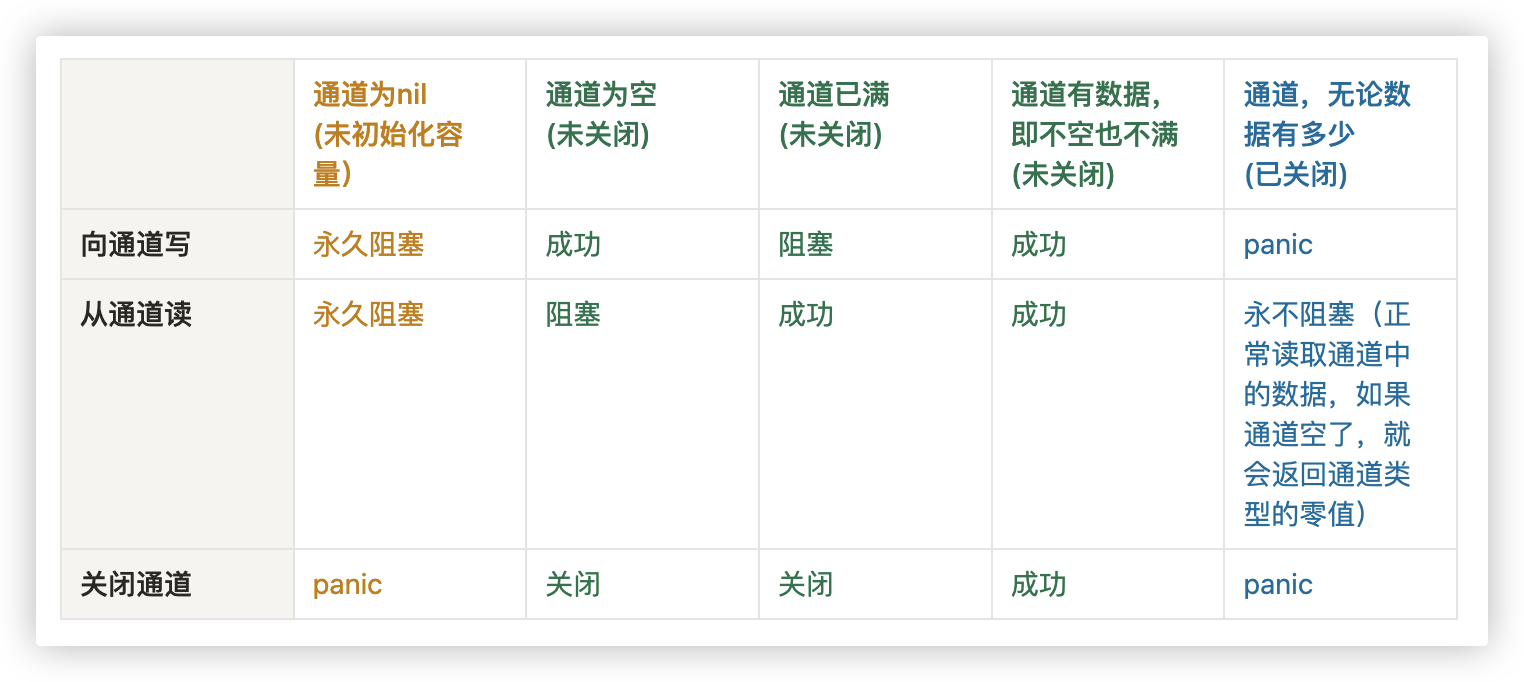
速记口诀:读关闭无数据返回空值,读空、写满阻塞,写关闭异常,关闭空、关闭已关闭异常
在实践中,上表的两种情况应该规避,避免出现死锁:
通道未初始化(第2列)
这个问题主要依赖开发者,不要忘记初始化通道。否则会出现死锁或panic
goch := make(chan int, 10)通道关闭(第6列)
关闭一般由写goroutine执行,并且只有在读goroutine的代码逻辑中,真的判断了是否关闭,我们才会在写goroutine中执行关闭通道,否则就不用关闭(关闭通道不是必须的)
goclose(ch)注意下,通道关闭了,其中的数据仍然可以被读出来
如何获知通道被关闭了?
通道关闭
目前Go语言中判断通道是否被关闭,必须通过读取通道才能得知:
循环读取通数据,等通道数据被读空后。ok为false代表通道被关闭了(可见在Go的逻辑中,并不希望我们直接判断通道是否关闭,而是希望我们正常读取数据,最后才能知道通道是否关闭)
data,ok:=<-ch如果通道中还有数据,则ok=true,data为读出的值
如果数据被读空了,且通道被关闭,则返回ok=false,data为零值;如果通道未关闭,则阻塞读goroutine
遍历读取通道
重点: close通道后,通道仍能读取剩余的数据,当数据读取完毕时继续读取将返回零值。为了不读取无效的零值,我们可以采用下面两种方法
方式一:读取到管道为空时,ok变会为false,x为元素类型对应的零值
for {
x, ok := <-ch1
if !ok {
fmt.Println("channel读取完毕")
break
}
ch2 <- x * 2
}方式二:读取关闭的通道,当通道为空时则结束,继续执行后面的代码。如果通道未关闭则一直阻塞,等待读取。(所以推荐写入者要关闭通道,读取者才会读取空后,继续运行其他代码)
for item := range ch2 {
fmt.Println(item)
}例子:close通道后,for range读取完毕,继续运行其他代码
package main
import "fmt"
func main() {
ch := make(chan int, 10)
ch <- 1
ch <- 2
close(ch)
for item := range ch {
fmt.Println(item)
}
fmt.Println("结束")
}
//1
//2
//结束重点:
关闭的通道,不要再执行close操作了,否则就会panic,所以一般是写goroutine在最后关闭通道。
如果通道一直不关闭,上面两种方式会一直阻塞读取,即发生死锁
package main
import (
"fmt"
)
func setData(ch chan int) {
//这段代码比较有意思的点,使用的是无缓冲区的通道,这就会导致for循环每写入一次,就会停止,等待数据被读走后,再次写入
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}
func main() {
ch := make(chan int)
go setData(ch)
//主进程被for循环阻塞。这段代码记住,用于遍历channel,后面会再次提到
for {
value, ok := <-ch
if ok {
fmt.Printf("读取值:%v,%v\n", value, ok)
} else {
fmt.Println("读取结束")
break
}
}
fmt.Println("主goroutine结束")
}
主、子goroutine通讯
WaitGroup实际上是主goroutine与子goroutine通讯,在子goroutine均结束后,才终止主goroutine
这里使用的是无缓冲区的通道实现的,不必再使用WaitGroup
通过主goroutine的读操作阻塞
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan bool)
go func() {
fmt.Println("子goroutine执行")
time.Sleep(2 * time.Second)
ch <- true
}()
//通道为空,会阻塞主goroutine。必须等待子goroutine写入通道数据,主goroutine才会继续执行
<-ch
fmt.Println("主goroutine执行完毕")
}这种也是同样的道理,通过主goroutine的写操作阻塞
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan bool)
go func() {
fmt.Println("子goroutine执行")
time.Sleep(2 * time.Second)
//区别看这里
<-ch
}()
//区别看这里
ch<-true
fmt.Println("主goroutine执行完毕")
}select语句
select {
case xx:
//执行语句1
case yy:
//执行语句2
default://可以没有default
//执行语句3
}注意点:
可以有多个case,每个case必须是通道操作(读、写通道)。如果有多个case的通道操作都没被阻塞,则随机挑选一个未被阻塞的case执行
gopackage main import ( "fmt" ) func main() { ch1 := make(chan int, 1) ch2 := make(chan int, 1) ch1 <- 100 ch2 <- 200 var data int //两个读取通道的操作均不被阻塞,会随机读取一个 select { case data = <-ch1: fmt.Println("执行了第一个case", data) case data = <-ch2: fmt.Println("执行了第二个case", data) } }如果没有default,所有case都被阻塞,则整个select阻塞等待某一个case不阻塞后执行该case。如果有default,一定不会阻塞,会直接执行default
gopackage main import ( "fmt" ) func main() { ch1 := make(chan int, 1) ch2 := make(chan int, 1) var data int //两个通道都为空,肯定阻塞了,所以会走defalut。这个例子中如果没有default会造成死锁,因为ch1、ch2均没有输入,他们会造成一直阻塞,即死锁 select { case data = <-ch1: fmt.Println("执行了第一个case", data) case data = <-ch2: fmt.Println("执行了第二个case", data) default: fmt.Println("执行了default") //执行了default } }for循环中使用select。持续阻塞等待从ch读取(通道写入后,需要close,否则这两个代码都会一直阻塞后续代码)
gofor { select { case x, ok:= <-ch: if !ok{ break } fmt.Println(i) } }等价于前面的for range
gofor i:=range ch{ fmt.Println(i) }
生产者消费者
1:1
1:n
n:1
n:m
生产者消费者模型在实现上有各种需要注意的细节点。这里我们暂时不考虑,只介绍重点:
1、操作系统I/O是串行的,多协程操作I/O也会被强制串行。这里模拟下了下I/O,多个协程将I/O操作写入通道(生产者),通道再去按顺序执行I/O(消费者)
package out
import "fmt"
type Out struct {
data chan interface{}
}
//io是串行的(不会并行),所以这里只需要全局维持一个实例,存到变量out中
var out *Out
func NewOut() *Out {
if out == nil {
out = &Out{
data: make(chan interface{}),
}
}
return out
}
// Input 作为生产者,在Out.data中写入数据
func Input(i interface{}) {
out.data <- i
}
// OutPut Out类型的方法,作为消费者读取Out.data中的数据,并打印
func (o *Out) OutPut() {
for {
select {
case i := <-o.data:
fmt.Println(i)
}
}
}2、生产者与消费者,一对一的例子:
package one_one
import (
"app/out"
"sync"
)
// Task 表示一个任务实例
type Task struct {
ID int64
}
// run 任务的方法,表示执行这个任务
func (t *Task) run() {
out.Input(t.ID)
}
const taskNum int64 = 10000
// producer 生产者向通道写入taskNum个Task
func producer(taskCh chan<- Task) {
var i int64
for i = 1; i <= taskNum; i++ {
taskCh <- Task{
ID: i,
}
}
close(taskCh) //这里关闭了channel,消费者for range在读取完后,才会结束函数。否则,会一直阻塞
}
// consumer 消费者读取通道中的Task,然后调用Task.run执行任务
func consumer(taskCh <-chan Task) {
for task := range taskCh {
task.run()
}
}
var taskCh = make(chan Task, 10)
// Exec 执行生产者、消费者
func Exec() {
//使用WaitGroup避免Exec结束时,协程被终止
var wg sync.WaitGroup
wg.Add(2)
//1个生产者
go func() {
defer wg.Done()
producer(taskCh)
}()
//1个消费者
go func() {
defer wg.Done()
consumer(taskCh)
}()
wg.Wait()
}这里重点记住
生产者:
func producer(taskCh chan<- Task) {
var i int64
for i = 1; i <= taskNum; i++ {
taskCh <- Task{
ID: i,
}
}
close(taskCh) //这里关闭了channel,消费者for range在读取完后,才会结束函数。否则,会一直阻塞
}消费者:
//这是一个消费者,其内部必须一直等待读取管道。可以for循环创建多个消费者
func consumer(taskCh <-chan Task) {
for task := range taskCh {
task.run()
}
}time库通道相关函数
Timer相关的几个方法:

Timer是类似于setTimeout,指定一个时间间隔,到时间后触发一次
NewTimer
创建一个Timer对象,它是一个结构体,其中C字段是一个只读的通道。到达指定的时间后,会在这个通道中放入一个当前时间的时间对象(Time对象)
因为C是个只读的通道,所以读取这个通道,会阻塞其所在的goroutine,直到时间到了后,会自动放入一个当前时间的时间对象
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println(time.Now()) //2023-01-07 20:22:18.478305 +0800 CST m=+0.000077767
timer := time.NewTimer(5 * time.Second)
ch := timer.C
t := <-ch //阻塞,5s后解除阻塞
fmt.Println(t) //2023-01-07 20:22:23.478783 +0800 CST m=+5.000432370
}AfterFunc
定时触发函数,返回值也是Timer
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func main() {
wg.Add(1)
fmt.Println(time.Now()) //2023-01-07 20:32:54.275679 +0800 CST m=+0.000106664
time.AfterFunc(5*time.Second, func() {
fmt.Println("5s后触发") //5s后触发
wg.Done()
})
wg.Wait()
}Reset、Stop
用于重启、停止Timer
timer := time.NewTimer(5 * time.Second)
timer.Stop()还有两个time包内的函数,返回值是通道

After
等价于NewTimer(d).C,即在d时间间隔后,像返回的通道中写入一个时间对象(Time)
Tick
返回值是通道,每隔时间间隔d向通道放入一个当前的时间实例
func Tick(d Duration) <-chan Time每隔1秒打印当前时间
for temp := range time.Tick(time.Second) {
fmt.Println(temp)
}
//2022-05-12 00:54:56.79165 +0800 CST m=+23.001189704
//2022-05-12 00:54:57.790955 +0800 CST m=+24.000480296
//2022-05-12 00:54:58.791673 +0800 CST m=+25.001182955
//....超时处理
package main
import (
"fmt"
"time"
)
var ch chan bool
func doSomething() {
time.Sleep(10 * time.Second)
ch <- true
return
}
func main() {
ch = make(chan bool, 1)
startTime := time.Now()
//这里必须使用goroutine,如果直接调用函数就会Sleep到10s后才会执行select
go doSomething()
select {
case <-time.After(15 * time.Second):
curTime := time.Now()
fmt.Println("任务超时,耗时", curTime.Sub(startTime))
case <-ch:
curTime := time.Now()
fmt.Println("完成任务,耗时", curTime.Sub(startTime))
}
}context包
context这个单词的含义是"上下文"
其主要作用是:
维持一个全局的变量,其中可以存储键值对
设置超时时间,当超时后,就能收到通知。常用于同步多个goroutine
context包的主要函数、类型:

Context类型
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
//获取key的值
Value(key interface{}) interface{}
}Background
Background() //创建一个空的上下文WithDeadline
指定最后的时间期限A,返回新的Context对象,如果给这个对象设置新的时间期限B,则新的Context以两个时间中最早的为准
package main
import (
"context"
"fmt"
"time"
)
func main() {
// 创建一个父 Context
parentContext := context.Background()
// 设置截止时间为当前时间加上5秒
deadline := time.Now().Add(5 * time.Second)
// 使用 WithDeadline 创建带有截止时间的 Context
ctx, cancel := context.WithDeadline(parentContext, deadline)
defer cancel() // 确保在使用完成后取消 Context
// 模拟一个耗时操作
select {
case <-time.After(2 * time.Second):
fmt.Println("Operation completed successfully.")
case <-ctx.Done():
fmt.Println("Operation canceled due to deadline.")
}
}WithTimeout
WithDeadline是指定一个截止时刻,WithTimeout是指定一个时间间隔
WithTimeout在指定的时间间隔结束后,ctx.Done()通道放入一个元素
如果想要提前取消,可直接调用cancel函数,则立即在ctx.Done()通道放入一个元素
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
select {
case <-ctx.Done():
fmt.Println("超时取消了")
}
}WithValue
将上下文对象包装下增加新的键值对,返回新的上下文
ctx := context.Background()
ctx = context.WithValue(ctx, "name", "jack")
fmt.Println(ctx.Value("name")) //jackGo官方不推荐直接使用string类型的值作为key,而是建议定义新的类型
超时处理
package main
import (
"context"
"fmt"
"time"
)
// handle 用来模拟耗时操作(例如,网络请求)
func handle(ctx context.Context, duration time.Duration, deep int) {
if deep > 0 {
time.Sleep(200 * time.Millisecond)
handle(ctx, duration, deep-1)
}
select {
case <-ctx.Done():
fmt.Printf("%v层handle,context取消,%v\n", deep, ctx.Err())
case <-time.After(duration):
fmt.Printf("%v层handle,time取消\n", deep)
}
}
//1、基于时间的超时
func worker1() {
deep := 10
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
go handle(ctx, 500*time.Millisecond, deep)
//阻塞主函数不结束。如果主函数超时,这里就会继续执行下去,子函数handle就会直接全部结束
select {
case <-ctx.Done():
fmt.Printf("主worker1函数执行完毕,%v\n", ctx.Err())
}
}
//2、基于操作的超时
func worker2() {
deep := 10
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
go handle(ctx, 500*time.Millisecond, deep)
//模拟10s后,手动调用cancel超时
time.Sleep(10 * time.Second)
cancel()
}
func main() {
worker1()
worker2()
}并发安全
sync.Once
在某些场景下我们需要确保某些操作即使在高并发的场景下也只会被执行一次,例如只加载一次配置文件等。第一次Do中的函数f会执行,第二次就不会执行了
func (o *Once) Do(f func()) //提醒下,sync.xxx都是结构体类型,Do是sync.Once的方法延迟一个开销很大的初始化操作到真正用到它的时候再执行,是一个很好的实践。因为预先初始化一个变量会增加程序的启动耗时,而且还有可能实际执行过程中这个变量没有用上
例子
var icons map[string]image.Image
var loadIconsOnce sync.Once
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 是并发安全的
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons)//创建的多个goroutine,只有一个会完成初始化的操作
return icons[name]
}sync.Map
Go 语言中内置的 map 不是并发安全的,如果在多个goroutine中读写map类型的变量,会报错
fatal error: concurrent map writes所以在启用多个goroutine的函数中应该使用sync.Map类型
该类型提供了一下方法
| 方法名 | 功能 |
|---|---|
| Store(key interface{}, value interface{}) | 存储key-value数据 |
| Load(key interface{}) (value interface{}, ok bool) | 查询key对应的value |
| Delete(key interface{}) | 删除key |
| LoadOrStore(key, value interface{}) (actual interface{}, loaded bool) | 查询key对应的value,如果没有则存储key-value |
| LoadAndDelete(key interface{}) (value interface{}, loaded bool) | 查询并删除key |
| Range(f func(key, value interface{}) bool) | 对map中的每个key-value依次调用f(看成是遍历Map) |
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func main() {
var syncMap = sync.Map{}
for i := 0; i < 10; i++ {
wg.Add(1)
go func(key, value int) {
syncMap.Store(key, value)
wg.Done()
}(i, i)
}
wg.Wait()
syncMap.Range(func(key, value interface{}) bool {
fmt.Printf("%d:%d\n", key, value)
return true
})
//0:0
//1:1
//2:2
//3:3
//4:4
//5:5
//7:7
//9:9
//6:6
//8:
}僵尸进程
僵尸进程的产生主要是因为父进程没有正确地处理已终止子进程的资源。
当子进程执行完毕并调用exit()函数退出时,它的进程描述符(PCB)并不会立即被系统回收。如果父进程没有调用wait()或waitpid()系统调用来获取子进程的终止状态并释放其资源,那么子进程的进程描述符和其他相关信息(如进程号、退出状态、运行时间等)会被保留,使得子进程进入一种称为僵尸状态的状态
僵尸进程不会消耗过多的CPU或内存资源,但会占用系统资源,如果大量子进程陷入僵尸状态,可能导致系统性能下降,甚至因为进程打满而崩溃
还有一种情况,当父进程创建了一个子进程时,他们的运行是异步的,父进程无法预知子进程会在什么时候结束。如果父进程在子进程结束前已经终止,那么子进程会由init进程接管,init进程会回收子进程占用的资源。但如果父进程在子进程结束后才终止,且没有正确处理子进程,那么僵尸进程就会产生
我遇到的场景:多线程调用git命令克隆仓库
参考:https://www.jb51.net/article/231381.htm
阻塞-返回输出
func exec_shell(s string) (string, error){
//函数返回一个*Cmd,用于使用给出的参数执行name指定的程序
cmd := exec.Command("/bin/bash", "-c", s)
//读取io.Writer类型的cmd.Stdout,再通过bytes.Buffer(缓冲byte类型的缓冲器)将byte类型转化为string类型(out.String():这是bytes类型提供的接口)
var out bytes.Buffer
cmd.Stdout = &out
//Run执行命令,并阻塞直到完成。 这里stdout被取出,cmd.Wait()无法正确获取stdin,stdout,stderr,则阻塞在那了
err := cmd.Run()
if err != nil {
return "",err
}
return out.String(), err
}阻塞-处理输出再返回
func execCommand(commandName string, params []string) bool {
// 1、函数返回一个*Cmd
cmd := exec.Command(commandName, params...)
// 2、StdoutPipe方法返回一个在命令Start后与命令标准输出关联的管道(Wait方法获知命令结束后会关闭这个管道,一般不需要显式的关闭该管道)
stdout, err := cmd.StdoutPipe()
if err != nil {
fmt.Println(err)
return false
}
// 3、执行命令
cmd.Start()
reader := bufio.NewReader(stdout)//创建一个流来读取管道内内容,这里逻辑是通过一行一行的读取的
//实时循环读取输出流中的一行内容
for {
line, err2 := reader.ReadString('\n')
if err2 != nil || io.EOF == err2 {
break
}
fmt.Println(line)
}
// 4、阻塞直到该命令执行完成(该命令必须是被Start方法开始执行的)
// Wait阻塞等待fork出的子进程执行的结果,和cmd.Start()配合使用。如果不写Wait阻塞住进程,会导致fork出执行shell命令的子进程变为僵尸进程
cmd.Wait()
return true
}文件操作
权限基础知识
linux 下有2种文件权限表示方式,即“符号表示”和“八进制表示”。
(1)符号表示方式:
- --- --- ---
type owner group others
文件的权限是这样子分配的 读 写 可执行 分别对应的是 r w x 如果没有那一个权限,用 - 代替
(-文件 d目录 |连接符号)
例如:-rwxr-xr-x
(2)八进制表示方式:
r ——> 004
w ——> 002
x ——> 001
- ——> 000
所以:0是没有任何权限,1是仅可执行,3是可写可执行,5是可读可执行,6是可读可写,7是全部权限
例如:(回忆下,开头的0是八进制数据的前缀)
0755 //owner有所有权限,group、others可读可执行
0777 //owner、group、others 有所有权限
0666 //owner、group、others 都可读可写文件路径操作
package main
import (
"fmt"
"path/filepath"
)
func main() {
path := "a.txt"
//判断是否为绝对路径:func IsAbs(path string) bool
fmt.Println(filepath.IsAbs(path)) //false
//转化为绝对路径func Abs(path string) (string, error)
// 注意: 是将代码运行路径(pwd)作为根路径,即:同一个go文件在不同路径下运行,根路径不同
// 例如: Abs(.)返回的就是代码运行路径。
fmt.Println(filepath.Abs(path)) //Users/yc/Documents/GO/GoProject/testFunc/a.txt <nil>
//拼接路径:func Join(elem ...string) string
fmt.Println(filepath.Join("..", path)) //../a.txt
}目录操作
Mkdir、MkdirAll
package main
import (
"fmt"
"os"
)
func main() {
//使用Mkdir创建的目录有两点限制:1、创建的目录不能存在;2、只能创建一层目录(其父目录必须存在),例如:创建./newFolder/data,必须保证newFolderfu存在才能成功创建data目录
err := os.Mkdir("./newFolder/data", 0777)
if err != nil {
fmt.Printf("目录创建失败err-->%v", err)
return
}
fmt.Println("目录创建成功") //目录创建成功
//MkdirAll 与 Mkdir 用法相同,区别是没有Mkdir的两点限制
}常见的写法,目录不存在则创建目录
// Stat入参可以是目录、文件路径
// 但是这里的功能是判断目录不存在,则创建目录,所以入参应该是目录路径
if _, err := os.Stat(dst); err != nil {
if err := os.MkdirAll(dst, os.ModePerm); err != nil {
return nil, err
}
}文件操作
文件信息
FileInfo类型:FileInfo是一个接口类型,用来描述一个文件的信息
type FileInfo interface {
Name() string // 文件的名字(不含扩展名)
Size() int64 // 普通文件返回值表示其大小;其他文件的返回值含义各系统不同
Mode() FileMode // 文件的模式位
ModTime() time.Time // 文件的修改时间
IsDir() bool // 等价于Mode().IsDir(),判断是否为目录
Sys() interface{} // 底层数据来源(可以返回nil)
}获取文件信息
返回FileInfo类型的函数:
func Stat(name string) (fi FileInfo, err error)
func Lstat(name string) (fi FileInfo, err error)参数都是文件、目录路径,如果不存在,则返回的错误值为*PathError类型
区别:
- Stat:如果指定的文件对象是一个符号链接(软链接),返回的FileInfo描述该符号链接指向的文件的信息
- Lstat:如果指定的文件对象是一个符号链接(软链接),返回的FileInfo描述该符号链接的信息
例子
package main
import (
"fmt"
"os"
)
/**
FileInfo: 文件信息
*/
func main() {
fileInfo, err := os.Stat("./a.txt")
if err != nil {
fmt.Printf("err:%v\n", err)
return
}
fmt.Println(fileInfo.Name()) //a.txt
fmt.Println(fileInfo.Size()) //11字节
fmt.Println(fileInfo.Mode()) //-rw-r--r-- 。
fmt.Println(fileInfo.ModTime()) //2022-11-23 13:19:50.828517901 +0800 CST
fmt.Println(fileInfo.IsDir()) //false
fmt.Println(fileInfo.Sys()) //
}创建文件
File类型,表示一个打开的文件对象。
type File struct {
// 内含隐藏或非导出字段
}创建文件的函数
func Create(name string) (file *File, err error)例子
//创建文件。创建的文件权限为666(任何人可读可写);若文件存在,则会清空已存在文件;只能创建文件,所以./newFolder/a.txt这种参数,必须保证newFolder目录存在
file, err := os.Create("./newFolder/a.txt")
if err != nil {
fmt.Printf("创建文件出错,err-->%v", err)
return
}删除文件
Remove
可以用来直接删除文件,删除目录时,只有目录为空时,才能被删除
err := os.Remove("./a.txt")
if err != nil {
fmt.Printf("文件打开错误:err-->%v", err)
return
}RemoveAll
这个删除比Remove多了一点功能就是:即使目录不为空,也可直接删除
打开文件
Open创建的文件是只读的(不可写入数据)
file, err := os.Open("a.txt")
if err != nil {
fmt.Printf("文件打开错误:err-->%v", err)
return
}OpenFile可通过
参数1:文件名
参数2:指定打开文件的方式。多个常量使用
|连接参数3:如果文件不存在,且参数2指定了
O_CREAT,则会按照该参数指定的权限创建文件。常量os.ModePerm等价于0777,即所有用户均有读写执行权限
file, err := os.OpenFile("a.txt", O_RDONLY|syscall.O_WRONLY, os.ModePerm)
if err != nil {
fmt.Printf("文件打开错误:err-->%v", err)
return
}参数2的选项
const (
O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
O_RDWR int = syscall.O_RDWR // 读写模式打开文件,是前两个的结合
O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件【写操作默认不会创建文件】
O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部。【写操作默认会覆盖文件】
O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)关闭文件
上一部分,介绍了打开文件,所有函数都会返回一个File类型的变量(文件对象)。一旦文件被打开,就一定记得要关闭,否则文件会一直是被占用状态
file.Close()I/O操作
基础知识
I/O操作指定的数据的输入输出
Go语言中的I/O相关的功能大部分都在io包中,io包中最重要的就是两个接口类型:
Reader类型
该类型是个接口,所有实现Read方法的类型都可以看做是Reader
gotype Reader interface { Read(p []byte) (n int, err error) }Read方法:读取len(p)字节数据写入参数p中,当Read在读取部分数据后遭遇错误时或者到达文件结尾,就会结束读取,并返回读取的字节数和错误对象(读到文件结尾,
err==io.EOF),且p中存储着发生错误前已读入的数据。Writer类型
该类型是个接口,所有实现Write方法的类型都可以看做是Writer
gotype Writer interface { Write(p []byte) (n int, err error) }Write方法:把len(p) 字节数据从参数p中,写入底层的数据流。它会返回写入的字节数(0 <= n <= len(p))和遇到的任何导致写入提取结束的错误
注意:Read、Write的参数类型是字节切片
实现了这两个接口怎么用?
实现了这个接口类型的对象,就可以:
该对象的实例自身带有Read、Write方法可以用来读写
把该对象作为参数传入,某些指定参数类型为
io.Reader、io.Writer的函数(这些函数内部还是调用了对象自身带有的Read、Write方法)go//这两个函数在bufio包中,用于读写,在后面会讲到 func NewReader(rd io.Reader) *Reader func NewWriter(w io.Writer) *Writer
哪些类型实现了这两个接口?
标准输入输出
os.Stdin os.Stdoutbytes.Buffer与strings.Builder实现了io.Reader、io.WriterGo1.10后加入了
strings.Builder,性能获得极大提升好文两个都是为了进行字符串拼接
gopackage main import ( "bytes" "fmt" "strconv" ) func intsToString(values []int) string { var buf bytes.Buffer buf.WriteByte('[') for i, v := range values { if i > 0 { buf.WriteString(",") } buf.WriteString(strconv.Itoa(v)) //数字转成字符,才能作为WriteString的参数 } buf.WriteByte(']') return buf.String() } func main() { fmt.Println(intsToString([]int{1, 2, 3})) // "[1, 2, 3]" }函数是为了将数字转化为16位的二进制形式,涉及到位运算相关知识
gopackage main import ( "fmt" "math" "strings" ) func binaryFormat(n int64) string { c := int64(math.Pow(2, 31)) var res strings.Builder for i := 0; i < 32; i++ { if n&c != 0 { res.WriteString("1") } else { res.WriteString("0") } c >>= 1 } return res.String() } func main() { fmt.Println(binaryFormat(4)) }strings.NewReader返回的strings.Reader,实现了io.Readergofunc NewReader(s string) *Reader例子,只读了100个字节,如果需要完整的读文件,要使用for循环
gopackage main import ( "fmt" "strings" ) func main() { temp := make([]byte, 100) reader := strings.NewReader("hello world") _, err := reader.Read(temp) if err != nil { fmt.Printf("err-->%v", err) return } fmt.Println(string(temp)) }http
http.Response.Body 实现了io.Reader接口net.Conn连接
go//server.go package main import ( "bufio" "fmt" "net" "sync" ) func process(conn net.Conn) { defer conn.Close() for { reader := bufio.NewReader(conn) //接收连接的内容,也可以不用bufio,而是直接使用conn.Read([]byte) var buf [1000]byte n, err := reader.Read(buf[:]) if err != nil { fmt.Printf("读取失败%v\n", err) continue } fmt.Printf("接收到:%s\n", string(buf[:n])) conn.Write([]byte("服务端已收到")) //写入连接内容 } wg.Done() } var wg sync.WaitGroup func main() { // 1. 监听端口 listener, err := net.Listen("tcp", "127.0.0.1:9090") if err != nil { fmt.Printf("监听失败,%v\n", err) return } defer listener.Close() // 2. 循环监听建立的连接 for { conn, err := listener.Accept() if err != nil { fmt.Printf("监听连接失败%v\n", err) continue } // 3. 处理连接 wg.Add(1) go process(conn) } wg.Wait() }hash.Hash
这个类型实现了io.Writer
goh := md5.New() //返回值是hash.Hash实例 io.WriteString(h, "go语言学习笔记") //将 "go语言学习笔记" 写入 hash.Hash实例中文件对象File
上一章节【文件操作】,讲到的创建文件、打开文件返回的 File类型(文件对象),实现了这两个接口,所以File类型的实例有这两个方法

注意:后面的IO操作基本都以读写文件对象作为例子,但是实际上可以读取 支持任何实现了io.Reader和io.Writer的对象
读文件数据(UTF-8编码的文本)
注意GO语言默认支持UTF-8编码的文本。读取方法,读取的文本也需要是UTF-8的
方式1
指定一个固定长度的字节切片,循环读取。在写这里时,我发现有一个细节,Read方法放入一个未初始化的切片,不能读进去内容。但是,我们可以定义一个未初始化的切片(这样就不用指定长度了)来接收每一次读入的字节
package main
import (
"fmt"
"io"
"os"
)
func main() {
file, err := os.Open("./a.txt")
defer file.Close()
if err != nil {
fmt.Println("read from file failed... ")
return
}
var res []byte
for {
temp := make([]byte, 100)
n, err := file.Read(temp) //将数据读入temp中,n是读取的字节数
if err == io.EOF||n=0 {
fmt.Println("读取文件结束")
break
}
if err != nil {
fmt.Println("读取文件失败")
break
}
// 这个技巧应该注意:temp是循环读取的,假设最后一次读取了10个字节,但是剩下的90个字节还是上一次读取的结果。这种赋值能保证temp中len长度内的都是本次循环的实际数据
temp=temp[:n]
res = append(res, temp...)
}
fmt.Printf("%s", string(res))
}写文件数据(UTF-8编码的文本)
Go语言默认支持UTF-8,写入方法写入的也是UTF-8编码的文本
file对象还实现了WriteString方法,参数为字符串,可向文件中直接写入字符串
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.OpenFile("./a.txt", os.O_RDWR|os.O_CREATE|os.O_APPEND, os.ModePerm)
defer file.Close()
if err != nil {
fmt.Printf("打开文件失败,err-->%v", err)
return
}
writeStr := "你好,世界"
_, err = file.Write([]byte(writeStr))
if err != nil {
fmt.Printf("写入失败,err-->%v", err)
return
}
}这里有个小的细节补充:Create函数也实现了io.Writer接口。可以创建文件后直接写入数据
file, err := os.Create(fileName)设置游标位置
前面我们只在写文件时,可以通过OpenFile的第二个参数指定,写入的数据追加到文件的末尾
os.OpenFile("./a.txt", os.O_RDWR|os.O_CREATE|os.O_APPEND, os.ModePerm)如何指定开始读写的位置?
这要讲到Seeker接口,它有一个Seek方法。
type Seeker interface {
//参数1:偏移量(从1开始,1从游标的起始位置开始向后移动1字节)
//参数2:游标的起始位置
Seek(offset int64, whence int) (int64, error)
}游标起始位置,类型是int:
0:文件开头位置
1:游标当前位置
2:文件末尾位置File对象就实现了这个接口,有Seek方法
package main
import (
"fmt"
"os"
)
func main() {
//文件内容是:abcde
file, err := os.OpenFile("./a.txt", os.O_RDWR, os.ModePerm)
if err != nil {
fmt.Printf("打开文件失败,err-->%v", err)
return
}
//读取
file.Seek(1, io.SeekStart)//io.SeekStart指定游标起始位置是文件开头,向后移动offset个字节。应输出b
temp := make([]byte, 1)
file.Read(temp)
fmt.Println(string(temp)) //b
//写入
file.Seek(0, io.SeekEnd)//指定游标起始位置是文件末尾,向后移动0字节。文件会在默认追加写入字符f
file.Write([]byte("f"))
}
// Seek的第二个参数:
//const (
// SeekStart = 0 // 光标置为文件开头
// SeekCurrent = 1 // 光标置为当前位置
// SeekEnd = 2 // 光标置为文件结尾
//)断点续传
读取指定字节
从r中读取buf大小的数据。如果r中的数据不够则返回错误。ReadFull读取后游标后移,再次读取从游标的位置继续读取
func ReadFull(r Reader, buf []byte) (n int, err error)这个函数非常好用
复制文件
func Copy(dst Writer, src Reader) (written int64, err error)参数是两个接口类型,File对象就实现了这两个方法,所以File对象可作为参数传入
这个方法的底层实现,就是先读入一个字节切片的数据,然后马上写入到输出文件,然后循环读写。与我们前面学的读写文件的方式一样,只不过Copy方法指定的切片大小为
tempSlice := make([]byte, 32*1024)Copy用于将src复制到dst,他的场景不仅仅是我们常规意义上的复制。例如:
输出到控制台
io.Copy(os.Stdout,r) //下载
package main
import (
"fmt"
"io"
"net/http"
"os"
)
func download(url, fileName string) {
response, err := http.Get(url)
if err != nil {
fmt.Printf("请求失败,err-->%v", err)
return
}
file, err := os.Create(fileName)
if err != nil {
fmt.Printf("创建文件失败,err-->%v", err)
return
}
defer func(){
response.Body.Close()
file.Close()
}()
io.Copy(file, response.Body)
}
func main() {
download("https://heyingjiee.github.io/logo.png", "avatar.png")
}断点续传
package main
import (
"fmt"
"io"
"os"
"path"
"path/filepath"
"strconv"
"strings"
)
func main() {
// 根目录下放一个test.png图片
srcFilePath, _ := filepath.Abs("./test.png")
srcRootDir, err := filepath.Abs(filepath.Dir(srcFilePath))
if err != nil {
fmt.Printf("获取根目录失败,err -->%v", err)
return
}
srcFileName := strings.Split(filepath.Base(srcFilePath), ".")[0]
srcFileExt := strings.Split(filepath.Base(srcFilePath), ".")[1]
// 临时文件绝对路径(记录复制了多少个byte)
var tempFilePath = path.Join(srcRootDir, "./temp.txt")
// 目标文件绝对路径
var dstFilePath = path.Join(srcRootDir, srcFileName+"-copy."+srcFileExt)
// 打开三个文件
srcFile, err := os.Open(srcFilePath)
if err != nil {
fmt.Printf("打开源文件失败,err -->%v", err)
return
}
tempFile, err := os.OpenFile(tempFilePath, os.O_CREATE|os.O_RDWR, os.ModePerm)
if err != nil {
fmt.Printf("打开临时文件失败,err -->%v", err)
return
}
dstFile, err := os.OpenFile(dstFilePath, os.O_CREATE|os.O_RDWR, os.ModePerm)
if err != nil {
fmt.Printf("打开目标文件失败,err -->%v", err)
return
}
// defer 关闭三个文件
defer func(fileSlice []*os.File) {
for _, file := range fileSlice {
err := file.Close()
if err != nil {
continue
}
}
}([]*os.File{srcFile, tempFile, dstFile})
// 读取临时文件
var bs = make([]byte, 100)
totalCopyByte, err := tempFile.Read(bs)
totalCopyCount, err := strconv.ParseInt(strconv.Itoa(totalCopyByte), 10, 64)
if err != nil {
fmt.Printf("读取临时文件失败,err -->%v", err)
return
}
// 对源、目标文件设置游标
srcFile.Seek(int64(totalCopyCount), io.SeekStart)
dstFile.Seek(int64(totalCopyCount), io.SeekStart)
copyData := make([]byte, 1024)
n1 := -1
n2 := -1
// 循环复制
for {
n1, err = srcFile.Read(copyData)
if err == io.EOF || n1 == 0 {
fmt.Printf("文件复制完成")
os.Remove(tempFilePath)
break
}
if err != nil {
fmt.Printf("读取源文件失败,err -->%v", err)
return
}
n2, err = dstFile.Write(copyData)
if err != nil {
fmt.Printf("写入目标文件失败,err -->%v", err)
return
}
_, err = tempFile.WriteString(strconv.Itoa(totalCopyByte + n2))
if err != nil {
fmt.Printf("写入临时文件失败,err -->%v", err)
return
}
}
}ioutil包
Go语言的I/O操作基本都在io包中,但其实还有一个ioutil包,它是对io包的封装,提供更加方便易用的方法
下面两个函数,参数直接就是文件名,不用再自己手动Open文件,获取File对象后才能读写,但是,当文件非常大时,最好不要使用(一次性读写,bufio包使用了缓存,显著提高效率,后面会讲到)
gofunc ReadFile(filename string) ([]byte, error) //写入文件。存在文件,会覆盖原文件。没有则会创建文件,文件权限是第三个参数。第二个参数就是写入的数据 func WriteFile(filename string, data []byte, perm os.FileMode) error例子
gopackage main import ( "fmt" "io/ioutil" ) func main() { byteStr, err := ioutil.ReadFile("./a.txt") if err != nil { fmt.Printf("写入文件,err-->%v", err) return } fmt.Println(string(byteStr)) }从
io.Reader类型中读取gofunc ReadAll(r io.Reader) ([]byte, error)例子
gopackage main import ( "fmt" "io/ioutil" "strings" ) func main() { reader := strings.NewReader("hello world") byteSlice, err := ioutil.ReadAll(reader) if err != nil { fmt.Printf("err-->%v", err) return } fmt.Println(string(byteSlice)) }读取指定目录下的目录(只能得到一层目录,子目录无法获取)
返回值是一个FileInfo的切片,FileInfo类型我们在前面讲过,看这里
gofunc ReadDir(dirname string) ([]os.FileInfo, error)例子
gopackage main import ( "fmt" "io/ioutil" ) func main() { fileInfoSlice, err := ioutil.ReadDir("./") if err != nil { fmt.Printf("err-->%v", err) return } fmt.Printf("目录总个数:%v\n", len(fileInfoSlice)) for i, v := range fileInfoSlice { fmt.Printf("第%v个文件,名为:%v,是否为目录:%v\n", i, v.Name(), v.IsDir()) } }如何获取目录下的所有目录及其子目录?
gopackage main import ( "fmt" "io/ioutil" ) func listFileDir(curPath string, level int) { s := "|--" for i := 0; i < level; i++ { s = fmt.Sprintf("| %s", s) } fileInfoSlice, err := ioutil.ReadDir(curPath) if err != nil { fmt.Printf("读取目录失败,err-->%v", err) return } for _, v := range fileInfoSlice { fmt.Printf("%v%v\n", s, v.Name()) if v.IsDir() { nextPath := fmt.Sprintf("%s/%s", curPath, v.Name()) listFileDir(nextPath, level+1) } } } func main() { listFileDir("./", 0) }运行效果:

临时目录、临时文件
函数并不会删除创建的临时目录、临时文件,需要手动删除
os.Remove(路径)go//在dir目录里创建一个新的、使用prfix作为前缀的临时文件夹,并返回文件夹的路径 func TempDir(dir, prefix string) (name string, err error) //在dir目录下创建一个新的、使用prefix为前缀的临时文件,以读写模式打开该文件并返回os.File指针 func TempFile(dir, prefix string) (f *os.File, err error)例子
gopackage main import ( "fmt" "io/ioutil" "os" ) func main() { tempDirName, err := ioutil.TempDir("./", "Test") if err != nil { fmt.Printf("err-->%v", err) return } fmt.Printf("临时目录名:%v\n", tempDirName) tempFile, err := ioutil.TempFile(tempDirName, "Test") fmt.Printf("临时文件名:%v\n", tempFile.Name()) defer os.Remove(tempDirName) defer os.Remove(tempFile.Name()) }
bufio包
bufio也是I/O相关的包,它也是对io包的封装,其主要是实现了有缓冲区的I/O,通过划分一块内存作为缓冲区,读写都在缓冲区中,最后在读写文件,这会大幅降低访问磁盘的次数,所以可以提高效率
bufio包中,最重要的两个类型(仔细看,这两个不是接口类型,所以有已经实现的方法):
bufio.Reader类型
其封装了
io.Reader类型(注意rd字段类型就是io.Reader)gotype Reader struct { buf []byte rd io.Reader // reader provided by the client r, w int // buf read and write positions err error lastByte int // last byte read for UnreadByte; -1 means invalid lastRuneSize int // size of last rune read for UnreadRune; -1 means invalid }带缓存区的读取实现思路:其核心就是看缓存区>读取的切片,就会使用缓冲区机制,一次性读入数据到缓存(读满缓存区),然后再使用io包的Read读取数据到切片p中(缓存区要删除读走的数据)
获取
bufio.Reader类型的实例:(参数是io包的Reader接口类型,回忆下,File对象实现了这个接口)gofunc NewReader(rd io.Reader) *Reader //默认缓冲区大小为4096字节 func NewReaderSize(rd io.Reader, size int) *Reader //第二个参数可以指定缓冲区大小(单位是字节)其实NewReader的底层还是NewReaderSize
goconst ( defaultBufSize = 4096 ) func NewReader(rd io.Reader) *Reader { return NewReaderSize(rd, defaultBufSize) }因为
bufio.Reader类型已经实现了大量的读取方法,获取的bufio.Reader实例可直接调用:go//注意:bifio包中的Reader类型的Read方法。与前面讲的,File对象自身实现的io包的Reader接口的Read方法不同 func (b *Reader) Read(p []byte) (n int, err error) //ReadLine读取一行,这是一个低水平的行数据读取原语,官方已经不建议使用了 func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error) //注意:ReadString、ReadBytes两个函数的作用是读取到指定字节终止,参数都是字节,返回值才不一样 //读取到delim为止,返回读取的数据(注意返回的是字符串);如果到文件结束都因为没遇到delim停止,就结束并返回错误err==io.EOF func (b *Reader) ReadString(delim byte) (line string, err error) //与ReadString用法一样,只不过返回值是[]byte func (b *Reader) ReadBytes(delim byte) (line []byte, err error)还有一个很好用的函数,前面的函数读取后,读取位置都会后移。Peek可以指定当前读取位置之后的n个字节(Byte),但是不移动读取位置。这个函数可以先判断后面的是不是自己需要的内容,如果是才读取
gofunc (b *Reader) Peek(n int) ([]byte, error)实践例子
gopackage main import ( "bufio" "fmt" "io" "os" ) func main() { //---------Read--------- file, err := os.Open("./a.txt") if err != nil { fmt.Printf("打开文件失败,err-->%v", err) return } var res []byte reader := bufio.NewReader(file) for { temp := make([]byte, 2) _, err := reader.Read(temp) if err == io.EOF { fmt.Printf("文件读取结束 %v\n", err) break } res = append(res, temp...) } fmt.Println(string(res)) //文件读取结束 EOF //abcdef //---------ReadString 从文件读取--------- reader2 := bufio.NewReader(file) str, err := reader2.ReadString('c') if err != nil { fmt.Printf("读取错误,err-->%v", err) return } fmt.Println(str) //abc //---------ReadString 从控制台读取--------- reader3 := bufio.NewReader(os.Stdin) str, err = reader3.ReadString('\n') if err != nil { fmt.Printf("err-->%v", err) return } fmt.Println(str) }Writer类型
其封装了
io.Writer类型gotype Writer struct { err error buf []byte n int wr io.Writer //这里是io.Writer }获取
bufio.Writer类型的实例:gofunc NewWriter(w io.Writer) *Writer func NewWriterSize(w io.Writer, size int) *Writer因为
bufio.Writer类型的写入方法:go//写入一个字符串 func (b *Writer) WriteString(s string) (int, error) //写入一个字节 func (b *Writer) WriteByte(c byte) error //写入一个字符 func (b *Writer) WriteRune(r rune) (size int, err error)注意,只有缓存区写满后,才会写入文件。所以,需要Flush函数刷新缓冲区,把缓冲区的内容写入文件
gofunc (b *Writer) Flush() error实践例子:
gopackage main import ( "bufio" "fmt" "os" ) func main() { file, err := os.OpenFile("./a.txt", os.O_CREATE|os.O_WRONLY, os.ModePerm) if err != nil { fmt.Printf("打开文件失败,err-->%v", err) return } defer file.Close() writer := bufio.NewWriter(file) _, err = writer.WriteString("hello world") if err != nil { fmt.Printf("写入文件,err-->%v", err) return } writer.Flush() }WriteTo方法,常用在HTTP服务器中,将下游服务器的响应数据写入到HTTP响应中时使用(网络编程-反向代理部分章节就用到了)
gofunc (b *Reader) WriteTo(w io.Writer) (n int64, err error) //该方法将读取bufio.Reader对象中当前可读的所有数据,并将其写入到一个实现了io.Writer接口的对象中。WriteTo会一直读取直到bufio.Reader中没有可读数据、遇到错误或到达结尾。
读写其他文件(非UTF-8的文本)
前面已经学习过读取UTF-8编码的文本文件了,如果不是UTF-8编码方式的,则使用解码器指定编码方式
import (
"encoding/encoding"
"io"
"os"
)
func main() {
// 打开文件
f, err := os.Open("file.txt")
if err != nil {
panic(err)
}
defer f.Close()
// 创建解码器
decoder := encoding.NewDecoder("gbk")
// 使用解码器读取文件
reader := decoder.Reader(f)
io.Copy(os.Stdout, reader)
}实际编程中,我们更多遇到的是:读取特定格式的文本、二进制(自定义编码、解码规则)
自定义的二进制格式
参考:http://c.biancheng.net/view/4570.html
使用encoding/binary 包中的:
func Write(w io.Writer, order ByteOrder, data interface{}) error
func Read(w io.Writer, order ByteOrder, data interface{}) error第二个参数,涉及到大端和小端模式的区别,参考这个https://www.cnblogs.com/sunlong88/p/13419715.html
所有网络协议都是采用big endian的方式来传输数据的,而在Intel CPU平台下使用的little endian,所以涉及网络编程时需要使用这个encoding/binary这个包,且第二个参数使用binary.BigEndian,表示将数据xxx转化为大端模式写入w中
binary.Write(w, binary.BigEndian, xxx)网络编程
网络基础知识
这里的很多内容,其实都是《计算机网络》这门课程中的内容
代码层面的网络通讯
在应用程序中,无论是使用WebSocket还是TCP协议,都是通过Socket来编码,Socket(套接字)不是协议,而是不同主机上的应用进程之间进行双向通信的端点的抽象
可以想象,Socket是一个类型,该类型实现了下面方法
通过这些方法,实现网络数据通讯
通讯的两端是对等的。但是实际场景下,客户端与服务端的Socket是有区别的,服务端存在一个特殊的Socket,通过监听客户端的握手包,成功之后就会创建一个新的Socket
通常我们所说TCP、UDP使用的哪种套接字?
TCP:使用的是Stream Socket,特点是面向连接的流式传输套接字,安全,可靠。
UDP:使用的是Datagram Socket,特点是面向消息的套接字,不保持可靠性,简单,速度快。
TCP三次握手与四次挥手
TCP报文的标志位
- SYN:SYN标志表示请求建立连接,只有在第一次握手时才置为1;
- Seq:Seq标志表示这是TCP报文段中的第一个序号,用于可靠传输的序号控制,其值随机产生;
- FIN:FIN标志表示客户端无需关闭通信,因此这个标志位不会被置为1。
三次握手
TCP的三次握手目的是保证连接是全双工的
四次挥手
TCP的四次挥手是因为连接是全双工的,需要确认双方都收到FIN包才能关闭
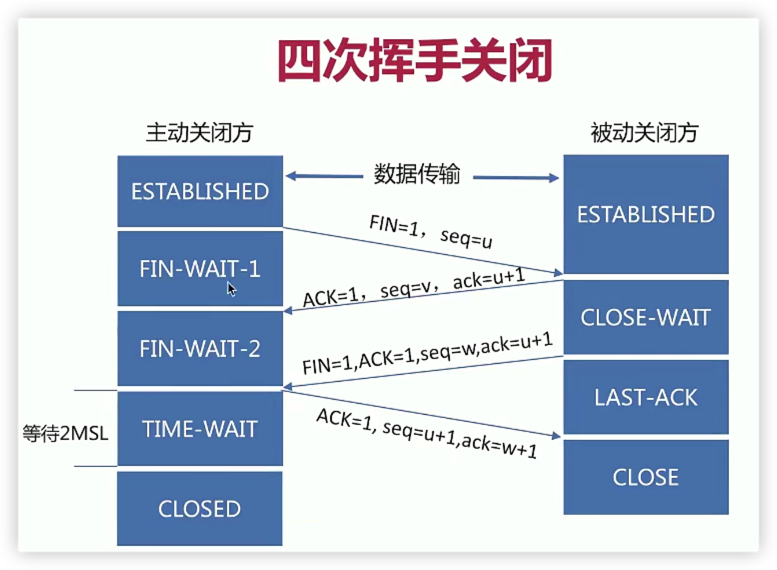
TCP在应用层的实现
经历过三次握手后,客户端与服务器之间建立了一个TCP连接(这是逻辑上的连接)
选取其中一个通讯端:
它的操作系统需要在
内核内存中分配两个缓冲区(读、写buffer,大小由系统参数决定)内核内存只有核心态才能读取
通讯的应用程序是在
用户态,用户态进程是无法直接访问内核内存空间的。因此通过Socket接口我们Write数据到底层的过程中,就要涉及一次数据的拷贝,也就是把数据从进程内存中拷贝到TCP写缓冲,这就是一次IO操作
HTTP
HTTP服务端
使用net/http包创建一个HTTP服务。运行下面代码,访问127.0.0.1:8800会被重定向到百度
package main
import "net/http"
func main() {
//创建路由器
mux := http.NewServeMux()
//在路由器上挂载处理器(请求命中路由后,则执行第二个参数指定的功能)
mux.Handle("/", xxx)//参数2:为Handler接口类型(即实现ServeHTTP方法)。例子在`处理器Handler`部分
mux.HandleFunc("/hi", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "<h1>你好</h1>") //向response中写入,文本
})
//创建服务对象(Addr指定服务运行端口,Handler字段指定挂载的`处理器`)
server := &http.Server{
Addr: ":8800",
Handler: mux,
}
//服务对象,监听端口接收连接
if err := server.ListenAndServe(); err != nil {
panic(err)
}
}概念讲解
服务器server
指定服务器的基础配置,其中最重要的是挂载路由器,来处理请求。该字段为nil,表示采用包变量默认处理器DefaultServeMux
创建服务器有两种方式:
ListenAndServe快捷创建服务器
go//参数1:监听端口 //参数2:处理器mux。如果为nil,则使用默认处理器DefaultServeMux http.ListenAndServe(":8800", nil)源码,启动Server仅配置了Addr、Handler两个字段(指定处理器mux的字段)
gofunc ListenAndServe(addr string, handler Handler) error { server := &Server{Addr: addr, Handler: handler} return server.ListenAndServe() }手动配置Server,可以指定更多配置字段
gocustomServe := &http.Server{ Addr: ":8000", Handler: nil,//参数为nil,表示采用包变量DefaultServeMux作为处理器 ReadTimeout: 10 * time.Second, WriteTimeout: 10 * time.Second, MaxHeaderBytes: 1 << 20, } err := customServe.ListenAndServe() if err != nil { fmt.Printf("监听出错:%v", err) }
路由器(也叫多路复用器)mux
当请求过来时,在处理器中查找请求对应的路由,并执行该路由对应的处理器
有两中方式创建:
默认路由器DefaultServeMux
仅需要创建服务器时,不指定路由器,就会默认使用DefaultServeMux
gohttp.ListenAndServe(":8800", nil)使用DefaultServeMux最大的好处,就是net/http包中为默认处理器提供了HandleFunc方法,来简化注册处理器的流程
gopackage main import ( "fmt" "net/http" ) func main() { //Handle、HandleFunc会向默认路由器DefaultServeMux上注册处理器 http.Handle('/',http.RedirectHandler("http://www.baidu.com", 307)) http.HandleFunc("/hi", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "<h1>你好</h1>") //向response中写入,文本 }) err := http.ListenAndServe(":8800", nil) if err != nil { panic(err) } }Handle源码:
go//DefaultServeMux.Handle是想默认路由器,注册handler func Handle(pattern string, handler Handler) { DefaultServeMux.Handle(pattern, handler) } //Handler是个接口类型,其实现ServeHTTP方法 func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) { f(w, r) }源码:
gofunc HandleFunc(pattern string, handler func(ResponseWriter, *Request)) { DefaultServeMux.HandleFunc(pattern, handler) }两者的区别就是:handler接口类型的实现,HandleFunc第二个参数直接就实现了ServeHTTP方法
mux使用NewServeMux创建
go例子中注册了 : '/'对应的处理函数是重定向到百度 当请求127.0.0.1:8800时,查找并命中路由'/'
处理器Handler
函数Handle、HandleFunc可以在路由器上注册不同路由对应的处理器,即<路由,处理器Handler>
当命中路由时,路由器会执行对应的处理器的ServeHTTP方法
Handle例子:
gopackage main import ( "net/http" ) //---------我们可以从customerHandler函数传入一些参数,存入customer实例中,在ServeHTTP中使用----- type customer struct { } func (c *customer) ServeHTTP(w http.ResponseWriter, r *http.Request) { w.Write([]byte("你好")) } func customerHandler() http.Handler { return &customer{} } //--------- func main() { mux := http.NewServeMux() //在路由器上挂载处理器(请求命中路由后,则执行第二个参数指定的功能) mux.Handle("/", customerHandler()) //参数2:为Handler接口类型(实现ServeHTTP方法) server := &http.Server{ Addr: ":8800", Handler: mux, } if err := server.ListenAndServe(); err != nil { panic(err) } }上面代码中Handle函数、Handler类型的源码
gofunc (mux *ServeMux) Handle(pattern string, handler Handler) //参数1:路由 //参数2:处理器。是一个接口类型,参数需要实现ServeHTTP方法 type Handler interface { ServeHTTP(ResponseWriter, *Request) }HandleFunc例子:
gomux.HandleFunc("/hi", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "<h1>你好</h1>") //向response中写入,文本 })补充:路由器如何调用处理器?
路由器的结构体定义,其中muxEntry存储着所有注册在路由器上的处理器
gotype ServeMux struct { mu sync.RWMutex//读写互斥锁,并发请求需锁机制 m map[string]muxEntry//路由规则,一个路由表达式对应一个复用器实体 es []muxEntry // slice of entries sorted from longest to shortest. hosts bool // 是否在任意路由规则中携带主机信息 } //pattern是路由,h是路由对应的处理器 type muxEntry struct { h Handler pattern string }路由器也实现了Handler接口的ServeHTTP方法。处理器实现Handler接口,是用于处理路由请求
而路由器实现Handler接口,用于匹配路由。下面是路由器的源码
gofunc (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) { //当路由器接收到请求后若请求的URI为`*`则会关闭连接 if r.RequestURI == "*" { if r.ProtoAtLeast(1, 1) { w.Header().Set("Connection", "close") } w.WriteHeader(StatusBadRequest) return } //如果不是`*`,则`Handler()`来获取对应路由的处理器 h, _ := mux.Handler(r) //指定处理的ServeHTTP来处理请求 h.ServeHTTP(w, r) }
HTTP客户端
这里简单的实现一个客户端,发起Get请求。(后面会详细介绍Get、Post、Put、Delete)
package main
import (
"fmt"
"io/ioutil"
"net"
"net/http"
"time"
)
func main() {
//1、创建连接池
transport := &http.Transport{
DialContext: (&net.Dialer{
Timeout: 30 * time.Second, //连接超时时间
KeepAlive: 30 * time.Second, //长连接超时时间
}).DialContext,
MaxIdleConns: 100, //最大空闲连接
IdleConnTimeout: 0, //空闲连接超时时间
TLSHandshakeTimeout: 0, //tls握手超时间
ExpectContinueTimeout: 0, //100-continue状态超时时间
}
//2、创建客户端
client := &http.Client{
Transport: transport, //如果为nil,采用默认连接池DefaultTransport
Timeout: 30 * time.Second, //客户端请求的超时时间
}
//3、客户端发起 Get 请求
resp, err := client.Get("http://httpbin.org/get")
if err != nil {
fmt.Printf("请求失败, err:%v\n", err)
return
}
//关闭response.Body响应
defer resp.Body.Close()
//读取响应体,可以使用多种方式读取,这里使用的是ioutil方式,b是返回的内容
b, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Printf("get resp failed, err:%v\n", err)
return
}
fmt.Println(string(b))
}不使用Http.Get,也使用http.NewRequest创建请求器,Client调用Do方法,参数传入请求器
package main
import (
"bufio"
"fmt"
"io"
"net/http"
"net/url"
)
func readBody(response *http.Response) []byte {
reader := bufio.NewReader(response.Body)
var res []byte
for {
temp := make([]byte, 100)
_, err := reader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
return res
}
func main() {
proxyUrl, _ := url.Parse("http://10.168.124.17:8080/charge-attract-customer-platform/")
t := &http.Transport{
Proxy: http.ProxyURL(proxyUrl),
}
client := &http.Client{
Transport: t,
}
request, err := http.NewRequest(http.MethodGet, "http://www.baidu.com", nil)
if err != nil {
fmt.Printf("err-->%v", err)
return
}
response, err := client.Do(request)
if err != nil {
fmt.Printf("err-->%v", err)
return
}
res := readBody(response)
fmt.Println(string(res))
}请求流程

默认连接池、客户端
例如,http.Get就是采用默认的连接池、客户端
package myGet
import (
"fmt"
"io/ioutil"
"net/http"
"net/url"
)
func SendGetRequest(path string, m map[string]string) {
//
resp, err := http.Get(u.String())
if err != nil {
fmt.Printf("请求失败, err:%v\n", err)
return
}
//关闭response.Body响应
defer resp.Body.Close()
//读取响应体,可以使用多种方式读取,这里使用的是ioutil方式,b是返回的内容
b, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Printf("get resp failed, err:%v\n", err)
return
}
fmt.Println(string(b))
}HTTP客户端请求
http://httpbin.org/,这是一个用于测试HTTP请求的网站,请求的返回值就是请求时的相关信息,方便调试


这里的请求均使用请求这个接口作为例子
发起请求
package main
import (
"bufio"
"fmt"
"io"
"net/http"
)
//这里是对请求的返回体的Body进行读取的函数
func readBody(response *http.Response) []byte {
reader := bufio.NewReader(response.Body)
var res []byte
for {
temp := make([]byte, 100)
_, err := reader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
return res
}
func get() {
response, err := http.Get("http://httpbin.org/get")
if err != nil {
fmt.Printf("请求,err-->%v", err)
return
}
defer response.Body.Close()
//读取响应体的body
res := readBody(response)
fmt.Println(string(res))
}
func post() {
//第2个参数是contentType,第3个参数是body
response, err := http.Post("http://httpbin.org/post", "", nil)
if err != nil {
fmt.Printf("请求,err-->%v", err)
return
}
defer response.Body.Close()
//读取响应体的body
res := readBody(response)
fmt.Println(string(res))
}
func put() {
//Go语言未提供http.Put方法。所有需要稍微繁琐点,自己实现。查看http.Get、http.Post的源码发现其底层也是先创建一个request,然后使用DefaultClient的Do方法发起请求的
request, err := http.NewRequest(http.MethodPut, "http://httpbin.org/put", nil)//第三个参数是body,类型是io.Reader
if err != nil {
fmt.Printf("创建request请求,err-->%v", err)
return
}
response, err := http.DefaultClient.Do(request)
if err != nil {
fmt.Printf("请求,err-->%v", err)
return
}
defer response.Body.Close()
//读取响应体的body
res := readBody(response)
fmt.Println(string(res))
}
func delete() {
//Go语言未提供http.Delete方法
request, err := http.NewRequest(http.MethodDelete, "http://httpbin.org/delete", nil)//第三个参数是body,类型是io.Reader
if err != nil {
fmt.Printf("创建request请求,err-->%v", err)
return
}
response, err := http.DefaultClient.Do(request)
if err != nil {
fmt.Printf("请求,err-->%v", err)
return
}
defer response.Body.Close()
//读取响应体的body
res := readBody(response)
fmt.Println(string(res))
}
func main() {
get()
post()
put()
delete()
}处理响应体
获取响应体的长度(字节,返回值是int64)
response.ContentLength响应体头(Response.Header)
这个Header实际是是个map[string]string类型,可以通过Get方法获取响应体头字段
fmt.Println(response.Header.Get("Content-Type")) //application/json响应体状态码(Response.StatusCode)
fmt.Println(response.StatusCode) //200
fmt.Println(response.Status) //200 OK响应体(Response.Body)
前面的例子就是使用下面的函数读取Body的内容的
func readBody(response *http.Response) []byte {
reader := bufio.NewReader(response.Body)
var res []byte
for {
temp := make([]byte, 100)
_, err := reader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
return res
}响应体解码
如果响应体不是UTF-8的,就需要解码了。需要下载两个Go的非标准库
go get -u golang.org/x/net/html
go get -u golang.org/x/text代码
package main
import (
"bufio"
"fmt"
"golang.org/x/net/html/charset"
"golang.org/x/text/transform"
"io"
"net/http"
)
func main() {
response, err := http.Get("http://www.baidu.com")
if err != nil {
fmt.Printf("err-->%v", err)
return
}
defer response.Body.Close()
//通过Peek读取1024个字节(通过DetermineEncoding源码可知,其实他只读取1024个字节,这里我们直接取出1024个字节)
bufReader := bufio.NewReader(response.Body)
bytes, err := bufReader.Peek(1024)
//DetermineEncoding用于判断bytes中存储的文本,是否是响应头中指定的类型
e, _, _ := charset.DetermineEncoding(bytes, response.Header.Get("Content-Type"))
fmt.Printf("%v\n", e)//&{UTF-8}
//参数1传入之前的bufReader,参数2传入根据e获取的解码器。返回解码后的Reader
newBufReader := transform.NewReader(bufReader, e.NewDecoder())
//读取并打印
var res []byte
for {
temp := make([]byte, 100)
_, err := newBufReader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
fmt.Println(string(res))
}Get请求传参
方式一:直接在参数里拼接
response, err := http.Get("http://httpbin.org/get?name=hedaodao&age=18")方式二:不直接使用http提供的Get、Post方法。而是使用创建request,对request进行处理添加参数,最后使用DefaultClient的Do方法发起请求
这里,还提到了设置请求头字段的方式
package main
import (
"fmt"
"net/http"
"net/url"
)
//这里是对请求的返回体的Body进行读取的函数
func readBody(response *http.Response) []byte {
reader := bufio.NewReader(response.Body)
var res []byte
for {
temp := make([]byte, 100)
_, err := reader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
return res
}
func getWithParams() {
//创建请求
request, err := http.NewRequest(http.MethodGet, "http://httpbin.org/get", nil)
if err != nil {
fmt.Printf("创建请求失败,err-->%v", err)
return
}
defer response.Body.Close()
//创建参数对象
params := make(url.Values)
params.Add("name", "hedaodao")
params.Add("note", "你好,世界")
//将参数对象,添加到请求体上
request.URL.RawQuery = params.Encode() //Encode是对参数进行URL编码
//设置请求头
request.Header.Add("user-agent", "chrome")
//发起请求
response, err := http.DefaultClient.Do(request)
if err != nil {
fmt.Printf("发起请求失败,err-->%v", err)
return
}
//读取响应体的body
res := readBody(response)
fmt.Println(string(res))
}
func main() {
getWithParams()
}POST请求传参
前面已经讲过POST请求了,但是例子中的POST请求未传递参数。
http.POST(接口地址,请求的Content-Type,发送的数据类型是io.Reader)这里详细讲解下,POST传参的几种格式
x-www-from-urlencoded
可以传递多条键值对数据,数据值只能是字符串。所以,不能上传文件。仍然是使用
url.Valuesgopackage main import ( "bufio" "fmt" "io" "net/http" "net/url" "strings" ) func readBody(response *http.Response) []byte { reader := bufio.NewReader(response.Body) var res []byte for { temp := make([]byte, 100) _, err := reader.Read(temp) if err == io.EOF { break } res = append(res, temp...) } return res } func postForm() { params := make(url.Values) params.Add("name", "hedaodao") params.Add("age", "18") response, err := http.Post("http://httpbin.org/post", "application/x-www-form-urlencoded", strings.NewReader(params.Encode())) if err != nil { fmt.Printf("请求失败,err-->%v", err) return } defer response.Body.Close() res := readBody(response) fmt.Println(string(res)) } func main() { postForm() }raw
传递文本数据,可以发送任意格式的文本,对应不同的Content-Type值
text`text ` content-type=text/plain `js` application/javascript `css` text/css `json` application/json `html` text/html `xml` text/xml常用其实只有JSON这一种格式,所以这里的例子也是使用JSON
gopackage main import ( "bufio" "encoding/json" "fmt" "io" "net/http" "net/url" "strings" ) func readBody(response *http.Response) []byte { reader := bufio.NewReader(response.Body) var res []byte for { temp := make([]byte, 100) _, err := reader.Read(temp) if err == io.EOF { break } res = append(res, temp...) } return res } func postJSON() { stu := struct { Name string Age int }{ Name: "hedaodao", Age: 18, } bytes, err := json.Marshal(stu) if err != nil { fmt.Printf("序列化错误,err-->%v", err) return } response, err := http.Post("http://httpbin.org/post", "application/json", strings.NewReader(string(bytes))) defer response.Body.Close() res := readBody(response) fmt.Println(string(res)) } func main() { postJSON() }运行结果
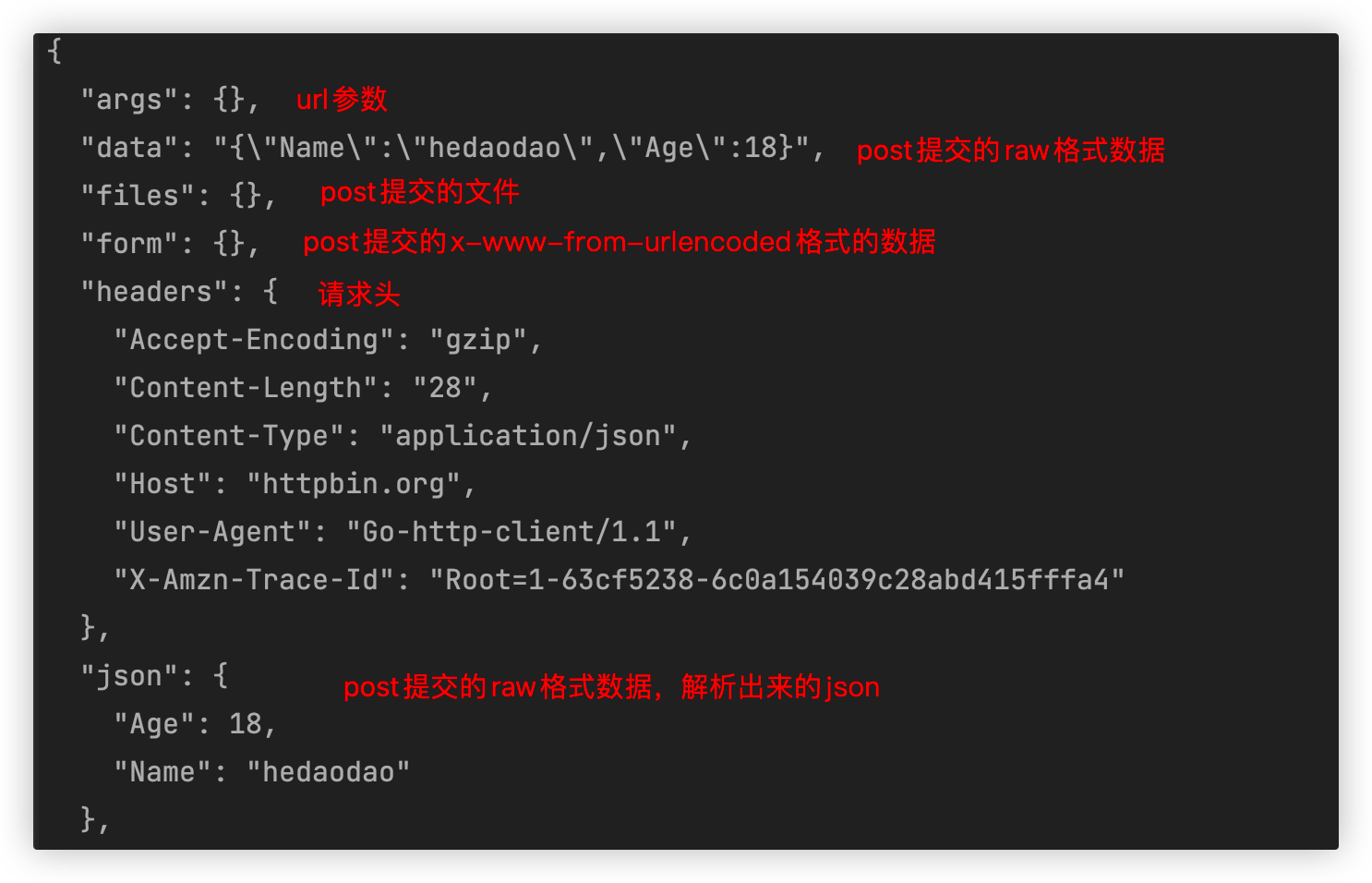
form-data
form-data可以传递多条键值对数据,数据值可以是字符串/文件,所以form-data是可以上传多个文件的
gofunc postFormData() { //1、构造一个缓冲区(所有的信息都是写入这里面) body := &bytes.Buffer{} //body实现了io.Reader、io.Writer writer := multipart.NewWriter(body) //提交的FormData是key-value形式的。value可以是字符串也可以是文件 //2、写入数据:value为字符串。key为word,value为123 writer.WriteField("word", "123") //3、写入数据:value为文件。key为uploadFile1,value为要上传的文件名 uploadWriter, err := writer.CreateFormFile("uploadFile1", "avatar") //uploadWriter实现了io.Writer if err != nil { fmt.Printf("创建uploadWriter失败,err-->%v", err) return } file, err := os.Open("../download/avatar.png") if err != nil { fmt.Printf("打开文件失败,err-->%v", err) return } io.Copy(uploadWriter, file) //相当于把打开的文件,写入了uploadWriter //4、写完数据,一定要记得关闭writer。否则无法发送数据 writer.Close() //fmt.Printf("%v\n", body.String()) //bytes.Buffer需要使用String方法才能转换为string类型 //5、发起请求 //fmt.Println(writer.FormDataContentType()) writer.FormDataContentType()是FormData的类型 response, err := http.Post("http://httpbin.org/post", writer.FormDataContentType(), body) if err != nil { fmt.Printf("post请求失败,err-->%v", err) return } defer func() { response.Body.Close() file.Close() }() res := readBody(response) fmt.Println(string(res)) }
HTTP客户端下载
response.Body实现了io.Reader,file实现了io.Writer
其本质就是,使用Copy方法,把响应体的内容复制到文件中
package main
import (
"fmt"
"io"
"net/http"
"os"
)
func download(url, fileName string) {
response, err := http.Get(url)
if err != nil {
fmt.Printf("请求失败,err-->%v", err)
return
}
file, err := os.Create(fileName)
if err != nil {
fmt.Printf("创建文件失败,err-->%v", err)
return
}
defer func(){
response.Body.Close()
file.Close()
}()
io.Copy(file, response.Body)
}
func main() {
download("https://heyingjiee.github.io/logo.png", "avatar.png")
}显示进度的下载
这个例子是我第一次定义结构体,然后实现io.Reader接口(实现结构体的Read方法)
package main
import (
"fmt"
"io"
"net/http"
"os"
)
//定义自己的结构体,然后实现io.Reader接口
type Reader struct {
io.Reader
totalBytes int64
curBytes int64
}
func (r *Reader) Read(p []byte) (n int, err error) {
n, err = r.Reader.Read(p)
if err != nil {
return
}
r.curBytes += int64(n)
// %%输出效果是:%
// \r是打印后,下次打印不换行,而是从头开始
fmt.Printf("\r下载进度:%v%%", r.curBytes*100/r.totalBytes)
return
}
func downloadWiteProgress(url, fileName string) {
response, err := http.Get(url)
if err != nil {
fmt.Printf("请求失败,err-->%v", err)
return
}
file, err := os.Create(fileName)
if err != nil {
fmt.Printf("创建文件失败,err-->%v", err)
return
}
customReader := &Reader{
Reader: response.Body,
totalBytes: response.ContentLength,
}
defer func() {
response.Body.Close()
file.Close()
}()
//这里的Copy会一值调用Read方法
io.Copy(file, customReader)
}
func main() {
downloadWiteProgress("https://heyingjiee.github.io/logo.png", "avatar.png")
}HTTP客户端重定向
这里的内容涉及到自定义服务http.Client,前面最多也就是用到了默认的服务http.DefaultClient。他们都有Do方法,用于发起请求
限制重定向次数
package main
import (
"bufio"
"errors"
"fmt"
"io"
"net/http"
)
func readBody(response *http.Response) []byte {
reader := bufio.NewReader(response.Body)
var res []byte
for {
temp := make([]byte, 100)
_, err := reader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
return res
}
func redirectLimitTime() {
client := &http.Client{
CheckRedirect: func(req *http.Request, via []*http.Request) error {
//Client.Do发起请求如果发生重定向就会触发这个函数
if len(via) > 10 {
return errors.New("重定向次数过多")
}
return nil
},
}
request, err := http.NewRequest(http.MethodGet, "http://httpbin.org/redirect/20", nil)
if err != nil {
fmt.Printf("构建请求失败,err-->%v", err)
return
}
response, err := client.Do(request)
if err != nil {
fmt.Printf("发起请求失败,err-->%v", err) //err-->Get "/relative-redirect/9": 重定向次数过多
return
}
fmt.Println(string(readBody(response)))
}
func main() {
redirectLimitTime()
}阻止重定向
func redirectForbidden() {
client := &http.Client{
CheckRedirect: func(req *http.Request, via []*http.Request) error {
return http.ErrUseLastResponse
},
}
request, err := http.NewRequest(http.MethodGet, "http://httpbin.org/cookies/set?name=hedaodao", nil)
if err != nil {
fmt.Printf("构建请求失败,err-->%v", err)
return
}
response, err := client.Do(request)
if err != nil {
fmt.Printf("发起请求失败,err-->%v", err)
return
}
fmt.Println(response.Request.URL) //http://httpbin.org/cookies/set?name=hedaodao
}
//访问http://httpbin.org/cookies/set?name=hedaodao,会自动重定向到http://httpbin.org/cookies。这里就阻止了重定向HTTP客户端超时处理
https://colobu.com/2016/07/01/the-complete-guide-to-golang-net-http-timeouts/
package main
import (
"bufio"
"context"
"fmt"
"io"
"net"
"net/http"
"time"
)
func readBody(response *http.Response) []byte {
reader := bufio.NewReader(response.Body)
var res []byte
for {
temp := make([]byte, 100)
_, err := reader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
return res
}
func main() {
client := &http.Client{
Timeout: 10 * time.Second,
//Transport字段可以指定超时、代理等功能
Transport: &http.Transport{
//创建链接的超时时间
DialContext: func(ctx context.Context, network, addr string) (net.Conn, error) {
return net.DialTimeout(network, addr, 2*time.Second)
},
//读取响应头的时间
ResponseHeaderTimeout: 5 * time.Second,
//TLS的握手时间
TLSHandshakeTimeout: 2 * time.Second,
//空闲链接的超时时间
IdleConnTimeout: 60 * time.Second,
},
}
request, err := http.NewRequest(http.MethodGet, "http://httpbin.org/delay/8", nil)
if err != nil {
fmt.Printf("建立请求失败,err-->%v", err)
return
}
response, err := client.Do(request)
if err != nil {
fmt.Printf("发起请求失败,err-->%v", err)
return
}
defer response.Body.Close()
res := readBody(response)
fmt.Println(string(res))
}HTTP客户端请求代理
package main
import (
"bufio"
"fmt"
"io"
"net/http"
"net/url"
)
func readBody(response *http.Response) []byte {
reader := bufio.NewReader(response.Body)
var res []byte
for {
temp := make([]byte, 100)
_, err := reader.Read(temp)
if err == io.EOF {
break
}
res = append(res, temp...)
}
return res
}
func main() {
//代理的地址
proxyUrl, _ := url.Parse("http://192.168.0.102:8080/merge-pay/")
t := &http.Transport{
Proxy: http.ProxyURL(proxyUrl),
}
client := &http.Client{
Transport: t,
}
//请求百度,会被代理到访问本地的一个项目http://192.168.0.102:8080/merge-pay/
request, err := http.NewRequest(http.MethodGet, "http://www.baidu.com", nil)
if err != nil {
fmt.Printf("err-->%v", err)
return
}
response, err := client.Do(request)
if err != nil {
fmt.Printf("err-->%v", err)
return
}
res := readBody(response)
fmt.Println(string(res))
}TCP
服务端
//server.go
package main
import (
"bufio"
"fmt"
"net"
"sync"
)
func process(conn net.Conn) {
defer conn.Close()
for {
reader := bufio.NewReader(conn) //接收连接的内容,也可以不用bufio,而是直接使用conn.Read([]byte)
var buf [1000]byte
n, err := reader.Read(buf[:])
if err != nil {
fmt.Printf("读取失败%v\n", err)
continue
}
fmt.Printf("接收到:%s\n", string(buf[:n]))
conn.Write([]byte("服务端已收到")) //写入连接内容
}
wg.Done()
}
var wg sync.WaitGroup
func main() {
// 1. 监听端口
listener, err := net.Listen("tcp", "127.0.0.1:9090")
if err != nil {
fmt.Printf("监听失败,%v\n", err)
return
}
defer listener.Close()
// 2. 循环监听建立的连接
for {
conn, err := listener.Accept()
if err != nil {
fmt.Printf("监听连接失败%v\n", err)
continue
}
// 3. 处理连接
wg.Add(1)
go process(conn)
}
wg.Wait()
}客户端
//client
package main
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:9090")
defer conn.Close()//必须关闭
if err != nil {
fmt.Printf("连接服务器失败%v\n", err)
return
}
input := bufio.NewReader(os.Stdin)
for {
str, err := input.ReadString('\n')
if err != nil {
fmt.Println("读取输入有误")
return
}
dealStr := strings.Trim(str, "\r\n") //去除输入中的\r\n
if strings.ToLower(dealStr) == "q" { //是q,则退出
return
}
//发送数据
n, err := conn.Write([]byte(dealStr))
if err != nil {
fmt.Printf("发送失败:%v\n", err)
return
}
//接收数据
buf := [1000]byte{}
n, err = conn.Read(buf[:])
if err != nil {
fmt.Printf("接收失败%v\n", err)
return
}
fmt.Println(string(buf[:n]))
}
}UDP
与TCP不同,UDP不必使用Accept接收到TCP连接,UDP可以直接从Listener读取信息
服务端
package main
import (
"fmt"
"net"
)
func main() {
// 1. 监听端口
udpConn, err := net.ListenUDP("udp", &net.UDPAddr{ //server端监听端口信息
IP: net.IPv4(127, 0, 0, 1),
Port: 9090,
})
if err != nil {
fmt.Printf("监听失败,%v\n", err)
return
}
for {
var data [1024]byte //数组
n, addr, err := udpConn.ReadFromUDP(data[:]) //参数是slice,addr是client端地址
if err != nil {
fmt.Printf("读取失败:%v\n", err)
continue
}
fmt.Printf("接收到:%v---%v\n", string(data[:n]), addr)
_, err = udpConn.WriteToUDP([]byte("服务端收到"), addr)
if err != nil {
fmt.Printf("发送失败:%v\n", err)
continue
}
}
}客户端
package main
import (
"bufio"
"fmt"
"net"
"os"
)
func main() {
remoteAddr := net.UDPAddr{
IP: net.IPv4(127, 0, 0, 1),
Port: 9090,
}
udpConn, err := net.DialUDP("udp", nil, &remoteAddr) //第二个参数是本地地址(如果传入nil就默认本机地址),第三个参数是远程地址
defer udpConn.Close()
if err != nil {
fmt.Println("连接服务端失败,err:", err)
return
}
for {
inputStr := bufio.NewReader(os.Stdin)
var buf [1000]byte
n, err := inputStr.Read(buf[:])
if err != nil {
fmt.Printf("读取失败:%v", err)
continue
}
_, err = udpConn.Write(buf[:n]) //发送数据 ,这里不能使用WriteToUDP
if err != nil {
fmt.Printf("发送失败:%v", err)
continue
}
n, _, err = udpConn.ReadFromUDP(buf[:]) //读数据
if err != nil {
fmt.Printf("接收数据失败:%v", err)
continue
}
fmt.Printf("接收到:%v\n", string(buf[:n]))
}
}网络代理
学习项目地址:https://github.com/solozyx/gateway_demo-1
转发:路由器对包的转发
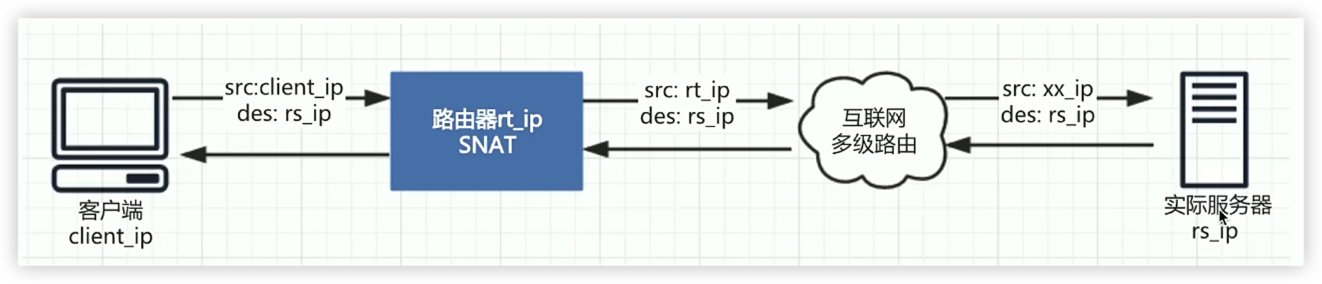
代理:客户端连接代理服务器,代理服务器和服务端通信
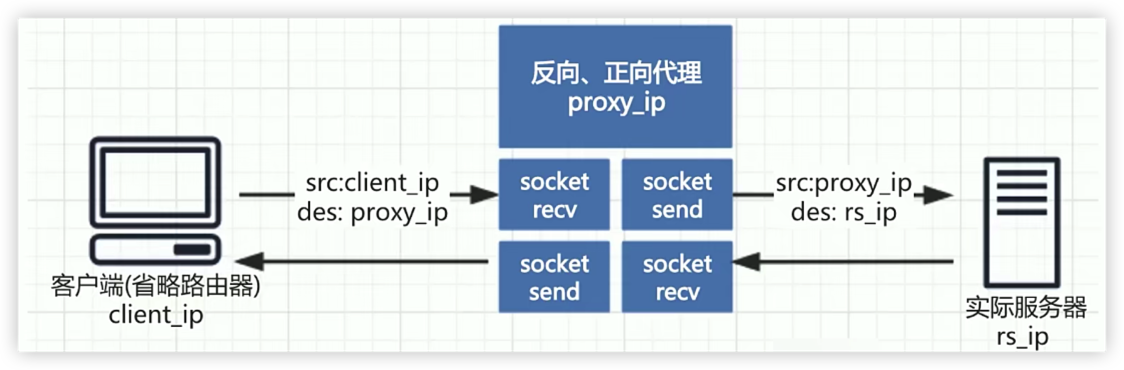
代理又分为:正向、反向代理
正向代理
例如,连接VPN服务器上网
客户端正向代理例子:
package main
import (
"fmt"
"io"
"net"
"net/http"
"strings"
)
type Pxy struct{}
func (p *Pxy) ServeHTTP(rw http.ResponseWriter, req *http.Request) {
fmt.Printf("Received request %s %s %s\n", req.Method, req.Host, req.RemoteAddr)
transport := http.DefaultTransport
// step 1,浅拷贝对象,然后就再新增属性数据
outReq := new(http.Request)
*outReq = *req
if clientIP, _, err := net.SplitHostPort(req.RemoteAddr); err == nil {
if prior, ok := outReq.Header["X-Forwarded-For"]; ok {
clientIP = strings.Join(prior, ", ") + ", " + clientIP
}
outReq.Header.Set("X-Forwarded-For", clientIP)
}
// step 2, 请求下游
res, err := transport.RoundTrip(outReq)
if err != nil {
rw.WriteHeader(http.StatusBadGateway)
return
}
// step 3, 把下游请求内容返回给上游
for key, value := range res.Header {
for _, v := range value {
rw.Header().Add(key, v)
}
}
rw.WriteHeader(res.StatusCode)
io.Copy(rw, res.Body)
res.Body.Close()
}
func main() {
fmt.Println("Serve on :8080")
http.Handle("/", &Pxy{})
http.ListenAndServe("0.0.0.0:8080", nil)
}反向代理
例如,服务器负载均衡、缓存、安全校验
实现一个简单的反向代理
反向代理的思路:
- 接收客户端请求(对请求做一些处理)
- 通过一定的负载均衡算法,获取下游服务器地址
- 将收到的请求发送到下游服务器
- 接收下游服务器返回的响应(对响应做一些处理),返回给客户端

启动两个服务器在 8000、8001端口
package main
import (
"fmt"
"io"
"log"
"net/http"
"os"
"os/signal"
"syscall"
"time"
)
type RealServe struct {
Addr string
}
func (s *RealServe) Run() {
mux := http.NewServeMux()
mux.HandleFunc("/", s.HelloHandler)
server := &http.Server{
Addr: s.Addr,
WriteTimeout: time.Second * 3,
Handler: mux,
}
go func() {
log.Fatal(server.ListenAndServe())
}()
}
func (s *RealServe) HelloHandler(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, fmt.Sprintf("addr:%s , path:%s \n", s.Addr, r.URL.Path))
io.WriteString(w, fmt.Sprintf("RemoteAddr:%s , X-Forwarded-For:%s , X-Real-Ip:%s\n", r.RemoteAddr, r.Header.Get("X-Forwarded-For"), r.Header.Get("X-Real-Ip")))
io.WriteString(w, fmt.Sprintf("%v\n", r.Header))
}
func main() {
s1 := &RealServe{
Addr: "127.0.0.1:8000",
}
s1.Run()
s2 := &RealServe{
Addr: "127.0.0.1:8001",
}
s2.Run()
quit := make(chan os.Signal)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM)
<-quit
}启动代理服务器,在8002端口。使用浏览器访问 http://127.0.0.1:8002/,页面显示的是 addr:127.0.0.1:8000
package main
import (
"bufio"
"net/http"
"net/url"
)
var proxy_addr = "http://127.0.0.1:8000"
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
//1、 解析目标机器的地址,并更改实际请求体的协议和主机为目标
proxy, _ := url.Parse(proxy_addr)
r.URL.Scheme = proxy.Scheme
r.URL.Host = proxy.Host
//2、请求代理的目标机器
transport := http.DefaultTransport
response, _ := transport.RoundTrip(r)
//3、将目标机器的返回值,返回给客户端
for k, vv := range response.Header { //vv都是切片类型的
for _, v := range vv {
w.Header().Add(k, v)
}
}
defer response.Body.Close()
bufio.NewReader(response.Body).WriteTo(w)
})
http.ListenAndServe(":8002", nil)
}反向代理的增强功能
使用Go官方提供的ReverseProxy,并扩展以下功能
- 错误回调和错误日志处理
- 更改代理返回内容
- 自定义负载均衡策略
- URL重写
- 限流、熔断、降级
- 数据统计
- 权限验证

使用Go自带的ReverseProxy实现
//浏览器访问127.0.0.1:8004/xxx,实际访问的是http://127.0.0.1:8000/base/xxx
package main
import (
"net/http"
"net/http/httputil"
"net/url"
)
//真实的目标地址
var proxyUrl = "http://127.0.0.1:8000/base"
func main() {
proxy, _ := url.Parse(proxyUrl)
reverseProxy := httputil.NewSingleHostReverseProxy(proxy)
http.ListenAndServe("127.0.0.1:8004", reverseProxy)
}补充下url.Parse函数,其返回值是URL实例(作用是:将string类型的url,转换为URL实例)
//参数: "http://127.0.0.1:8000/a?name=jack&desc=ceshi%3A%3A%3A#first"
type URL struct {
Scheme string // 协议, http
Opaque string // 如果url格式是 'scheme:opaque[?query][#fragment]',即协议后不是'://',就会被解析为opaque字段
User *Userinfo // url中的用户信息
Host string // 主机地址, 127.0.0.1:8000
Path string // 路径(最开始是斜杠), /a
RawPath string // <不要使用这个字段,使用Path>
ForceQuery bool // <不要使用这个字段>
RawQuery string // 被编码的参数(不带?号), name=jack&desc=ceshi%3A%3A%3A
Fragment string // 锚点(不带#号), first
RawFragment string // <不要使用这个字段,使用Fragment>
}
// 其实url中也可以添加用户信息,在host之前添加 username:password@
// 例如 "http://hedaodao:password@127.0.0.1:8000"Go文档ReverseProxy

ReverseProxy的类型定义
type ReverseProxy struct {
// Director must be a function which modifies
// the request into a new request to be sent
// using Transport. Its response is then copied
// back to the original client unmodified.
// Director must not access the provided Request
// after returning.
//控制器,函数内部可以对请求进行修改
Director func(*http.Request)
//请求连接池。如果为nil,则使用http.DefaultTransport
Transport http.RoundTripper
// FlushInterval specifies the flush interval
// to flush to the client while copying the
// response body.
// If zero, no periodic flushing is done.
// A negative value means to flush immediately
// after each write to the client.
// The FlushInterval is ignored when ReverseProxy
// recognizes a response as a streaming response, or
// if its ContentLength is -1; for such responses, writes
// are flushed to the client immediately.
// 刷新间隔
FlushInterval time.Duration
// ErrorLog specifies an optional logger for errors
// that occur when attempting to proxy the request.
// If nil, logging is done via the log package's standard logger.
ErrorLog *log.Logger
// BufferPool optionally specifies a buffer pool to
// get byte slices for use by io.CopyBuffer when
// copying HTTP response bodies.
//错误记录器
BufferPool BufferPool
// ModifyResponse is an optional function that modifies the
// Response from the backend. It is called if the backend
// returns a response at all, with any HTTP status code.
// If the backend is unreachable, the optional ErrorHandler is
// called without any call to ModifyResponse.
//
// If ModifyResponse returns an error, ErrorHandler is called
// with its error value. If ErrorHandler is nil, its default
// implementation is used.
// 修改响应
ModifyResponse func(*http.Response) error
// ErrorHandler is an optional function that handles errors
// reaching the backend or errors from ModifyResponse.
//
// If nil, the default is to log the provided error and return
// a 502 Status Bad Gateway response.
// ModifyResponse函数返回错误时的错误回调。如果为nil,遇到错误时,返回502
ErrorHandler func(http.ResponseWriter, *http.Request, error)
}NewSingleHostReverseProxy函数源码:
func NewSingleHostReverseProxy(target *url.URL) *ReverseProxy {
targetQuery := target.RawQuery
//这里创建一个director
director := func(req *http.Request) {
//把目标服务器的协议、主机,赋值给req对象(req就是代理服务器接收到的客户端请求)
req.URL.Scheme = target.Scheme
req.URL.Host = target.Host
//如果 客户端请求127.0.0.1:8000/dir , 目标服务器target是127.0.0.1:8001/base,最后客户端实际访问的是127.0.0.1:8001/base/dir
req.URL.Path, req.URL.RawPath = joinURLPath(target, req.URL)
// 拼接url参数
if targetQuery == "" || req.URL.RawQuery == "" {
req.URL.RawQuery = targetQuery + req.URL.RawQuery
} else {
req.URL.RawQuery = targetQuery + "&" + req.URL.RawQuery
}
// 修改头的User-Agent
if _, ok := req.Header["User-Agent"]; !ok {
// explicitly disable User-Agent so it's not set to default value
req.Header.Set("User-Agent", "")
}
}
return &ReverseProxy{Director: director}
}加密相关基础知识
加密大致分为以下几种:
单项加密
即明文只能转化为密文,而密文不能解密为明文。例如:MD5、SHA
双向加密
对称加密
秘钥把明文加密为密文,同一个秘钥可解密密文。例如:AES
非对称加密
公钥加密的内容只能用私钥解密。。例如:RSA
MD5
MD5信息摘要算法,属于Hash算法的一种(类似一个单调函数,输入入参x,只返回唯一值y。且不同x,必然返回不同相同y)
MD5算法对输入任意长度的信息进行运算,输出128bit的数据
应用场景:文件一致性校验,下载文件后计算文件MD5值与线上文件MD5值是否一致,如果一致则文件完整
SHA
由美国国家安全局(NSA)所设计,并由美国国家标准与技术研究院(NIST)发布
SHA包含了一系列的具体算法(-后的数字表示生成的散列值为位数):
SHA-1
SHA-2包括:SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256。
SHA-3包括:SHA3-224、SHA3-256、SHA3-384、SHA3-512
目前,SHA256是最为常见的
AES
AES(Advanced Encryption Standard)是一种对称秘钥加密算法
它是一种区块加密算法,加密时会将原始数据按大小拆分成一个个区块进行加密,区块大小固定为 128 比特(即 16 字节)。AES 密钥长度可以是 128、192 或 256 比特(即 16、25 或 32 字节),密钥长度越长,安全性越高,而性能也就越低
加密结果不固定
填充、偏移量和模式是其加密过程中的三个重要概念
填充(Padding)
在AES中,块加密算法要求数据的长度必须是块大小的整数倍。如果明文长度不是块大小的整数倍,就填充为整数倍
填充方式包括:Pkcs7、Iso97971、Iso10126、AnsiX923、ZeroPadding、NoPadding
Pkcs7是最为常见的填充方式:它在数据末尾添加了字节,字节的值等于需要填充的字节数。例如,如果还需要填充3个字节,就添加3个字节的值为3的字节。
偏移量(Initialization Vector,IV)
IV是在使用块密码算法时引入的一个随机值,用于在相同的明文和密钥下生成不同的密文
模式(Mode of Operation)
AES本身是块密码算法,不同模式块加密的方式不同,常用的有下面几种:
ECB(Electronic Codebook)模式
将数据分成块,每个块单独加密。相同的明文块将生成相同的密文块,可能导致一些安全性问题,因此不推荐在实际应用中使用。无偏移量的概念
CBC(Cipher Block Chaining)模式
每个块的加密依赖于前一个块的密文,通过引入了偏移量(IV)以增加安全性
CTR(Counter)模式
使用计数器和密钥产生一个密钥流,然后将明文与密钥流异或得到密文。不需要填充,可以并行处理数据
GCM(Galois/Counter Mode)模式
在CTR模式基础上加入了认证,提供了加密和认证的功能,常用于保护通信的完整性和保密性
RSA
非对称加密
应用场景:Https请求就是非对称加密
Base64编码
注意:Base64编码并不是加密方式,其本身不是为了提供安全性,而仅仅是为了在文本环境中更方便地处理二进制数据
例如,AES加密后结果为二进制数据,但是二进制数据中包含不可见字符,在以文本的形式传输或存储环境中直接使用二进制可能会引发问题,而Base64编码可以将二进制数据转换为可见的ASCII字符集,便于在文本中安全地传输和存储。接口返回JSON格式的加密字段,一般都是使用Base64编码后的字符串
例如,前端经常使用image标签显示base64编码的图片
不同的文本环境中,能使用的字符会有一定的限制
标准Base64
使用字符集:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
填充字符:=在上面【标准Base64】中,可以看出来其中包括+和/,这两个刚好是URL中的特殊字符,直接将其用于URL中的参数会出现问题
所以出现了其他Base64变体,这些变体的区别是字符集或填充字符上的不同
URL安全Base64
使用字符集:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_
填充字符:=对标准的Base64编码做出了如下调整
"+" : 如果Base64编码中包含+,会被视为空格,与其真正含义不同。一般替换为换为"-"
"/" : /是URL中路径分隔符,如果Base64编码中包含/,会被当做路径。一般替换为换为"_"(下划线)Base64编码URL和文件名安全
使用字符集:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_
填充字符:省略(不填充)Base64编码文件URL安全
使用字符集:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_
填充字符:~进制相关基础知识
最为常用二进制与十进制对应关系(如何算?这个就涉及到初中知识了)
- 0001 对应 十进制1
- 0010 对应 十进制2
- 0100 对应 十进制4
- 1000 对应 十进制8
二进制转十进制
快速计算方法:
1011 对应的十进制是11
计算过程:
二进制 1000 + 0010 + 0001=1001
十进制 8 + 2+ 1=11
所以,看到二进制数从右向左,每4位作为一组(不足4位,在高位补0),对应到十进制的加法,最后将每组计算出来的十进制数相加
举个复杂的例子
101101 => 分组 0010 1101 =>(2)+(1+4+8)=15 ,最后结果是十进制的15二进制与十六进制
在Go中,以0x开头,后面跟的是具体的数字。例如0x12表示十六进制数12
十六进制位的范围 (0~9、A、B、C、D、E),超过E则高位进1
有一个规律,1+2+4+8=15刚好能表示一位十六进制,推理出:对应的4个二进制位也能表示一位十六进制数的
0x12A转二进制 计算过程:
12A => 每个十六进制位转为对应的4位二进制 0000 0001 0010 1010
100101010 转十六进制 计算过程:
100101010 => 分组 0001 0010 1010 => 每4位对应一个十六进制位 1 2 A代码测试(待补充)
学习资料
测试中涉及一些,我并不了解的知识,所以放在最后学习
项目中,以*_test.go命名的源代码文件都是测试文件,这些文件不会被go build编译到最终的可执行文件中
在*_test.go文件中有三种类型的函数:
| 类型 | 格式 | 示例 | 作用 |
|---|---|---|---|
| 单元测试函数 | 函数名前缀为Test(后接大写首字母) | TestSum | 测试程序的一些逻辑行为是否正确 |
| 基准测试函数 | 函数名前缀为Benchmark(后接大写首字母) | BenchmarkSum | 测试函数的性能 |
| 示例函数 | 函数名前缀为Example(后接大写首字母) | ExampleSum | 为文档提供示例文档 |
单元测试
函数名前缀为Test ,参数必须为testing包中的*testing.T
//a_test.go
func TestSum(t *testing.T){
}其中参数t用于报告测试失败和附加的日志信息。 testing.T的拥有的方法如下:
func (c *T) Cleanup(func())
func (c *T) Error(args ...interface{})
func (c *T) Errorf(format string, args ...interface{})
func (c *T) Fail()
func (c *T) FailNow()
func (c *T) Failed() bool
func (c *T) Fatal(args ...interface{})
func (c *T) Fatalf(format string, args ...interface{})
func (c *T) Helper()
func (c *T) Log(args ...interface{})
func (c *T) Logf(format string, args ...interface{})
func (c *T) Name() string
func (c *T) Skip(args ...interface{})
func (c *T) SkipNow()
func (c *T) Skipf(format string, args ...interface{})
func (c *T) Skipped() bool
func (c *T) TempDir() string运行单元测试
注意不指定run时,go test默认运行的是单元测试,而不会运行基准测试
go test -v -timeout=20m -run=Sum -count=1 -short a_test.go
# -v 打印详细测试信息
# -timeout 超时时间
# -count 函数运行次数
# -short 如果希望在跳过某些用例(比如,耗时的用例),详细会在下面讲解
# -run 参数是一个正则表达式,只有函数名匹配上的"单元测试函数"才会被执行测试
# -bench 与run一样参数是一个正则表达式,但是是指定执行哪些基准测试函数
#-benchmem 输出内存分配情况
#-benchtime 每个基准测试函数的运行时间详细讲解short
go test -shortfunc TestTimeConsuming(t *testing.T) {
if testing.Short() { //当使用-short命令,testing.Short()函数返回值为true
t.Skip("short模式下会跳过该测试用例")
}
}一个单元测试的例子
- 单测试用例
//split_test.go
package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
got := Split("a,b,c,d", ",")
want := []string{"a", "b", "c", "d"}
if !reflect.DeepEqual(got, want) { //因为slice不能比较直接,借助反射包中的方法比较
t.Errorf("want:%v,but got:%v", want, got)
}
}多单测试用例。提前将多个测试用例写入一个切片中,在一个测试函数中,通过循环切片中的多个用例,来执行多个测试
go//split_test.go package split import ( "reflect" "testing" ) func TestSplit(t *testing.T) { type test struct { input string sep string want []string } tests := map[string]test{ "example1": test{input: "a,b,c", sep: ",", want: []string{"a", "b", "c"}}, "example2": test{input: ",b,", sep: ",", want: []string{"", "b", ""}}, } for key, value := range tests { got := Split(value.input, value.sep) if !reflect.DeepEqual(got, value.want) { t.Errorf("name: %s fail,want:%v,got:%v", key, value.want, got) } } }子测试。Go1.7+中新增子测试,支持在一个测试函数中使用多个t.Run执行多组测试用例,每个t.Run执行一组用例
go//split_test.go package split import ( "reflect" "testing" ) //子测试, func TestSplit(t *testing.T) { t.Run("example1", func(t *testing.T) { got := Split("a,b,c,d", ",") want := []string{"a", "b", "c", "d"} if !reflect.DeepEqual(got, want) { t.Errorf("want:%v,but got:%v", want, got) } }) t.Run("example2", func(t *testing.T) { got := Split(",b,c,", ",") want := []string{"", "b", "c", ""} if !reflect.DeepEqual(got, want) { t.Errorf("want:%v,but got:%v", want, got) } }) }表格驱动测试+并行测试
这是一种思想,即提前将多个测试用例写入一个切片中,通过循环切片中的多个用例,通过t.Run执行每一组用例。
这样有哪些用例一目了然,其实就是第2、3点的结合
并行测试:t.Parallel,将当前测试用例标记为能够并行运行
go//split_test.go package split import ( "reflect" "testing" ) func TestSplit(t *testing.T) { type test struct { input string sep string want []string } tests := map[string]test{ "example1": test{input: "a,b,c", sep: ",", want: []string{"a", "b", "c"}}, "example2": test{input: ",b,", sep: ",", want: []string{"", "b", ""}}, } for key, value := range tests { t.Run(key,func(* testing.T){ t.Parallel() //将每个测试用例标记为能够彼此并行运行 got := Split(value.input, value.sep) if !reflect.DeepEqual(got, value.want) { t.Errorf("name: %s fail,want:%v,got:%v", key, value.want, got) } }) } }
生成表格测试文件的工具
gotests是一个生产测试文件的工具,是一个全局的工具文档地址
//编译并将gotests命令添加到环境变量
go install github.com/cweill/gotests/...
//生成单元测试文件。目录下如果事先存在这个文件就不再生成
gotests -all -w xxx.go默认生成的文件 xxx_test.go
package sum
import "testing"
func Test_sum(t *testing.T) {
type args struct {
a int
b int
}
tests := []struct {
name string
args args
want int
}{
// TODO: Add test cases.
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := sum(tt.args.a, tt.args.b); got != tt.want {
t.Errorf("sum() = %v, want %v", got, tt.want)
}
})
}
}测试覆盖率
测试覆盖率是指代码被测试用例覆盖的百分比,也就是在测试中至少被运行一次的代码占总代码的比例。在公司内部一般会要求测试覆盖率达到80%左右。
进入包含测试文件的目录,执行下面命令,输出测试覆盖率
go test -cover
执行下面命令,输出覆盖率相关的信息到一个文件
go test -coverprofile a.text //输出到a.text文件使用cover工具来处理生成的记录信息,并打开本地的浏览器窗口生成一个HTML报告。绿色的部分是被测试覆盖的代码,红色的是未覆盖的
go tool cover -html=a.text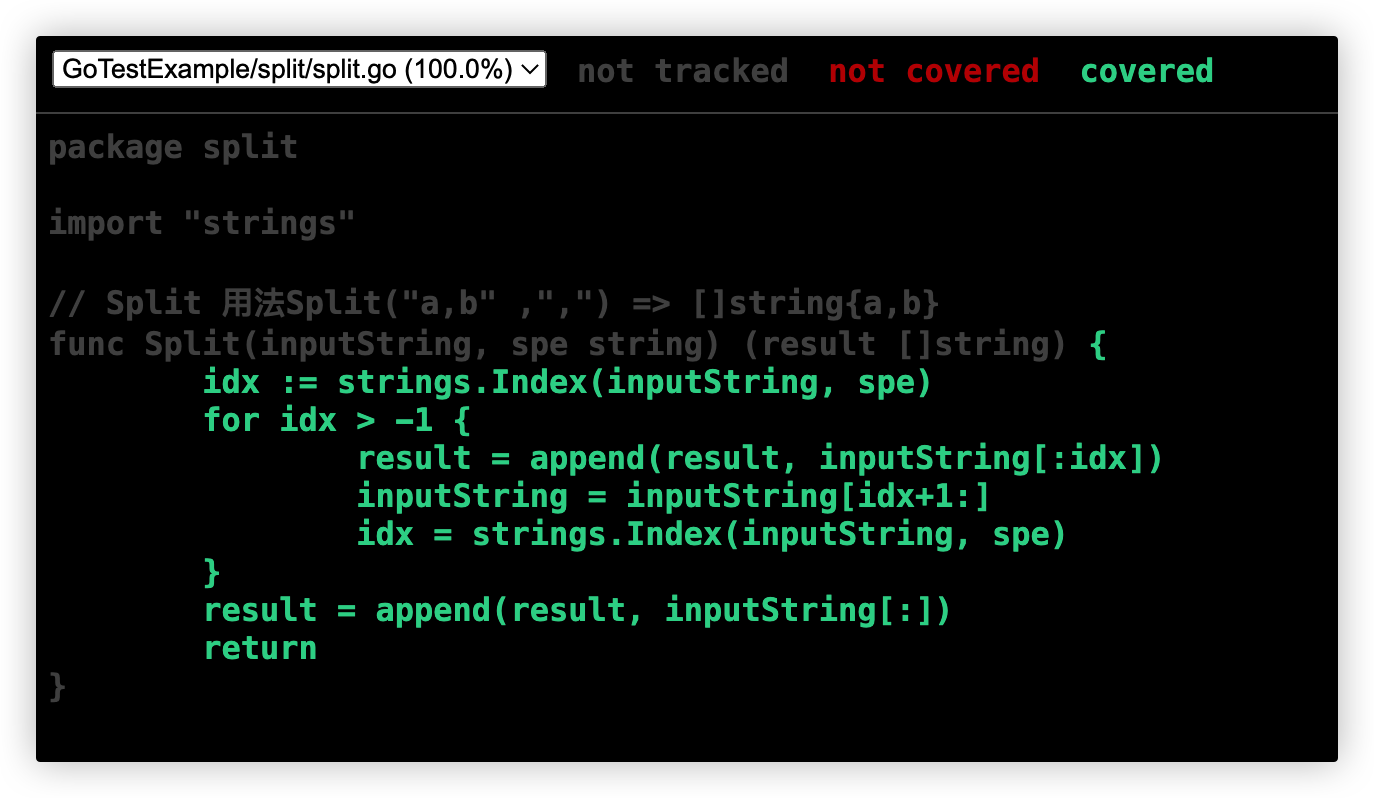
测试断言
我们在写单元测试的时候,通常需要使用断言来校验测试结果(比如,前面使用reflect.DeepEqual),但是Go语言官方没有提供断言
testify是一个社区非常流行的Go单元测试工具包,其中使用最多的功能就是它提供的断言工具——testify/assert或testify/require
testify/assert提供了非常多的断言函数,可以查看官方文档testify/require拥有testify/assert所有断言函数,它们的唯一区别就是——testify/require遇到失败的用例会立即终止本次测试。
go get github.com/stretchr/testify前面的写法
t.Run(tt.name, func(t *testing.T) { // 使用t.Run()执行子测试
got := Split(tt.input, tt.sep)
if !reflect.DeepEqual(got, tt.want) {
t.Errorf("expected:%#v, got:%#v", tt.want, got)
}
})使用testify工具后面的写法,使用assert.Equal函数,如果不相等会自动抛出错误
t.Run(tt.name, func(t *testing.T) { // 使用t.Run()执行子测试
got := Split(tt.input, tt.sep)
assert.Equal(t, got, tt.want) // 使用assert提供的断言函数
})也可以
func TestSomething(t *testing.T) {
assert := assert.New(t)
//断言相等
assert.Equal(123, 123, "they should be equal")
//断言不相等
assert.NotEqual(123, 456, "they should not be equal")
//断言为nil
assert.Nil(object)
//断言为非nil。非nil才能取取Value字段
if assert.NotNil(object) {
assert.Equal("Something", object.Value)
}
}基准测试
函数名前缀为Benchmark,参数为*testing.B类型的参数b
基准测试必须要执行b.N次,这样的测试才有对照性,b.N的值是系统根据实际情况去调整的,从而保证测试的稳定性
//a_test.go
func BenchmarkSum(b *testing.B){
}运行基准测试,必须指定-bench
指定-run=^$,即可不运行单元测试函数,否则会默认运行单元测试函数
go test -bench=StrCat -run=^$ -benchmem -benchtime=2s a_test.go
#-bench 指定运行哪个基准测试函数,支持正则表达式。StrCat表示包含StrCat这个词的基准测试函数
#-benchmem 输出内存分配情况
#-benchtime 每个函数运行时间
#-cpuprofile 输出CPU性能数据 到指定文件,例如:-cpuprofile=cpu.prof输出到cpu.prof文件
#-memprofile 输出内存性能数据 到指定文件案例:
//split.go
package split
import "strings"
// Split 用法Split("a,b" ,",") => []string{a,b}
func Split(inputString, spe string) (result []string) {
idx := strings.Index(inputString, spe)
for idx > -1 {
result = append(result, inputString[:idx])
inputString = inputString[idx+len(spe):]
idx = strings.Index(inputString, spe)
}
result = append(result, inputString[:])
return
}测试文件 split_test.go
func BenchmarkSplit(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = Split("a,b,c,d,e", ",")
}
}go test -bench=Split
go test -bench=Split -benchmem
性能分析pprof
介绍
pprof是Go程序性能分析工具,prof是profile(画像)的缩写
使用pprof可以分析下面9种数据

分析时一般常用4种:
CPU Profiling
CPU 分析,按照一定的频率采集所监听的应用程序 CPU(含寄存器)的使用情况,可确定应用程序在主动消耗 CPU 周期时花费时间的位置
Memory Profiling
内存分析,在应用程序进行堆分配时记录堆栈跟踪,用于监视当前和历史内存使用情况,以及检查内存泄漏
Block Profiling
阻塞分析,记录 goroutine 阻塞等待同步(包括定时器通道)的位置
Mutex Profiling
互斥锁分析,报告互斥锁的竞争情况
采集数据
分成两大类场景,对应使用不同的Go标准库
采集指定代码区域的运行数据进行分析,使用标准库runtime/pprof,也可以使用基准测试函数
比如,都某个函数的分析
对于Http Server类应用,采集其运行时的数据进行分析,使用标准库net/http/pprof
比如,一个Gin框架的Web服务器
下面分别具体介绍
注意:使用go tool pprof分析工具提示
Could not execute dot; may need to install graphviz.使用如下方法安装:mac安装graphviz的3种方法
采集指定区域运行数据
CPU分析
package main
import (
"GoTestExample/split"
"os"
"runtime/pprof"
)
func work() {
}
func main() {
cpuOut, _ := os.Create("./cpu.pprof")
//1、开始监控
pprof.StartCPUProfile(cpuOut)
//2、需要监控的代码
work()
//3、结束监控
pprof.StopCPUProfile()
cpuOut.Close()
}生成文件cpu.pprof,通过tool生成一个Web可视化界面
go tool pprof -http=:8080 cpu.pprof #-http是指定可视化web页面的启动地址,不指定启动IP地址,默认在127.0.0.1启动内存分析
memOut, _ := os.Create("./mem.pprof")
pprof.WriteHeapProfile(memOut)
memOut.Close()生成文件,可视化分析
go tool pprof -http=:8080 mem.pprof采集Web服务运行数据
CPU分析
go tool pprof -http=:8080 http://localhost:9090/debug/pprof/profile
# -http指定可视化Web页面启动地址,后面的http://localhost:9090是项目的运行地址内存分析
go tool pprof -http=:8080 http://localhost:9090/debug/pprof/heap性能数据分析
前面的例子中,都是通过下面的工具来实现可视化分析的
go tool pprof -http=:8080也可以使用下面的命令,在命令行进入交互模式
go tool pprof 文件交互模式下常用命令
topn // 例如top10,性能消耗前十名的数据
list //列出详细数据
func
peekfunc
web协程排查工具trace
如何生成trace文件
在代码中显式调用trace
gopackage main import ( "os" "runtime/trace" "strings" ) func work(){ } func main() { traceOut, _ := os.Create("./trace.pprof") trace.Start(traceOut) //开始trace defer trace.Stop() //结束trace work() //监控的对象 }通过web可视化页面,查看trace文件数据
shellgo tool trace -http=127.0.0.1:8080 trace文件位置
利用pprof生成trace文件

查看trace文件
gogo tool trace -http=127.0.0.1:8080 /path/to/trace_filego test时,加上-trace参数,指定输出的文件名
gogo test -trace=trace_file查看trace文件
shellgo tool trace -http=127.0.0.1:8080 trace文件位置
如何读Go源码
if语句不读,因为有if代表这句可能执行/不执行

有一种if除外,Go语言中if内部可以执行函数,只有后面的err才是进行判断的地方。这种还是要读
变量声明不要读

重点读必会执行的函数调用,记住几个快捷键
command+左键点击函数,跳转函数定义
command+光标悬浮在变量/函数上,显示其类型定义
option+command+向左/向右,上一个/下一个
如果函数是结构体实现的接口方法,如下:
则会进入接口定义的函数签名处。点击前面的图标
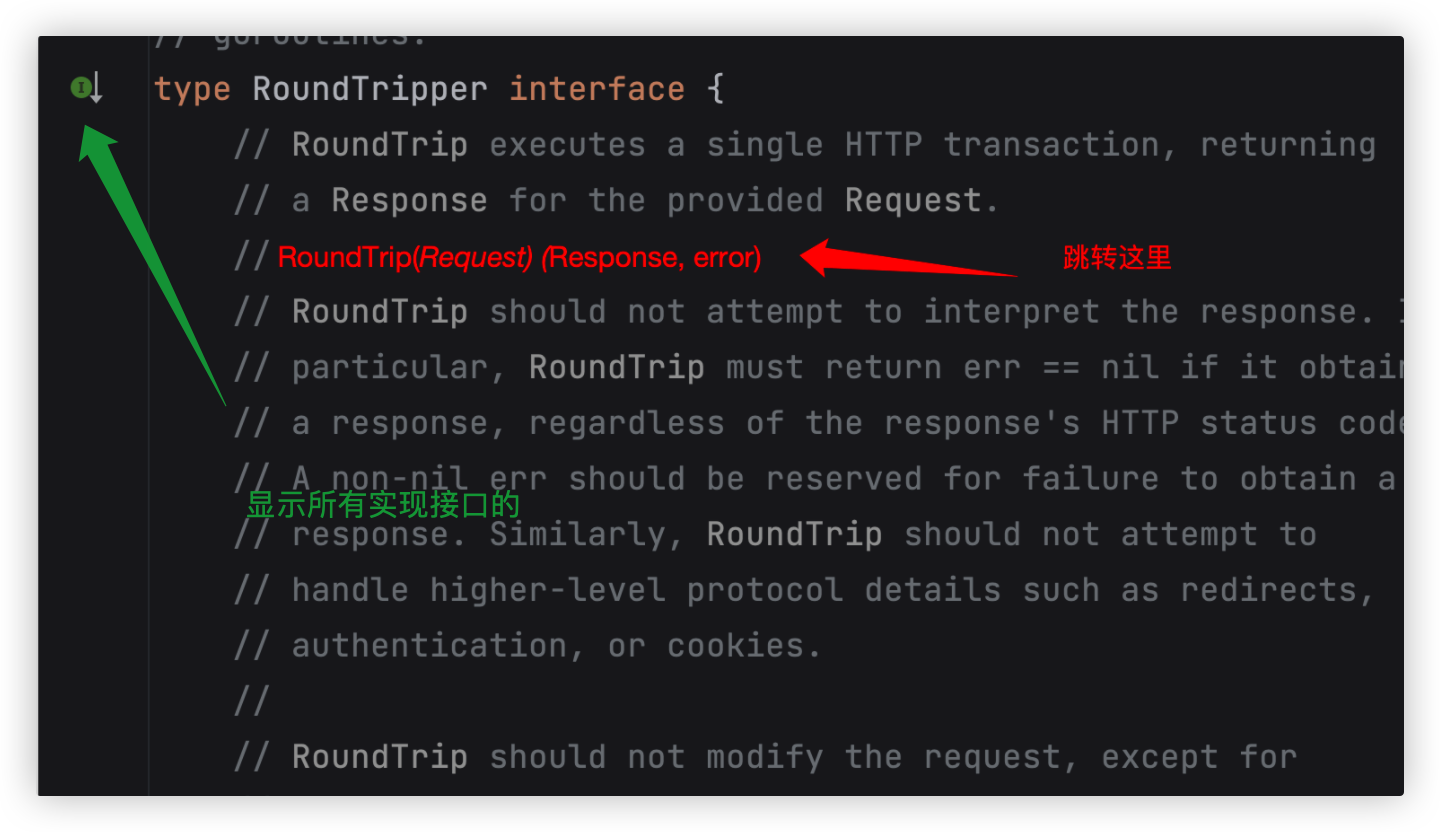
提示所有实现该接口的类型,我们要在其中找到实例rt是那个类型。这里rt是属于红框中的类型

如何找到属于哪个类型?这个比较难找,将鼠标放在rt变量上,显示其是接口类型RoundTripper

所以,我们必须一路向上层追踪变量实例化的地方,才能知道该变量的具体类型
积累
这部分主要记录下,平时看到的一些库或者文章里代码,学习下使用Go语言的经验
公共前缀
package main
import "fmt"
func min(a, b int) int {
if a <= b {
return a
}
return b
}
func longestCommonPrefix(a, b string) int {
//这里其实就是个for循环
i := 0
max := min(len(a), len(b))
for i < max && a[i] == b[i] {
i++
}
return i
}
func main() {
i := longestCommonPrefix("123789", "12456")
fmt.Printf("%v\n", i) //2
fmt.Printf("%v", str1[:i]) //12
}切片的方法
不仅仅只有struct有方法
很多库都有对于切片的get方法
type elementList []string
func (elist elementList) Get(findElement string) (result string, err error) {
for _, element := range elist {
if element == findElement {
return
}
}
return "", nil
}自己写一个更复杂一点的例子
package main
import (
"errors"
"fmt"
)
type userInfo map[string]interface{}
type userCollect []userInfo
func (u userCollect) Get(key string) (findUserInfo userInfo, err error) {
for _, value := range u {
if value["name"] == key {
return value, nil
}
}
return nil, errors.New("获取出错")
}
func main() {
users := userCollect{
{"name": "tom", "age": 18},
{"name": "jack", "age": 22},
}
value, err := users.Get("jack")
if err != nil {
fmt.Printf("err:%v\n", err)
return
}
fmt.Printf("value:%v\n", value)//fmt.Printf("err:%v",err)
}