Go Web学习
大体分为两个部分
- Go标准库实现Web开发
- Gin框架实现Web开发
有一点需要注意,Gin、GORM实际上有很多地方就是用的Go的标准库
Go标准库之http
http包提供了HTTP客户端和服务端的实现
package main
import (
"fmt"
"net/http"
)
func main() {
//接口地址/,处理函数hello
http.HandleFunc("/", hello)
//定义服务器配置
server := &http.Server{
Addr: ":8888", //8888端口
}
//根据上面的配置启动监听
if err := server.ListenAndServe(); err != nil {
fmt.Printf("启动失败,%v\n", err)
}
}
func hello(w http.ResponseWriter, _ *http.Request) {
w.Write([]byte("你好"))
}这里是Server配置结构体
type Server struct {
Addr string // 监听的TCP地址,如果为空字符串会使用":http"
Handler Handler // 调用的处理器,如为nil会调用http.DefaultServeMux
ReadTimeout time.Duration // 请求的读取操作在超时前的最大持续时间
WriteTimeout time.Duration // 回复的写入操作在超时前的最大持续时间
MaxHeaderBytes int // 请求的头域最大长度,如为0则用DefaultMaxHeaderBytes
TLSConfig *tls.Config // 可选的TLS配置,用于ListenAndServeTLS方法
// TLSNextProto(可选地)指定一个函数来在一个NPN型协议升级出现时接管TLS连接的所有权。
// 映射的键为商谈的协议名;映射的值为函数,该函数的Handler参数应处理HTTP请求,
// 并且初始化Handler.ServeHTTP的*Request参数的TLS和RemoteAddr字段(如果未设置)。
// 连接在函数返回时会自动关闭。
TLSNextProto map[string]func(*Server, *tls.Conn, Handler)
// ConnState字段指定一个可选的回调函数,该函数会在一个与客户端的连接改变状态时被调用。
// 参见ConnState类型和相关常数获取细节。
ConnState func(net.Conn, ConnState)
// ErrorLog指定一个可选的日志记录器,用于记录接收连接时的错误和处理器不正常的行为。
// 如果本字段为nil,日志会通过log包的标准日志记录器写入os.Stderr。
ErrorLog *log.Logger
// 内含隐藏或非导出字段
}Go标准库之html/template
只对一些常用的用法进行学习记录,更多用法请查看下面这篇文章
html/template这个库简单来说就是实现了一个模板引擎
Go语言内置了文本模板引擎text/template和用于HTML文档的``。它们的作用机制可以简单归纳如下:
1 、模板文件通常定义为 .tmpl 和 .tpl 为后缀(也可以使用其他的后缀),必须使用 UTF8编码(Go语言使用UTF-8编码)
2 、模板文件中使用{{和}}包裹和标识需要传入的数据,其他内容均不做修改原样输出。
3 、传给模板这样的数据就可以通过点号(.)来访问,如果数据是复杂类型的数据,可以通过{{ .字段名 }}来访问它的字段解析为模版对象
下面的方法可以去解析模板文件,得到模板对象:
func (t *Template) Parse(src string) (*Template, error) //解析字符串,返回模版对象
func ParseFiles(filenames ...string) (*Template, error) //解析文件,参数是文件地址(可以是多个),返回模版对象
func ParseGlob(pattern string) (*Template, error) //解析Glob匹配到的所有文件,返回模版对象注意:
也可以使用func New(name string) *Template函数创建一个名为name的模板,我们可以在这个模版上定义一些自定义方法、修改默认标识符等自定义行为,然后再对其调用上面的方法去解析模板字符串或模板文件。
(在【模版函数】、【自定义操作符】章节中会用到,【补充踩坑】章节也解释了默认情况下,模版名文件名,就是name)
模版渲染
解析一个文件,不用指定名字
func (t *Template) Execute(wr io.Writer, data any) error {
//....
}解析多个文件,返回多个模版对象,必须指定模版文件名来确定返回哪个模版对象
func (t *Template) ExecuteTemplate(wr io.Writer, name string, data any) error {
//....
}简单例子
使用Go语言的标准库 "html/template"
main.go
package main
import (
"fmt"
"html/template"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
//1.解析模版文件(读取模版文件)
tpl, err := template.ParseFiles("./index.tpl")
if err != nil {
fmt.Printf("解析出错,err:%v", err)
return
}
//2.模版渲染(把第二个参数填写到模版文件中,模版中的点就是传入的数据)
err = tpl.Execute(w, "jack")
if err != nil {
fmt.Printf("渲染模版出错,err:%v", err)
return
}
})
http.ListenAndServe(":9090", nil)
}index.tpl
<!DOCTYPE html>
<html>
<head></head>
<body>
你好,{{.}}
</body>
</html>模版基础
模版注释【左(右)花括号与左(右)注释之间不能有空格】
{{/* a comment */}}模版内变量
//定义变量a
{{$a}}
//变量初始化
{{$a:=1000}}去除空格【左(右)花括号与左(右)横杠之间不能有空格】
{{- .Name -}}管道符【|前面的命令会将运算结果(或返回值)传递给后一个命令的最后一个位置】
//将$a的值传递给method作为参数
{{$a|method}}模版参数
参数为结构体【注意:字段必须首字母大写,模版才能访问到】
type Stu struct {
Name string
Age int
}
tpl.Execute(w, Stu{Name: "jack", Age: 18})
//模版中
{{.Name}} 、{{.Age}}参数为map
//main.go
tpl.Execute(w, map[string]string{
"name": "jack",
"age": "18",
})
//模版中,可直接根据key取出value
{{.name}} 、{{.age}}参数是复杂数据时,可以让map的value是空接口类型
tpl.Execute(w, map[string]interface{}{
"studentInfo": map[string]string{
"name": "jack",
"age": "18",
},
"hobby": []string{
"唱歌",
"跳舞",
},
})条件渲染
判断.studentInfo.age是否大于10
{{if gt .studentInfo.age 10}}
年龄大于10岁
{{else eq .studentInfo.age 10}}
年龄等于10岁
{{else}}
年龄小于10岁
{{end}}比较函数
eq 如果arg1 == arg2则返回真
ne 如果arg1 != arg2则返回真
lt 如果arg1 < arg2则返回真
le 如果arg1 <= arg2则返回真
gt 如果arg1 > arg2则返回真
ge 如果arg1 >= arg2则返回真除eq外,其他函数只有两个参数。eq可以有多个参数,只有第一个参数和后面的所有数都相等,才返回true
eq a b c d循环渲染
循环的数据类型必须是数组、切片、字典或者通道
切片、数组
{{range $index,$value :=.hobby}}
{{$index}}---{{$value}}
{{end}}字典
{{range $index,$value :=.stuInfo}}
{{$index}}---{{$value}}
{{end}}模版函数
Go模版中提供了一些预定义函数
and
函数返回它的第一个empty参数或者最后一个参数;
就是说"and x y"等价于"if x then y else x";所有参数都会执行;
or
返回第一个非empty参数或者最后一个参数;
亦即"or x y"等价于"if x then x else y";所有参数都会执行;
not
返回它的单个参数的布尔值的否定(布尔函数会将任何类型的零值视为假,其余视为真)
len
返回它的参数的整数类型长度
index
执行结果为第一个参数以剩下的参数为索引/键指向的值;
如"index x 1 2 3"返回x[1][2][3]的值;每个被索引的主体必须是数组、切片或者字典。
print
即fmt.Sprint
printf
即fmt.Sprintf
println
即fmt.Sprintln
html
返回与其参数的文本表示形式等效的转义HTML。
这个函数在html/template中不可用。
urlquery
以适合嵌入到网址查询中的形式返回其参数的文本表示的转义值。
这个函数在html/template中不可用。
js
返回与其参数的文本表示形式等效的转义JavaScript。
call
执行结果是调用第一个参数的返回值,该参数必须是函数类型,其余参数作为调用该函数的参数;
如"call .X.Y 1 2"等价于go语言里的dot.X.Y(1, 2);
其中Y是函数类型的字段或者字典的值,或者其他类似情况;
call的第一个参数的执行结果必须是函数类型的值(和预定义函数如print明显不同);
该函数类型值必须有1到2个返回值,如果有2个则后一个必须是error接口类型;
如果有2个返回值的方法返回的error非nil,模板执行会中断并返回给调用模板执行者该错误;自定义函数
package main
import (
"fmt"
"html/template"
"net/http"
)
type Stu struct {
Name string
Age int
}
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
//---------自定的函数------------
//如果有两个返回值,第二个必须是error对象
myGetStuAge := func(name string) string {
return "你好," + name
}
//1.创建模版对象
t := template.New("index.tpl")
//2.在模版对象上注册自定义函数
t.Funcs(template.FuncMap{
"getStuAge": myGetStuAge, //属性是模版中的使用的函数名,值是go代码中定义的函数名
})
//3.将模版对象和解析文件得到的模版对象绑定
tpl, err := t.ParseFiles("./index.tpl")
if err != nil {
fmt.Printf("解析出错,err:%v", err)
return
}
//4.渲染模版
err = tpl.Execute(w, map[string]interface{}{
"studentInfo": map[string]interface{}{
"name": "jack",
"age": 18,
},
"hobby": []string{
"唱歌",
"跳舞",
},
})
if err != nil {
fmt.Printf("渲染模版出错,err:%v", err)
return
}
})
http.ListenAndServe(":9090", nil)
}模版中使用自定义函数
{{getStuAge .studentInfo.name}}嵌套模版(template)
即,模版页面中,直接引入其他模版页面
- 这个template可以是单独的模版文件
- 也可以是通过
define定义的区域
例子中,ul.tmpl是单独的文件,ol.tmpl是通过define定义的template
t.tpl
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
</head>
<body>
<h1>测试嵌套template语法</h1>
<hr>
{{template "ul.tmpl"}}
<hr>
{{template "ol.tmpl"}}
</body>
</html>
{{ define "ol.tmpl"}}
<ol>
你好,这里是ol.tpl文件
</ol>
{{end}}ul.tpl
<ul>
你好,这里是 ul.tpl 文件
</ul>main.go
func tmplDemo(w http.ResponseWriter, r *http.Request) {
tmpl, err := template.ParseFiles("./t.tpl", "./ul.tpl") //注意这里有先后顺序限制。ul包含在t之中,所以t在前面
if err != nil {
fmt.Println("create template failed, err:", err)
return
}
tmpl.Execute(w, nil) //不传递数据
}模版继承(block)
定义块
{{block "名字" .}}{{end}} //点的含义是,将所在模版的数据,传入block中创造一个区域,上一节,使用define定义了一个模版
{{define "名字"}}
块中的内容{{.}}
{{end}}案例
common.tpl是基本模版,subA.tpl和subB.tpl只是修改了其中block区域的内容
subA.tpl
{{/*继承根模版*/}}
{{template "common.tpl" .}}
{{/*重新定义根模版中的块模版*/}}
{{define "content"}}
这里是{{.}}
{{end}}subB.tpl
{{/*继承根模版*/}}
{{template "common.tpl" .}}
{{/*重新定义块模版*/}}
{{define "content"}}
这里是{{.}}
{{end}}common.tpl
<!DOCTYPE html>
<html>
<head>
<style>
*{
margin: 0;
padding: 0;
}
.nav{
width: 100vw;
height: 100px;
background: red;
display: flex;
justify-content: center;
align-items: center;
}
.main{
width: 100vw;
height: 100vh;
display: flex;
justify-content: space-between;
}
.sider{
width: 200px;
height: 100%;
background: greenyellow;
display: flex;
justify-content: center;
align-items: center;
}
.content{
flex-grow: 1;
}
</style>
</head>
<body>
<div>
<div class="nav">顶部导航栏</div>
<div class="main">
<div class="sider">侧边栏</div>
<div class="content">
{{block "content" .}}{{end}}
</div>
</div>
</div>
</body>
</html>main.go
package main
import (
"fmt"
"html/template"
"net/http"
)
type Stu struct {
Name string
Age int
}
func main() {
http.HandleFunc("/subA", func(w http.ResponseWriter, r *http.Request) {
tpl, err := template.ParseFiles("./template/common.tpl", "./template/subA.tpl") //注意顺序
if err != nil {
fmt.Printf("解析出错,err:%v", err)
return
}
err = tpl.Execute(w, "subA")
if err != nil {
fmt.Printf("渲染模版出错,err:%v", err)
return
}
})
http.HandleFunc("/subB", func(w http.ResponseWriter, r *http.Request) {
tpl, err := template.ParseFiles("./template/common.tpl", "./template/subA.tpl") //注意顺序
if err != nil {
fmt.Printf("解析出错,err:%v", err)
return
}
err = tpl.Execute(w, "subB")
if err != nil {
fmt.Printf("渲染模版出错,err:%v", err)
return
}
})
http.ListenAndServe(":9090", nil)
}补充踩坑
在Go代码中解析模版文件时,需要明确文件所在路径
tmpl, err := template.ParseFiles("./a.tpl", "./b.tpl")所以,在模版文件,才可以直接使用,而不用考虑路径
{{template "a"}}
{{template "b"}}如果没有解析对应文件,在模版中就找不到对应的template
还有一点就是
xxx.tpl解析时,默认为一个名为xxx的模块,所以前面【嵌套模版(template)】的例子中,能直接通过
{{template "ul.tmpl"}}就把ul.tmp插入了其他模版中
如果,不希望模版名(name)为文件名,可以再模版首尾增加
{{define "新名字"}}
原本内容
{{end}}自定义操作符
模版中的默认操作符是双花括号,Vue中也是,所以可能会有些场景下,发生冲突
在解析文件前,使用Delims函数自定义操作符
http.HandleFunc("/subA", func(w http.ResponseWriter, r *http.Request) {
tpl,err:=template.New("index.tpl").Delims("{[","]}").ParseFiles("./index.tpl")
if err != nil {
fmt.Printf("解析出错,err:%v", err)
return
}
err = tpl.Execute(w, "subA")
if err != nil {
fmt.Printf("渲染模版出错,err:%v", err)
return
}
})html/template与text/template的区别
html/template 会把 {{.}} 中的html、js、css代码做转译,转化为文字,避免xss攻击如果不想要自动转译,希望能正常执行,可以自定义一个函数,即使用template.HTML方法
http.HandleFunc("/subA", func(w http.ResponseWriter, r *http.Request){
tmpl,err := template.New("index.tmpl").Funcs(template.FuncMap{
"safe": func(s string)template.HTML {
return template.HTML(s)
},
}).ParseFiles("./index.tmpl")
if err != nil {
fmt.Println("解析模版失败, err:", err)
return
}
Str := `<script>alert('123')</script>`
err = tmpl.Execute(w, Str)
if err != nil {
fmt.Println("渲染模版失败, err:", err)
return
}
})使用
{{.|safe}}Gin框架是一个使用Go语言开发的高性能Web框架
Go标准库之database/sql
database/sql这个库简单来说就是实现了SQL或类SQL数据库的泛用接口,并不提供具体的数据库驱动。使用database/sql包时必须注入(至少)一个数据库驱动。
我们常用的数据库基本上都有完整的第三方实现好的驱动。例如:MySQL驱动
后面的例子都是使用Mysql数据库
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
var db *sql.DB
func initDB() (err error) {
dsn := "root:xxxx@tcp(127.0.0.1:13306)/db1" //账号:密码@协议(地址:端口)/数据库名
db, err = sql.Open("mysql", dsn)
if err != nil {
panic(err)
}
err = db.Ping() //连接数据库失败返回err,成功返回nil
if err != nil {
fmt.Printf("连接失败")
return
}
db.SetMaxOpenConns(500) //连接池中与数据库建立连接的最大数目,默认为0(无限制)
db.SetMaxIdleConns(10) //连接池中的最大闲置连接数,最大不能超过"最大连接数",超过就最大闲置连接为"最大连接数"
db.SetConnMaxLifetime(time.Second*10) //正在使用的连接的存活时间
//db.SetConnMaxIdleTime() //空闲链接的存活时间
return
}
func main() {
if err := initDB(); err != nil {
fmt.Printf("err:%v", err)
return
}
defer db.Close() //必须确保db不为nil,才能调用Close
}这篇文章介绍一些关于SetMaxOpenConns、SetMaxIdleConns、SetConnMaxLifetime的信息(https://learnku.com/go/t/49809)
新建数据库表
create table users_info
(
id int auto_increment,
name varchar(50) null,
age int null,
constraint users_info_pk
primary key (id)
);建议使用GoLand的数据库插件,可视化建表

SQL语句中的占位符
我们后面见到的增删改查中,SQL语句中的? 是查询占位符,它可以防止SQL注入攻击。
database/sql不对占位符处的文本进行任何验证;只是将带占位符的SQL语句和编码后的参数一起按原样发送到服务器,查询是在数据库服务器上进行的,所以不同的数据库使用的占位符也不同:
- MySQL中使用
? - PostgreSQL使用枚举的
$1、$2等bindvar语法 - SQLite中
?和$1的语法都支持 - Oracle中使用
:name的语法
对占位符一个常见误解就是将它们看成是SQL语句的拼接,其实并不是
SQL语句的拼接不能防范SQL注入,而使用占位符的方式可以防范SQL注入
sqlStr := "select id,name,age from users_info where id=?"
row := db.QueryRow(sqlStr, 2)同时,占位符所在的位置不能更改SQL语句的结构,例如:
// ?不能用来插入表名
db.Query("SELECT * FROM ?", "mytable")
// ?也不能用来插入列名
db.Query("SELECT ?, ? FROM people", "name", "location")查询
先在建好的表中插入几条数据,在查询
查询单条数据
db.QueryRow()返回的row对象,如果不执行Scan就会一直占用数据库连接,这时,如果设置最大连接数是1,同时发起两次查询,就会阻塞代码。只有执行Scan连接才会断开
//定义一个结构,将查出的数据保存在这个结构里
type user struct {
id int
age int
name string
}
func queryRow() {
var u user
sqlStr := "select id,name,age from users_info where id=?"
row := db.QueryRow(sqlStr, 2)
err:=row.Scan(&u.id, &u.name, &u.age)
if err != nil {
fmt.Printf("读取失败:%v", err)
return
}
fmt.Printf("查询结果:%#v\n ", u)
}在main函数中调用
func main() {
if err := initDB(); err != nil {
fmt.Printf("err:%v", err)
return
}
defer db.Close() //必须确保db不为nil,才能调用Close
queryRow() //查询结果:main.user{id:1, age:200, name:"h3"}
}为了避免忘记Scan释放连接,一般连写
err := db.QueryRow(sqlStr, 2).Scan(&u.id, &u.name, &u.age)
if err != nil {
fmt.Printf("读取失败:%v", err)
}查询多行数据
为了避免循环rows数据时出现panic导致程序中断了,但是数据库连接没有被释放,所以一定要加上defer rows.Close()
func queryRows() {
sqlStr := "select id,name,age from users_info where id in (?,?)"
rows, err := db.Query(sqlStr, 1, 2)
if err != nil {
fmt.Printf("查询失败:%v", err)
return
}
defer rows.Close() //这里很重要,有可能某行时就会触发panic
for rows.Next() { //循环读取查询结果
var u user
err := rows.Scan(&u.id, &u.name, &u.age)
if err != nil {
fmt.Printf("读取失败:%v", err)
continue
}
fmt.Printf("查询结果:%#v\n ", u)
}
}调用
func main() {
if err := initDB(); err != nil {
fmt.Printf("err:%v", err)
return
}
defer db.Close() //必须确保db不为nil,才能调用Close
queryRows()
//查询结果:main.user{id:1, age:200, name:"h3"}
//查询结果:main.user{id:2, age:18, name:"y"}
}补充:为什么user结构体名和其中的字段可以小写,其他的一些数据库相关的第三方Go库必须大写
因为Scan函数仅仅是做一个赋值操作
其他的一些库,可能是将变量传入函数,在函数中操作结构体,比如通过反射进行一些处理后赋值(回忆下,使用其他包中的变量或函数时,这个变量或函数必须首字母大写)
插入
接下来的,插入、更新、删除,都需要使用Exec执行,Exec执行完后,会自动断开连接
// 插入数据
func insertRow() {
sqlStr := "insert into users_info(name, age) values (?,?)"
ret, err := db.Exec(sqlStr, "jack", 20)
if err != nil {
fmt.Printf("插入失败:%v\n", err)
return
}
theID, err := ret.LastInsertId() // 新插入数据的id
if err != nil {
fmt.Printf("插入失败:%v\n", err)
return
}
lineNum, err := ret.RowsAffected() //新插入数据影响的行数
if err != nil {
fmt.Printf("插入失败:%v\n", err)
return
}
fmt.Printf("插入成功, id是 %d ;受影响的行数是:%v\n", theID, lineNum)
}更新
func updateRow() {
sqlStr := "update users_info set age=? where name=?"
ret, err := db.Exec(sqlStr, 22, "tom")
if err != nil {
fmt.Printf("更新失败:%v\n", err)
return
}
lineNum, err := ret.RowsAffected() //更新数据影响的行数
if err != nil {
fmt.Printf("更新失败:%v\n", err)
return
}
fmt.Printf("更新成功, 受影响的行数是:%v\n", lineNum) //更新成功, 受影响的行数是:0
}删除
func deleteRow() {
sqlStr := "delete from users_info where id=?"
ret, err := db.Exec(sqlStr, 1)
if err != nil {
fmt.Printf("删除失败:%v\n", err)
return
}
lineNum, err := ret.RowsAffected() //删除数据影响的行数
if err != nil {
fmt.Printf("删除失败:%v\n", err)
return
}
fmt.Printf("删除失败, 受影响的行数是:%v\n", lineNum) //删除失败, 受影响的行数是:1
}预处理
把SQL语句分成两部分,命令部分与数据部分。先把命令部分发送给MySQL服务端,MySQL服务端进行SQL预处理,然后把数据部分发送给MySQL服务端,MySQL服务端对SQL语句进行占位符替换后,再去查询
拼接查询字符串
用拼接后的查询字符串,去数据库执行,这种十分容易出现SQL注入的问题
sqlStr := fmt.Sprintf("select id,name,age from users_info where id='%s'", "3' or 1=1#")
rows, err := db.Query(sqlStr) //执行:select id,name,age from users_info where id='3' or 1=1#'
// #在Sql语句中时注释的含义。这句Sql语句原本是根据id查询数据,因为插入"3' or 1=1#" ,就变成了搜索整个表前面的增删改查
不会出现SQL注入的后果(以多行查询为例子)
sqlStr := "select id,name,age from users_info where id=?"
rows, err := db.Query(sqlStr, "2' or 1=1#") //执行:select id,name,age from users_info where id='3'预处理
不会出现SQL注入的后果
sqlStr := "select id,name,age from users_info where id=?"
stmt, err := db.Prepare(sqlStr)
if err != nil {
fmt.Printf("prepare failed, err:%v\n", err)
return
}
defer stmt.Close()
//增、删、改、查都是用预处理的stmt,参数就是字符串中的参数
rows, err := stmt.Query(1)
err := stmt.QueryRow(1).Scan(&u.id, &u.name, &u.age)
ret, err:=stmt.Exec(1)事务
通常事务必须满足4个条件(ACID):原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
| 条件 | 解释 |
|---|---|
| 原子性 | 一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。 |
| 一致性 | 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。 |
| 隔离性 | 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。 |
| 持久性 | 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。 |
事务相关的方法
Begin()
Rollback()
Commit()例子
func transaction() {
tx, err := db.Begin()
if err != nil {
fmt.Printf("创建事务错误,%v\n", err)
return
}
//第一条SQL语句
res, err := tx.Exec("insert into users_info(name,age) values (?,?)", "hhh", 20)
if err != nil {
fmt.Printf("回滚事务,第一条SQL语句错误,%v\n", err)
tx.Rollback()
return
}
if firstRowNum, err := res.RowsAffected(); err != nil || firstRowNum != 1 {
fmt.Printf("回滚事务,第一条SQL语句错误,%v\n", err)
tx.Rollback()
return
}
//第二条SQL语句
res, err = tx.Exec("select * from users_info where id=?", 22)
if err != nil {
fmt.Printf("回滚事务,第二条SQL语句错误,%v\n", err)
tx.Rollback()
return
}
if secondRowNum, err := res.RowsAffected(); err != nil || secondRowNum != 1 {
fmt.Printf("回滚事务,第二条SQL语句错误,%v\n", err)
tx.Rollback()
return
}
//
fmt.Printf("提交事务")
tx.Commit() // 提交事务
}Redis(略)
这部分介绍go-redis这个第三方库
因为我电脑里没有安装redis
# 使用redis 5.0.7 版本的镜像,启动一个名为 redis507 的 容器,运行一个redis server
docker run --name redis507 -p 6379:6379 -d redis:5.0.7
# 启动一个 redis-cli 连接上面的 redis server
docker run -it --network host --rm redis:5.0.7 redis-cli例子
package main
import (
"fmt"
"github.com/go-redis/redis"
)
var rdb *redis.Client
func initClient() (err error) {
rdb = redis.NewClient(&redis.Options{
Addr: "localhost:6379", //地址
Password: "", // 无密码,就设置为空字符串
DB: 0, // 数据库
PoolSize: 20, // 连接池大小
})
_, err = rdb.Ping().Result()
if err != nil {
return
}
return
}
func getValue() {
str, err := rdb.Get("name").Result()
if err == redis.Nil {
fmt.Printf("不存在该键值对")
return
} else if err != nil {
fmt.Printf("获取值错误,%v\n", err)
return
}
fmt.Printf("获取的值:%v\n", str)
}
func main() {
err := initClient()
if err != nil {
fmt.Printf("连接redis失败,%v\n", err) //err是redis:nil
panic(err)
}
defer rdb.Close()
getValue()
}Gin介绍
Gin 是一个 Go (Golang) 编写的轻量级 http web 框架,最擅长的就是 Api 接口的高并发,运行速度非常快,如果你是性能和高效的追求者,推荐使用 Gin 框架。
当某个接口的性能遭到较大挑战的时候,这个还是可以考虑使用 Gin 重写接口
Gin的简单例子
新建文件夹goGin
go mod init goGin
go get -u github.com/gin-gonic/gin新建main.go 文件
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
//1. 创建一个默认的路由引擎
r := gin.Default()
//2. Get请求
r.GET("/hi", func(context *gin.Context) {
//http.StatusOK是一个状态码常量,就是200
context.JSON(http.StatusOK, gin.H{
"message": "你好",
})
})
//3. 启动,默认在8080端口启动服务
r.Run()
}访问http://127.0.0.1:8080/hi,看到返回的结果
Gin返回响应数据
Gin返回HTML
也就是使用Gin做模版渲染
加载模版文件 (等同于Go标准库中的ParseFiles、ParseGlob)
gor.LoadHTMLGlob("glob字符串") r.LoadHTMLFiles("模版文件路径","模版文件路径")HTML方法
gofunc main() { r := gin.Default() r.LoadHTMLGlob("templates/**/*") //r.LoadHTMLFiles("templates/posts/index.html", "templates/users/index.html") r.GET("/posts/index", func(c *gin.Context) { c.HTML(http.StatusOK, "posts/index.html", gin.H{ "title": "posts/index", }) }) r.GET("users/index", func(c *gin.Context) { c.HTML(http.StatusOK, "users/index.html", gin.H{ "title": "users/index", }) }) r.Run(":8080") }静态文件
html中引用的静态资源,比如:css、js、image
gor := gin.Default() r.Static("html中静态文件地址", "文件的实际位置")比如:打开网页,可以在控制台看到,访问了/static/*等一系列静态资源。这些资源我们放在项目根目录下的static目录
 go
gor.Static("/static", "./static")
Gin返回JSON
map
gin.H
结构体
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/hi", func(context *gin.Context) {
//1.map作为参数
//data := map[string]string{
// "name": "jack",
// "age": "18",
//}
//2. 使用gin.H ,其实就是map[string]interface{}类型
//data := gin.H{
// "name": "jack",
// "age": 18,
//}
//3.结构体
type JSONData struct {
name string
age int
}
data := JSONData{
Name: "jack",
Age: 18,
}
context.JSON(http.StatusOK, data) //JSON方法做了一个JSON序列化的操作
})
r.Run(":9080")
}注意:
- 如果使用结构体,必须首字母大写,才能正常返回字段
- 如果想要返回小写首字母的字段,或者想要返回重命名的字段,可以使用tag
type JSONData struct {
Name string `json:"name"`
Age int `json:"age"`
}响应参数规范
一般应该遵循统一的返回规范
{
"code": 0,
"msg": "这里是错误原因说明",
"data": {} // 业务数据
}code
业务状态码,用来表示业务请求是否成功
0 //代表成功
小于0 //代表发生错误
大于0 //代表成功,但是有额外步骤举例子,不同code的含义,注意具体原因还是应该通过msg返回
1 注册成功,但是需要完善个人资料
0 成功
-1 参数不全msg
当code小于0时,msg字段为错误原因
code大于等于0,msg字段为ok
data
业务数据
请求返回的结果放在这里面
Gin获取请求数据
http://httpbin.org/,这是一个用于测试HTTP请求的网站,请求的返回值就是请求时的相关信息,方便调试
请求基础
Get请求
通过URL传递数据
xxx.com?name=jack&age=18Post请求
Post请求将传递的数据放在请求体中
分为:
form-data
可以从Postman工具的Body字段得知,form-data可以传递多条键值对数据,数据值可以是字符串/文件
form-data是可以上传多个文件的,这是与binary最大的不同

同时,在Content-Type字段指定了数据类型、在boundary 字段中指明了分割每条数据的字符串
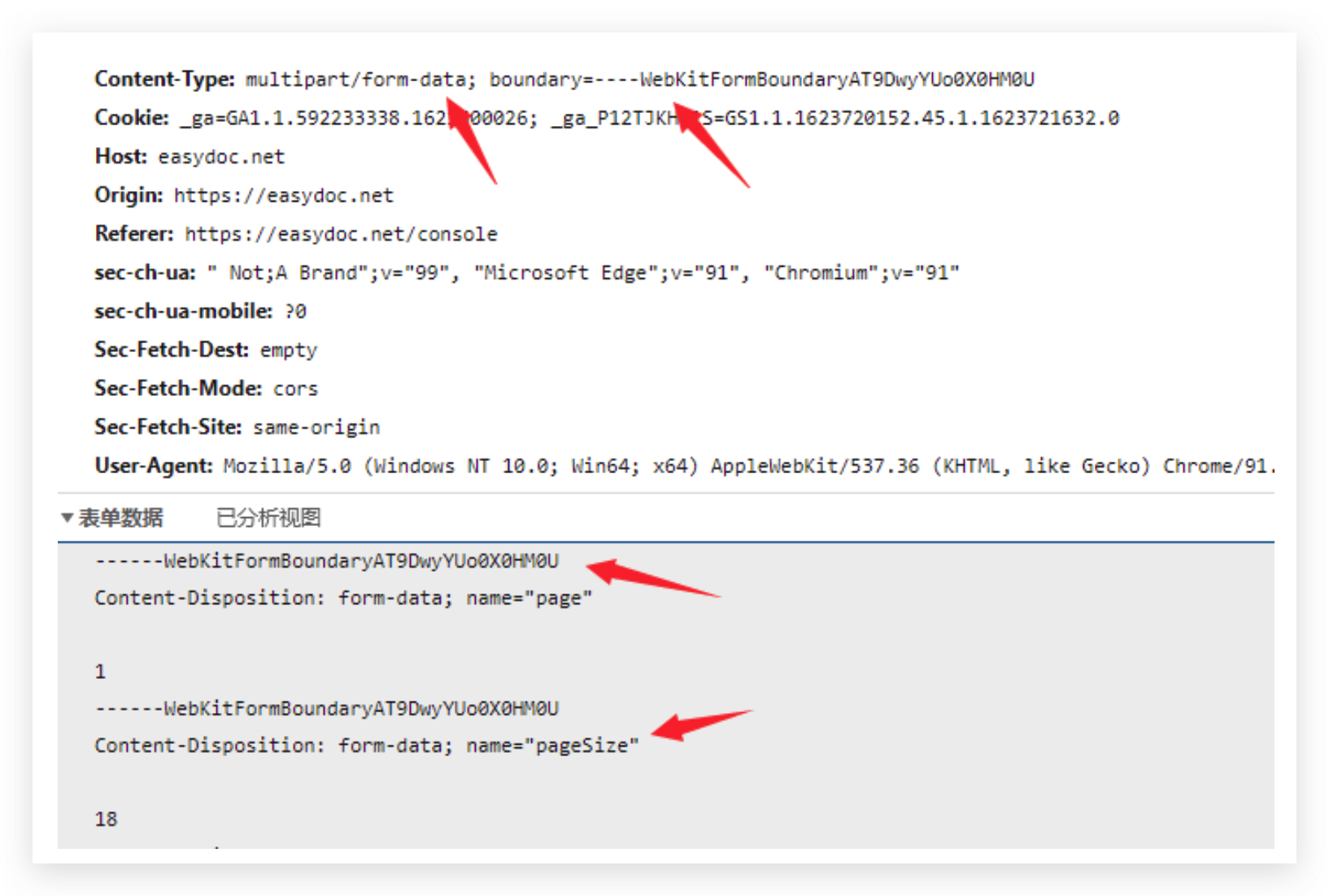
前端发送方式:
手动构造FormData对象,然后发送。FormData的常用方法
html<script> // 创建FormData对象 var formData = new FormData(); //往FormData对象里加入键值对: formData.append('username', 'Chris'); //删除键值对 formData.delete('username'); let response = await fetch('./upload', { method: 'POST', body: formData }); </script>自动构造FormData,通过指定enctype为
multipart/form-data(默认值为x-www-from-urlencoded)html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>上传</title> </head> <body> <form action="./upload" method="post" enctype="multipart/form-data"> <!--所有的输入元素都需要有name属性,name就是键--> <input type="file" name="file1"> <input type="submit" value="提交"> </form> </body> </html>x-www-from-urlencoded
可以传递多条键值对数据,数据值只能是字符串。所以,不能上传文件

Content-Type指明类型,其数据是以键值对的形式进行URL编码后存在请求体中发送的
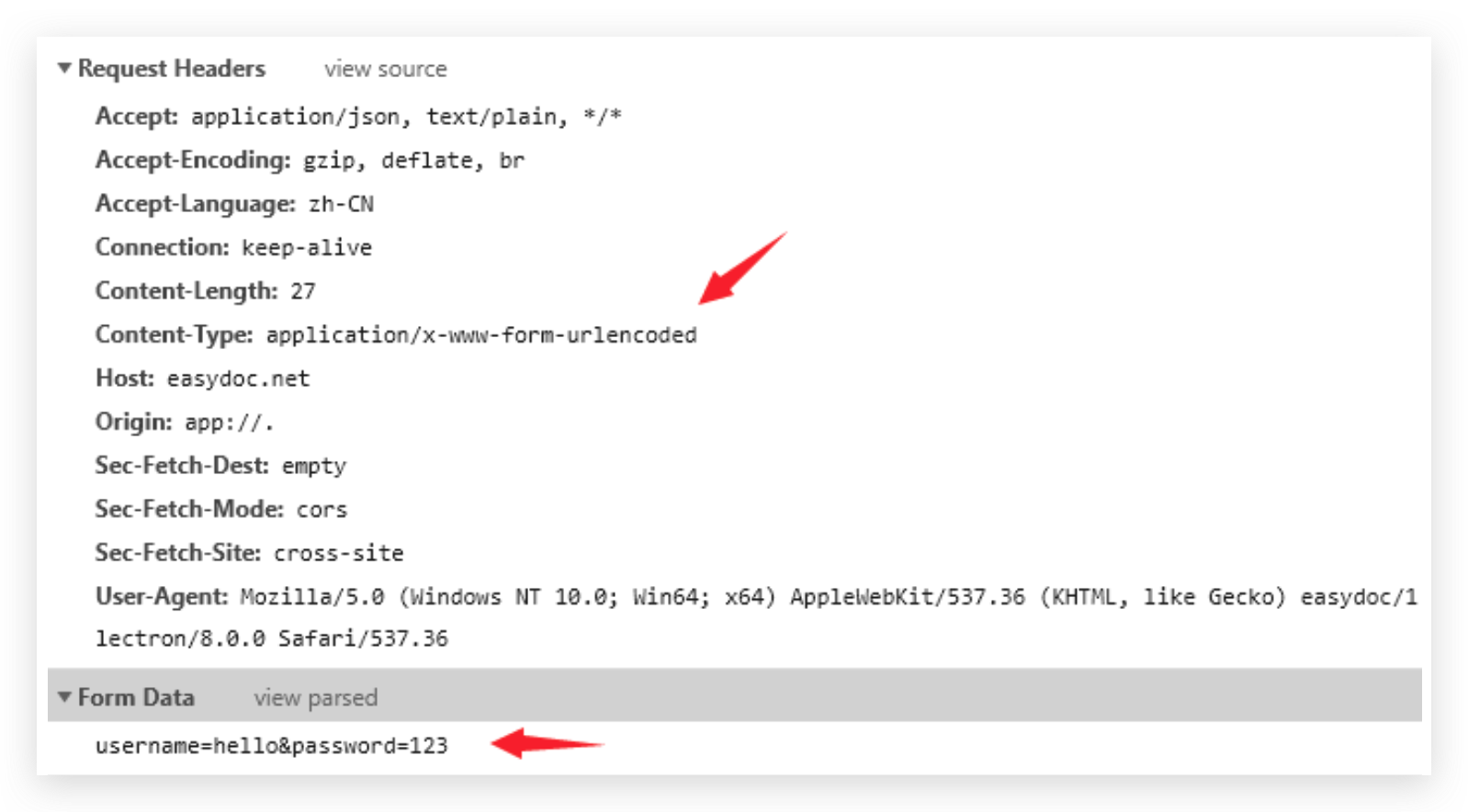 html
html<script> let response = await fetch('./upload', { method: 'POST', body: 'username=hello&password=123' }); </script>raw
传递文本数据
可以上传任意格式的文本,对应不同的Content-Type值
textcontent-type=text/plainjsapplication/javascriptcsstext/cssjsonapplication/jsonhtmltext/htmlxmltext/xml
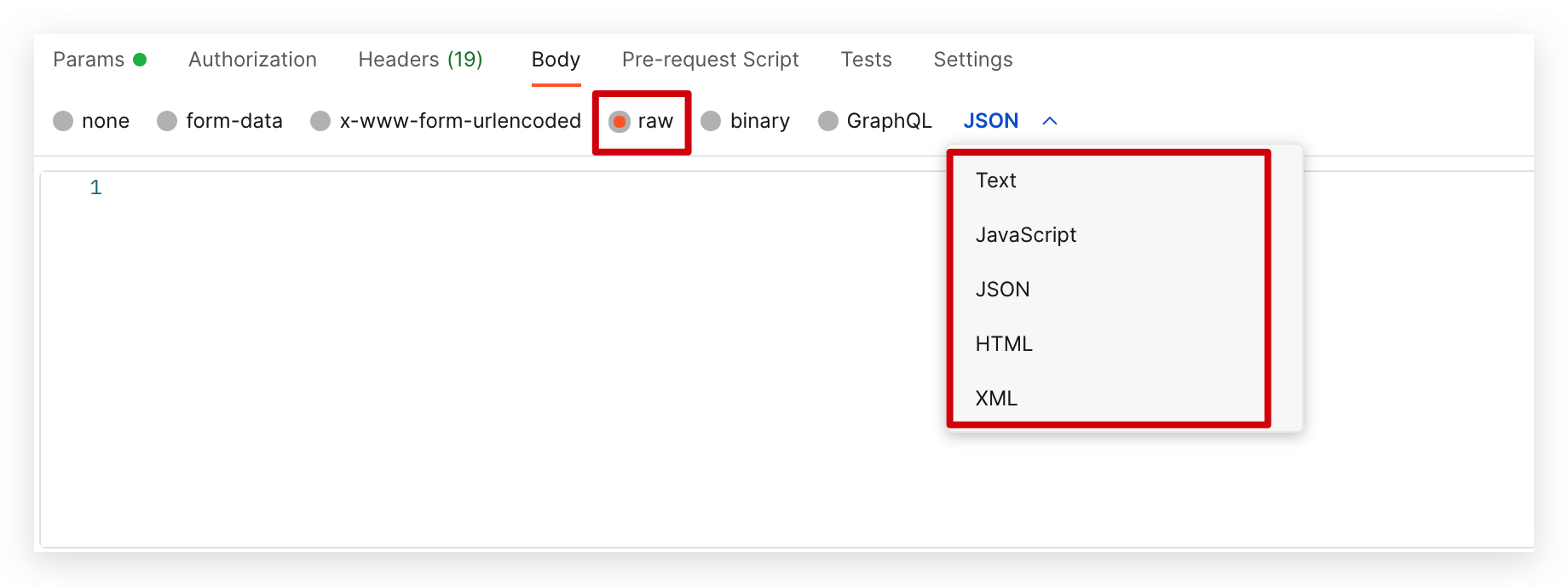
前端发送方式:
html<script> let user = { name: 'John', surname: 'Smith' }; let response = await fetch('./upload', { method: 'POST', body: JSON.stringify(user) }); </script>binary
只可以上传二进制数据,通常用来上传文件,由于没有键值,所以,一次只能上传一个文件
Content-Type:application/octet-stream
html的表单
表单是最常见的 POST 提交数据的方式了。浏览器的原生 <form> 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。如果想使用表单 上传文件 时,必须让<form>表单的enctype属性值为 multipart/form-data
<form action="/login" method="post">
First name: <input type="text" name="username"><br>
Last name: <input type="text" name="password"><br>
<input type="submit" value="提交">
</form>Get请求获取URL参数(queryString)
前面的例子都是使用的Get请求
这里补充下,获取Get请求的参数的方法
Query、DefaultQuery、GetQuery
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/hi", func(context *gin.Context) {
//获取指定key,key不存在,返回空字符串
str1 := context.Query("name")
fmt.Printf("Query:%v\n", str1)
//获取指定key,key不存在,返回默认值
str2 := context.DefaultQuery("name", "默认值")
fmt.Printf("DefaultQuery:%v\n", str2)
//获取指定key,key不存在,返回空字符串
str3, ok := context.GetQuery("name")
if !ok {
fmt.Println("GetQuery:不存在此key值")
}
fmt.Printf("DefaultQuery:%v", str3)
context.JSON(http.StatusOK, str1)
})
r.Run(":9080")
}Post请求获取表单数据(x-www-from-urlencoded)
Go语言命名中常常出现的Form相关的变量、方法都是用来处理x-www-from-urlencoded的
PostForm、DefaultPostForm、GetPostForm,与Get请求中取参数的函数相同
例子

main.go
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
//加载模版文件,模版名默认为文件名。下面返回登陆页面时,通过指定名字返回对应的页面
r.LoadHTMLFiles("./login.html", "./loginSuccess.html")
//返回登陆页面
r.GET("/login", func(context *gin.Context) {
context.HTML(http.StatusOK, "login.html", nil)
})
//登陆页面form标签发起post请求
r.POST("/login", func(context *gin.Context) {
username := context.PostForm("username")
password := context.PostForm("password")
fmt.Printf("用户名:%v 密码:%v\n", username, password)
//返回登陆成功页面
context.HTML(http.StatusOK, "loginSuccess.html", gin.H{
"username": username,
"password": password,
})
})
r.Run(":9080")
}login.html
登陆页面,使用form表单,【请求基础】中提到过form表单默认的enctype是x-www-from-urlencoded,即以键值对的形式传递数据。input标签的type是类型,name就是上传的键值对的的key
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登陆</title>
</head>
<body>
<div>
<form action="/login" method="post">
First name: <input type="text" name="username"><br>
Last name: <input type="text" name="password"><br>
<input type="submit" value="提交">
</form>
</div>
</body>
</html>loginSuccess.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登陆成功</title>
</head>
<body>
你好,{{.username}}
密码是:{{.password}}
</body>
</html>Post请求获取上传文件(form-data)
Go语言命名中常常出现的MultipartForm相关的变量、方法都是用来处理form-data的
上传单个文件
main.go
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"net/http"
"path"
)
func main() {
r := gin.Default()
r.LoadHTMLFiles("./upload.html")
//上传页面
r.GET("/uploadFile", func(context *gin.Context) {
context.HTML(http.StatusOK, "upload.html", nil)
})
//处理上传请求
r.POST("./upload", func(context *gin.Context) {
file, err := context.FormFile("file1") //value值是文件,参数是文件对应的key,也就是input标签的name值
if err != nil {
context.JSON(http.StatusBadRequest, gin.H{
"error": err.Error(), //错误接口中的Error方法返回字符串
})
} else {
//拼接文件路径,为当前路径
dst := path.Join("./", file.Filename)
//保存文件到指定路径
err := context.SaveUploadedFile(file, dst)
if err != nil {
fmt.Printf("保存文件失败,err:%v", err)
}
context.JSON(http.StatusOK, gin.H{
"status": "ok",
})
}
})
r.Run(":9000")
}upload.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>上传</title>
</head>
<body>
<form action="./upload" method="post" enctype="multipart/form-data">
<input type="file" name="file1">
<input type="submit" value="提交">
</form>
</body>
</html>修改文件大小限制
处理multipart forms提交文件时默认的内存限制是32 MiB ,可以通过下面的方式修改
router.MaxMultipartMemory = 8 << 20 // 8 MiB上传多个文件
使用MultipartForm接收
func main() {
router := gin.Default()
// 处理multipart forms提交文件时默认的内存限制是32 MiB
// 可以通过下面的方式修改
// router.MaxMultipartMemory = 8 << 20 // 8 MiB
router.POST("/upload", func(c *gin.Context) {
// Multipart form
form, _ := c.MultipartForm()
files := form.File["file"]
for index, file := range files {
log.Println(file.Filename)
dst := fmt.Sprintf("C:/tmp/%s_%d", file.Filename, index)
// 上传文件到指定的目录
c.SaveUploadedFile(file, dst)
}
c.JSON(http.StatusOK, gin.H{
"message": fmt.Sprintf("%d files uploaded!", len(files)),
})
})
router.Run()
}html中就是多个上传的input即可
<form action="./upload" method="post" enctype="multipart/form-data">
<input type="file" name="file1">
<input type="file" name="file2">
<input type="submit" value="提交">
</form>Post请求raw数据(raw)
raw类型虽然可以传输很多格式的数据,但实际上一般都是传递JSON格式,下面以JSON为例子
如果发送以下数据
{
"name":"jack",
"age":20
}定义的结构需要使用json这个tag
type m struct{
Name string `joson:"name"`
Age int `json:"age"`
}
r.POST("/json", func(c *gin.Context) {
b, _ := c.GetRawData() // 从c.Request.Body读取请求数据
// 定义map或结构体
var m map[string]interface{}
// 反序列化
_ = json.Unmarshal(b, &m) //m是对应的GO语言的数据结构
c.JSON(http.StatusOK, m)
})获取请求路径中的参数
访问http://127.0.0.1:9080/login/123 ,123就会被接收到
r.GET("/login/:username", func(context *gin.Context) {
fmt.Println(context.Param("username"))
//或者通过Params属性
//string,ok:=context.Params.Get("id")
})注意参数类型
只有raw类型的JSON格式,其中传递的数字,在后端接收到是数字
{
"age":10其他发送方式,**接收到的参数都是字符串格式 **
接口设计规范
基本结构
/{系统类型或者api}/{版本号}/{功能模块}/{具体操作}例如
App登录:/app/v1/user/login
微信程序登陆:/wechat/app/v1/user/login
管理后台登录:/admin/v1/user/login
创建群:/app/v1/group/create
群列表:/app/v1/group/list自动绑定数据
上一章节,获取数据后,需要手动的存储到变量中
这章学习自动将接收到的参数,绑定到变量上
总述
Context的绑定相关的方法非常多,到底是用哪一个呢?
主要取决于
- 是否需要指定Binding
- 是否需要自动写入400状态码。Context的MustBindWith方法比ShouldBindWith多了一步处理返回体状态码的操作

Context.Bind的调用流程
以Context.Bind为例子,介绍下流程
Context.Bind
Context.Bind(用于存储数据的结构体obj)
1、binding.Default(c.Request.Method, c.ContentType()) //根据请求方法和Content-Type创建不同的Binding对象对象
2、return c.MustBindWith(obj, b) //返回context调用不同的binding对象
var (
JSON = jsonBinding{}
XML = xmlBinding{}
Form = formBinding{}
Query = queryBinding{}
FormPost = formPostBinding{}
FormMultipart = formMultipartBinding{}
ProtoBuf = protobufBinding{}
MsgPack = msgpackBinding{}
YAML = yamlBinding{}
Uri = uriBinding{}
Header = headerBinding{}
TOML = tomlBinding{}
)Context.MustBindWith
.MustBindWith(用于存储数据的结构体obj, 根据上一步根据请求方法和Content-调用Binding对象)
1、c.ShouldBindWith(obj, b); //调用ShouldBindWith
2、c.AbortWithError(http.StatusBadRequest, err).SetType(ErrorTypeBind) //向响应体的状态码中写入400,设置错误类型Context.ShouldBindWith
Context.ShouldBindWith(用于存储数据的结构体obj, 根据上一步根据请求方法和Content-Typ返回的调用Binding对象)
1、b.Bind(c.Request, obj) //调用Binding对象(提醒下,这个前面请求方法和Content-Typ决定的)的Bind方法binding.Bind
这一步才到真正绑定数据到变量
binding.Bind(Content中的请求体, 用于存储数据的结构体obj)
这个方法只能绑定 queryString、raw中是JSON数据、 x-www-from-urlencodeShouldBind/Bind
使用ShouldBind/Bind可以自动提取queryString、x-www-from-urlencoded、form-data、raw中的JSON数据的数据,并把值绑定到指定的结构体对象
原理:基于请求的Content-Type识别请求数据类型并利用反射机制自动提取请求数据到结构体中
有两点注意:
ShouldBind/Bind参数是存放数据的结构体,因为要操作结构体,所以必须是指针类型
结构体名、结构体字段首字母大写
如果想将接收到的参数a存储到Name字段,参数 b存储到Age字段。那么就需要使用tag
gotype User struct { Name string `form:a` Age string `form:b` }存储数据的结构体变量,如果某个字段接收不到值,该字段默认为零值
ShouldBind例子
GET请求发送queryString
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"net/http"
)
type Stu struct {
Name string `form:"name"`
Age int `form:"age"`
}
func main() {
r := gin.Default()
r.GET("/index", func(context *gin.Context) {
var s Stu
if err := context.ShouldBind(&s); err != nil {
fmt.Printf("err: %v", err)
context.JSON(http.StatusOK, gin.H{
"msg": err,
})
return
}
context.JSON(http.StatusOK, gin.H{
"msg": s,
})
})
r.Run(":9090")
}
POST请求发送x-www-urlencoded、form-data、raw中的JSON数据
//只需要将方法改成POST即可
r.POST("/index", func(context *gin.Context){
//xxxx
})Bind例子
用法与ShouldBind一模一样,唯一的区别就是返回的状态码
以POST请求发送raw类型的JSON数据为例子,如果前端发送以下数据,name被接收到,但是绑定到Stu类型的结构体的Name字段时,由于Name是string类型,所以一定会绑定出错
{
"name":{
"abc":122
}
}Bind会在返回体中设置状态码为400

ShouldBind

ShouldBindUri/BindUri
用于绑定请求路径中的参数
BindUri比ShouldBindUri多一个绑定出错时,有400状态码返回
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"net/http"
)
type Stu struct {
Name string `uri:"name"`
Age int `uri:"age"`
}
func main() {
r := gin.Default()
r.GET("/index/:name/:age", func(context *gin.Context) {
var s Stu
if err := context.BindUri(&s); err != nil {
fmt.Printf("err: %v", err)
context.JSON(http.StatusOK, gin.H{
"msg": err,
})
return
}
context.JSON(http.StatusOK, gin.H{
"msg": s,
})
})
r.Run(":9090")
}
注意这里使用uri字段作为tag
type Stu struct {
Name string `uri:"name"`
Age int `uri:"age"`
}其tag和路径中的名字对应上
r.GET("/index/:name/:age", func(context *gin.Context) {
//xxxxx
})快捷方式
以BindJSON为例子,接收以raw的json格式的参数
type ParamSignUp struct {
Username string `json:"username"`
Password string `json:"password"`
}
p := new(models.ParamSignUp)
if err := c.BindJSON(p); err != nil { //只有在前端传过来的字段类型与绑定的结构体字段类型不符时,才会报错
c.JSON(http.StatusOK, gin.H{
"code": -1,
"msg": err.Error(),
"data": nil,
})
return
}
c.JSON(http.StatusOK, gin.H{
"code": 0,
"msg": "ok",
"data": nil,
})重定向
HTTP重定向
访问http://127.0.0.1:9000/index,浏览器地址栏直接重定向到百度首页
r.GET("./index", func(context *gin.Context) {
context.Redirect(http.StatusMovedPermanently, "http://www.baidu.com")
})路由重定向
访问http://127.0.0.1:9000/a,浏览器地址没有变化,返回{"message": "处理/b的函数中",}
r.GET("./a", func(context *gin.Context) {
//1.修改路由地址为/b
context.Request.URL.Path = "/b"
//2.继续处理这个路由请求
r.HandleContext(context)
})
r.GET("./b", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"message": "处理/b的函数中",
})
})Gin路由
路由基础
复习下
常用的四种路由方式
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/user", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "Get",
})
})
r.POST("/user", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "Post",
})
})
r.PUT("/user", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "Put",
})
})
r.DELETE("/user", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "Delete",
})
})
r.Run(":9000")
}简写
r.Any("/book", func(context *gin.Context) {
switch context.Request.Method {
case http.MethodGet:
{
context.JSON(http.StatusOK, gin.H{
"msg": "Get",
})
}
case http.MethodPost:
{
context.JSON(http.StatusOK, gin.H{
"msg": "Post",
})
}
case http.MethodPut:
{
context.JSON(http.StatusOK, gin.H{
"msg": "Put",
})
}
case http.MethodDelete:
{
context.JSON(http.StatusOK, gin.H{
"msg": "Delete",
})
}
}
})未匹配路由
r.NoRoute(func(context *gin.Context) {
context.JSON(http.StatusNotFound, gin.H{
"msg": "找不到页面",
})
})路由组
常用在:
- 一个业务线的Api写在一个组里
- 不同版本的Api写在不同组里。比如:对Api进行升级就可以这样
r.Group("/music/v2"),然后再组里写升级后的Api
musicGroup := r.Group("/music")
{
musicGroup.GET("/index", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "music下的index",
})
})
musicGroup.GET("/my", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "music下的my",
})
})
}路由组可以嵌套
musicGroup := r.Group("/music")
{
musicGroup.GET("/index", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "music下的index",
})
})
//嵌套路由组
newMusicGroup := r.Group("/v2")
{
//注意:地址是 /v2/index ,不是 /music/v2/index
newMusicGroup.GET("/index", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"msg": "music组中的/v2/index",
})
})
}
}路由文件
当项目很大时,不可能把所有路由写在一个文件中,一般会把路由分配到多个文件中
router文件夹下,建立两个路由文件
路由A文件
package routes
import "github.com/gin-gonic/gin"
func ARoutesInit(router *gin.Engine)
{
defaultRoute := router.Group("/") {
defaultRoute.GET("/", func(c *gin.Context) {
c.String(200, "首页")
})
}
}路由B文件
package routes
import "github.com/gin-gonic/gin"
func BRoutesInit(router *gin.Engine)
{
defaultRoute := router.Group("/") {
defaultRoute.GET("/", func(c *gin.Context) {
c.String(200, "首页")
})
}
}main文件
func main() {
r := gin.Default()
//从main函数中引用路由文件中的函数,把路由实例传入
routes.AdminRoutesInit(r)
routes.ApiRoutesInit(r)
routes.DefaultRoutesInit(r)
r.Run(":8080")
}中间件
Gin框架允许开发者在处理请求的过程中,加入用户自己的钩子(Hook)函数。这个钩子函数就叫中间件,中间件适合处理一些公共的业务逻辑,比如登录认证、权限校验、数据分页、记录日志、耗时统计等
中间件
Gin中的中间件必须是一个HandlerFunc类型,其实就是一个参数为Context的函数
type HandlerFunc func(*Context)路由函数
以GET为例子,可以看到其第二个参数可以是多个HandlerFunc类型的值。前面我们只写一个处理函数
func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {
return xxxxx //省略
}多个处理函数,会按顺序执行【注意:相当于在每一个处理函数末尾加一个Next方法,后面会提到】
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func Processor1(context *gin.Context) {
fmt.Println("Processor1")
}
func Processor2(context *gin.Context) {
fmt.Println("Processor2")
}
func main() {
r := gin.Default()
r.GET("/user", Processor1, Processor2)
r.Run(":9000")
}
//Processor1
//Processor2Next
处理下一个HandlerFunc,处理完再回到当前的HandlerFunc
func Processor1(context *gin.Context) {
fmt.Println("进入 Processor1")
context.Next()
fmt.Println("退出 Processor1")
}
func Processor2(context *gin.Context) {
fmt.Println("进入 Processor2")
fmt.Println("退出 Processor2")
}输出
进入 Processor1
进入 Processor2
退出 Processor2
退出 Processor1Abort
不去处理下一个HandlerFunc,继续执行当前HandlerFunc
func Processor1(context *gin.Context) {
fmt.Println("进入 Processor1")
context.Next()
fmt.Println("退出 Processor1")
}
func Processor2(context *gin.Context) {
fmt.Println("进入 Processor2")
context.Abort()
fmt.Println("退出 Processor2")
}
func Processor3(context *gin.Context) {
fmt.Println("进入 Processor3")
fmt.Println("退出 Processor3")
}输出
进入 Processor1
进入 Processor2
退出 Processor2
退出 Processor1return
直接结束当前的HandlerFunc,返回上一个HandlerFunc的Next位置
func Processor1(context *gin.Context) {
fmt.Println("进入 Processor1")
context.Next()
fmt.Println("退出 Processor1")
}
func Processor2(context *gin.Context) {
fmt.Println("进入 Processor2")
return
fmt.Println("退出 Processor2")
}输出
进入 Processor1
进入 Processor2
退出 Processor1所有路由统一处理
一个个的给每个路由添加处理函数,太过于繁琐
func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes {
xxxx
}例子
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func Processor1(context *gin.Context) {
fmt.Println("进入 Processor1")
context.Next()
fmt.Println("退出 Processor1")
}
func Processor2(context *gin.Context) {
fmt.Println("进入 Processor2")
context.Abort()
fmt.Println("退出 Processor2")
}
func main() {
r := gin.Default()
r.Use(Processor1, Processor2)//统一添加到路由中,每个路由都会使用到
r.GET("/user")
r.GET("/book")
r.GET("/music")
r.Run(":9000")
}路由组添加处理器
不一定是所有路由请求,都经过处理函数,我们可以把一些路由请求编组,统一添加
r := gin.Default()
bookGroup := r.Group("/book", Processor1, Processor2)
{
bookGroup.GET("/index")
bookGroup.GET("/my")
}或者
bookGroup := r.Group("/book", Processor1, Processor2)
bookGroup.Use(Processor1,Processor2)多处理器传值
通过在Context上存储键值对,来达到传值的目的
func Processor1(context *gin.Context) {
fmt.Println("Processor1")
context.Set("name", "tom")
}
func Processor2(context *gin.Context) {
fmt.Println("Processor2")
value, ok := context.Get("name")
if !ok {
fmt.Println("没有name字段")
return
}
fmt.Println(value)
}输出
Processor1
Processor2
tom默认中间件
前面,一直使用的
r := gin.Default()其实就是,默认使用了Logger和Recovery中间件,其中:
Logger中间件将日志写入gin.DefaultWriter,即使配置了GIN_MODE=release。Recovery中间件会recover任何panic。如果有panic的话,会写入500响应码。
如果不想使用上面两个默认的中间件
r:=gin.New() //新建一个没有任何默认中间件的路由。注意
如果要在中间件中使用goroutine
当在中间件(HandlerFunc)中启动新的goroutine时,不能使用原始的上下文(c *gin.Context)作为goroutine函数的参数,必须使用其只读副本c.Copy()
r.GET("/", func(c *gin.Context) {
cCp := c.Copy()
go func() {
// 睡眠5s
time.Sleep(5 * time.Second)
// 这里使用你创建的副本
fmt.Println("Done! in path " + cCp.Request.URL.Path)
}()
c.String(200, "首页")
})GORM(新版V2)
简单来说就是Go语言的一个工具,直接使用工具提供的函数,来完成SQL操作(不用使用SQL语句)

数据库
以下都是以Mysql为例子,自行安装MySql
如果使用mysql命令提示找不到,记得配置环境变量
# 1.一般默认安装在 /usr/local/mysql/bin 这个路径下,找一下确定有bin目录
# 2.在.zshrc文件中添加环境变量
export PATH=$PATH:/usr/local/mysql/bin
# 3.重启文件生效
source .zshrc终端登陆mysql
mysql -uroot -p #-u后是用户名 ,-p是密码。执行后,会要求输入密码创建一个新的数据库(有的也叫schema)
mysql create database 数据库名查看所有数据库
show databases;GORM的约定
默认约定的规则,基本上都是可以用tag指定修改的,tag这部分放在后面讲解
默认表名和表字段名
默认:GORM 使用结构体名的蛇形命名的复数形式作为表名,使用结构体字段名的蛇形命名作为表字段
什么是蛇形命名?
- 对于字段名
UserInfo,其表字段名为user_infos(大写部分小写,并用下划线分隔) - 对于结构体名
ID,其表字段名为id(连续大写的部分,直接转成小写,不用短下划线分隔)
自定义:
表名的命名规则:下面一部分讲的open的第二个参数可以修改表名的命名默认规则
表字段名的命名规则:通过GORM提供的tag指定结构体字段创建的表名
gotype StuInfo struct { gorm.Model Name string `gorm:"column:my_name"` Age int Hobby string }- 对于字段名
默认使用
ID作为主键默认:GORM 会默认将结构体中名为
ID的字段, 设置为表的主键,且自增gotype User struct { ID string // 默认情况下,名为 `ID` 的字段会作为表的主键 Name string }自定义:也可以通过
gorm:"primaryKey"将其它字段设为主键go// 将 `UUID` 设为主键 type Animal struct { ID int64 UUID string `gorm:"primaryKey"` Name string Age int64 }默认情况下,整型
PrioritizedPrimaryField启用了AutoIncrement,要禁用它,您需要为整型字段关闭autoIncrement:gotype Product struct { CategoryID uint64 `gorm:"primaryKey;autoIncrement:false"` TypeID uint64 `gorm:"primaryKey;autoIncrement:false"` }时间戳追踪
如果定义的结构体中也出现了
CreatedAt、UpdatedAt字段默认:GORM会自动更新每一条记录的创建时间、更新时间
自定义:通过tag指定字段关闭更新
gotype User struct { CreatedAt time.Time `gorm:"autoCreateTime:false"` UpdatedAt time.Time `gorm:"autoUpdateTime:false"` }
配置GORM连接
前提:已经创建了名为gorm_class的数据库
结果:返回一个DB对象,通过操作这对象进行增删改查
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
)
func main() {
//1、写连接字符串,格式:用户名:密码@(ip:端口)/数据库名?
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
//2、open函数创建数据库对象,有两个参数,
// -第一个是mysql驱动配置,详情参见https://github.com/go-gorm/mysql
// -第二个是gorm的配置,详情参见https://gorm.io/zh_CN/docs/gorm_config.html
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
//默认为false,即开启事务。会在后面【事务】部分讲解
SkipDefaultTransaction: false,
//数据库表名命名规则
NamingStrategy: schema.NamingStrategy{
TablePrefix: "hdd_", //表名加hdd_前缀
SingularTable: false, //表名是否结尾加s
//这里表名就是hdd_users(注意结构体叫User)
},
DisableForeignKeyConstraintWhenMigrating: true,
})
//3、错误判断
if err != nil {
panic(err)
}
}配置连接池
gorm使用Go原生的database/sql维护连接池
通过DB方法获取*sql.db,可操作通过*sql.db设置数据库连接池的一些配置信息
mysqlDB, err := db.DB()
//最大连接数
mysqlDB.SetMaxOpenConns(500)
//最大空闲连接数
mysqlDB.SetMaxIdleConns(10)
//最大生命周期
mysqlDB.SetConnMaxLifetime(time.Hour)
//关闭数据库(对的,关闭数据库需要获取`*sql.db`,调用它的Close才能关闭)
mysqlDB.Close()数据库迁移
其实就是根据Go中定义的数据结构,创建对应的表结构
中文档地址:https://gorm.io/zh_CN/docs/migration.html 如果数据库已存在迁移指定的表:User结构某字段改名,表中会添加该新字段,原字段对应的表字段不会删除;结构体删除字段,表也不会删除该字段;
创建一个表
定义一个User结构体,下面用AutoMigrate、Migrator分别创建表(结构体字段必须大写)
type User struct {
Name string
Age int
Score int
}AutoMigrate自动创建数据库表
使用前面链接数据库返回的db对象(gorm.Open返回的),在这个数据库中,创建一个User结构体对应的数据库表结构
//自动创建表
db.AutoMigrate(&User{})根据约定会自动创建一个名为users的表(gorm.Open的第二个参数会影响默认约定的表名)
表字段:
name - longtext
age - bigint
score - bigint也可以在建立表结构体时,通过方法指定表名
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type User struct {
Name string
}
func (u User) TableName() string {
return "new_table" //指定表名 new_table
}
func main() {
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
DB, _ := gorm.Open(mysql.Open(dsn), &gorm.Config{})
DB.AutoMigrate(&User{})
}Migrator手动创建数据库表
想要配置迁移细节,使用Migrator函数,返回一个Migrator接口
m := db.Migrator()可在GoLand中查看源码Migrator接口中提供的函数,用这些函数我们可以手动创建表(或者其他表操作)
type Migrator interface {
// AutoMigrate
AutoMigrate(dst ...interface{}) error
// Database
CurrentDatabase() string
FullDataTypeOf(*schema.Field) clause.Expr
// Tables
CreateTable(dst ...interface{}) error
DropTable(dst ...interface{}) error
HasTable(dst interface{}) bool
RenameTable(oldName, newName interface{}) error
GetTables() (tableList []string, err error)
// Columns
AddColumn(dst interface{}, field string) error
DropColumn(dst interface{}, field string) error
AlterColumn(dst interface{}, field string) error
MigrateColumn(dst interface{}, field *schema.Field, columnType ColumnType) error
HasColumn(dst interface{}, field string) bool
RenameColumn(dst interface{}, oldName, field string) error
ColumnTypes(dst interface{}) ([]ColumnType, error)
// Views
CreateView(name string, option ViewOption) error
DropView(name string) error
// Constraints
CreateConstraint(dst interface{}, name string) error
DropConstraint(dst interface{}, name string) error
HasConstraint(dst interface{}, name string) bool
// Indexes
CreateIndex(dst interface{}, name string) error
DropIndex(dst interface{}, name string) error
HasIndex(dst interface{}, name string) bool
RenameIndex(dst interface{}, oldName, newName string) error
}例子:如果存在表就删除,如果不存在表就创建
m := db.Migrator()
//含义:
if m.HasTable(&User{}) {
//m.DropTable(&User{})这个函数是删除表
m.RenameTable(&User{}, &UserV2{}) //将表重命名为第二个字段。可以是字符串直接指定表名,但是Go就失去了对这个表的控制了,所以一般指定一个新的结构体,新结构体UserV2就对应了数据库里的那张表
} else {
m.CreateTable(&User{})
}GORM Model
GORM把一些常用的字段单独抽出来,定义了一个结构体gorm.Model,它最大的好处是GORM的钩子会自动维护这几个字段,不用开发者处理,就会自动创建ID、记录创建时间、记录更新时间、记录删除时间
type Model struct {
ID uint `gorm:"primarykey"` //字段名是ID,默认做为主键,且自增
CreatedAt time.Time //创建时间
UpdatedAt time.Time //更新时间
DeletedAt DeletedAt `gorm:"index"` //删除时间,类型比较特殊,下面会补充
}我们可以将gorm.Model嵌入到自己的结构体里(注意需要匿名嵌入。如果用命名嵌入,自动迁移时,就被当成另一个表了)
type StuInfo struct {
gorm.Model//匿名嵌入
Name string
Age int
Hobby string
}gorm.Model默认ID做为主键,也可以通过tag( gorm:"primaryKey" )将其它字段设为主键
// 将 `UUID` 设为主键
type Animal struct {
ID int64
UUID string `gorm:"primaryKey"`
Name string
Age int64
}默认自动填充Model里的所有字段,如果不使用自动填充的Model字段,手动指定(字段名是Model)
s:=StuInfo{
Model:gorm.Model{
ID:1
},
Name:"jack",
Age:1,
Hobby:"football",
}补充下
DeletedAt字段是一个DeletedAt类型,也就是sql.NullTime类型
type DeletedAt sql.NullTime也就是下面这个结构体
type NullTime struct {
Time time.Time
Valid bool // Valid is true if Time is not NULL
}Go类型与数据库类型
type Node struct {
gorm.Model
time time.Time
Bool bool
Int int
Uint uint
Int8 int8
Uint8 uint8
Byte byte
Int32 int32
Uint32 uint32
Int64 int64
Uint64 uint64
Float32 float32
Float64 float64
String string
Rune rune
}对应的数据库表类型
`id` bigint unsigned AUTO_INCREMENT,
`created_at` datetime(3) NULL,
`updated_at` datetime(3) NULL,
`deleted_at` datetime(3) NULL,
`time` datetime(3),
`bool` boolean,
`int` bigint,
`uint` bigint unsigned,
`int8` tinyint,
`uint8` tinyint unsigned,
`byte` tinyint unsigned,
`int32` int,
`uint32` int unsigned,
`int64` bigint,
`uint64` bigint unsigned,
`float32` float,
`float64` double,
`string` longtext
`rune` int,上面的是GO中的类型对应数据库的类型
实际在生产环境更多的是先申请线上工单,确定数据库类型,所以我们更应该清楚数据库类型对应哪些Go中的类型,有些数据库类型没有对应的Go类型,但是标准库sql为我们提供了一些内置的类型
如果,我们读取数据的name字段,映射到结构体的Name字段,可是name可以能为字符串或空。这时候就要用
sql.NullString类型了。下面的类型都是兼容读取为空的情况
sql.NullString
sql.NullInt16、sql.NullInt32、sql.NullInt64
sql.NullByte
sql.NullFloat64
sql.NullBool
sql.NullTime以sql.NullString为例子,其定义为
type NullString struct {
String string
Valid bool // Valid is true if String is not NULL
}所以,我们可以
if Name.Valid {
// Name字段有值,继续处理
}增删改查
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
"time"
)
type User struct {
Name string
Age int
Score int
gorm.Model
}
//
//type UserV2 struct {
// Name string
//}
func main() {
//1、前提:安装了数据库+有gorm_class这个schema。
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
//open函数有两个参数,
// -第一个是mysql驱动配置,详情参见https://github.com/go-gorm/mysql
// -第二个是gorm的配置,详情参见https://gorm.io/zh_CN/docs/gorm_config.html
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
SkipDefaultTransaction: false,
NamingStrategy: schema.NamingStrategy{
TablePrefix: "hdd_", // table name prefix, table for `User` would be `t_users`
SingularTable: false, // use singular table name, table for `User` would be `user` with this option enabled
},
DisableForeignKeyConstraintWhenMigrating: true,
})
if err != nil {
panic(err)
}
//2、连接池。gorm使用Go原生的database/sql维护连接池
mysqlDB, err := db.DB() //通过DB方法获取*sql.db
mysqlDB.SetMaxOpenConns(500)
mysqlDB.SetMaxIdleConns(10)
mysqlDB.SetConnMaxLifetime(time.Hour)
defer mysqlDB.Close()
//3、将Go数据结构迁移到数据库中(创建一个表,将表和结构体建立映射)
//文档地址:https://gorm.io/zh_CN/docs/migration.html
//如果已存在数据库表规则:User结构某字段改名,表中会添加该新字段,原字段对应的表字段不会删除;结构体删除字段,表也不会删除该字段;
//AutoMigrate自动创建创建
db.AutoMigrate(&User{})
//想要配置迁移细节,使用Migrator,返回一个Migrator接口。可查看源码Migrator接口中提供的函数签名
//m := db.Migrator()
//含义:如果存在就删除,如果不存在就创建
//if m.HasTable(&User{}) {
// //m.DropTable(&User{})删除表
// m.RenameTable(&User{}, &UserV2{}) //将表重命名为第二个字段。可以是字符串直接指定表名,但是Go就失去了对这个表的控制了,所以一般指定一个新的结构体
//} else {
// m.CreateTable(&User{})
//}
//4、插入数据
//4-1 插入一条数据,使用结构体指针
//if err := db.Create(&User{
// Name: "jack",
// Age: 20,
//}).Error; err != nil {
// fmt.Printf("插入数据出错%v\n", err)
//}
//4-2 插入多条数据,使用切片
//if err := db.Create(&[]User{
// {Name: "jhon", Age: 20},
// {Name: "tom", Age: 21},
//}).Error; err != nil {
// fmt.Printf("插入数据出错%v\n", err)
//}
//4-3 Select指定传入Create的数据字段哪些需要插入 ;Omit指定传入Create的数据字段哪些需要忽略
//if err := db.Select("Name").Create(&User{
// Name: "jackv2",
// Age: 20,
//}).Error; err != nil {
// fmt.Printf("插入数据出错%v\n", err)
//}
//5、查询 (First、Last、Take如果查不到数据就是错误,即ErrRecordNotFound,而Find找不到也不会报错)
//查询会将结果放入查询函数(First、Last、Take、Find)的参数中(一个结构体指针),这里有一个隐藏的知识点,查询函数会在schema中找到参数这个空结构体对应的表。如果找不到就需要先用Model指定下是哪个表
//5-1 First、Last,按照主键排序(没有主键,则按照第一个字段进行排序),然后查询第一个、最后一个数据。
//注意:函数 db.Model(xxx) 用于指定执行操作的表,这里Model指定了当前查询的是User对应的数据库表。由于这里查询函数指定了入参&u,GORM会自动推导用户查询的为User对应的表,所以可以省略db.Model(xxx)。
//推断失败需要手动指定表的情况,例如结构体User对应表名users,但是First入参使用了NewUser结构体类型接收,这时候GORM会去找new_users表,而不是users表
//var u User
//if err := db.Model(&User{}).Where("name=?", "jack3").First(&u).Error; err != nil {
// if errors.Is(err, gorm.ErrRecordNotFound) {
// fmt.Println("查找不到")
// return
// } else {
// fmt.Println("查询错误,err:", err)
// return
// }
//}
//fmt.Printf("查询的数据:%#v\n", u)
//5-2 Take 查表内的第一条数据(不必排序)
//var u User
//db.Take(&u)
//fmt.Printf("查询的数据:%#v\n", u)
//5-3 Find查询多条数据(不设置查询条件,就把整个表格查出来了)
//var uList []User
//db.Find(&uList)
//fmt.Printf("查询的数据:%#v\n", uList)
//5-4 查询条件(以First例子,添加查询条件)
//5-4-1 Where函数——字符串参数
//var u User
//db.Where("name=?", "tom").First(&u)
//fmt.Printf("查询的数据:%#v\n", u)
//5-4-2 Where函数——结构体参数
//var u User
//db.Where(User{Name: "tom"}).First(&u)
//fmt.Printf("查询的数据:%#v\n", u)
//5-4-3 Where函数——map参数
//var u User
//db.Where(map[string]interface{}{
// "name": "tom",
//}).First(&u)
//fmt.Printf("查询的数据:%#v\n", u)
//5-4-4 内联查询,即不使用Where函数,可以直接将字符串、结构体、map作为参数传入
//var u User
//db.First(&u, "name=?", "tom")
//fmt.Printf("查询的数据:%#v\n", u)
//5-4-4 内联查询还有一个用法,查询主键值是1的记录
//db.First(&u, 1)
//5-5 Or查询条件,参数与Where相同包括:字符串、结构体、map
//5-6 Not查询条件,参数包括:字符串、结构体、map,还可以是切片
//var u User
//db.Not([]int64{1, 2, 3}).First(&u) //主键不在{1、2、3}的集合里
//fmt.Printf("查询的数据:%#v\n", u)
//5-7 Order查询条件.desc从大到小,aesc从小到大,默认aesc
//var u []User
//db.Order("age desc,score").Find(&u) //如果多个字段排序,就用逗号分隔
//fmt.Printf("查询的数据:%#v\n", u)
//5-8 Limit限制返回几条数据,Offset表示查询结果跳过几条数据
//var u []User
//db.Limit(3).Find(&u)
//fmt.Printf("查询的数据:%#v\n", u)
//db.Offset(3).Find(&u)
//fmt.Printf("查询的数据:%#v\n", u)
//5-9 Select指定查询结果的某些字段,Omit忽略查询结果中的某些字段
//db.Select("name", "age").Find(&u)
//SELECT name, age FROM users;
//5-10 智能查询(如果多次查询,每次都使用Select指定要哪些字段,有些臃肿)
//type newUser struct {
// Name string
// Age int
//}
//var nu []newUser
//db.Model(&User{}).Find(&nu) //必须使Model指定查询的表,否则就回去查找new_users这个表了(我这个例子,设置了TablePrefix:"hdd_"这个配置,所以会去找hdd_new_users这个表)
//fmt.Printf("查询的数据:%#v\n", nu) //查询的数据:main.newUser{Name:"jack", Age:20}
//6、更新 (要么先查询后,更新查询的结果;要么必须指定where条件才能更新符合条件的数据)
//6-1、save更新数据(无论如何都会更新,即使是零值也会更新到数据库中)
//var uList []User
//res := db.Find(&uList)
//
//for key := range uList {
// uList[key].Age = 0
//}
//res.Save(&uList)
//6-2、updates
//6-2-1 参数为结构体(如果某字段是该类型的零值,则不更新该字段)
//var uList []User
//db.First(&uList).Updates(User{
// Name: "",
// Age: 0,
//})
//6-2-2 参数为Map(可以更新零值)
//var uList []User
//db.First(&uList).Updates(map[string]interface{}{
// "name": "", //map的key需要是数据库的字段名name,不是结构体名Name
// "age": 0,
//})
//6-3、update 只更新选择的字段
//var uList []User
//db.First(&uList).Update("name", "jack")
//7、删除(要么先查询后,再删除查询的结果;要么必须指定where条件才能删除其中符合条件的数据)
//7-1、删除(删除是软删除;删除的数据不会放在uList中,这里的uList只是指代删除的结构)
//var uList []User //这里使用var uList User也可以的
//db.Where("name=?", "jhon").Delete(&uList)
//7-2、物理删除
//var uList []User
//db.Unscoped().Where("name=?", "").Delete(&uList)
//8、原生SQL语句,Raw参数是sql语句,Scan执行
//var uList []User //这里使用var uList User也可以的
//db.Raw("select * from hdd_users where name=?", "jhon").Scan(&uList)
//fmt.Printf("%v\n", uList)
}where
where的占位符形式。第一个参数中的问号就是占位符,后面的参数就是占位符的值(类似于printf的用法)
//等于
Where("name = ?", "h1")
//不等于
Where("name <> ?", "h1")
//大于
Where("updated_at > ?", lastWeek)
//小于
Where("updated_at < ?", lastWeek)
//为null和不为空
Where("name IS NULL")
Where("name IS NOT NULL")
//范围name=h1或name=h2
Where("name IN ?", []string{"h1", "h2"})
//模糊匹配 %代表零个或多个
Where("name LIKE ?", "%王%")
//且
Where("name = ? AND age >= ?", "h1", "22")
//或
Where("name = ? OR age = ?", "h1", "22")
//between and
Where("created_at BETWEEN ? AND ?", lastWeek, today)
//not between and
Where("created_at NOT BETWEEN ? AND ?", lastWeek, today)定义删除字段
自定义一个删除时会使用软删除的字段
使用 1 / 0 作为 delete flag
type User struct {
ID uint
Name string
IsDel soft_delete.DeletedAt `gorm:"softDelete:flag"`
}
// 查询
SELECT * FROM users WHERE is_del = 0;
// 删除
UPDATE users SET is_del = 1 WHERE ID = 1;临时表
创建一个临时表u,用于查询
db.Table("(?) as u", db.Model(&User{}).Select("name", "age")).Where("age = ?", 18).Find(&User{})
// SELECT * FROM (SELECT `name`,`age` FROM `users`) as u WHERE `age` = 18GORM Tag(后续补充)
表字段属性相关tag
通过给结构体添加gorm的tag,来指定数据库字段的属性
| 结构体标记(Tag) | 描述 |
|---|---|
| Column | 指定列名 |
| Type | 指定列数据类型 |
| Size | 指定列大小, 默认值255 |
| PRIMARY_KEY | 将列指定为主键 |
| UNIQUE | 将列指定为唯一 |
| DEFAULT | 指定列默认值 |
| PRECISION | 指定列精度 |
| NOT NULL | 将列指定为非 NULL |
| AUTO_INCREMENT | 指定列是否为自增类型 |
| INDEX | 创建具有或不带名称的索引, 如果多个索引同名则创建复合索引 |
| UNIQUE_INDEX | 和 INDEX 类似,只不过创建的是唯一索引 |
| EMBEDDED | 将结构设置为嵌入 |
| EMBEDDED_PREFIX | 设置嵌入结构的前缀 |
| - | 忽略此字段 |
综上,我们可以将gorm.Model嵌入自己的结构体中,同时指定一些tag
type User struct {
gorm.Model
Name string
Age sql.NullInt64 //空值
Birthday *time.Time //时间类型
Email string `gorm:"type:varchar(100);unique_index"`
Role string `gorm:"size:255"` // 设置字段大小为255
MemberNumber *string `gorm:"unique;not null"` // 设置会员号(member number)唯一并且不为空
Num int `gorm:"AUTO_INCREMENT"` // 设置 num 为自增类型
Address string `gorm:"index:addr"` // 给address字段创建名为addr的索引
IgnoreMe int `gorm:"-"` // 忽略本字段
}表关联tag
| 结构体标记(Tag) | 描述 |
|---|---|
| MANY2MANY | 指定连接表 |
| FOREIGNKEY | 设置外键 |
| ASSOCIATION_FOREIGNKEY | 设置关联外键 |
| POLYMORPHIC | 指定多态类型 |
| POLYMORPHIC_VALUE | 指定多态值 |
| JOINTABLE_FOREIGNKEY | 指定连接表的外键 |
| ASSOCIATION_JOINTABLE_FOREIGNKEY | 指定连接表的关联外键 |
| SAVE_ASSOCIATIONS | 是否自动完成 save 的相关操作 |
| ASSOCIATION_AUTOUPDATE | 是否自动完成 update 的相关操作 |
| ASSOCIATION_AUTOCREATE | 是否自动完成 create 的相关操作 |
| ASSOCIATION_SAVE_REFERENCE | 是否自动完成引用的 save 的相关操作 |
| PRELOAD | 是否自动完成预加载的相关操作 |
数据库实关系
数据库实体关系分为一对一关系、一对多关系、多对多关系
可以参考下面的这篇文章,了解关系以及如何从ER图(概念模型)转化为逻辑模型
https://blog.csdn.net/m0_67316550/article/details/124288116
一对一关系
数据库实体关系中的一对一关系,可以将关系的属性归属到两个实体的任意一个上。
所以,GORM中把一对一关系中,两个实体结构体的关系,分成了 belongs to 和has one两种
下面以学校与校长的关系来举例子:
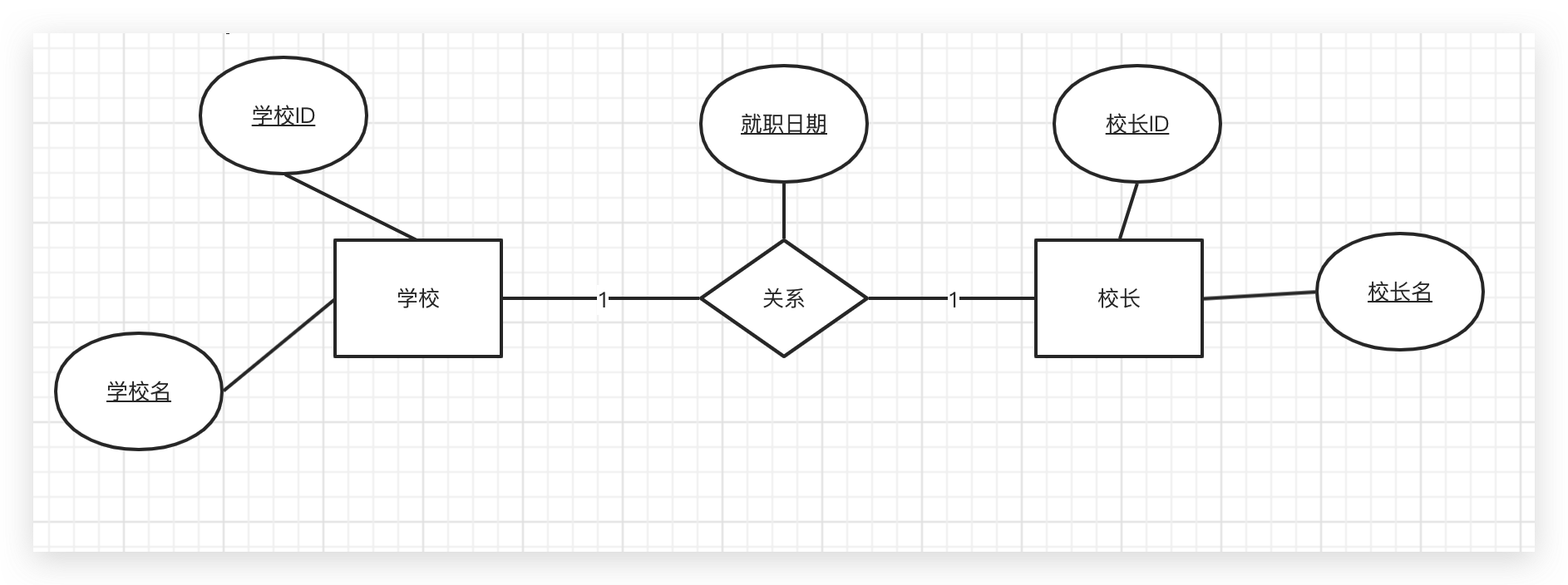
数据库知识:一对一关系转换为表结构时,可以将一方主键放到到另一方作为外键
使用belongs to和has one 两种方式,区别就是把A的主键放到B,还是把B的主键放到A
belongs to
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type School struct {
gorm.Model
Name string
}
type HeadMaster struct {
gorm.Model
Name string
SchoolID uint //名字必须 <对方实体的结构体名字+其主键名>
School School //必须使用命名方式,匿名方式就直接把School的字段合并到HeadMaster中了
}
func main() {
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
SkipDefaultTransaction: false,
DisableForeignKeyConstraintWhenMigrating: true,
})
if err != nil {
panic(err)
}
//迁移时,只迁移HeadMaster就会同时创建两个表
db.AutoMigrate(&HeadMaster{}) //参照表
//创建实例的时候,不用手动处理校长表中学校外键,GORM会自动填写这个外键值
school := School{
Model: gorm.Model{
ID: 2,
},
Name: "希望小学",
}
master := HeadMaster{
Model: gorm.Model{
ID: 1,
},
Name: "校长一号",
School: school,
}
//校长结构中是两个表的全量数据
db.Create(&master)
}校长表

学校表

has one
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type School struct {
gorm.Model
Name string
HeadMasterID uint //名字必须 <对方实体的结构体名字+其主键名>
}
type HeadMaster struct {
gorm.Model
Name string
School School //必须使用命名方式,匿名方式就直接把School的字段合并到HeadMaster中了
}
func main() {
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
SkipDefaultTransaction: false,
DisableForeignKeyConstraintWhenMigrating: true,
})
if err != nil {
panic(err)
}
//迁移时,必须指定School、HeadMaster两个表
db.AutoMigrate(&School{}, &HeadMaster{})
//创建实例的时候,不用手动处理校长表中学校外键,GORM会自动填写这个外键值
school := School{
Model: gorm.Model{
ID: 2,
},
Name: "希望小学",
}
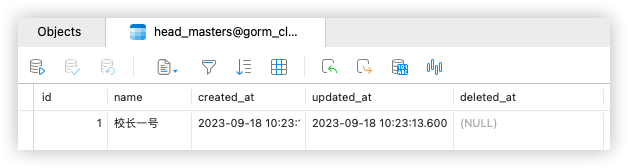
master := HeadMaster{
Model: gorm.Model{
ID: 1,
},
Name: "校长一号",
School: school,
}
//校长结构中是两个表的全量数据
db.Create(&master)
}校长表
学校表

手动维护两个表的一对一关系
中文文档:https://gorm.io/zh_CN/docs/associations.html
前面的两种情况都是GORM自动的创建两个有外键关系的表,我们也可以自己手动去维护两个表的关系
belongs to
主体是校长,Model创建一个模型,Association关联(取出)一个字段名,就是追加学校表到这个关联的字段中
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
)
type School struct {
gorm.Model
Name string
}
type HeadMaster struct {
gorm.Model
Name string
SchoolID uint //名字必须 <对方实体的结构体名字+其主键名>
School School //必须使用命名方式,匿名方式就直接把School的字段合并到HeadMaster中了
}
func main() {
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
SkipDefaultTransaction: false,
NamingStrategy: schema.NamingStrategy{
TablePrefix: "relative_",
SingularTable: false,
},
DisableForeignKeyConstraintWhenMigrating: true,
})
if err != nil {
panic(err)
}
//迁移时,只迁移HeadMaster就会同时创建两个表
db.AutoMigrate(&HeadMaster{})
school := School{
Model: gorm.Model{
ID: 2,
},
}
newSchool := School{
Model: gorm.Model{
ID: 3,
},
}
master := HeadMaster{
Model: gorm.Model{
ID: 1,
},
}
//Model创建一个校长模型,Association关联(取出)校长模型的School字段的内容,就是追加学校表到这个关联的School字段中
//指定校长表ID为1的这条数据的School这个字段,设置为学校表ID为2的这条数据的某个字段(由校长结构体的SchoolID指定了外键为学校表的ID字段)
//注意即使学校表里不存在ID为2的数据,school_id字段也会设置为2
db.Model(&master).Association("School").Append(&school) //【school_id字段为2】
//更换校长表ID为1的这条数据的的School这个字段为newSchool这条记录
db.Model(&master).Association("School").Replace(&school, &newSchool)//【school_id字段为3】
//清除校长表ID为1的这条数据的School这个字段(清除外键的数据)
db.Model(&master).Association("School").Clear()//【school_id字段为2】
}has to
主体是学校
db.Model(&school).Association("HeadMaster").Append(&master)
db.Model(&school).Association("HeadMaster").Replace(&master, &newMaster)//【school_id字段为3】
db.Model(&school).Association("HeadMaster").Clear()//【school_id字段为2】多对一关系
一个学校有多个学生,一个学生只属于一个学校
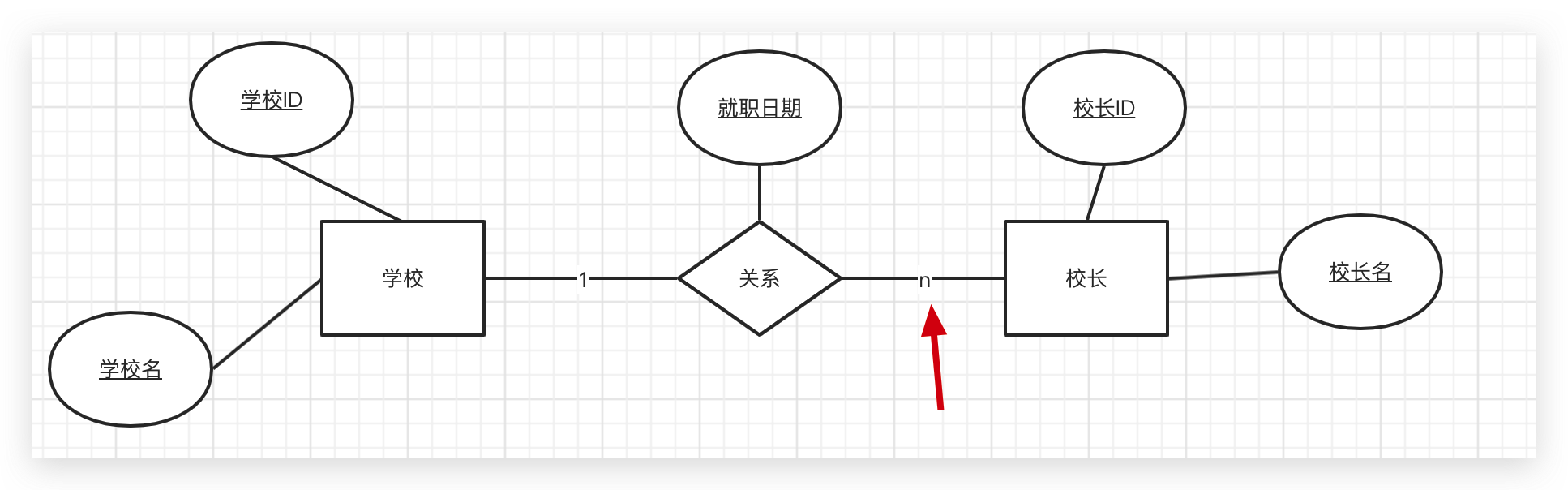
数据库知识:数据库<1:n>关系,转换为表结构,应该将1端的主键,作为外键放入n端。
所以,学生表应该包含学校ID作为外键,GORM的两种写法,其实必须有这个规则
即Student结构体包含SchoolID,唯一区别是:
- School包含Student。 仅仅需要实例化School,就可以插入两个表的数据
- Student包含School。 仅仅需要实例化Student,就可以插入两个表的数据
方式一:
GORM称为has many,其实就是has one的学校结构体的HeadMaster字段变为了切片
//学校
type School struct {
gorm.Model
Name string
Student []Student //has many 只有这里变成了切片
}
//学生
type Student struct {
gorm.Model
Name string
SchoolID uint //名字必须 <对方实体的结构体名字+其主键名>
}
db.AutoMigrate(&School{}, &Student{})方式二:(我更习惯使用这种方式)
//学校
type School struct {
gorm.Model
Name string
}
//学生
type Student struct {
gorm.Model
Name string
SchoolID uint //名字必须 <对方实体的结构体名字+其主键名>
School School
}
db.AutoMigrate(&Student{})生成的表结构中,students表中包含了外键school_id
指定外键名
//学校
type School struct {
gorm.Model
Name string
Student []Student `gorm:"foreignKey:FrID"`
}
//学生
type Student struct {
gorm.Model
Name string
FrID uint //名字必须 <对方实体的结构体名字+其主键名>
}//学校
type School struct {
gorm.Model
Name string
}
//学生
type Student struct {
gorm.Model
Name string
FrID uint //名字不想用 <对方实体的结构体名字+其主键名>,可以通过tag指定
School School `gorm:"foreignKey:FrID"`
}生成的表结构中,students表中包含了外键fr_id
两种方式的区别
当做多表查询时
- 方式一查询School表结构时,可以使用预加载查询出相关的Student结构
- 方式二查询Student表结构时,可以使用预加载查询出相关的School结构
预加载
中文文档:https://gorm.io/zh_CN/docs/preload.html
还是之前的例子(has many)
type School struct {
gorm.Model
Name string
HeadMasters []HeadMaster
}
type HeadMaster struct {
gorm.Model
Name string
SchoolID uint
}查询School中ID为2的数据,实际查询结构是查出来HeadMasters字段中的子字段都是零值
db.First(&school, 2)这时候就要使用预加载(Preload),参数传入字符串HeadMasters,就能把关联的HeadMasters字段信息一起查出来
例子
预加载
var school School
db.Preload("HeadMasters").First(&school, 2)
fmt.Printf("%#v\n", school)查询带条件的预加载(限制预加载的HeadMasters字段的条件为name是校长2的数据)
var school School
db.Preload("HeadMasters", "name=?", "校长2").First(&school, 2)
fmt.Printf("%#v\n", school)自定义预加载
var school School
db.Preload("HeadMasters", func(db *gorm.DB) *gorm.DB {
return db.Where("name=?", "校长2") //在函数中继续删选条件,参数db指得是HeadMasters这层里的数据
}).First(&school, 2)
fmt.Printf("%#v\n", school)嵌套的预加载
再增加一个关系,即校长和书的关系。一个学校有多个校长,一个校长有多本书。
多个Preload函数没有先后顺序
如果Preload有条件时,只能筛选自己Preload这个层级的数据,然后再结构中继续筛选下一个Preload层级的数据
type School struct {
gorm.Model
Name string
HeadMasters []HeadMaster
}
type HeadMaster struct {
gorm.Model
Name string
SchoolID uint
Books []Book
}
type Book struct {
gorm.Model
Name string
HeadMasterID uint
}
var school School
db.Preload("HeadMasters").Preload("HeadMasters.Books").First(&school, 2)
fmt.Printf("%#v\n", school) //查询的数据包含三个表的数据join预加载
还有一个预加载的关键字是join,这个关键字只能适用于一对一的关系,例如: has one, belongs to
join不能添加筛选条件,可以继续使用Where、Order等函数操作数据
多对对关系
AutoMigrate生成表
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
)
type Teacher struct {
gorm.Model
Name string
Students []Student `gorm:"many2many:teacher_student"`
}
type Student struct {
gorm.Model
Name string
Teachers []Teacher `gorm:"many2many:teacher_student"`
}
func main() {
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
SkipDefaultTransaction: false,
NamingStrategy: schema.NamingStrategy{
TablePrefix: "m2m_",
SingularTable: false,
},
DisableForeignKeyConstraintWhenMigrating: true,
})
if err != nil {
panic(err)
}
//迁移时,只迁移Teacher、Student、关系表
db.AutoMigrate(&Teacher{}, &Student{})
}生成的表

自动维护多对多数据
插入数据,会自动处理m2m_teacher_student关系表的数据
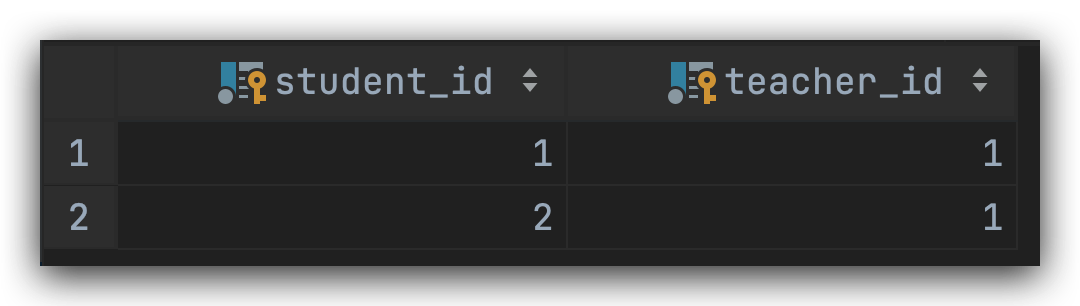
s1 := Student{
Model: gorm.Model{
ID: 1,
},
Name: "学生1",
}
s2 := Student{
Model: gorm.Model{
ID: 2,
},
Name: "学生2",
}
t1 := Teacher{
Model: gorm.Model{
ID: 1,
},
Name: "教师1",
Students: []Student{ //自动维护数据的关键在这里,这里可表明两个表的关系
s1, s2,
},
}
db.Create(&t1)表数据


手动维护多对多数据
s1 := Student{
Model: gorm.Model{
ID: 1,
},
Name: "学生1",
}
s2 := Student{
Model: gorm.Model{
ID: 2,
},
Name: "学生2",
}
t1 := Teacher{
Model: gorm.Model{
ID: 1,
},
Name: "教师1",
}
//选取ID为1的教师生成模型,取Students字段,在这个字段中追加s1,s2关系
db.Model(&t1).Association("Students").Append(&s1, &s2)结果m2m_teacher_student表,执行后,就会填写好教师学生关系表

//选取ID为1的教师生成模型,取Students字段,清空所有t1的关系,然后再加上s1这个关系
db.Model(&t1).Association("Students").Replace(&s1)//选取ID为1的教师生成模型,取Students字段,清空所有t1的关系
db.Model(&t1).Association("Students").Clear()
//仅清除t1与s1的关联关系
db.Model(&t1).Association("Students").Delete(&s1)查询多对多的关联数据
使用预加载,取出所有数据
var t Teacher
db.Preload("Students").Find(&t, 1)
fmt.Printf("%#v\n", t)
//使用预加载,查询的ID为1的教师数据中,还携带关联的两个学生数据
//main.Teacher{Model:gorm.Model{ID:0x1, CreatedAt:time.Date(2022, time.August, 2, 0, 53, 27, 400000000, time.Local), UpdatedAt:time.Date(2022, time.August, 2, 0, 53, 27, 400000000, time.Local), DeletedAt:gorm.DeletedAt{Time:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Valid:false}}, Name:"教师1", Students:[]main.Student{main.Student{Model:gorm.Model{ID:0x1, CreatedAt:time.Date(2022, time.Augt, 2, 0, 53, 27, 403000000, time.Local), UpdatedAt:time.Date(2022, time.August, 2, 0, 53, 27, 403000000, time.Local), DeletedAt:gorm.DeletedAt{Time:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Valid:false}}, Name:"学生1", Teachers:[]main.Teacher(nil)}, main.Student{Model:gorm.Model{ID:0x2, CreatedAt:time.Date(2022, time.August, 2, 0, 53, 27, 403000000, time.Local), UpdatedAt:time.Date(2022time.August, 2, 0, 53, 27, 403000000, time.Local), DeletedAt:gorm.DeletedAt{Time:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Valid:false}}, Name:"学生2", Teachers:[]main.Teacher(nil)}}}使用Association,只取出来学生数据
var s []Student
//指定模型为ID为1的教师,取Students字段数据,Find就是在这个字段中的数据中搜索
db.Model(&Teacher{Model: gorm.Model{ID: 1}}).Association("Students").Find(&s)
fmt.Printf("%#v\n", s)
//[]main.Student{main.Student{Model:gorm.Model{ID:0x1, CreatedAt:time.Date(2022, time.August, 2, 0, 53, 27, 403000000, time.Local), UpdatedAt:time.Date(2022, time.August, 2, 0, 53, 27, 403000000, time.Local), DeletedAt:gorm.DeletedAt{Time:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Valid:false}}, Name:"学生1", Teachers:[]main.Teacher(nil)}, main.Student{Model:gorm.Model{ID:0x2, CreatedAt:ti.Date(2022, time.August, 2, 0, 53, 27, 403000000, time.Local), UpdatedAt:time.Date(2022, time.August, 2, 0, 53, 27, 403000000, time.Local), DeletedAt:gorm.DeletedAt{Time:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Valid:false}}, Name:"学生2", Teachers:[]main.Teacher(nil)}}事务
官方中文文档:https://gorm.io/zh_CN/docs/transactions.html
这部分官方文档很清楚,暂时略过了
自定义类型
官方中文文档:https://gorm.io/zh_CN/docs/data_types.html
为自定义的字段定义Value、Scan方法。
例子1
将一个结构体以JSON的格式写入数据库,读出时放到对应的结构体中
package main
import (
"database/sql/driver"
"encoding/json"
"errors"
"fmt"
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
)
type CUser struct {
gorm.Model
Name string
Info CInfo
}
type CInfo struct {
Score int
Age int
}
//Value 写入自定义类型到数据库.u是Go中类型,driver.Value是将Go中的类型转化为后的值,并写入数据
func (c CInfo) Value() (driver.Value, error) {
str, err := json.Marshal(c)
if err != nil {
return nil, errors.New("不匹配的数据类型")
}
return str, nil
}
//Scan 读取数据库字段,转化为Go中的类型.将value转化为Go中的结构后,并写入u
func (c *CInfo) Scan(value interface{}) error {
str, ok := value.([]byte)
if !ok {
return nil
}
json.Unmarshal(str, c)
return nil
}
func main() {
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
SkipDefaultTransaction: false,
NamingStrategy: schema.NamingStrategy{
TablePrefix: "test_",
SingularTable: false,
},
DisableForeignKeyConstraintWhenMigrating: true,
})
if err != nil {
panic(err)
}
db.AutoMigrate(&CUser{})
//1、创建
//db.Create(&CUser{
// Name: "frist",
// Info: CInfo{
// Score: 100,
// Age: 18,
// },
//})
//2、查询
var c CUser
db.First(&c)
fmt.Printf("%#v\n", c)
}
例子2
将一个切片以逗号连接的字符串格式写入数据库,读出时放到对应的切片变量中

package main
import (
"database/sql/driver"
"errors"
"fmt"
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
"strings"
)
type CUser struct {
gorm.Model
Name string
Info Args
}
type Args []string
//Value 写入自定义类型到数据库.u是Go中类型,driver.Value是将Go中的类型转化为后的值,并写入数据
func (a Args) Value() (driver.Value, error) {
if len(a) > 0 {
resStr := a[0]
for _, value := range a[1:] {
resStr += "," + value
}
return resStr, nil
}
return "", nil
}
//Scan 读取数据库字段,转化为Go中的类型.将value转化为Go中的结构后,并写入u
func (a *Args) Scan(value interface{}) error {
str, ok := value.([]byte)
if !ok {
return errors.New("不匹配的数据类型")
}
*a = strings.Split(string(str), ",") //注意这里的*用法,a已经是指针类型了,在加星号就是该内存地址中的值,这个值是[]string类型。注意这里就不是Args类型了
return nil
}
func main() {
dsn := "root:hedaodao@(127.0.0.1:3306)/gorm_class?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
SkipDefaultTransaction: false,
NamingStrategy: schema.NamingStrategy{
TablePrefix: "test_",
SingularTable: false,
},
DisableForeignKeyConstraintWhenMigrating: true,
})
if err != nil {
panic(err)
}
//迁移时,只迁移HeadMaster就会同时创建两个表
db.AutoMigrate(&CUser{})
//db.Create(&CUser{
// Name: "frist",
// Info: Args{
// "1",
// "2",
// },
//})
var c CUser
db.First(&c)
fmt.Printf("%#v\n", c.Info) //main.Args{"1", "2"}
}已经实现的value/Scan
下面的【GORM忽略零值】就是使用已经实现的value/Scan
GORM忽略零值
1.插入时
不插入Name字段数据,就走默认值
type StuInfo struct {
Name string `gorm:"default:未知"`
Age int
}
//---插入数据
student := &StuInfo{
Age: 18,
}
db.Create(&student)如果插入零值(即,空字符串),默认零值会被忽略。所以,也会走默认值
这个情况就比较不合理,因为有些时候我们需要插入的是零值,所以需要特殊处理下
//---插入数据
student := &StuInfo{
Name:""
Age: 18,
}
db.Create(&student)使用Scann/Value,将Name定义为sql.NullString类型
type StuInfo struct {
Name sql.NullString `gorm:"default:未知"`
Age int
}
student := &StuInfo{
Name: sql.NullString{String: "", Valid: true},//Valid为true,则代表String字段的值不是Null,插入String字段的值。如果是false,则插入Null
Age: 18,
}2.查询、更新、删除
同样的,查询、更新、删除都会忽略零值的字段
比如查询年龄为0的记录时,GORM会忽略这个查询条件
3.总结
所以,比较推荐将数据定义为 sql.Nullxxxx
type StuInfo struct {
Name sql.NullString `gorm:"default:未知"`
Age sql.NullInt64
}Scope
将常用的操作封装成函数,可以方便的调用
官网的例子
func AmountGreaterThan1000(db *gorm.DB) *gorm.DB {
return db.Where("amount > ?", 1000)
}
func PaidWithCreditCard(db *gorm.DB) *gorm.DB {
return db.Where("pay_mode_sign = ?", "C")
}
func PaidWithCod(db *gorm.DB) *gorm.DB {
return db.Where("pay_mode_sign = ?", "C")
}
func OrderStatus(status []string) func (db *gorm.DB) *gorm.DB {
return func (db *gorm.DB) *gorm.DB {
return db.Where("status IN (?)", status)
}
}
db.Scopes(AmountGreaterThan1000, PaidWithCreditCard).Find(&orders)
// 查找所有金额大于 1000 的信用卡订单
db.Scopes(AmountGreaterThan1000, PaidWithCod).Find(&orders)
// 查找所有金额大于 1000 的 COD 订单
db.Scopes(AmountGreaterThan1000, OrderStatus([]string{"paid", "shipped"})).Find(&orders)
// 查找所有金额大于1000 的已付款或已发货订单Hooks
更新、删除等操作触发前会触发的钩子函数
场景:
用户插入密码、修改密码时,需要触发钩子函数来进行加密存储
其他
Debug
执行增删改查前,加入Debug方法,可以将执行的SQL语句打印在控制台
db.Debug().First(&s) //查找错误处理
result是查找函数的返回值
result.RowsAffected // 返回找到的记录数
result.Error // 没找到返回 gorm.ErrRecordNotFound
// 检查 ErrRecordNotFound 错误
errors.Is(result.Error, gorm.ErrRecordNotFound)GORM的函数在执行数据库操作之前,可以一直加条件,形成链式调用
一般错误处理,都是以下这种形式。执行结果的返回值有一个Error属性,是error类型。有错误,返回这个error对象,否则返回nil
//删除指定id的数据
func DeleteTodoItemById(id int) (err error) { //注意:返回参数列表,后面直接写return就行
var todo ToDo
if err := dao.DB.Delete(&todo, id).Error; err != nil {
return
}
return
}待办事项案例
项目结构划分
一般结构
项目根目录
|- router //路由
|- controller //控制器,最终返回JSON/HTNML的位置
|- logic //处理业务逻辑
|- models //处理数据库增删改查相关
|- dao //(database access object) 数据库链接配置一般流程
请求 ——>router路由 ——> controller(控制器) ——> logic(逻辑层) ——> models(模型层增删改查)代码
有一点需要注意:结构体的Status字段,是布尔类型,但是存储时,会存储为0或1

日志库(zap)
Go标准库log提供的能力非常有限,所以这里主要介绍的是Zap日志库
安装
go get -u go.uber.org/zap简单例子
Zap提供了两种类型的日志记录器—
Sugared Logger和Logger(对性能要求高就是用Logger,但它只支持强类型的结构化日志记录,一般用于生产)日志记录器的默认配置有三种方式,它们之间唯一的区别在于它将记录的信息不同
- NewProduction() 生产环境默认配置值
- NewDevelopment() 开发环境默认配置值
- New() 自定义配置
默认情况下日志都会打印到console
记录日志函数
这里分别写了Logger和SugaredLogger两种日志记录器
XXX表示Debug、Info、Warn、Error、Panic等方法,记录不同等级的日志
gofunc (log *Logger) XXX(msg string, fields ...Field) func (s *SugaredLogger) XXX(msg string, fields ...Field)返回fields类型的函数,名字值得是val的类型
go//val是string类型 func String(key string, val string) Field //val是Int32指针 func Int32p(key string, val *int32) Field //不确定val类型,用Any(key,val) //val是错误对象,可以不指定key ,用Error(错误实例)
Logger
package main
import (
"go.uber.org/zap"
"net/http"
)
var logger *zap.Logger //日志记录器Logger、SugaredLogger,对性能要求高就是用Logger
func initLogger() (err error) {
//zap.NewProduction() // 生产环境默认配置值
//zap.NewDevelopment() // 开发环境默认配置值
//zap.New() //自定义配置
logger, err = zap.NewProduction()
return
}
func main() {
initLogger()
defer logger.Sync() //写入磁盘
resp, err := http.Get("http://www.baidu.com")
if err != nil {
logger.Error(
"访问错误",
zap.String("url", "www.baidu.com"),
zap.Error(err))
} else {
logger.Info("访问成功",
zap.String("statusCode", resp.Status),
zap.String("url", "www.baidu.com"))
resp.Body.Close()
}
}打印结果
{"level":"info","ts":1657118439.748776,"caller":"zaplog/index.go:29","msg":"访问成功","statusCode":"200 OK","url":"www.baidu.com"}
//level:是日志级别
//ts:时间戳
//caller:调用栈
//caller:log日志方法的第一个参数
//后面的statusCode、url的键值对是log日志方法的额外参数sugaredLogger
Logger调用Sugar方法,返回的就是sugaredLogger
package main
import (
"go.uber.org/zap"
"net/http"
)
var sugaredLogger *zap.SugaredLogger //日志记录器Logger、SugaredLogger,对性能要求高就是用Logger
func initLogger() (err error) {
//zap.NewProduction() // 生产环境默认配置值
//zap.NewDevelopment() // 开发环境默认配置值
//zap.New() //自定义配置
logger, _ := zap.NewProduction()
sugaredLogger = logger.Sugar()
return
}
func main() {
initLogger()
defer sugaredLogger.Sync() //写入磁盘
resp, err := http.Get("http://www.baidu.com")
if err != nil {
sugaredLogger.Error(
"访问错误",
zap.String("url", "www.baidu.com"),
zap.Error(err))
} else {
sugaredLogger.Info("访问成功",
zap.String("statusCode", resp.Status),
zap.String("url", "www.baidu.com"))
resp.Body.Close()
}
}打印结果
{"level":"info","ts":1657121340.018529,"caller":"zaplog/index.go:30","msg":"访问成功{statusCode 15 0 200 OK <nil>} {ur 0 www.baidu.com <nil>}"}补充
上面两个例子均使用NewProduction这个配置
Logger换成NewDevelopment这个配置
2022-07-07T01:10:24.785+0800 INFO zaplog/index.go:29 访问成功 {"statusCode": "200 OK", "url": "www.baidu.com"}Logger换成NewDevelopment这个配置
2022-07-07T01:13:22.526+0800 INFO zaplog/index.go:30 访问成功{statusCode 15 0 200 OK <nil>} {url 15 0 www.b.com <nil>}自定义Logger
func New(core zapcore.Core, options ...Option) *Logger其中的参数zapcore.Core,需要三个配置项——Encoder,WriteSyncer,LogLevel
1、Encoder:日志的格式
字段配置:使用预先设置的NewProductionEncoderConfig()、NewDevelopmentEncoderConfig()
日志格式
JSON:
NewJSONEncoder()zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig()) //输出格式样例 //{"level":"info","ts":1657126830.894248,"msg":"访问成功{statusCode 15 0 200 OK <nil>} {url 15 0 www.baidu.com <nil>}"}Console输出格式(字段间空格分隔):
gozapcore.NewConsoleEncoder(zap.NewProductionEncoderConfig()) //输出格式样例 //1.6571270591036348e+09 info 访问成功{statusCode 15 0 200 OK <nil>} {url 15 0 www.baidu.com <nil>}
2、WriterSyncer :指定日志将写到哪里去
使用zapcore.AddSync()函数并且将打开的文件句柄传进去
创建新文件
file, _ := os.Create("./test.log")
writeSyncer := zapcore.AddSync(file)没文件新建,有文件就追加
func getLogWriter() zapcore.WriteSyncer {
file, err := os.OpenFile("./test.log", os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)
if err != nil {
fmt.Printf("%v\n", err)
}
return zapcore.AddSync(file)
}3、Log Level:哪种级别的日志将被写入
DebugLevel
InfoLevel
WarnLevel
ErrorLevel
DPanicLevel
PanicLevel
FatalLevel
_minLevel
_maxLevel例子
以日志记录器Logger为例子,使用自定义日志记录器配置,重写initLogger函数
func initLogger() {
//1、Encoder
encoder := getEncoder()
//2、WriterSyncer
writeSyncer := getLogWriter()
//3、创建zapcore.Core
core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)
//4、New方法自定义
logger := zap.New(core)
}
func getEncoder() zapcore.Encoder {
return zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
}
func getLogWriter() zapcore.WriteSyncer {
file, _ := os.Create("./test.log")
return zapcore.AddSync(file)
}运行结果:将日志输出到文件中
{"level":"info","ts":1657128015.7524219,"msg":"访问成功","statusCode":"200 OK","url":"www.baidu.com"}进一步自定义Encoder的字段
不使用NewProductionEncoderConfig()、NewDevelopmentEncoderConfig()这两种预定义的输出的格式
以NewProductionEncoderConfig为例子,如果想要精细的更改字段,就需要看下的源码
其只是返回了一个结构体,其实我们不使用NewProductionEncoderConfig,自己写这个结构体作为参数即可
func NewProductionEncoderConfig() zapcore.EncoderConfig {
return zapcore.EncoderConfig{
TimeKey: "ts",
LevelKey: "level",
NameKey: "logger",
CallerKey: "caller",
FunctionKey: zapcore.OmitKey,
MessageKey: "msg",
StacktraceKey: "stacktrace",
LineEnding: zapcore.DefaultLineEnding,
EncodeLevel: zapcore.LowercaseLevelEncoder,
EncodeTime: zapcore.EpochTimeEncoder,//这个属性是时间戳
EncodeDuration: zapcore.SecondsDurationEncoder,
EncodeCaller: zapcore.ShortCallerEncoder,
}
}修改getEncoder方法
func getEncoder() zapcore.Encoder {
encoderConfig := zapcore.EncoderConfig{
//定义日志的key和value
LevelKey: "等级",
EncodeLevel: zapcore.LowercaseLevelEncoder,//日志等级小写,如果希望大写请使用:zapcore.CapitalLevelEncoder,
//定义表示日志时间的key和value
TimeKey: "时间",
EncodeTime: zapcore.ISO8601TimeEncoder,
//定义message的key和value,value是logger.Error等记录日志函数的第一个参数
MessageKey: "提示信息",
//定义当前生成这条日志的调用位置的key和value,只有在zap.New(core, zap.AddCaller())中添加第二个参数,才会输出这个字段
CallerKey: "调用位置",
EncodeCaller: zapcore.ShortCallerEncoder,//调用位置从项目根目录开始,如果希望是系统绝对路径请使用:FullCallerEncoder
NameKey: "logger",
FunctionKey: zapcore.OmitKey,
StacktraceKey: "stacktrace",
//每行以\n结尾
LineEnding: zapcore.DefaultLineEnding,
EncodeDuration: zapcore.SecondsDurationEncoder,
}
return zapcore.NewJSONEncoder(encoderConfig)
}运行结果:将日志输出到文件中
{"等级":"info","时间":"2022-07-07T01:24:45.491+0800","提示信息":"访问成功","statusCode":"200 OK","url":"www.baidu.com"}结构体的EncodeTime字段的值
EncodeTime:zapcore.EpochTimeEncoder //时间戳
EncodeTime:zapcore.ISO8601TimeEncoder //"2022-07-07T01:24:45.491+0800"
EncodeTime:zapcore.TimeEncoderOfLayout("2006-01-02"), //按照指定格式格式化时间,例如:"2022-07-07"zap.New(core, zap.AddCaller())
增加调用字段(每条日志记录的代码位置)
package main
import (
"fmt"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
"net/http"
"os"
)
var logger *zap.Logger //日志记录器Logger、SugaredLogger,对性能要求高就是用Logger
func initLogger() {
//1、Encoder
encoder := getEncoder()
//2、WriterSyncer
writeSyncer := getLogWriter()
//3、创建zapcore.Core
core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)
//4、New方法自定义
logger = zap.New(core, zap.AddCaller())
}
func getEncoder() zapcore.Encoder {
encoderConfig := zapcore.EncoderConfig{
//定义日志的key和value
LevelKey: "等级",
EncodeLevel: zapcore.LowercaseLevelEncoder, //日志等级小写,如果希望大写请使用:zapcore.CapitalLevelEncoder,
//定义表示日志时间的key和value
TimeKey: "时间",
EncodeTime: zapcore.ISO8601TimeEncoder,
//定义message的key和value,value是logger.Error等记录日志函数的第一个参数
MessageKey: "提示信息",
//定义当前生成这条日志的调用位置的key和value,只有在zap.New(core, zap.AddCaller())中添加第二个参数,才会输出这个字段
CallerKey: "调用位置",
EncodeCaller: zapcore.ShortCallerEncoder,
NameKey: "logger",
FunctionKey: zapcore.OmitKey,
StacktraceKey: "stacktrace",
LineEnding: zapcore.DefaultLineEnding,
EncodeDuration: zapcore.SecondsDurationEncoder,
}
return zapcore.NewJSONEncoder(encoderConfig)
}
func getLogWriter() zapcore.WriteSyncer {
//file, _ := os.Create("./test.log")
//return zapcore.AddSync(file)
file, err := os.OpenFile("./test.log", os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)
if err != nil {
fmt.Printf("%v\n", err)
}
return zapcore.AddSync(file)
}
func main() {
initLogger()
defer logger.Sync() //写入磁盘
resp, err := http.Get("http://www.baidu.com")
if err != nil {
logger.Error(
"访问错误",
zap.String("url", "www.baidu.com"),
zap.Error(err))
} else {
logger.Info("访问成功",
zap.String("statusCode", resp.Status),
zap.String("url", "www.baidu.com"))
resp.Body.Close()
}
}结果:多了一个调用位置
{"等级":"info","时间":"2022-07-08T00:16:56.543+0800","调用位置":"zaplog/index.go:74","提示信息":"访问成功","statusCode":"200 OK","url":"www.baidu.com"}注意
一般生成JSON格式的日志,使用filebeat来进行日志分析
日志切割
zap不支持日志切割,所以一般使用Lumberjack
https://www.liwenzhou.com/posts/Go/zap/#autoid-1-3-4
安装
go get github.com/natefinch/lumberjack使用
只需要修改WriteSyncer部分的代码,就能在zap中加入Lumberjack支持
func getLogWriter() zapcore.WriteSyncer {
lumberJackLogger := lumberjack.Logger{
Filename: "./test.log", //日志文件的位置
MaxSize: 1, //日志文件的最大大小(以MB为单位)
MaxBackups: 5, //保留旧文件的最大个数
MaxAge: 1, //保留旧文件的最大天数
Compress: false, //是否压缩/归档旧文件
}
return zapcore.AddSync(&lumberJackLogger)
}在Gin中集成zap
学习Gin时候提到过
gin.Default()其原理就是,添加了Logger和Recovery两个中间件
func Default() *Engine {
debugPrintWARNINGDefault()
engine := New()
engine.Use(Logger(), Recovery())
return engine
}如果想要集成zap日志,就要使用自己的中间件
自己实现,请参考这篇博客:https://www.liwenzhou.com/posts/Go/use_zap_in_gin/
使用第三方库实现的请参考:https://github.com/gin-contrib/zap
处理配置文件(viper)
介绍
https://www.liwenzhou.com/posts/Go/viper_tutorial/
项目的官方github地址(https://github.com/spf13/viper)
viper简单来说就是一个用来读取自己项目中的配置的库
支持显式的设置参数值,设置参数默认值
支持读取
JSON、TOML、YAML、HCL、envfile和Java properties格式的配置文件,同时支持热加载(可以监听配置文件变化)从环境变量中读取配置
支持从命令行参数读取配置
支持从buffer读取配置
Viper会按照下面的优先级读取(从高到低)
- 显式的设置值
- 命令行参数
- 环境变量
- 配置文件(
JSON、TOML、YAML、HCL、envfile和Java properties) - key/value存储(注意:目前Viper配置的键(Key)是大小写不敏感的)
- 默认值
安装
go get github.com/spf13/viper设置Viper
package main
import (
"fmt"
"github.com/spf13/viper"
)
func main() {
//1、读取配置文件
viper.SetConfigName("config") //配置文件名(不带后缀的名字)这是因为有些文件本就是不带后缀的,比如.zshrc
//当从远程获取配置文件信息时,才会生效
//viper.SetConfigType("yaml") //配置文件的后缀名
//如果项目下,有两个多个名为config的文件,可以使用SetConfigFile同时指定带后缀的文件名
//viper.SetConfigFile("config.yaml")
//2、配置去哪个路径下,找配置文件(可以添加多个)
viper.AddConfigPath(".") //当前项目路径
viper.AddConfigPath("./config") //当前项目路径的config文件夹下
viper.AddConfigPath("$HOME") //参数中可包含环境变量
}监听配置变化
viper.WatchConfig()
viper.OnConfigChange(func(e fsnotify.Event) {
// 配置文件发生变更之后会调用的回调函数
fmt.Println("配置文件变化了:", e.Name)
})例子
package main
import (
"fmt"
"github.com/fsnotify/fsnotify"
"github.com/gin-gonic/gin"
"github.com/spf13/viper"
"net/http"
)
func main() {
viper.SetConfigName("config")
viper.SetConfigType("yaml")
viper.AddConfigPath(".")
if err := viper.ReadInConfig(); err != nil {
if _, ok := err.(viper.ConfigFileNotFoundError); ok {
fmt.Printf("配置文件不存在")
return
} else {
fmt.Printf("配置文件存在,但是存在其他错误:%v\n", err)
return
}
}
viper.WatchConfig()
viper.OnConfigChange(func(e fsnotify.Event) {
// 配置文件发生变更之后会调用的回调函数
fmt.Println("配置文件变化了:", e.Name)
})
r := gin.Default()
r.GET("/config", func(context *gin.Context) {
value := viper.Get("userName")
context.String(http.StatusOK, "%v\n", value)
})
r.Run(":9000")
}
更改配置文件,控制台就会打印
配置文件变化了 /Users/yc/Documents/GO/GoProject/Gogin/goViper/config.yaml写入配置文件
配置的默认值
viper.SetDefault("file", "123")覆盖配置的值
viper.Set("file2", "1234")别名
为配置项的key名建立映射
viper.RegisterAlias("name", "UserNmae")
//下面两个覆盖效果是一样的
viper.Set("name", "tom")
viper.Set("UserNmae", "tom")注意
后面的写入配置文件,还是拷贝配置文件,他们的前提都是要指明配置文件的位置,就是【设置Viper】章节提到的SetConfigName、AddConfigPath中指定配置文件的名字和路径,否则就会报错
写入配置文件
前面的配置默认值、覆盖配置都需要调用这里的方法,才能写入配置文件
- WriteConfig :如果写入的键在配置文件中存在,SetDefault不会覆盖,Set会覆盖
- SafeWriteConfig:如果写入的键在配置文件中存在, 不会覆盖,会报错
err := viper.WriteConfig()
//err := viper.SafeWriteConfig()
if err != nil {
fmt.Printf("写入配置文件失败,err:%v\n", err)
}拷贝配置文件
参数是拷贝配置文件到目标路径
- viper.WriteConfigAs 如果目标路径存在该配置文件,就会覆盖
- SafeWriteConfigAs 如果目标路径存在该配置文件,就会覆盖,而且报错
err:=viper.WriteConfigAs("./Myconfig.yaml")
//err:=viper.SafeWriteConfigAs("./Myconfig.yaml")
if err != nil {
fmt.Printf("拷贝配置文件失败,err:%v\n", err)
}读取不同源数据到Viper实例
从io.Read读取
viper.SetConfigType("yaml")
var yamlExample = []byte(`
name: "tom"
age: 19
host:
- address: "127.0.0.1"
- port: 9000
`)
viper.ReadConfig(bytes.NewBuffer(yamlExample))
viper.Get("name") // tom从环境变量读取
BindEnv使用一个或两个参数
- 第一个参数是键名称,第二个是环境变量的名称
- 环境变量的名称区分大小写。
- 没有第二个参数(没有提供ENV变量名)那么Viper将自动假设ENV变量与以下格式匹配:
前缀大写+ "_" +键名全部大写。例如,如果只有一个参数是“home”,Viper将查找环境变量"AVA_HOME" - 有第二个参数时, 不会 自动添加前缀。例如,如果第二个参数是"home",Viper将查找环境变量"HOME"
viper.SetEnvPrefix("java") //设置前缀,参数全部转换为大写
viper.BindEnv("home") //参数全部转换为大写字母,如果有设置前缀,绑定为JAVA_HOME;如果
//读取值
value := viper.Get("home")
fmt.Printf("值是:%v", value)从命令行参数读取
Viper支持Cobra库中使用的Pflag
//设置命令行参数 flagname
pflag.Int("flagname", 1234, "help message for flagname")
//读取参数
pflag.Parse()
//绑定参数,默认绑定命令函数参数
viper.BindPFlags(pflag.CommandLine)
//读取值
i := viper.GetInt("flagname") // 从viper而不是从pflag检索值如果想要绑定Go标准库中提供的flag库
原理:通过调用pflag包提供的函数AddGoFlagSet()来包装flag库
package main
import (
"flag"
"github.com/spf13/pflag"
)
func main() {
// 使用标准库 "flag" 包
flag.Int("flagname", 1234, "help message for flagname")
pflag.CommandLine.AddGoFlagSet(flag.CommandLine)
pflag.Parse()
viper.BindPFlags(pflag.CommandLine)
i := viper.GetInt("flagname") // 从 viper 检索值
}从配置文件读取
if err := viper.ReadInConfig(); err != nil {
if _, ok := err.(viper.ConfigFileNotFoundError); ok {//使用断言判断是否是配置文件不存在的错误
fmt.Printf("配置文件不存在")
return
} else {
fmt.Printf("配置文件存在,但是存在其他错误:%v\n", err)
return
}
}
fmt.Printf("读取成功\n")从Viper实例获取值
例子
例如,现在有一个配置文件config.yaml
userName: "hdd"
age: 22
host:
address: "127.0.0.1"
port: 9000
gitConfig:
repoName: "Git仓库名"
repoUrl: "github.com/xxx/xxxx"
pollTime: 3600main.go
package main
import (
"fmt"
"github.com/spf13/viper"
)
func main() {
//读取配置文件
viper.SetConfigName("config")
viper.SetConfigType("yaml")
//当前项目路径下找配置文件
viper.AddConfigPath(".")
//使用断言判断是否是配置文件不存在的错误
if err := viper.ReadInConfig(); err != nil {
if _, ok := err.(viper.ConfigFileNotFoundError); ok {
fmt.Printf("配置文件不存在")
return
} else {
fmt.Printf("配置文件存在,但是存在其他错误:%v\n", err)
return
}
}
//这里来进行读取配置(*)
}下面读取值的代码都是在(*)这一行下面写的
根据配置项value的类型
GetBool(key string) : boolGetFloat64(key string) : float64GetInt(key string) : intGetIntSlice(key string) : []intGetString(key string) : stringGetStringMap(key string) : map[string]interface{}GetStringMapString(key string) : map[string]stringGetStringSlice(key string) : []stringGetTime(key string) : time.TimeGetDuration(key string) : time.Duration
例子:
value := viper.GetInt("age")注意:
GetInt函数要求value是Int类型,如果age字段的值是字符串,就会返回Int类型的零值
如果配置文件中不存在age字段,也会返回Int类型的零值
如何判断是使用的函数不对,还是配置项的value真的是零值
IsSet(key string) : bool
不区分配置项value的类型
Get(key string) : interface{}
注意:
如果,配置文件中不存在,下面的port字段,会返回nil
value := viper.Get("age")读取嵌套结构中的某个key
比如,访问配置文件中的post字段下的port
value := viper.Get("host.port")读取子树
Sub函数返回值是一个Viper指针
value := viper.Sub("host").Get("port")反序列化
将Viper实例中的值,转化为Go语言中的结构体(需要提前定义好结构体的结构)
type config struct {
UserName string
Age int
}
var c config
if err := viper.Unmarshal(&c); err != nil {
fmt.Printf("序列化失败,err:%v\n", err)
}
fmt.Printf("%#v\n", c)无论是哪种格式的配置文件(我们的例子里是yaml格式),tag都是mapstructure
如果仅仅是结构体字段首字母大写,配置文件首字母小写的差异,不用添加tag,Viper也能正常读入
type config struct {
Name string `mapstructure:"userName"`
Age int
}反序列化为嵌入结构体
这种是实际项目中用的最多的,一般会把配置文件读入到嵌入结构体中,然后再全局使用
type config struct {
userName string
Age int
host configHost //这里嵌入了另一个结构体
}
type configHost struct {
address string
port int
}
var c config
if err := viper.Unmarshal(&c); err != nil {
fmt.Printf("序列化失败,err:%v\n", err)
}
var h configHost
if err := viper.Unmarshal(&h); err != nil {
fmt.Printf("序列化失败,err:%v\n", err)
}
fmt.Printf("%#v\n", c) //main.config{Name:"hdd", Age:22, host:main.configHost{address:"", port:0}}嵌入结构体的指针用法
type config struct {
UserName string
Age int
*ConfigHost `mapstructure:"host"` //切入部分用指针
}
type ConfigHost struct {
Address string
Port int
}
var C = new(config)//直接定义一个全局指针
if err := viper.Unmarshal(C); err != nil {
fmt.Printf("序列化失败,err:%v\n", err)
}序列化为字符串
将Viper实例中的值,并转成字符串(反序列化是转成结构体)
需要安装
go get "gopkg.in/yaml.v2"例子
import (
yaml "gopkg.in/yaml.v2"
)
c := viper.AllSettings()
bs, err := yaml.Marshal(c)
if err != nil {
fmt.Printf("转化为YAML失败,err:%v\n", err)
}
fmt.Printf("%#v\n", string(bs))注意
全局就一个Viper实例时,在其他包下直接引入,就可以获取Viper实例
import "github.com/spf13/viper"
func GetData(){
viper.Get(key)
}优雅关机和重启
https://www.liwenzhou.com/posts/Go/graceful_shutdown/
分布式ID生成器
用户表
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`username` varchar(64) COLLATE utf8mb4_general_ci NOT NULL,
`password` varchar(64) COLLATE utf8mb4_general_ci NOT NULL,
`email` varchar(64) COLLATE utf8mb4_general_ci,
`gender` tinyint(4) NOT NULL DEFAULT '0',
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE
CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_username` (`username`) USING BTREE,
UNIQUE KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;分布式ID的特点
全局唯⼀性:不能出现有重复的ID标识,这是基本要求
递增性:确保⽣成ID对于⽤户或业务是递增的
⾼可⽤性:确保任何时候都能⽣成正确的ID
⾼性能性:在⾼并发的环境下依然表现良好
snowflake算法介绍
雪花算法,它是Twitter开源的由64位整数组成分布式ID,性能较⾼,并且在单机上递增

- 第⼀位 占⽤1bit,其值始终是0,没有实际作⽤
- 时间戳 占⽤41bit,单位为毫秒,总共可以容纳约69年的时间。这⾥的时间戳只是相对于某个时间的增量,⽐如我们的系统上线是2020-07-01,那么我们完全可以把这个timestamp当作是从 2020-07-01 00:00:00.000 的偏移量
- ⼯作机器id 占⽤10bit,其中⾼位5bit是数据中⼼ID,低位5bit是⼯作节点ID,最多可以容纳1024个节点
- 序列号 占⽤12bit,⽤来记录同毫秒内产⽣的不同id,同⼀毫秒⼀共可以产⽣4096个ID【(2^12)个】
第三方库实现
go get "github.com/bwmarrin/snowflake"例子
package main
import (
"fmt"
"github.com/bwmarrin/snowflake"
"time"
)
var node *snowflake.Node
func Init(startTime string, machineID int64) (err error) {
var st time.Time
st, err = time.Parse("2006-01-02", startTime)
if err != nil {
return
}
snowflake.Epoch = st.UnixNano() / 1000000 //纳秒除1000000是毫秒
node, err = snowflake.NewNode(machineID)
return
}
func GenID() int64 {
return node.Generate().Int64()
}
func main() {
if err := Init("2020-07-01", 1); err != nil {
fmt.Printf("init failed, err:%v\n", err)
return
}
id := GenID()
fmt.Println(id)
}校验请求数据
validator库用于校验接收的请求参数,仓库地址:https://github.com/go-playground/validator
gin框架使用支持validator库,只需要在定义结构体时使用 binding tag,不同的tag值表示不同的校验规则(可以查看validator文档查看支持的所有 tag)
例子
不使用binding这个tag,默认情况只有字段类型和ParamSignUp字段类型不同才会报错
使用binding:required表示该字段必须存在,字段缺失BindJSON也会报错
type ParamSignUp struct {
Username string `json:"username" binding:"required"`
Password string `json:"password" binding:"required"`
RePassword string `json:"re_password" binding:"required"`
}
func main(){
r:=gin.Default()
r.POST("/signup",func SignUpHandler(c *gin.Context) {
p := new(ParamSignUp)
//定义的tag是binding,这里就会按照binding字段的要求校验,不符合返回err
if err := c.BindJSON(p); err != nil {
c.JSON(http.StatusOK, gin.H{
"code": -1,
"msg": err.Error(),
"data": nil,
})
return
}
c.JSON(http.StatusOK, gin.H{
"code": 0,
"msg": "ok",
"data": nil,
})
})
r.Run(":9000")
}调用接口,不传递结构体的RePassword字段返回
{"code":-1,"data":null,"msg":"Key: 'ParamSignUp.RePassword' Error:Field validation for 'RePassword' failed on the 'required' tag"}改进1
Gin框架的validator默认返回的err是英文的,我们可以自定义一个翻译器,注册到Gin框架的validator上
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"github.com/gin-gonic/gin/binding" //gin框架的binding库
"net/http"
//语言包
"github.com/go-playground/locales/en"
"github.com/go-playground/locales/zh"
//翻译器
ut "github.com/go-playground/universal-translator"
//校验器
"github.com/go-playground/validator/v10"
enTranslations "github.com/go-playground/validator/v10/translations/en"
zhTranslations "github.com/go-playground/validator/v10/translations/zh"
)
// 定义一个全局翻译器T
var trans ut.Translator
// InitTrans 初始化翻译器
func InitTrans(locale string) (err error) {
// 修改gin框架中的Validator引擎属性,实现自定制
if v, ok := binding.Validator.Engine().(*validator.Validate); ok {
zhT := zh.New() // 中文字典
enT := en.New() // 英文字典
// 装载字典,第一个参数是备用的语言环境,后面的参数是应该支持的语言环境(支持多个)
uni := ut.New(enT, zhT, enT)
var ok bool
// 创建翻译器
//locale 通常取决于 http 请求头的 'Accept-Language',也可以使用 uni.FindTranslator(...) 传入多个locale进行查找
trans, ok = uni.GetTranslator(locale)
if !ok {
return fmt.Errorf("uni.GetTranslator(%s) failed", locale)
}
// 将翻译器注册到gin框架的Validator引擎上
switch locale {
case "en":
err = enTranslations.RegisterDefaultTranslations(v, trans)
case "zh":
err = zhTranslations.RegisterDefaultTranslations(v, trans)
default:
err = enTranslations.RegisterDefaultTranslations(v, trans)
}
return
}
return
}
type ParamSignUp struct {
Username string `json:"username" binding:"required"`
Password string `json:"password" binding:"required"`
RePassword string `json:"re_password" binding:"required"`
}
func main() {
InitTrans("zh")
p := new(ParamSignUp)
r := gin.Default()
r.POST("/signup", func(c *gin.Context) {
if err := c.BindJSON(p); err != nil {
//使用validator
if errs, ok := err.(validator.ValidationErrors); !ok {
c.JSON(http.StatusOK, gin.H{
"code": -1,
"msg": err.Error(),
"data": nil,
})
} else {
c.JSON(http.StatusOK, gin.H{
"code": -1,
"msg": errs.Translate(trans),
"data": nil,
})
}
return
}
c.JSON(http.StatusOK, gin.H{
"code": 0,
"msg": "ok",
"data": nil,
})
})
r.Run(":9898")
}调用接口,不传递结构体的RePassword字段返回
{"code":-1,"data":null,"msg":{"ParamSignUp.RePassword":"RePassword为必填字段"}}改进2
自定义返回msg中的提示信息{"ParamSignUp.RePassword":"RePassword为必填字段"}的value值中的RePassword是结构体字段名,一般应该提示前端请求的字段名
RePassword为必填字段变成re_password为必填字段
其实就是在 InitTrans函数中,添加下面代码
v.RegisterTagNameFunc(func(fld reflect.StructField) string {
name := strings.SplitN(fld.Tag.Get("json"), ",", 2)[0]
if name == "-" {
return ""
}
return name
})InitTrans全部代码
func InitTrans(locale string) (err error) {
// 修改gin框架中的Validator引擎属性,实现自定制
if v, ok := binding.Validator.Engine().(*validator.Validate); ok {
// 注册一个获取json tag的自定义方法
v.RegisterTagNameFunc(func(fld reflect.StructField) string {
name := strings.SplitN(fld.Tag.Get("json"), ",", 2)[0]
if name == "-" {
return ""
}
return name
})
zhT := zh.New() // 中文字典
enT := en.New() // 英文字典
// 装载字典,第一个参数是备用的语言环境,后面的参数是应该支持的语言环境(支持多个)
uni := ut.New(enT, zhT, enT)
var ok bool
// 创建翻译器
//locale 通常取决于 http 请求头的 'Accept-Language',也可以使用 uni.FindTranslator(...) 传入多个locale进行查找
trans, ok = uni.GetTranslator(locale)
if !ok {
return fmt.Errorf("uni.GetTranslator(%s) failed", locale)
}
// 将翻译器注册到gin框架的Validator引擎上
switch locale {
case "en":
err = enTranslations.RegisterDefaultTranslations(v, trans)
case "zh":
err = zhTranslations.RegisterDefaultTranslations(v, trans)
default:
err = enTranslations.RegisterDefaultTranslations(v, trans)
}
return
}
return
}结果
{"code":-1,"data":null,"msg":{"ParamSignUp.re_password":"re_password为必填字段"}}改进3
自定义返回msg中的提示信息{"ParamSignUp.RePassword":"RePassword为必填字段"}的key
增加新函数
func removeTopStruct(fields map[string]string) map[string]string {
res := map[string]string{}
for field, err := range fields {
res[field[strings.Index(field, ".")+1:]] = err
}
return res
}使用
r.POST("/signup", func(c *gin.Context) {
if err := c.BindJSON(p); err != nil {
if errs, ok := err.(validator.ValidationErrors); !ok {
c.JSON(http.StatusOK, gin.H{
"code": -1,
"msg": err.Error(),
"data": nil,
})
} else {
c.JSON(http.StatusOK, gin.H{
"code": -1,
"msg": removeTopStruct(errs.Translate(trans)),//这里做的处理
"data": nil,
})
}
return
}
c.JSON(http.StatusOK, gin.H{
"code": 0,
"msg": "ok",
"data": nil,
})
})结果
{"code":-1,"data":null,"msg":{"re_password":"re_password为必填字段"}}登录方案
分为Session和JWT两种方案,这里只介绍JWT方式
JWT(待补充)
go get github.com/golang-jwt/jwt/v4业务场景1
refreshToken+accessToken方法
https://www.liwenzhou.com/posts/Go/json-web-token/#autoid-0-5-0
业务场景2
同一时刻,同一个账号只能登录一个设备
第一次登录将user_id和token的键值对存在redis中,第二次登录解析出token中的user_id后,在redis存储中查找是否存在键值对,如果存在且redis中的token和当前接收的token不一致,即可判定为多人登录
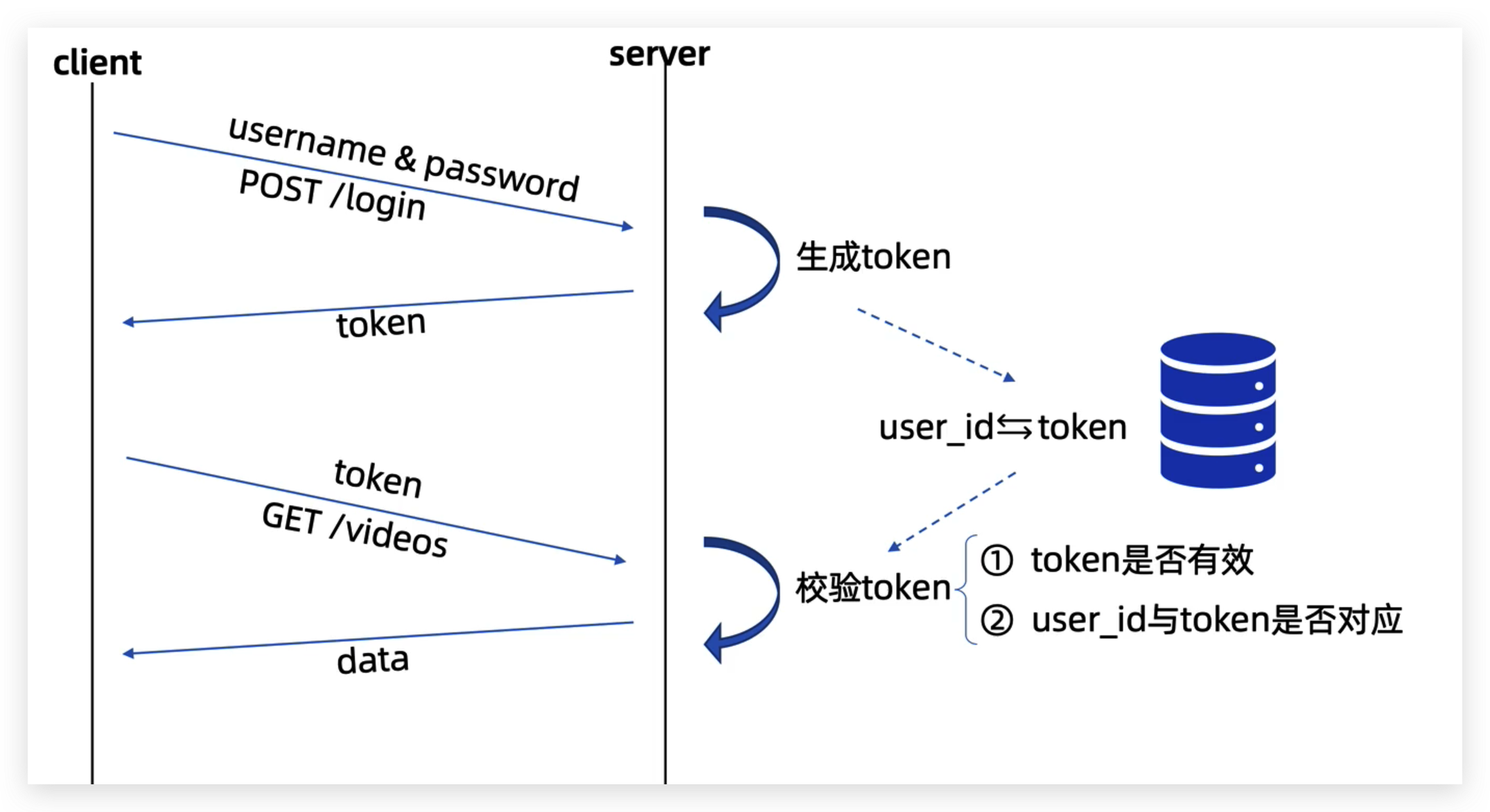
Makefile
make是一个构建自动化工具,会在当前目录下寻找Makefile或makefile文件。如果存在相应的文件,它就会依据其中定义好的规则完成构建任务。借助Makefile我们在编译过程中不再需要每次手动输入编译的命令和编译的参数,可以极大简化项目编译过程。
Makefile的基本格式
targets : [prerequisites][; command]
command- targets:目标
- prerequisites:生成 targets 所需要的文件或者是目标
- command:命令。以有多条命令,每一条命令占一行
Makefile示例
#.PHONY关键字,用来定义伪目标
.PHONY: all build run gotool clean help
#BINARY关键字,用来定义变量bluebell,使用${bluebell}获取变量
BINARY="bluebell"
#下面都是定义的命令,终端输入make xxxx执行
all: gotool build #终端输入make时,自动执行的命令
build:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -ldflags "-s -w" -o ./bin/${BINARY}
run:
@go run ./main.go #命令前加@符号,执行时不会在终端输出当前执行的命令
gotool:
go fmt ./
go vet ./
clean:
@if [ -f ${BINARY} ] ; then rm ${BINARY} ; fi
help:
@echo "make - 格式化 Go 代码, 并编译生成二进制文件"
@echo "make build - 编译 Go 代码, 生成二进制文件"
@echo "make run - 直接运行 Go 代码"
@echo "make clean - 移除二进制文件和 vim swap files"
@echo "make gotool - 运行 Go 工具 'fmt' and 'vet'"热加载(Air)
Air 是为 Go 应用开发设计的另外一个热重载的命令行工具
安装
Air是个全局的工具,并不需要在项目中引入
go install github.com/cosmtrek/airshell配置
把alias air='~/.air'加到你的.bashrc或.zshrc中
项目配置
项目下新建
.air.conf配置文件配置模板
ini# 设置root是项目的根目录,tmp_dir是存放air日志的目录 # 使用 . 或绝对路径,请注意 `tmp_dir` 目录必须在 `root` 目录下 root = "." tmp_dir = "tmp" [build] # 只需要写你平常编译使用的shell命令。你也可以使用 `make` # Windows平台示例: cmd = "go build -o tmp\main.exe ." cmd = "go build -o ./tmp/main" # 指定存放由`cmd`命令得到的二进制文件的路径和文件名 # Windows平台示例:bin = "tmp\main.exe" bin = "tmp/main" # 自定义执行程序的命令,当项目重启时执行bin字段配置的路径下的可执行文件(可以添加额外的变量标识例如添加 GIN_MODE=release) # Windows平台示例:full_bin = "tmp\main.exe" # 指定变量示例:full_bin = "APP_ENV=dev APP_USER=air ./tmp/main" full_bin = "./tmp/main ./conf/config.yaml" # 监听以下文件扩展名的文件. include_ext = ["go", "tpl", "tmpl", "html"] # 忽略这些文件扩展名或目录 exclude_dir = ["assets", "tmp", "vendor", "frontend/node_modules"] # 监听以下指定目录的文件 include_dir = [] # 排除以下文件 exclude_file = [] # 如果文件更改过于频繁,则没有必要在每次更改时都触发构建。可以设置触发构建的延迟时间 delay = 1000 # ms # 发生构建错误时,停止运行旧的二进制文件。 stop_on_error = true # air的日志文件名,该日志文件放置在你的`tmp_dir`中 log = "air_errors.log" [log] # 显示日志时间 time = true [color] # 自定义每个部分显示的颜色。如果找不到颜色,使用原始的应用程序日志。 main = "magenta" watcher = "cyan" build = "yellow" runner = "green" [misc] # 退出时删除tmp目录 clean_on_exit = true补充
启动Air时,会执行
cmd字段指定的命令,将该命令输出的二进制文件保存到bin字段指定的目录(没有就会自动创建)每次修改监听的文件后,都会重新执行
full_bin字段指定的命令结束Air(control+c)时,会自动删除
bin字段指定的目录应用
仅用在启动测试环境进行开发时使用Air实现热加载
自动生成接口文档(swager)
gin-swager是一个自动成RESTful API文档的gin中间件
安装全局工具
go install github.com/swaggo/swag/cmd/swag@latest通用API注释 :在main函数前添加
// @title 管理后台接口文档
// @version 1.0.0
// @description 管理后台相关接口
// @termsOfService http://swagger.io/terms/
// @contact.name 何叨叨
// @contact.url http://heyingjiee.github.io
// @contact.email 1270433876@qq.com
// @host localhost:8686
// @BasePath /api/v1API注释 :在controller层,在每个Handler处理函数上添加对应的注释
// LoginHandler 登录处理Handler
// @Summary 用户登录接口
// @Description 详细描述
// @Tags 用户相关
// @Accept json
// @Produce json
// @Param object body models.ParamLogin true "用户名和密码"
// @Success 200 {object} controller._ResponseLogin
// @Router /login [post]
func LoginHandler(c *gin.Context) {}字段含义在中文文档中有介绍,这里主要提示下
@Param 中的字段如果是个结构体,就写成object
就是我们定义的接收参数的结构体吗,如果我这里的登录接口接收数据的结构体
在这个结构体后加注释,就会被写入swagger文档字段的注释
example这个tag指定了这个接口的一个入参例子
gotype ParamLogin struct { Username string `json:"username" binding:"required" example:"rosetest"` //用户名 Password string `json:"password" binding:"required" example:"123"` //密码 }@Success 中
{object}就是返回的结构样式,一般定义统一的返回结构,但是每一个接口返回的data字段是不一样的
就需要一个个定义下
在controller包下建一个
docs_models.go文件专门存放,返回的结构体结构gopackage controller //这里定义的结构体仅仅为了在swagger文档中展示返回数据的格式, //为了和项目中用到的其他结构体区分,统一添加短横线前缀 type _ResponseLogin struct { Code utils.ResCode `json:"code"` // 业务响应状态码 Message string `json:"message"` // 提示信息 Data struct { Token string `json:"token"` } `json:"data"` // 业务响应数据 }
生成doc文档
使用全局工具生成文档
swag init
将生成的文档,添加到gin
go get -u github.com/swaggo/gin-swagger
go get -u github.com/swaggo/files添加新的路由,重启项目,访问http://localhost:8686/swagger/index.html
import (
_ "bluebell/docs" //这里将生成的swagger文档引入
swaggerfiles "github.com/swaggo/files" //swagger embed files
ginSwagger "github.com/swaggo/gin-swagger" //gin-swagger middleware
)
r.GET("/swagger/*any", ginSwagger.WrapHandler(swaggerfiles.Handler))生成的文档

展开登录接口的文档
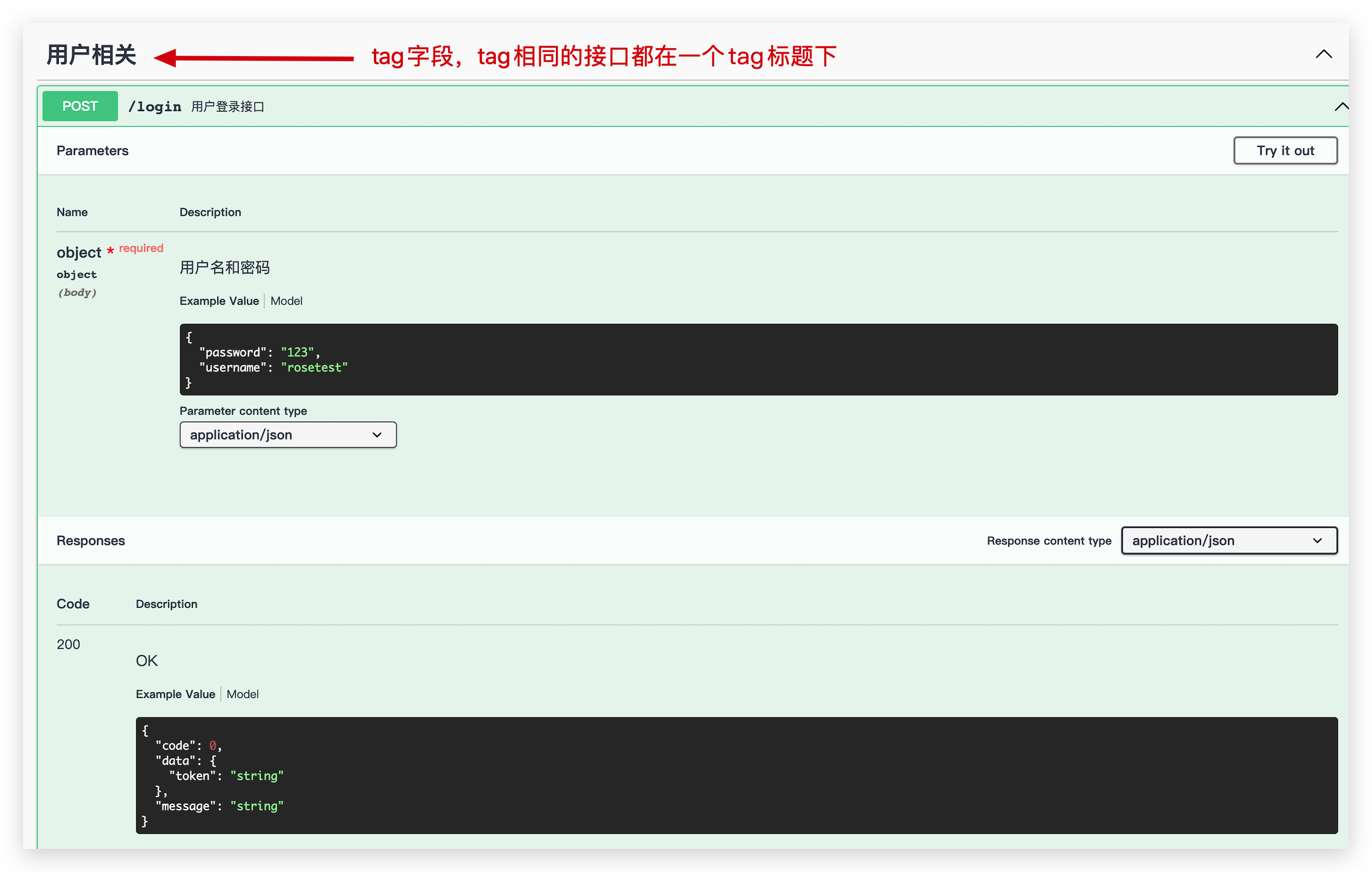
企业级脚手架
将 日志(zap)、配置文件(viper)、GORM 集成到Gin框架中
后端安全
接口安全
可能面临的攻击手段
中间人攻击
请求篡改
重放攻击
防御手段
使用HTTPS协议,由于加密的原因,可以防止抓包。但是如果信任了第三方攻击者的证书,仍然会被截获
Charles这种抓包工具其实就是中间人攻击的手段
接口验证签名
1、所有前端发送字段按照字典升序排列,把参数按照 key1=value1&key2=value2… 的格式拼接起来【前端如果发送的是GET请求,会将参数放到URL后面,这些value必须使用URL编码,才能保证正确发送。前端发送的POST请求中,x-www-from-urlencoded,也是使用URL编码了value,所以对应的这里计算签名也必须将value编码,才能使得前后端计算的签名一致】
2、再拼接一个秘钥 key=xxx
3、再拼接一个时间戳 timestamp=xxx
4、把拼接好的字符串进行 MD5 签名,然后转为大写得到最后的签名字符串
5、在发送的数据中添加一个x-sign字段,用来发送签名
例如,前端发送的数据是
{ "userName": hhh, "userAge": 18 }密钥是ABCDEF,时间戳是1655026676291
首先 ,拼接好字符串
textuserAge=18&userName=hhh&key=ABCDEF×tamp=1655026676291经过MD5计算的签名是(MD5在线转换)
text59279C2928F081859B9295083DE974B2最终前端发送的数据仍然是
{ "userName": hhh, "userAge": 18, }但是,要在请求头中加入
x-sign:"59279C2928F081859B9295083DE974B2" x-timestamp:1655026676291后端
接收到参数后,使用一样的密钥(只有前后端知道)和请求头中的时间戳,算出一个签名
如果算出的签名和x-sign一样,则代表数据未被篡改,可防止请求篡改攻击
同时x-timestamp也是可信的,和当前时间对比,相差不多,就证明不是重放攻击
密码存储安全
为了安全,后端数据库中不能存储明文密码
一般有两种方式
MD5/SHA256 进行哈希
可以将前端传递的密码通过MD5计算签名,与数据库中存储的签名进行对比,如果一样,就代码密码正确
缺点:由于一些在线工具存储了大量的计算好的哈希值,而且还有彩虹表破解法,这两种方式都有一定几率破解密码,所以不够安全
MD5/SHA256 + 盐: 为了防止反向字典查询破解和彩虹表破解,就衍生出了加盐的做法,也就是在原有字符串后面增加一些其他的字符,使得哈希值跟原始的不一样,主要加的盐没有泄漏,就不能得知原始密码是多少
缺点:为了安全每个密码都是用随机的盐值,但是,这样就需要单独存储每一个密码的盐值
Bcrypt 加密存储
Bcrypt 就是一个非常方便的工具,它可以为你生成随机的盐,结合你的密码进行一大串非常复杂的计算,最后生成一个字符串,只需要保存这一个字符串,不需要单独另外存储一个salt字段
HTTP压测
HTTP压测可以用来评估当前系统的性能水平
压测基础
性能指标
- 响应时间(RT) :指系统对请求作出响应的时间.
- 吞吐量(Throughput) :指系统在单位时间内处理请求的数量
- QPS每秒查询率(Query Per Second) :“每秒查询率”,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
- TPS(TransactionPerSecond):每秒钟系统能够处理的交易或事务的数量
- 并发连接数:某个时刻服务器所接受的请求总数
压测工具wrk
wrk是一个现代的HTTP基准测试工具,通过模拟请求,并统计接收响应的时间,来测试性能
安装
推荐使用brew安装
brew install wrk使用方式
wrk [flag] 接口地址参数含义
-c, --connections: 模拟的总请求数,
每个进程的请求数 = connections/threads
-t, --threads: 压力测试使用的进程数
-d, --duration: 压力测试持续时间, 例如: 2s, 2m, 2h
-s, --script: 指定使用的Lua脚本
-H, --header: 添加HTTP请求头, 例如: "User-Agent: wrk"
--latency: 打印详细的延迟统计信息
--timeout: 设置超时时间,从发出模拟请求到接收响应之间的时间超出timeout,即视为超时使用wrk
简单压测
对于一般的Get请求,进行简单压测,直接使用wrk命令并指定一些需要的参数即可

复杂压测
- 有些接口需要post参数或者token等才能访问
- 我们像自定义测试的结果形式
如何实现?wrk支持使用Lua脚本(官网的Lua脚本例子)
具体使用参考:https://www.jianshu.com/p/81136edd6333
部署
这里部署一个简单地Gin框架项目
初始化项目
go mod init DockerBuild新建文件main.go
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"msg": "ok",
})
})
r.Run(":8888")
}Docker部署
FROM golang
# 为镜像设置必要的环境变量(Go编译时需要)
ENV CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
# 容器内,移动到`/build`内
WORKDIR /build
# 将本地文件 复制 到容器内(第一个点是执行docker build命令所在的目录,第二个点是容器内的路径,即在/build目录下)
COPY . .
# 将代码编译成二进制可执行文件(文件名为app),这个点是容器内的/build目录下
RUN go build -o app .
# 声明服务端口
EXPOSE 8888
# 启动容器时运行的命令(点是容器内路径/build目录,即运行/build/app文件)
CMD ["./app"]注意,From中指定的golang:alpine镜像仅仅是编译Go源代码才需要,编译后的可执行程序并不依赖任何环境 ,就可以直接运行,所以有了多阶段构建技术
多阶段构建
###################
# 1、指定一个builder名为go-builder
###################
FROM golang As go-builder
# 为我们的镜像设置必要的环境变量
ENV CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
# 移动到工作目录:/build
WORKDIR /build
# 将代码复制到容器中
COPY . .
# 将我们的代码编译成二进制可执行文件app
RUN go mod tidy && go build -o app .
###################
# 2、--from=go-builder引用该builder
###################
FROM alpine
COPY --from=go-builder /build . #复制go-builder的/build目录复制到容器的根目录
# 声明服务端口
EXPOSE 8888
# 启动容器时运行的命令
CMD ["./app"]两种方式打包的镜像,大小差异:

后端项目部署不仅仅是部署代码,相关的mysql、redis等服务也要部署后端代码部署到一个容器中,mysql、redis也要分别部署到不同容器中,所以有了关联容器的方案
关联容器
独立部署
使用nohup、supervisor来运行Go编译后的可执行文件,使其作为后台守护进程运行
参见这篇文章:https://www.liwenzhou.com/posts/Go/deploy_go_app/
这种方式大多用来部署一些小型的项目
对于大型项目或者正式的商业化项目来说,更多的还是使用下面的方式部署