python爬虫进阶学习笔记
爬虫流程
抓取目标url
使用Python发送请求
解析返回的数据 【xpath,bs4】
[取到的多条数据,拼接成一个一个的字典] 比如:解析出两个列表,学校名和学校官网,需要把学校名和对应的学校官网拼接
{ name:"清华大学" web:"XXXX.com" }找新的url
使用Python发送请求
解析返回的数据
数据持久化:json、csv 、MongoDB 、resdis 、mysql
python3 提供的原生模块: urlib.request
第三方模块 :requests
urllib模块
Get请求
Get请求:向url发送请求,参数是以键值对的形式传递的,使用urllib.request.urlopen(url)【注意参数不能包含中文否则报错】
使用urllib.parse.quote 和string 将中文进行URL编码。具体网页如何解码,要看网页的meta标签的charset属性指定使用什么方式进行编码
pythonimport urllib.request #下面的两个包是把url中出现的汉字进行转译 import urllib.parse import string def get_method_param(): url="http://www.baidu.com/s?wd=" final_url=url+"美女" #网址中包含汉字必须转译成url编码,否则urlopen函数报错 encode_new_url=urllib.parse.quote(final_url,safe=string.printable) print(encode_new_url) #打印:https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3 #发送网络请求,返回对象(二进制的) response=urllib.request.urlopen(encode_new_url) #将返回的二进制数据,需要使用decode解码成文字 data=response.read().decode("utf-8") #把整个网页html代码打印出来了 print(data) #encode是编码,意思是使用utf-8编码,写入文件 with open("good_gril.html","w",encoding="utf-8")as f: f.write(data) #函数调用 get_method_param()上面是含一个中文字符串,如果是多对键值对,如何处理?
使用urllib.parse.urlencode()将整个键值对中的中文进行URL编码,自动在不同键值对之间添加&隔开
python#字典 params={ "wd":"中文", "key":"zhang", "value":"san" } #使用 str_params=urllib.parse.urlencode(params) print(str_params) #控制台输出=》wd=%E4%B8%AD%E6%96%87&key=zhang&value=san final_url=url+str_params #发送网络请求,返回对象(二进制的) response=urllib.request.urlopen(final_url)
Post请求
Post请求,添加到请求头,需要使用使用urllib.request.urlopen(request)
#添加请求头
a={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
#添加参数
b={
"wd":"中文",
"key":"zhang",
"value":"san"
}
#把请求头赋值给请求头headers,参数赋值给data,与url组成request
request=urllib.request.Request(url,headers=a,data=b)
#直接用request发起请求
response=urllib.request.urlopen(request)修改request
#方法一:
#添加请求头
a={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
#把对象,赋值给请求头headers,与url组成request
request=urllib.request.Request(url,headers=a)
#直接用request发起请求
response=urllib.request.urlopen(request)
#方法二:
#向request中的添加url
request=urllib.request.Request(url)
#向request中的请求头添加键值对
request.add_header("Ha","en")查看request
#获取请求对象request的url
request.get_full_url()
#获取请求对象request的请求头信息
request.headers
#获取请求头中对应key的值
request.get_header("User-agent")#取出User-agent
request.get_header("Cookie") #取出Cookie应用
通常为了将请求伪装成浏览器发起的请求,往往向请求头添加User-agent字段,为了更加真实的模拟用户用浏览器访问,用random随机赋值User-agent,不容易被反爬虫机制发现
使用 random 模块,用random.choice 实现随机效果
import urllib.request
import random
def load_data():
url="https://www.baidu.com/"
#[]是列表数据类型,百度的User_agent大全,写了4个
user_agent_list=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201"
]
#随机从列表中选择一个元素
random_user_agent=random.choice(user_agent_list)
#将url加入request
request=urllib.request.Request(url)
#将键值对加入request的请求头
request.add_header("User-agent",random_user_agent)
#通过request对象发起请求
response=urllib.request.urlopen(request)
#调用Load_data()函数
load_data()使用代理发起网络请求
IP代理
虽然用User-agent可以模拟不同的浏览器,但是发送请求的IP地址是一样的,很容易发现是爬虫。
所以这里我们提到IP代理的使用。
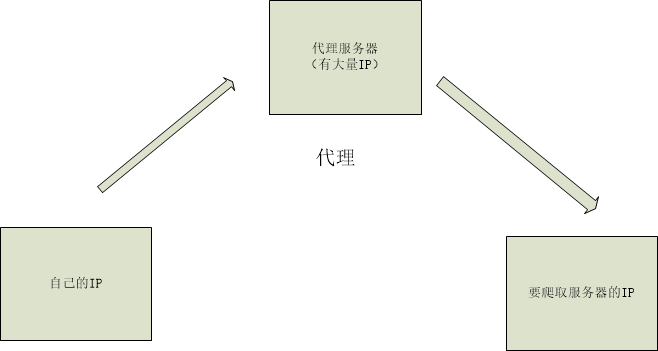
目前IP代理:免费的,时效性差,错误率高。付费的IP,贵,但是也有失效的IP
免费快代理
IP的分类:
| 类型 | 详情 |
|---|---|
| 透明IP | 对方知道我们的真实IP |
| 匿名IP | 对方不知道我们真实的IP,但知道我们使用了代理 |
| 高匿IP | 对方不知道我们真实的IP,也不知道我们使用了代理 |
创建handler处理器
因为urlopen的函数并没有提供代理的功能,所以我们得自定义这个功能
主要思路:1.创建handler处理器 【有好多handler,不同的handler功能不同】 2.用handler创建opener请求数据 3.调用opener.open(url,[timeout])/opener.open(request)【添加请求头的方式,需要传的参数是request】,返回response对象,timeout是设置访问url的超时时间,一旦超时就会报错
HTTPHandler
只能简单的发送http网络请求,不能使用IP代理
import urllib.request
def handler_opener():
url="https://www.cnblogs.com/jeavy/p/11205653.html"
#1.创建自己的handler,httphandler这个不能使用IP代理
handler=urllib.request.HTTPHandler()
#2.使用handler创建自己的opener
opener=urllib.request.build_opener(handler)
#3.调用opener的open方法向url发起请求
response=opener.open(url)
data=response.read().decode("utf-8")
print(data)
handler_opener()ProxyHandler 【IP代理】
proxyHandler的参数就是代理IP的键值对,可以使用代理IP
import urllib.request
def creact_proxy_handler():
url="https://www.cnblogs.com/jeavy/p/11205653.html"
#添加代理
proxy={
#协议类型(有http和https):IP地址
"http":"223.199.24.230:9999"
}
#1.创建自己的handler
handler=urllib.request.ProxyHandler(proxy)
#2.用handler创建自己的opener
opener=urllib.request.build_opener(handler)
#3.调用opener的open方法,返回response对象
response=opener.open(url)
data=response.read().decode("utf-8")
print(data)
creact_proxy_handler()实际中遇到的问题:
- 我们往往使用大量的使用代理IP,才能隐藏是使用爬虫来访问
- 使用的IP中,可能存在失效IP,必须用try,catch,防止程序报错而终止
- 买的付费的IP,一般都会有开发文档,根据开发文档来写
import urllib.request
def proxy_user():
url="https://www.cnblogs.com/jeavy/p/11205653.html"
#创建handler需要用字典,但是要储存多个IP,用LIst列表然后嵌套字典
proxy_list=[
{"http":"223.199.24.230:9999"},
{"https":"123.149.136.241:9999"},
{"https":"144.123.68.25:9999"},
{"https":"223.199.22.71:9999"},
{"http":"223.199.29.227:9999"}
]
#for循环,proxy是便利的元素
for proxy in proxy_list:
#print(proxy)
#创建handler
proxy_handler=urllib.request.ProxyHandler(proxy)
#创建opener
proxy_opener=urllib.request.build_opener(proxy_handler)
#调用opener的open方法发起请求
#但是有的IP本事无法使用,所以用try catch
try:
proxy_opener.open(url,timeout=1)
print("1")
except Exception as e:
print(e)
proxy_user()HTTPBasicAuthHandler【Http基础验证/auth认证】
HTTPBasicAuthHandler的参数是密码管理器
用于Http基础验证/auth认证
什么是Http基础验证/auth认证呢?
1、客户端发送http request 给服务器,服务器验证该用户是否已经登录验证过了,如果没有的话,服务器会返回一个401 Unauthozied给客户端,并且在Response 的 header “WWW-Authenticate” 中添加信息。
2、浏览器在接受到401 Unauthozied后,会弹出登录验证的对话框。用户输入用户名和密码后,浏览器用BASE64编码后,放在请求头的Authorization字段中发送给服务器。如下图:
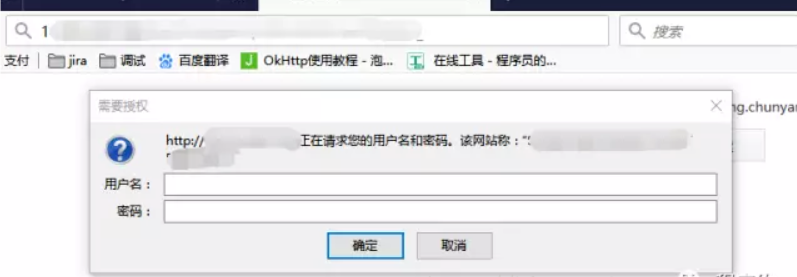
使用Python通过基础验证
import urllib.request
def auth_neiwang():
#用户名和密码
user="admin"
pwd:"admin123"
neiwang="http://192.168.179.66"
#创建密码管理器
pwd_manager=urllib.request.HTTPPasswordMgrWithDefaultRealm()
pwd_manager.add_password(None,neiwang,user,pwd)
#1.创建自己的handler
auth_handler=urllib.request.HTTPBasicAuthHandler(pwd_manager)
#2.用handler创建自己的opener
opener=urllib.request.build_opener(auth_handler)
#3.调用opener的open方法,返回response对象
response=opener.open(neiwang)
print(response)
auth_neiwang()HTTPCookieProcessor【cookie认证】
HTTPCookieProcessor参数是cookiejar
通过爬虫直接访问在任何网站的个人中心网址,肯定会被重定向到登陆页面
但是有的网站使用cookie存储用户的登录信息,只要用户登陆在浏览器登录过,我们可以直接使用cookies进入个人中心,进而爬取数据
方式一:找到cookie,手动粘贴到代码中,并添加到请求头
#1.向请求头中,填入cookies字段,就可以以登陆状态,进入网站
import urllib.request
def load_data():
url="https://www.baidu.com/"
#1.创建请求对象
header={
#浏览器的版本
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
#cookies的内容
"coookies":"XXXXXXX"
}
#2.把header的信息都填入请求对象request之中
request=urllib.request.Request(url,headers=header)
#3.使用代码发送网络请求,respones是返回的是object对象
response=urllib.request.urlopen(request)
#读取object对象 ,返回 bytes类型(二进制类型)
data=response.read()
#把bytes内容转解码成字符串
str_data=data.decode("utf-8")
# print(str_data)
#4.将数据写入文件,和代码在同一目录下
with open("baidu.html","w",encoding="utf-8")as f:
f.write(str_data)
#调用Load_data()函数
load_data()方式二:代码自动登录,自动保存cookie,不用手动粘贴cookie,在带着cookie访问个人中心
使用药智网,作为例子 ==>https://www.yaozh.com/login/

这里需要注意,因为我们要添加请求头,所以用的oper.open(request)
import urllib.request
#这个包,用来把get请求中参数部分的中文转成URL编码
from urllib import parse
#使用这个包,自动保存cookie
from http import cookiejar
#1.用代码登录
#1.1登录网址【在登陆页面,右键检查,在network中找到login文件】
login_url="https://www.yaozh.com/login/"
#1.2登陆参数【在登录页打开网页调试,在network中勾选preserve log(保存上个页面的请求),输入账号密码点击登录跳转页面,然后在login中找到form data参数】
login_form_data={
#账号密码
"username":"heyingjie",
"pwd":"heyingjie1996",
#这两个参数,和登录页有关系,在网络调试器的elements中ctrl+f可以查找到两个参数
"formhash":"18280DC67C",
"backurl":"https%3A%2F%2Fwww.yaozh.com%2F"
}
#对参数中含有中文,要转移成URL编码
encode_login_form_data=parse.urlencode(login_form_data).encode("utf-8")
#请求头
header={
#创建键值对要求键名必须首字母大写,其余位置字母小写
#浏览器的版本
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
#1.3发送登录请求POST【这个网站是用post登陆的】
#实例化cookiejar
cook_jar=cookiejar.CookieJar()
#定义有cookie功能的handler,这个handler的参数是cookiejar
cookie_handler=urllib.request.HTTPCookieProcessor(cook_jar)
#定义opener
cookie_opener=urllib.request.build_opener(cookie_handler)
#Post请求,把header的信息和提交参数,都填入请求对象request之中
cookie_request=urllib.request.Request(login_url,headers=header,data=encode_login_form_data)
#发请求,如果登陆成功自动保存cookie,之后用opener的open()访问其他,就会自动带上cookie
cookie_opener.open(cookie_request)
#2.带着cookies去访问
center_url="https://www.yaozh.com/member/"
#创建请求头
center_request=urllib.request.Request(center_url,headers=header)
#使用之前创建的opener来发起请求,因为opener里面有之前获取的cookie
response=cookie_opener.open(center_request)
#保存下来
data=response.read().decode("utf-8")
with open("center.html","w",encoding="utf-8")as f:
f.write(data)urllib.request.openurl提示错误
两种HTTPError和URLError
HTTPError :比如404页面找不到
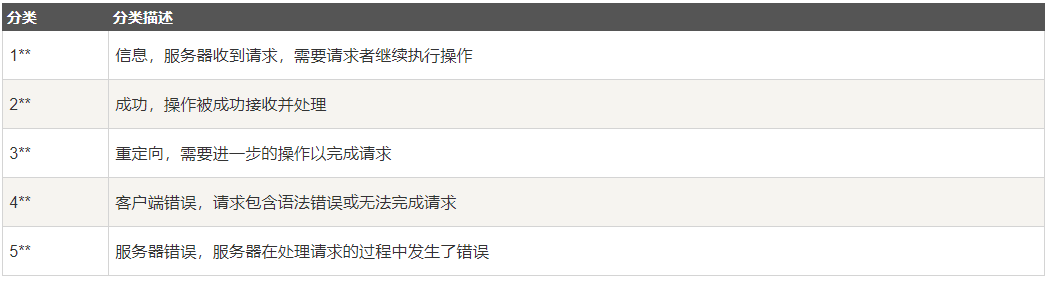
URLError :url不存在
try:
response=urllib.request.urlopen(url)
except urllib.request.HTTPError as error:
#打印出http状态码
print(e.code)
except urllib.request.URLError as error:
print(e.code)requests模块
目前用的最多的第三方模块。优点:更加简单易用,自动将中文转成URL编码
安装
pip install requestsGet请求
request.get(url,[header=字典],[param=字典],[cookies=字典],[json=字典],[auth=字典],[timeout=数字],[proxies=字典],[verify=true/false])header用来给请求头加字段
param用来传参数,如果包含中文,自动转化为URL编码
verify当访问https的网站时,false表示,忽略SSL认证
response=requests.get函数返回值的相关函数:
#1.发送get请求和添加参数
response=requests.get(url,headers=header)
#1.1获取整个请求头(里面有很多字段,包括cookie)
requests_header=response.request.headers
#1.2获取请求头中的cookie
requests_cookie=response.request._cookies
#1.3获取整个响应头(里面有很多字段,包括cookie)
response_header=response.headers
#1.4获取响应头中的cookie
request_cookie=response.cookies
#1.5响应http状态码
code=response.status_code
#1.5实际请求的URL
url=response.url
#1.6 请求返回html数据,content是二进制内容,需要解码
data=response.content.decode("utf-8")
print(data)
#1.7返回的数据是json格式时
data_json=response.json()
#打印整个json数据
print(data_json)
#取出message字段的值
print(data_json["message"])不同的返回数据
- 当请求返回的是html页面
import requests
import json
url="https://www.baidu.com"
header={
#创建键值对要求键名必须首字母大写,其余位置字母小写
#浏览器的版本
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
response=requests.get(url,headers=header)
#content返回的是bytes二进制,encode转成str字符串
data=response2.content.decode("utf-8")
data=response.content.decode("utf-8")
with open("meinv.html","w",encoding="utf-8") as f:
f.write(data)- 请求返回的是json数据
方式一:通过json模块, 字符串——>字典。适用于:返回的数据,先content.decode()成字符串类型,然后进行自己的处理,然后将处理好的字符串,转化成json
import requests
import json
url2="https://api.github.com/user"
response2=requests.get(url2,headers=header)
#content返回的是bytes二进制,encode转成str字符串
data=response2.content.decode("utf-8")
#把str转成字典,需要import json
#data_dict是字典
data_dict=json.loads(data)
print(data_dict)
#取出字典键对应的值
print(data_dict["message"])方式二:直接使用requests的内置方法,转化为字典。适用于:返回的数据不需要处理,直接转化成json形式
import requests
url2="https://api.github.com/user"
response2=requests.get(url2,headers=header)
#更加方便的方法取出键的值==>用response的json()函数,直接返回对应的字典dict或者列表list,
data_json=response2.json()
#打印整个json数据
print(data_json)
#取出message字段的值
print(data_json["message"])Post请求
request.post(url,[header=字典],[data=字典],[cookies=字典],[json=字典],[auth=字典],[timeout=数字],[proxies=字典],[verify=true/false])Get和Post仅有传参字段不一样,Post请求中,data用来传递参数;Get请求中,用param来传递参数
使用代理发起网络请求
IP代理
使用proxies参数
import requests
url="http://www.baidu.com"
header={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
free_proxy={"http":"114.223.62.43:9999"}
#IP可能会失效
try:
response=requests.get(url,headers=header,proxies=free_proxy,timeout=1)
print(response.status_code)
except Exception as e:
print(e)Http基础验证/auth认证
auth=(user,pwd)
response=requests.get(url,auth=auth)SSL认证
访问https的网站,网站需要有CA颁发的证书才行。
CA是负责签发证书、认证证书、管理已颁发证书的机关。它制定政策和具体步骤来验证、识别用户身份,并对用户证书进行签名,以确保证书持有者的身份和公钥的拥有权。SSL证书就是CA机构签发的。
公认的证书颁发机构的CA证书是默认内置在我们的操作系统或者浏览器当中的,也就是客户端操作系统默认信任的证书。
我们可以给自己颁发数字证书(SSL证书、邮件证书、客户端证书、代码证书等),自己签发的证书不需要花钱。然而,自签发的数字证书默认是不受到客户端操作系统信任的,所以他们访问我们的站点的时候就会提示不信任。
访问https的网站,如果网站没有CA颁发的受信任SSL证书,浏览器就会中断连接,并提示

#12306是https网站 ,但是它不是第三方的CA证书,是他自己颁布的证书
#解决方法:添加verify参数为false。告诉服务器,忽略证书
import requests
url="https://www.12306.cn"
header={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
response=requests.get(url,headers=header,verify=False)
data=response.content.decode("utf-8")
with open("ssl_test.html","w",encoding="utf-8") as f:
f.write(data)cookie认证
方式一:粘贴cookie,然后把cookie变成字典形式,传入requests.get中
import requests
url="https://www.yaozh.com/member/"
header={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
#字符串cookies
cookies="acw_tc=2f624a3915808756962682370e648cacc4be39414c87db82068bcd666e0a4d; _ga=GA1.1.1215331318.1580875789; PHPSESSID=l48id5ka9m98484mb3v0br3vo1; _gid=GA1.2.1727011553.1581154549; _gat=1; Hm_lpvt_65968db3ac154c3089d7f9a4cbb98c94=1581154551; yaozh_logintime=1581154552; yaozh_user=875728%09heyingjie; yaozh_userId=875728; yaozh_jobstatus=kptta67UcJieW6zKnFSe2JyXnoaZbppsl5yHnKZxanJT1qeSoMZYoNdzcJtamsjey8%2FLzsqch3DYnp6bVaOWq6XArZqgxlig13NokXJUlJq016A791238C639D5e8D15b6daF703C92akZ2ckmmWa4ef2JtncVesms6eU27UcJaXc1mSbWqUlpeVmZmTaptmh5%2Fi14e21605c1c29f3d20c362a7d5ff8a2d; db_w_auth=747788%09heying"
#cookies的字符串,split分割后成为列表list
cook_dict={}
#处理字符串成字典
cookies_list=cookies.split("; ") ##字符串中 分号后有空格
##for循环写法,字典的键值赋值方法,split分割后[0]代表前部分,[1]代表后半部分
for cookie in cookies_list:
cook_dict[cookie.split("=")[0]]=cookie.split("=")[1]
#核心是多了一个cookies的参数
response=requests.get(url,headers=header,cookies=cook_dict)
data=response.content.decode("utf-8")
with open("requests_cookies.html","w",encoding="utf-8") as f:
f.write(data)方式二:使用账号密码登录后,获取cookie,以后使用cookie登录
使用药智网,作为例子 ==>https://www.yaozh.com/login/
session=requests.session()
session.get/post()发起请求后,会自动保存cookie,在下一次用sessions.get/post()访问时,自动带上cookie
import requests
#1.用代码登录
##session类 可以自动保存cookies 类似于之前用urllib库的时候,用的cookjar
session=requests.session()
login_url="https://www.yaozh.com/login/"
login_form_data={
#账号密码
"username":"heyingjie",
"pwd":"heyingjie1996",
#这两个参数,和登录页有关系,在网络调试器的elements中ctrl+f可以查找到两个参数
"formhash":"5BCC27EEF0",
"backurl":"https%3A%2F%2Fwww.yaozh.com%2F"
}
header={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
##查看网络调试器,登陆页面的请求方式是POST
login_response=session.post(login_url,data=login_form_data,headers=header)
#2.登陆成功后 带着 有效的cookies访问请求数据目标,登录成功后查看网络调试器,请求个人中心的方式是get
member_url="https://www.yaozh.com/member/"
member_response=session.get(member_url,headers=header)
data=member_response.content.decode("utf-8")
with open("requests_cookies2.html","w",encoding="utf-8") as f:
f.write(data)数据解析
补充:数据类型转换
使用requests模块,data=response.content.decode("utf-8") 的结果是字符串
无论是使用正则表达式还是xpath解析,都是使用字符串作为参数
但是,解析后返回的类型有的是列表,有的是字符串
字符串——>字典/json
使用json模块,json.loads(字符串)
import requests
import json
url2="https://api.github.com/user"
response2=requests.get(url2,headers=header)
#content返回的是bytes二进制,encode转成str字符串
data=response2.content.decode("utf-8")
#把str转成字典,需要import json
#data_dict是字典
data_dict=json.loads(data)
print(data_dict)
#取出字典键对应的值
print(data_dict["message"])字典/json——>字符串
使用json模块,json.dumps(列表),返回值是字符串
常用于,将json以文本的形式保存下来
with open("school.json","w",encoding="utf-8") as f:
f.write(字符串类型)补充:数据拼接
详见xpath例子1
正则表达式
使用正则表达式,需要引入re模块
引入模块: import re
指定内容,一次匹配,能匹配的数量(符号前加要匹配的内容),比如 [0-9]{4}是匹配四个数字
| 符号 | 含义 |
|---|---|
* | 匹配零个或多个[0-多] |
+ | 匹配一个或多个[1-多] |
? | 匹配零个或1个[0-1] ,即可用于表示,有无。 |
{n} | 匹配n个 |
{n,} | 匹配多余n个 |
{n,m} | 匹配n到m个 |
匹配位置
| 符号 | 含义 |
|---|---|
^ | 匹配的开始 |
^a | 匹配以a开头的 |
$ | 匹配的结尾 |
f$ | 匹配以f结尾的 |
匹配内容
| 符号 | 含义 |
|---|---|
. | 匹配任意字符(除\n) |
默认贪婪模式,a123b456b匹配a.*b会匹配的最后一个b
在正则后面加?,就会变成非贪婪
import re
one="a123b456b"
pattern=re.compile("a.*b")
result=pattern.findall(one)
print(result) #打印 ['a123b456b']
pattern2=re.compile("a.*?b")
result2=pattern2.findall(one)
print(result2) #打印 ['a123b'][]指定匹配范围
| 符号 | 含义 |
|---|---|
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [\u4e00-\u9fa5] | 匹配中文 |
| [aeiou] | 匹配中括号内的任意一个字母 |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [Pp]ython | 匹配 "Python" 或 "python" |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
匹配后,取出的内容
| 符号 | 含义 |
|---|---|
| () | 括号内的部分是匹配出来的 |
import re
one="A123A"
pattern=re.compile("A.*A")
result=pattern.findall(one)
print(result) #打印['A123A']
#带括号的
pattern=re.compile("A(.*)A")
result=pattern.findall(one)
print(result) #打印['123']匹配函数
pattern=re.complie(正则字符串,修饰符)构造匹配模式
pattern的方法有:match,search,findall。参数是要匹配的字符串
match 从头匹配 匹配一次 返回字符串
import re
one="123abc456"
pattern=re.compile("\d+")
result=pattern.match(one)
print(result) #<re.Match object; span=(0, 3), match='123'>
print(result.group())#打印 123
two="abc123"
pattern2=re.compile("\d+")
result2=pattern2.match(two)
print(result2) #打印 Nonesearch 从任意位置 匹配一次 返回字符串
import re
one="123abc456"
pattern=re.compile("\d+")
result=pattern.search(one) #打印 123 ,如果one=a123b45也是打印123,但是match就匹配不到了
print(result)findall 查找符合正则的 匹配多次 返回列表
import re
one="123abc456"
pattern=re.compile("\d+")
result=pattern.findall(one)
print(result) #打印 ['123', '456']sub 多次匹配 把匹配到的所有符合要求的部分替换为第一个参数 返回字符串
import re
one="123abc456"
pattern=re.compile("\d+")
#sub 替换字符串 返回字符串
result=pattern.sub("#",one)
print(result) #打印 #abc#split 拆分
import re
one="123abc456"
pattern=re.compile("\d+")
#split 拆分 返回list
pattern=re.compile("\d+")
result=pattern.split(one)
print(result) #打印 ['', 'abc', '']匹配中文
import re
one="123abc456"
pattern=re.compile("\d+")
#匹配中文
two="acmkldclskdn版权所有,翻版必究"
pattern=re.compile("[\u4e00-\u9fa5]+")
result6=pattern.findall(two)
print(result6) #打印['版权所有', '翻版必究']修饰符
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
xpath
安装
pip install lxml引用
from lxml import etree转类型(把string类型转成对应的xpath的类型)
#data是string型,所以需要用response.content.decode("utf-8")
data_xpath=etree.HTML(data)解析数据 (返回值是列表型)
data_xpath.xpath('xpath语句')xpath的语法:
节点 :/
就是找到html标签下的head标签下的title标签
/html/head/title跨节点://
有时候网页的层级很多,一层一层的结点,会写很多。用跨结点会更快
把整个网页中title标签找到
//title选择条件[ ]
精确选中标签: a[@属性="属性值"] a是标签名
python//找到整个html页面中,a标签中mon属性值是ct=1的a标签 a[@mon="ct=1"]标签有下标(下标从1开始)
python//表示第3个li标签 li[3]python//编号大于2的span标签 span[position()>2]模糊查询
python//使用contain包裹,@后是属性名,下一个参数是属性值,这个属性值可以是原本属性值的一部分。例如class=“abdc”,会被匹配到 div[contain(@class,"a")]
获取标签包裹的内容
找到整个html页面中,a标签中包裹的文字
//a/text()
//有时候,标签包裹的内容含有空格和回车
normalize-space(//a/text())注意:
<h1>
你好
<span>哈喽</span>
<h2>xpath路径//h1/text()只会输出 你好,后面的,<span>标签不会带上
获取标签的属性
//a/@href下一个节点(是平级的下一个兄弟节点)
/following-sibling::\*xpath语句中添加变量
#可以变量控制,取得具体的路径
#变量是index,从0到10;{}是变量放在的位置
s1 = data_xpath.xpath("//div[@id=\"lists\"]/a[{}]/div/div[1]/div[2]/div[2]/*/text()".format(index))例子1【数据拼接】
拼接以后的数据形式

注意点
- xpath语句出现了双引号,要用转义字符\
- 用for循环实现拼接
- 对于school_level字段,不同的学校的数据个数是不一样的,需要单独处理
import requests
from lxml import etree
import json
url="https://souky.eol.cn/jd/school/lists?uc_biz_str=OPT%3aW_ENTER_ANI%401%7cOPT%3aTOOLBAR_STYLE%401%7cOPT%3aS_BAR_BG_COLOR%40FFFFFF"
header={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
response=requests.get(url,headers=header)
data=response.content.decode("utf-8")
data_xpath=etree.HTML(data)
#取数据拼接数据
school_img_list=data_xpath.xpath("//div[@class=\"school-img\"]/img/@src")
school_name_list=data_xpath.xpath("//span[@class=\"name\"]/text()")
school_type_list=data_xpath.xpath("//div[@class=\"school-tip\"]/span[1]/text()")
school_address_list=data_xpath.xpath("//div[@class=\"school-adress\"]/span/text()")
schools=[]
for index,item in enumerate(school_img_list) :
school_info={}
school_info["school_name"]=item
school_info["school_img"] = school_img_list[index]
school_info["school_type"] = school_type_list[index]
school_info["school_address"] = school_address_list[index]
school_info["school_level"]= data_xpath.xpath("//div[@id=\"lists\"]/a[{}]/div/div[1]/div[2]/div[2]/span[position()>1]/text()".format(index+1))
schools.append(school_info)
#print(schools)
final_data=json.dumps(schools)
with open("school.json","w",encoding="utf-8") as f:
f.write(final_data)例子2【url参数翻页】
注意点
- 封装成类的形式
- 通过控制拼接url,实现翻页
import requests
#导入json库
import json
#导入xpath
from lxml import etree
class BtcSpider(object):
#init相当,java中构造函数,把信息存入self中,其中的变量类似于java的私有变量
def __init__(self):
self.base_url="https://www.chainnode.com/forum/1"
self.header={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}
#用来存文章标题和对应url的list
self.data_list=[]
#1.发请求 ===>接收self中的私有变量,和调用时传入的url,返回 请求返回的数据data(str格式)
def get_response(self,url):
response=requests.get(url,headers=self.header)
#content返回的是byte二进制,decode后成为字符串str
data=response.content.decode("utf-8")
return data
#2.解析数据===>接收self中的私有变量,和发送请求后返回的请求data
def parse_data(self,data):
#使用xpath解析页面结构
#1.转换类型
x_data=etree.HTML(data)
#2.根据xpath路径解析(粘贴两个文章标题的html结构)
#<a href="/event/408554" target="_blank" class="link-primary font-bold bbt-block" data-v-0713d2ac=""><!----> 2020开工值得学:巴比特产业迎新大课
# </a>
#<a href="/post/408628" target="_blank" class="link-dark-major font-bold bbt-block" data-v-0713d2ac=""><!----> 人们并不关心真相,人本质上都是为自己的价值观服务
# </a>
#取出文章标题(list)
title_list=x_data.xpath('//a[@class="link-dark-major font-bold bbt-block"]/text()')
#取出文章url(list)
url_list=x_data.xpath('//a[@class="link-dark-major font-bold bbt-block"]/@href')
#enumerate是枚举类型,用for循环 把每一个文章和标题变成一个字典news,并放入私有变量self.data_list中
for index,title in enumerate(title_list):
# print(index)
# print(title)
news={}
#{"name":"文章标题","url":"文章对应的网址"}
news["name"]=title
news["url"]=url_list[index]
self.data_list.append(news)
# 3.保存数据===>解析数据时,把文章和url放入self的data_list中,这个函数把self中的数据保存到文件
def save_data(self):
#将列表转换成json
data_str=json.dumps(self.data_list)
with open("btc.json","w",encoding="utf-8") as f:
f.write(data_str)
#4启动===>按照 发起请求 解析数据 保存数据
# 调用的函数参数是self的调用方法是 self.函数
def run(self):
#4.1拼接 完整url
#观察翻页的url特点,大多是在网页后加上 "-页数",这个for循环是从2页到10页
for i in range(2,10):
url=self.base_url+"-"+str(i)
#4.2.发送请求
data=self.get_response(url)
print(url)
#4.3做解析
self.parse_data(data)
#4.4保存
self.save_data()
#建立连接后要中断
s = requests.session()
s.keep_alive = False
BtcSpider().run()例子3【待完善,翻页url不动,异步请求数据】
这种需要在浏览器抓包,看一下触发异步加载时,网页请求的API,以及返回的JSON
快速找到元素的xpath语句

bs4
安装
pip install beautifulsoup4引用
from bs4 import BeautifulSoup数据持久化
JSON
引入json模块
json和json型的字符串看起来是一样的,但是json对象可以通过键名得到对应的值,方便操作
不同函数函数返回值 有的是 json有的是字符串
而有些函数的参数要求,必须是json或者是字符串
所以有了转化类型的需要

import json
#1.字符串 和 dict list转换
#str--->list
data='[{"name":"张三","age":20},{"name":"李四","age":18}]'
list=json.loads(data)
#list--->str
list2=[{"name":"张三","age":20},{"name":"李四","age":18}]
data_json=json.dumps(list2)
#2.文件对象 和 dict 转换
# dict list 写入文件 ,这个没有用引号引起来是list
list2=[{"name":"张三","age":20},{"name":"李四","age":18}]
#list--->str———>存进文件
data_json2=json.dumps(list2)
with open("1.json","w") as f:
f.write(data_json2)
#更加简单的方法,直接把list dict-->文件
json.dump(list2,open("2.json","w"))
#读取文件json--->list dict
result=json.load(open("2.json","r"))
print(result)CSV
引入csv模块
json文件——>csv
open读进来的是字符串格式,需要json.load转换成字典/json格式
import json
import csv
#json--->csv
#1.分别是 读json ,创建csv,
json_fp=open("2.json","r")#返回的是字符串型
csv_fp=open("3.csv","w",newline='') #不加newline,会有空行
#2.转换成字典格式
# data_list的内容 [{"name":"张三","age":20},{"name":"李四","age":18}]
data_list=json.load(json_fp)
#3.创建表头
#data_list[0]是list中的第一个字典,key()是 dict_keys(['name', 'age'])
sheet_title=data_list[0].keys() #也可以,主动给表头赋值:sheet_title={"姓名","年龄"}
#4.创建表体数据
#data是list中的所有字典,value是dict_values(['张三', 20])和 dict_values(['李四', 18])]
sheet_data=[]
for data in data_list:
sheet_data.append(data.values())
#5.将创建的表头,表体,写入csv
writer=csv.writer(csv_fp)
#写入表头
writer.writerow(sheet_title)
#写入内容
writer.writerows(sheet_data)
#6.关闭两个文件
json_fp.close()
csv_fp.close()MongoDB
Redis
简介
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
开始起步
启动redis服务
下载压缩包,解压,解压文件就是安装目录,在该目录下,进入命令行【把bin目录添加到环境变量中,就可以在任何目录下的cmd窗口执行Redis命令了】,输入:
redis-server
//或者,这种是指定按照哪个配置文件启动。不写默认用redis.windows.conf启动
redis-server redis.windows.conf 出现:

进入redis命令行
这时候在安装目录,另启一个 cmd 窗口进行其他操作,原来的不要关闭,不然就无法访问服务端了。
pythonredis-cli出现:

证明进入redis命令行,在这个界面可以输入redis命令了
配置相关
查看配置项
config get *
config get 配置名修改配置项
CONFIG set 配置名 修改的值Window下修改配置更简单 :在安装目录下,以文本的形式打开以下文件,直接编辑文件

常见配置项
| 配置项 | 说明 |
|---|---|
| daemonize no | Redis 默认不是以守护进程的方式运行,可以通过该配置项修改,使用 yes 启用守护进程(Windows 不支持守护线程的配置为 no ,所以运行redis-server的cmd窗口,不能关闭) |
| port 6379 | 指定 Redis 监听端口,默认端口为 6379 |
| bind 127.0.0.1 | 绑定的主机地址 |
| databases 16 | 设置数据库的数量为16个,从0-15号,默认数据库为0,可以使用SELECT 命令在连接上指定数据库id |
slaveof <masterip> <masterport> | 设置当本机为 slave 服务时,设置 master 服务的 IP 地址及端口,在 Redis 启动时,它会自动从 master 进行数据同步 |
1.什么是守护进程?
守护进程(Daemon Process),也就是通常说的 Daemon 进程(精灵进程),是 Linux 中的后台服务进程。它是一个生存期较长的进程,守护进程是个特殊的孤儿进程,这种进程脱离终端。在 linux 中,每一个系统与用户进行交流的界面称为终端,每一个从此终端开始运行的进程都会依附于这个终端,这个终端就称为这些进程的控制终端,当控制终端被关闭时,相应的进程都会自动关闭。
由于 redis 采用的安全策略,默认会只准许本地访问。在配置文件中,加#注释掉,bind 127.0.0.1,否则只能本机访问这个redis服务
3.什么是master-slave
即主从复制,主机数据更新后根据配置和策略自动同步到备机的 master/slave 机制,Master以写为主,Slave 以读为主
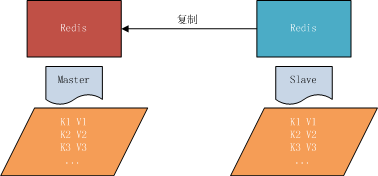
4.redis默认16个数据库,切换数据库。最开始默认在0号数据库
select 数字与Key相关的命令
查看所有key
keys *查看键名以on开头的
keys on*判断数据库是否存在某键名
exists 键名
//返回1,存在
//返回0,不存在查看键对应的值的类型
type 键名删除键和值(无论值是哪种类型都可以删除)
del 键名清空所有数据库(默认0-15,共16个数据库)
flushall清空当前所在数据库
flushdbvalue是字符串(String)
增加键值对
//存一个键值对
set key名 value值
//存多个
mset key1 aa key2 bb
//设置键值对存在时间
//3秒之后,键值对自动删除
setex key1 3 "abc"修改
set key1 a ,之后set key1 b,后面的会覆盖掉前面的,此时key1是b
查找键值对
//读取一个键值对
get key名
//读取多个键值对
mget key1 key2追加键值对
set key1 a
append key1 bcd
get key1 /输出abcd删除key,对应的值也就删除了
del 键名value是哈希(Hash)
添加值
hset person name "jack"
hset person age 18
hget person name /打印 jack
//一次设置多个字段,必须得先写一个字段,创建了person对象,才能下次插入多个键值对
hset person name "jack"
hset age 18 gender 1查询
//一次查所有键名
hkeys person
//一次查所有值
hvals person
//一次查指定键名的值
hmget person age name删除Hash中的某些字段
//删除person的name和age
hdel person name agevalue是列表(List)
从左侧推入列表
//在列表one中从左侧推入1
lpush one 1
//在列表one中从左侧推入2,3,4,5
lpush one 2 3 4 5
//从第零个元素,到最后一个
lrange one 0 -1 //输出5 4 3 2 1
从右侧推入列表
//在列表two中从右侧推入1
rpush two 1
//在列表two中从右侧推入2,3,4,5
rpush two 2 3 4 5
//从第零个元素,到最后一个
lrange two 0 -1 //打印 1 2 3 4 5
删除/出队
//two左侧出队
lpop two //出队1
//two右侧出队
rpop two //出队5
在指定位置插入
//linsert 键名 after 值1 值2 //在值1前插入值2
linsert two before 3 A
//linsert 键名 after 值1 值2 //在值1后插入值2
linsert two after 3 B
修改指定位置元素
//索引从0开始
lset two 1 C//two中元素是2 C 3 B 4删除指定值
lrem 键名 count 值
//count是大于0的任何数 从头删除第一个符合条件的值
//count是小于0的任何数 从尾删除第一个符合条件的值
//count=0 符合条件的所有删除//例子
rpush three 1 2 3 1 2 3
lrem three 1 1
lrange three 0 -1 //打印 2 3 1 2 3从左到右查看整个List
//从第零个元素,到最后一个
lrange one 0 -1value是集合(Set)
数据无序,不重复。没有修改
添加值
sadd 键名 元素1 [元素2 元素3]查看
smembers 键名按值删除
srem 键名 值判断值是否存在
sismember 键名 值value是有序集合(sorted set)
数据有序
增加(需要指定值的权重,用于排序)
zadd 键名 权重 值1 [权重 值2 权重 值3]查看
//查看所有数据,(按权重排序)
zrange 键名 0 -1//查看从权重1到权重2之间的数据
zrangebyscore 键名 权重1 权重2//查看指定值的权重
zscore 键名 值按值删除
zrem 键名 值按权重范围删除
zremrangebyscore 键名 权重1 权重2Redis与Python的交互
安装
pip install redis引入
import redis使用
import redis
#连接数据库,这个函数还有有很多参数,比如 password
client=redis.StrictRedis(host="127.0.0.1",port=6379,db=0)
#设置key名
key="pyone"
#增加String,添加成功返回ture
result=client.set(key,"1")
# print(result)
#删除,删除成功返回1
result2=client.delete(key)
# print(result2)
#修改,就是向已存在的key中set新值,就会覆盖原值
#查询,返回是二进制
result3=client.get(key) #[b'1']
result4=client.keys() #[b'pyone', b'one', b'two', b'three']
#print(result3)主从服务器
当项目访问量比较多 相应的数据库的读写操作就特别多,就会导致服务器受不了那么多用户的请求和对数据的操作,导致服务器负荷,相应的用户的等待时间就会特别长,给用户的体验特别差,而主从同步就很好的解决的这种并发的问题。主从同步:简单来说就是使用两台服务器,分别处理用户的读和写的操作,从而实现了读写分离。
主服务器master端,负责写数据
- 查找master端IP(不同系统,方式不一样,具体百度)
- redis.conf文件中,修改bind项为本机IP
- 重启服务 ,
redis-server redis.windows.conf/或者redis-server
从服务器salve端,负责读数据
- 复制master端的redis.conf文件,并改名slave.conf。粘贴到slave端
- 修改slave.conf文件
- bind项为master端的IP地址
- slave项为 master端IP地址和端口号 (redis默认端口是6379)
- port项为6378,这是slave端的端口号
- 按照salve.conf重启,
redis-server slave.conf

MySql
安装
视化安装,安装完就自动启动了Windows系统安装——详见
可以在搜索栏,搜索服务
通过可视化的方式启动/关闭 MySql服务
登录
注意:默认用户名是root,密码在安装过程中,设置过了
当 MySQL 服务已经运行时,进入MySql Server的安装目录的bin文件夹下【把文件夹下的bin目录添加到环境变量中,就可以先任何目录下使用MySQL命令了】, 进入命令行, 输入以下格式的命名:
mysql -h 主机名 -u 用户名 -p参数说明:
- -h : 指定客户端所要登录的 MySQL 主机名, 登录本机(localhost 或 127.0.0.1)该参数可以省略;
- -u : 登录的用户名;
- -p : 告诉服务器将会使用一个密码来登录, 如果所要登录的用户名密码为空, 可以忽略此选项。
如果我们要登录本机的 MySQL 数据库,只需要输入以下命令即可:
mysql -u root -p按回车确认, 如果安装正确且 MySQL 正在运行, 会得到以下响应:
Enter password:若密码存在, 输入密码登录, 不存在则直接按回车登录。登录成功后你将会看到 Welcome to the MySQL monitor... 的提示语。
然后命令提示符会一直以 mysq> 加一个闪烁的光标等待命令的输入, 输入 exit 或 quit 退出登录
可视化操作
使用Navicat等软件
命令行操作(记得加分号)
MySql版本号
select version();Mysql的所有数据库
show databases;进入指定数据库
//进入数据库
use 数据库名;
//查看当前所在数据库
select database();创建数据库
create database 数据库名 charset=utf8;删除数据库
drop database 数据库名;表相关
//进入数据库
use 数据库名;
//创建表,指明:列名,类型,约束
mysql> create table dog(
-> id int auto_increment primary key,
-> name varchar(10) not null
-> );
//修改表,增加列,指明:列名,类型,约束
alter table dog add birthday datetime;
//修改表,删除列
alter table dog drop birthday;
//修改表名,把表名dog改为cat
rename table dog to cat;
//删除表名
drop table 表名;
//查看表中的数据
select * from 表名;//显示数据库的所有表
show tables;
//查看表的所有字段的名字,类型,约束
desc 表名;13集 30分钟处 -15集
MySql与Python交互
安装
pip install pymysql引入
import pymysql使用
#放在try except之间防止报错
import pymysql
try:
#连接数据库
con=pymysql.Connect(
host="127.0.0.1",
port=3306,
db="aa",
user="root",
passwd="heyingjie1996",
charset="utf8"
)
#创建游标对象
cur=con.cursor()
#添加SQL语句
insert_sub='delete from dog where name="金毛"'
#执行SQL语句,返回受影响的行数
result=cur.execute(insert_sub)
print(result)
#SQL语句执行后,如果是查询语句,则返回所有查询的数据。其他语句执行正确返回None
print(cur.fetchone())
#提交事务
con.commit()
#关闭事务
cur.close()
#关闭连接
con.close()
except Exception as e:
print(e)Scrapy框架
框架结构
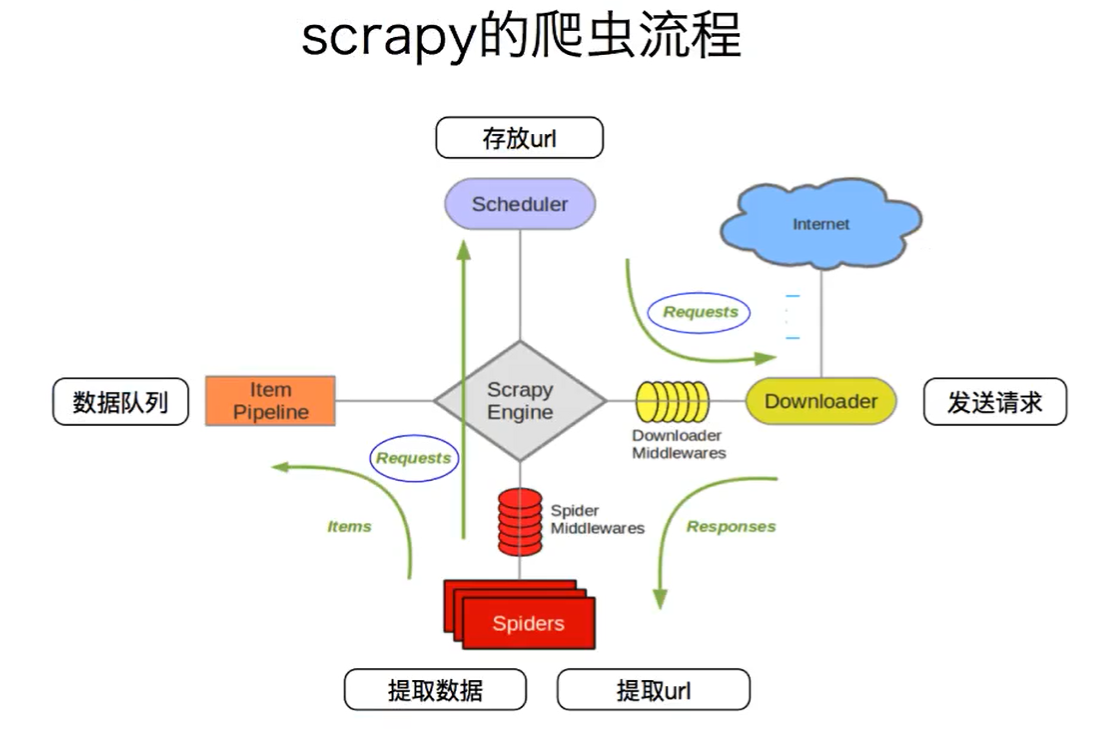

Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。
基本流程
安装
pip install scrapy新建scrapy项目
//在要建项目的目录,进入cmd,输入
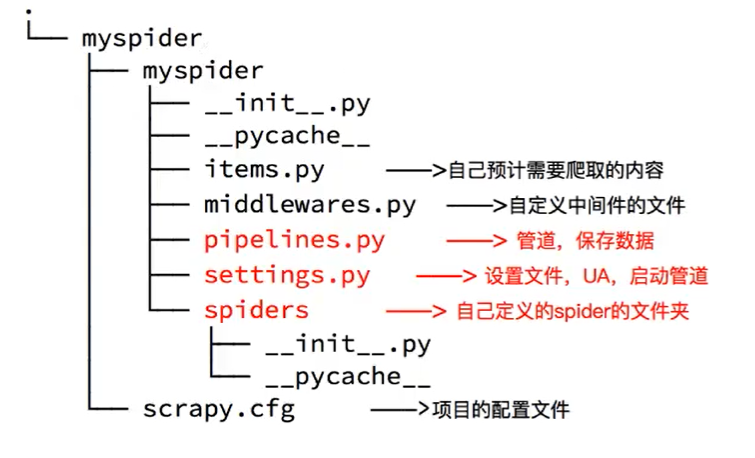
scrapy startproject 项目名新建项目mySpider的目录结构
初始化一个爬虫
//在项目根目录执行:
scrapy genspider 爬虫名 爬取的范围启动爬虫
//在项目根目录执行:
scrapy crawl 爬虫名提取数据
- 完善
Spider模块,使用xpath方法取到数据
保存数据
- 完善
Item Pipeline模块,在pipeline中保存数据
具体化流程
新建scrapy项目
scrapy startproject mySpider
生成目录结构

初始化爬虫
cd mySpider //在项目根目录下
scrapy genspider itcast itcast.cn一个项目往往是创建多个爬虫,但都是在spiders文件夹下创建以爬虫名命名的文件
打开itcast.py文件

开启User-agent
在settings.py文件中,找到
USER_AGENT:'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'完善爬虫模块
修改start_urls字段为要爬取的网址
在parse函数中写解析数据相关的代码
启动爬虫
scrapy crawl itcast这时候会输出大量日志,影响查看爬虫的print结果

在settings.py文件中,添加以下内容,过滤掉日志
//log分为4个等级,从低到高:debug,info,warning,error //这句话含义是,只会显示大于等于warning等级的日志 LOG_LEVEL="WARNING"response.xpath返回结果是列表格式,解析到的数据放在data中
[
<Selector xpath='//div[@class="main_bot"]/h2/span/text()' data='课程研究员'>,<下一个selector>]取出每个selector的data数据,类型是列表型[ ]
result=response.xpath('XXXX').extract()所以我们通常,只需要[ ]其中的数据即可
result=response.xpath('XXXX').extract()[0] //当找不到数据时,会自动返回none result=response.xpath('XXXX').extract_first()
完善爬虫模块
这里要爬取网页的格式
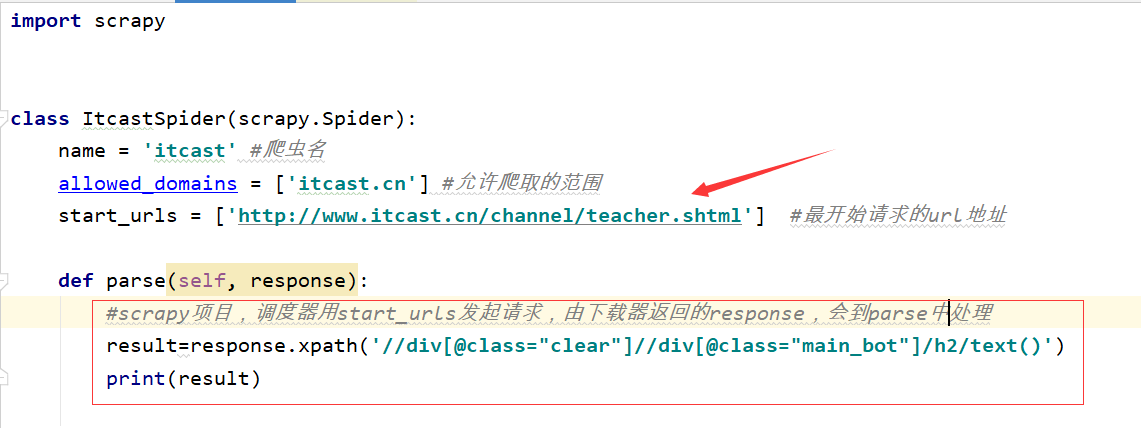
html<ul> <li>我们要的信息</li> <li>我们要的信息</li> <li>我们要的信息</li> <li>我们要的信息</li> <li>我们要的信息</li> </ul>打开
itcast.py,在parse函数中写爬虫模块代码pythonimport scrapy #引入日志模块 import logging #用文件名,创建logger logger=logging.getLogger(__name__) class ItcastSpider(scrapy.Spider): name = 'itcast' #爬虫名 allowed_domains = ['itcast.cn'] #允许爬取的范围 start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] #最开始请求的url地址 def parse(self, response): # scrapy项目,调度器用start_urls发起请求,由下载器返回的response,会到parse中处理 list = response.xpath('//div[@class="maincon"]/ul[@class="clears"]/li') for li in list: # 这里循环的是li元素 item = {} item["name"] = li.xpath('.//div[@class="main_bot"]/h2/text()').extract_first() # 注意xpath路径有".",代表当前li路径 item["profile"] = li.xpath('.//div[@class="main_mask"]/p/text()').extract_first() #打印日志 logger.warning(item) # 将数据返回Pipeline,通常将每次循环的结果字典返回。而不是将整个循环结束后,把所有数据放到列表返回。 # item只能是Request,BaseItem,dit,None类型 # 这样更节约内存,速度更快 yield item使用BaseItem类
在上一条最后,我们看到
yeild item中item类型可以是BaseItem我们在上一个例子中,自己定义了一个字典item,来存放数据
其实我们可以在
items.py中定义存放数据的BaseItem包含的键名注意:可以创建多个BaseItem类,起不一样的名字就行。注意使用时,实例化自己需要的那个类
python###items.py文件 import scrapy class MyspiderItem(scrapy.Item): # 定义MyspiderItem这个类的键名 # name = scrapy.Field() name=scrapy.Field() profile=scrapy.Field()在爬虫模块中使用,把原本普通的item字典,换成实例化的MyspiderItem
python#在items.py文件中引入MyspiderItem类 from mySpider.items import MyspiderItem #实例化MyspiderItem类 item=MyspiderItem() #存值 item["name"]=XXX item["profle"]=XXX yield itemyield item将数据传递到
pipeline.py,注意两点:传递过去的item,需要转化为dict,才能像原来一样使用
pythondict(item)还有就是,可能有多个BaseItem,要判断是哪个
python#判断item是MyspiderItem实例化的,才进入if执行 if isinstance(item,MyspiderItem): XXXX
设置日志
通常我们实际项目中,我们通常都会使用日志,print输出仅仅会打印到控制台,不能保存记录。我们可以用logger打印每一步的数据
在
setting.py通过LOG_FILE字段设置日志保存的位置,设置后控制台,就不会打印数据了
在需要打印日志的位置添加
python#引入日志模块 import logging #用文件名,创建logger logger=logging.getLogger(__name__) #打印日志,item是打印的数据 logger.warning(item)
开启管道模块
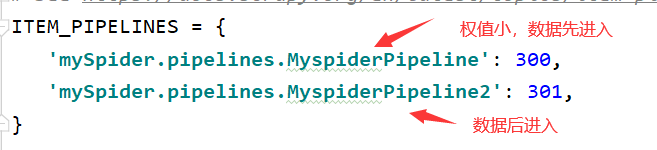
先开settings.py文件,把以下内容注释取消,就能开启Pipeline
ITEM_PIPELINES = {
#键名是项目个目录下的mySpider/pipelines.py中的MyspiderPipeline类
#值是权值,数字越小,从爬虫模块返回的数据越先进入该管道
'mySpider.pipelines.MyspiderPipeline': 300,
}在settings.py文件中,开启了两个管道类,数据进入管道中的顺序,有权重有关【数字越小,从爬虫模块返回的数据越先进入该管道】
完善管道模块
这是pipelines.py文件
- 参数
item:由爬虫yield item传过来的数据,在item参数中。 - 参数
spider:可以通过spider.name判断是哪个爬虫,然后在处理该爬虫的数据
在这个文件中可以写多个管道类,但是必须
- 在
settings.py文件的ITEM_PIPELINES配置中按格式添加上这个类的键值对 - 下一个管道类如果需要接收到上一个管道类的数据,上一个管道类必须要
return item
###pipelines.py文件
class MyspiderPipeline:
def process_item(self, item, spider):
# item是爬虫yield item,传递过来的数据
# spider.name获取到传递数据爬虫的名字
if(spider.name=="itcast"):
#对数据处理
#将数据传递到下个管道类的item之中
return item
class MyspiderPipeline2:
def process_item(self, item, spider):
# 参数item是在上一个管道类处理后,传递过来的
return item给管道模块,添加日志(与爬虫模块一样)
在
pipeline.py中,我们大多数时候要写入数据库。这个时候我们要在处理数据的那个管道类里面添加,open_spider和close_spider两个方法
import pymysql
class TencentPipeline:
con = pymysql.Connect(
host="127.0.0.1",
port=3306,
db="school",
user="root",
passwd="heyingjie1996",
charset="utf8"
)
cur=""
def open_spider(self, spider):
pass
def close_spider(self, spider):
# 提交事务
self.con.commit()
# 关闭事务
self.cur.close()
# 关闭连接
self.con.close()
def process_item(self, item, spider):
# 创建游标对象
self.cur = self.con.cursor()
#添加SQL语句
insert_sub = 'insert into schoollist values(NULL,"{}","{}","{}","{}")'.format(item["school_img"],item["school_name"],item["school_type"],join(item["school_tip"])+item["school_address"])
print(insert_sub)
# 执行SQL语句,返回受影响的行数
result = self.cur.execute(insert_sub)
return item使用settings.py文件来保存参数
settings.py除了可以设置默认的字段外,我们也可以将一些配置数据存在里面。比如数据库的连接,需要存一些连接数据库的信息,比如数据库地址,账号,密码
//在settings.py文件中
//键名大写
HOST="127.0.0.1"#在爬虫.py文件中使用HOST字段
from 文件名.settings import HOST#在pipelines.py文件中使用HOST字段
#方法一:
from 文件名.settings import HOST
#方法二:
def parse(self,response):
#可以通过self参数,获取settings.py中的字段
self.settings["HOST"]
#可以通过self参数,设置settings.py中的字段
self.settings.get("HOST","新的HOST值")scrapy实现翻页
原理还是url翻页,创建Request对象,写回电函数处理数据
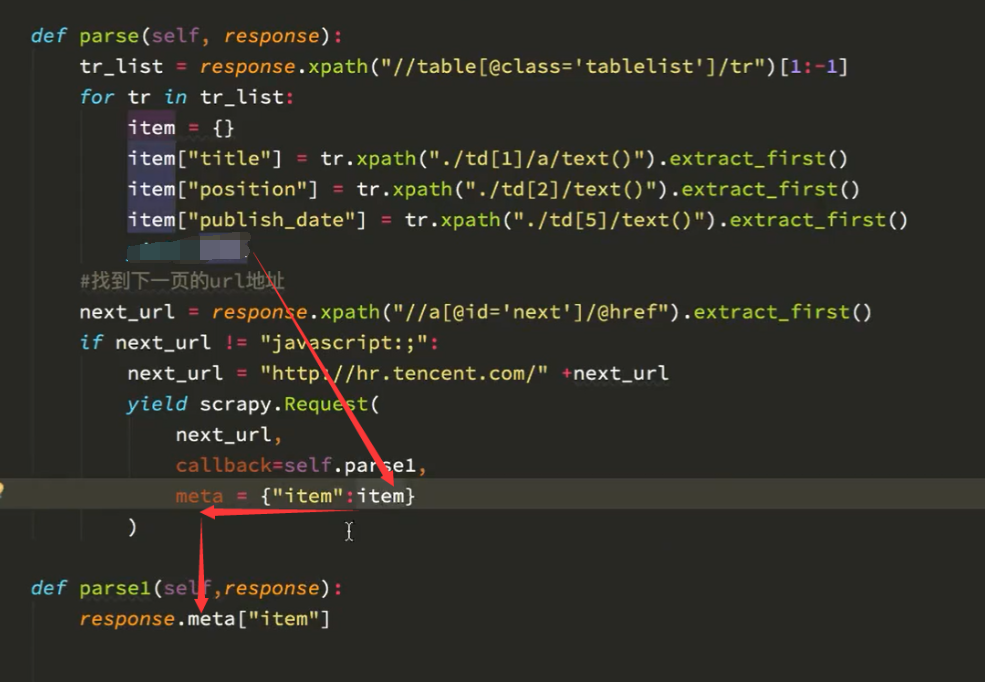
找到下一页的url,翻页到新页面,页面解析方式与原来一样,callback=parse
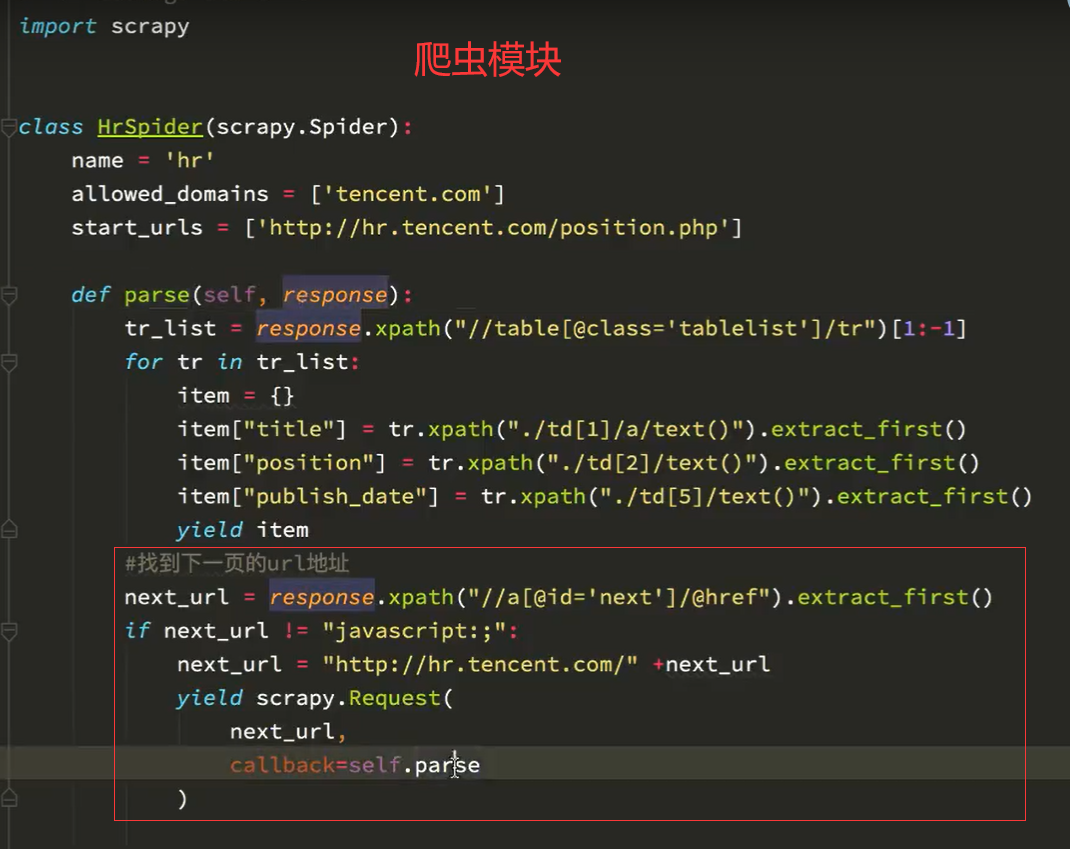
找到详情页url,详情页解析方式与原来不同,令callback=parse1。然后写parse1函数处理详情页

yield scrapy.Request()参数详解

meta参数:在不同parse函数之间传递数据
翻页综合例子

scrapy startproject yangguang
cd yangguang
scrapy genspider yg sun0769.com在settings.py文件中配置
LOG_LEVEL="WARNING"
USER_AGENT:'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
ITEM_PIPELINES = {
'yangguang.pipelines.YangguangPipeline': 300,
}yg.py文件
import scrapy
from yangguang.items import YangguangItem
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest']
def parse(self, response):
ul=response.xpath('//ul[@class="title-state-ul"]/li')
for li in ul:
item=YangguangItem()
item["condition"]=li.xpath('normalize-space(./span[@class="state2"]/text())').extract_first()
item["question"] = li.xpath('./span[@class="state3"]/a/text()').extract_first()
item["wait_time"] = li.xpath('normalize-space(./span[@class="state4"]/text())').extract_first()
item["proposal_time"] = li.xpath('./span[5]/text()').extract_first()
href= li.xpath('./span[@class="state3"]/a/@href').extract_first()
#进入详情页
yield scrapy.Request(
'http://wz.sun0769.com'+href,
callback=self.parse_detail,
meta={'item':item}
)
#向下翻页
next_url='http://wz.sun0769.com'+response.xpath('//a[@class="arrow-page prov_rota"]/@href').extract_first()
if next_url is not None:
yield scrapy.Request(
next_url,
callback=self.parse
)
def parse_detail(self, response):
#把item传递进来,把详情页内容加进去
item=response.meta["item"]
item["detail"]=response.xpath('//div[@class="details-box"]/pre/text()').extract_first()
print(dict(item))
#加上详情页数据后,在yield数据到pipelinepipelines.py文件
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class YangguangPipeline:
def process_item(self, item, spider):
con = pymysql.Connect(
host="127.0.0.1",
port=3306,
db="yangguang",
user="root",
passwd="heyingjie1996",
charset="utf8"
)
# 创建游标对象
cur = con.cursor()
# 添加SQL语句
item=dict(item)
insert_sub = 'insert into yg values(NULL,"{}","{}","{}","{}","{}")'.format(item["condition"],item["question"],item["wait_time"],item["proposal_time"],item["detail"])
print(insert_sub)
# 执行SQL语句,返回受影响的行数
#result = cur.execute(insert_sub)
# 提交事务
con.commit()
# 关闭事务
cur.close()
# 关闭连接
con.close()
return item爬取苏宁图书信息
建立MySql数据库
CREATE TABLE `book` (
`id` int NOT NULL AUTO_INCREMENT,
`first_cate` varchar(255) NOT NULL,
`second_cate` varchar(255) NOT NULL,
`se_cate_href` varchar(255) NOT NULL,
`book_img` varchar(255) NOT NULL,
`book_href` varchar(255) NOT NULL,
`book_name` varchar(255) NOT NULL,
`book_author` varchar(255) NOT NULL,
`book_press` varchar(255) DEFAULT NULL,
`book_isbn` varchar(255) DEFAULT NULL,
`book_price` decimal(10,2) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3367 DEFAULT CHARSET=utf8;创建项目和爬虫
scrapy startproject book
cd book
scrapy genspider suning suning.com打开settings.py中的设置
LOG_LEVEL="WARNING"
USER_AGENT:'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
ITEM_PIPELINES = {
'book.pipelines.BookPipeline': 300,
}items.py代码
import scrapy
class BookItem(scrapy.Item):
#图书一级分类
first_cate=scrapy.Field()
#图书二级分类
second_cate=scrapy.Field()
#图书分类对应的图书列表页url
se_cate_href=scrapy.Field()
#图书封面
book_img=scrapy.Field()
#图书详情页url
book_href=scrapy.Field()
#图书名
book_name=scrapy.Field()
#图书作者
book_author=scrapy.Field()
#图书出版社
book_press=scrapy.Field()
#图书ISBN编号
book_isbn=scrapy.Field()
#图书价格
book_price=scrapy.Field()爬虫页面代码
import scrapy
##使用deepcopy()必须引入
from copy import deepcopy
##使用正则
import re
from book.items import BookItem
class SuningSpider(scrapy.Spider):
name = 'suning'
allowed_domains = ['suning.com']
start_urls = ['https://book.suning.com/?safpn=10006.502325']
def parse(self, response):
try:
#一级分类
first_list=response.xpath('//div[@class="left-menu-container"]/div[@class="menu-list"]/div[@class="menu-sub"]/div[@class="submenu-left"]')
for first_li in first_list:
item=BookItem()
seconde_list=first_li.xpath('.//p')
for index,second_li in enumerate(seconde_list) :
item["first_cate"]=second_li.xpath('./a/text()').extract_first()
third_list=first_li.xpath('.//ul[{}]/li'.format(index+1))
for third_li in third_list:
item["second_cate"]=third_li.xpath('.//a/text()').extract_first()
item["se_cate_href"] = third_li.xpath('.//a/@href').extract_first()
#进入图书列表
yield scrapy.Request(
item["se_cate_href"],
callback=self.parse_book_list,
#这个函数是异步的,有可能这里正在发送请求时,item进入下一次循环,被更改了
##deepcopy需要引入,作用是复制一份新的item。
meta={"item":deepcopy(item)}
)
except Exception as e:
pass
def parse_book_list(self,response):
item=response.meta["item"]
bool_list=response.xpath('//ul[@class="clearfix"]/li')
for bool_li in bool_list:
item["book_img"]=bool_li.xpath('.//div[@class="wrap"]/div[@class="res-img"]//a/img/@src2').extract_first()
item["book_href"] ='http:' +bool_li.xpath('.//div[@class="wrap"]/div[@class="res-img"]//a/@href').extract_first()
item["book_name"] = bool_li.xpath('normalize-space(.//div[@class="wrap"]/div[@class="res-info"]/p[@class="sell-point"]/a/text())').extract_first()
#详情页
yield scrapy.Request(
item["book_href"],
callback=self.parse_detail,
meta={"item":deepcopy(item)}
)
#下一页
yield scrapy.Request(
'https://list.suning.com/'+response.xpath('//a[@id="nextPage"]').extract_first(),
callback=self.parse_book_list,
)
def parse_detail(self,response):
try:
item=response.meta["item"]
item["book_author"]=response.xpath('//ul[@class="bookcon-param clearfix"]/li[1]/span/text()').extract_first()
item["book_press"] = response.xpath('//ul[@class="bookcon-param clearfix"]/li[2]/text()').extract_first().split(':')[1]
#图书价格所在的html元素,不在返回的页面,是在返回的js代码中,有js生成的 ;
item["book_isbn"] = re.findall("\"isbnCode\":\"(.*?)\"", response.body.decode("utf-8"))[0]
item["book_price"]=float(re.findall("\"itemPrice\":\"(.*?)\"",response.body.decode("utf-8"))[0])
#print(dict(item))
yield item
except Exception as e:
passpipelines.py页面
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class BookPipeline:
con = pymysql.Connect(
host="127.0.0.1",
port=3306,
db="books",
user="root",
passwd="heyingjie1996",
charset="utf8"
)
cur = ""
count=0
def open_spider(self, spider):
pass
def close_spider(self, spider):
pass
# 提交事务
self.con.commit()
# 关闭事务
self.cur.close()
# 关闭连接
self.con.close()
def process_item(self, item, spider):
self.count+1
item=dict(item)
#print(item)
# 创建游标对象
self.cur = self.con.cursor()
# 添加SQL语句
insert_sub = 'insert into book values(NULL,"{}","{}","{}","{}","{}","{}","{}","{}","{}",{})'.format(item["first_cate"],item["second_cate"],item["se_cate_href"],item["book_img"],item["book_href"],item["book_name"],item["book_author"],item["book_press"],item["book_isbn"],item["book_price"])
print(insert_sub)
# 执行SQL语句,返回受影响的行数
result = self.cur.execute(insert_sub)
return item启动爬虫
scrapy crawl suningCrawlSpider类
帮助我们提取详情页和下一页URL地址
不使用
scrapy genspider 爬虫名 爬取的范围使用以下命令创建爬虫
scrapy genspider -t crawl 爬虫名 爬取范围生成的项目,仅爬虫文件有变化
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CfSpider(CrawlSpider):
name = 'cf'
allowed_domains = ['circ.gov.cn']
start_urls = ['http://circ.gov.cn/']
#定义获取url的规则
rules = (
#LinkExtractor:链接提取器,用来提取url
#callback:可选参数,将提取出来的url的response交给callback指定的函数处理
#follow:当前提取出来的url的response是否继续经过rules提取,true表示会继续提取,不写该参数则默认false
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item如何进行手机APP的数据爬取?
平时我们的爬虫多是针对网页的,但是随着手机端APP应用数量的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来说是一项必备的技能。我们知道,网页爬取的时候我经常使用F12开发者工具或者fiddler之类的工具来帮助我们分析浏览器行为。那对于手机的APP该如何使用呢?同样的,我们也可以使用fiddler来分析。好了,本篇博主将会给大家介绍如何在电脑端使用fiddler进行手机APP的抓包。
首先了解一下fiddler(百度百科):
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以让你胡乱修改的意思)。 Fiddler 要比其他的网络调试器要更加简单,因为它不仅仅暴露http通讯还提供了一个用户友好的格式。
完成此项工作的整个流程可分为如下几个步骤。
1. 下载fiddler抓包工具
fiddler的官方下载链接:https://www.telerik.com/download/fiddler 安装步骤没什么特别,常规下一步完成即可。
2. 设置fiddler
这里有两点需要说明一下。
设置允许抓取
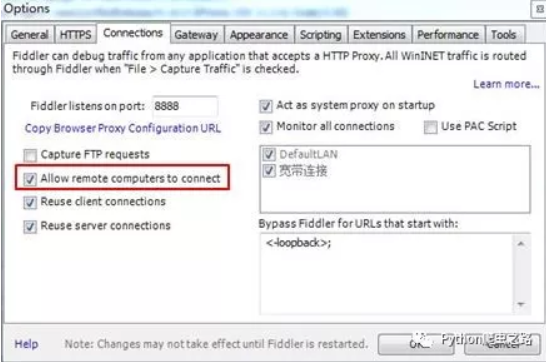
HTTPS信息包操作很简单,打开下载好的
fiddler,找到Tools -> Options,然后在HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。这样,fiddler就会抓取到HTTPS的信息包,否则会一直显示tunnel。

- 设置允许外部设备发送
HTTP/HTTPS到fiddler相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住上面的端口号8888,端口号后面会使用到。
好了,需要的fiddler设置就配置完成了。
3. 设置手机端
设置手机端之前,我们需要记住一点:电脑和手机需要在同一个网络下进行操作。可以使用wifi或者手机热点等来完成。
假如你已经让电脑和手机处于同一个网络下了,这时候我们需要知道此网络的ip地址,可以在命令行输入ipconfig简单的获得,如图。

好了,下面我们开始手机端的设置。
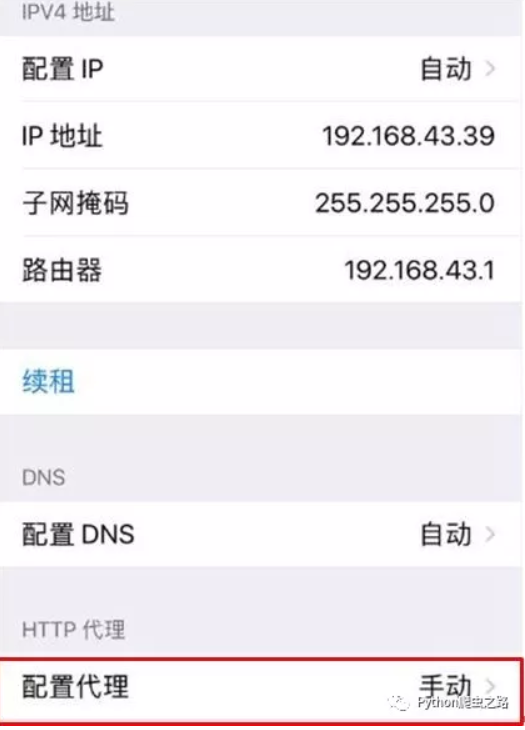
手机APP的抓取操作对于Android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
首先进入到手机wifi的设置界面,选择当前连接网络的更多信息,在苹果中是一个叹号。点击进入后你会在最下面看到HTTP代理的选项,选择点击进入,选择 手动。
进入后,填写上面记住的ip地址和端口号,确定保存。

4. 下载fiddler安全证书
手机端设置完成后,我们还需要下载fiddler安全证书,可以在在手机上打开浏览器输入一个上面ip地址和端口号组成的url:http://192.168.43.38:8888。打开后你会看到如下的界面,然后点击FiddlerRoot certificate下载fiddler证书。

以上就简单完成了所有的操作,最后我们测试一下是否好用。
5. 手机端测试
就以知乎APP为例,在手机上打开 知乎APP。下面是电脑上fiddler的抓包结果。
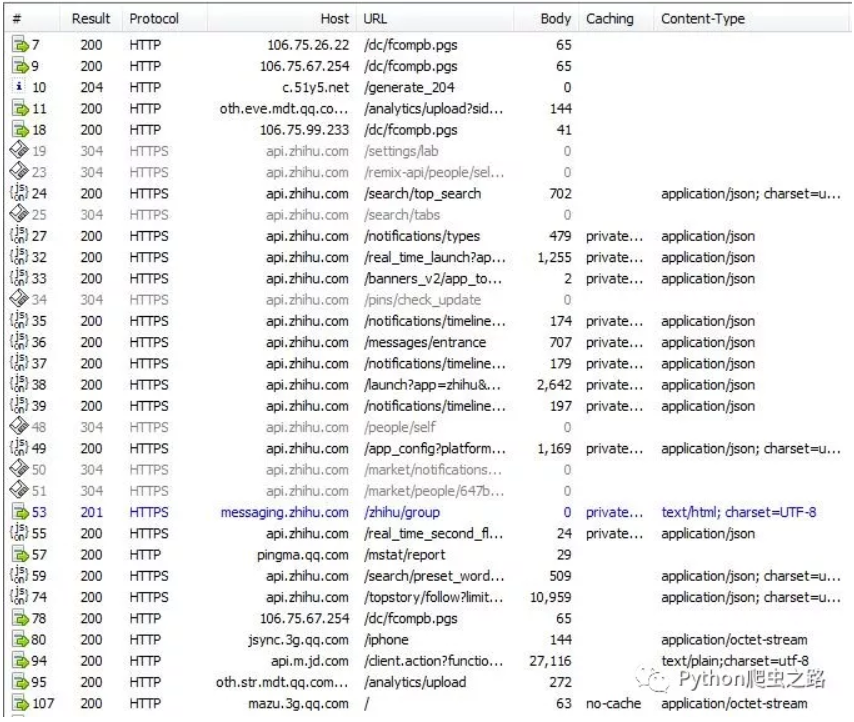
结果没有问题,抓到信息包。然后就可以使用我们分析网页的方法来进行后续的操作了。
爬虫模拟登录—OAUTH的详解
原创 Python爬虫之路 [Python数据科学](javascript:void(0)😉 2018-02-15
前两篇分享了HTTP的基本概念和高级用法,以及京东模拟登录的实战内容。本篇博主将会继续与大家分享HTTP中的另一个有趣内容:OAUTH,它也是在爬虫的模拟登录中可能会用到的,下面给大家详细介绍一下。
OAUTH的定义
引自百度百科的定义:
OAUTH协议为用户资源的授权提供了一个安全的、开放而又简易的标准。与以往的授权方式不同之处是OAUTH的授权不会使第三方触及到用户的帐号信息(如用户名与密码),即第三方无需使用用户的用户名与密码就可以申请获得该用户资源的授权,因此OAUTH是安全的。oAuth是Open Authorization的简写。
目前,最新的OAUTH协议使用2.0版本,具体内容被记录在RFC6749标准中,可参考链接:*https://tools.ietf.org/html/rfc6749*。
OAUTH的应用
一个简单而不陌生的例子。
我们平时访问某个网站或论坛,如果进行一些个人操作(比如留言),网页一般会弹出让我们先登录的提示。如果这时候我没有账号又不想注册的话,该怎么办呢?我们通常会点击一个第三方的小图标(比如微信)而完成登录。有些网站甚至没有用户注册的功能,完全依靠第三方网站登录获取用户信息。
比如我们使用微博账号来登录segmentfault网站。
网页会首先被重定向到微博的登录界面进行登录,我们输入我们的账号和密码后,segementfault网站会根据从微博账号获取的信息(比如你的微博头像、昵称、好友列表等)来创建一个用户。当然,segmentfault是不会知道你的微博密码的,因为我们必须保证用户登录信息的安全性而不能将密码明文出去。这一系列的安全性的授权操作都源于使用了OAUTH协议。
其实在这一过程中,OAUTH协议解决了传统第三方登录方法的一些弊端,比如:
- 避免了传统方法中直接使用
用户名称和密码进行第三方登录的行为,而是通过token的形式使登录过程更安全可靠。 - 避免了传统方法中修改密码会丧失所有第三方程序授权的尴尬。
- 避免了因任意一个第三方程序被破解而泄露用户信息的缺点。
也正是基于这些,OAUTH就应运而生了。那么,上述的第三方授权登录过程到底是怎么实现的呢?这一过程怎么进行的呢?我们带着这些问题继续往下看。
OAUTH实现的思路
通过上面应用的介绍,我们不难发现这其中可大概分为三个对象,分别是:
- 客户端(上面的segmentfault)
- 第三方(上面的weibo)
- 用户(我们自己)。
清楚这个之后,我们看看OAUTH授权的大概思路。
- 使用
OAUTH协议,客户端不会与第三方登录网站直接联系,而是先通过一个授权的中间层来建立联系(有的网站将授权服务器和资源服务器分开使用,有的一起使用)。在这个授权层下,用户密码等安全信息不会泄露给客户端,而是通过反馈一个临时的令牌token来代替用户信息完成授权。token相当于一把钥匙,并且区别于用户密码,token令牌是经过加密算法生成的,一般的很难破解。 - 另外,用户可以指定
token令牌的权限范围和有效期,以适度的开放资源。 - 得到授权后,客户端就会带着
token,并根据用户规定的权限范围和有效期来规矩的获取资源信息。
这只是一个大体的思路,说白了就是通过一个授权层隔离了客户端与用户信息,并在授权层基础上使用了一把安全的钥匙来代替用户完成授权。
OAUTH的运行流程
基于这个思路,RFC6749标准规定了四种不同的授权流程供选择,分别是:
- 授权码模式(authorization code)
- 简化模式(implicit)
- 密码模式(resource owner password credentials)
- 客户端模式(client credentials)
上面提到的微博web网站使用OAUTH2.0授权码模式完成授权。其它客户端进行第三方登录之前,需要先在微博开放平台上注册一个应用,在应用里填写信息。注册完后,开放平台会给客户端(比如上面提到的segmentfault)颁发一个client_id和一个APP Secret,供授权请求使用。
下面将详细介绍微博的授权流程,即授权码模式,其它模式可以参考官方文档:*https://tools.ietf.org/html/rfc6749*。
OAUTH的详细实现过程
下面是OAUTH2.0协议的详细流程图:
博主以上面segmentfault通过微博第三方登录为例来详细说明OAUTH授权流程。
1、第一步
首先用户点击微博图标进行第三方登录,然后页面跳转到微博登录界面等待用户输入账号密码授权。
登录界面url如下:
https://api.weibo.com/oauth2/authorize?
client_id=1742025894&
redirect_uri=https%3A%2F%2Fsegmentfault.com%2Fuser%2Foauth%2Fweibo&
scope=follow_app_official_microblog客服端通过application/x-www-form-urlencoded格式并使用 UTF8编码 将下列参数加入到 query string 中来建立URI请求。
- client_id:即segmentfault在微博开放平台申请的应用ID号。
- redirect_uri:用户授权后需要跳转到的url地址。
- scope:用户授权的权限范围和有效期。
2、 第二步
页面跳转到上一步骤的redirect_uri地址并在末尾添加一个授权码code值,在后面步骤中会用code值来换取token。
跳转地址如下:
https://segmentfault.com/user/oauth/weibo?
code=e7ec7daeb7bbf8cb9d622152cd449ae0- code:授权码,且只能被客户端使用一次,否则会被授权服务器拒绝。该码与上面的应用ID和重定向URI,是一种映射关系。
这也验证了reponse_type是code类型的正确性。
3、 第三步
segmentfault客户端使用授权的code来获得钥匙token。
获取token可以通过对微博OAuth2的access_token接口进行POST请求完成,请求链接如下:
https://api.weibo.com/oauth2/access_token当然,请求还需要携带以下参数才行。
- client_id:申请应用时分配的AppKey
- client_sceret:申请应用时分配的AppSecret
- grant_type:请求的类型,填写authorization_code
- code:调用authorize获得的code值
- redirect_uri:回调地址,需需与注册应用里的回调地址一致
4、 第四步
返回上步请求获得的token信息。一个实例结果如下:
{
"access_token": "ACCESS_TOKEN",
"expires_in": 1234,
"remind_in":"798114",
"uid":"12341234"
}参数说明:
- access_token:用户授权的唯一票据,用于调用微博的开放接口,同时也是第三方应用验证微博用户登录的唯一票据,第三方应用应该用该票据和自己应用内的用户建立唯一影射关系,来识别登录状态,不能使用本返回值里的UID字段来做登录识别。
- expires_in:access_token的生命周期,单位是秒数。
- remind_in:access_token的生命周期。
- uid:授权用户的UID,本字段只是为了方便开发者,减少一次user/show接口调用而返回的,第三方应用不能用此字段作为用户登录状态的识别,只有access_token才是用户授权的唯一票据。
5、 第五步
使用上一步获得的token获取用户的名称头像等信息。可以通过请求如下链接:
https://api.weibo.com/2/users/show.json同时请求需要携带以上获取的token和 uid参数。
** 6、第六步**
返回获取的用户名称头像等已授权信息。
以上就是整个微博OAUTH授权流程的详细介绍。