Rust
参考
陈天 - Rust 编程第一课 (参考:https://github.com/tyr-rust-bootcamp)
Rust 官方资源
Rust 中文网 https://rustwiki.org/
Rust 异步:https://rust-lang.github.io/async-book/
b站视频讲解:【Rust Async 异步编程(完结)-哔哩哔哩】 https://b23.tv/jcmaN5d
Github 上的 《rust 语言圣经》(和官网的不一样,明显这个版本要好很多):https://course.rs/basic/intro.html
Rusty Book(收集大量的 rust 包、代码片段、明星项目):https://rusty.course.rs/
Rust 秘典(死灵书): https://nomicon.purewhite.io/intro.html
陈天的 Rust 项目模板 ,其中配置了一系列的工具,以及使用Github Action来定义提交代码的流程
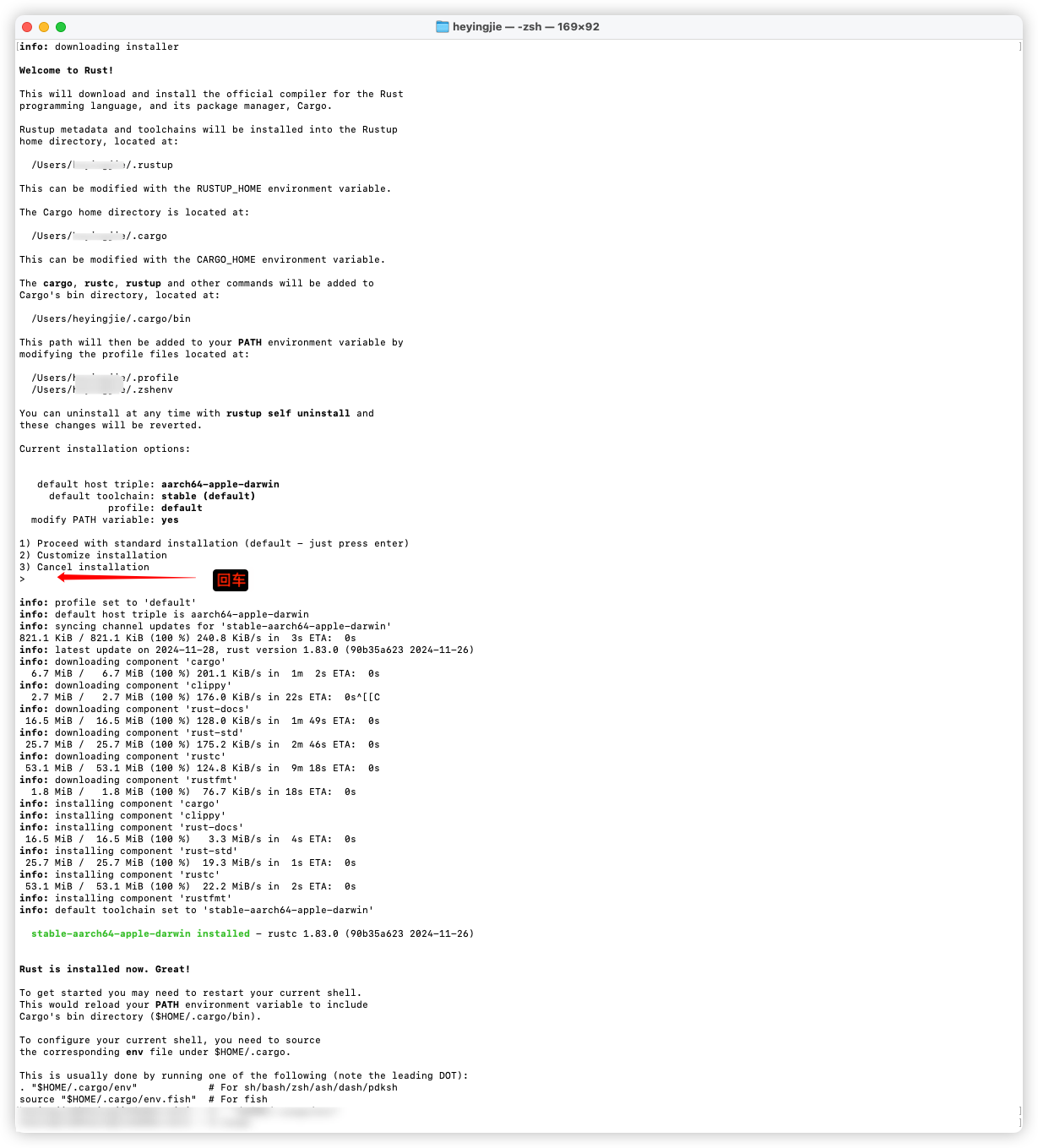
安装
- rustup 是 rust 工具链管理器,其中包含 rustc (rust 编译器)
- cargo 是 rust 包管理工具
安装时会自动安装两个工具
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | zsh安装输出的内容很详细,可以仔细看下
输出 print!
println!是换行打印
// 【占位符输出】
let name = "tom";
// ⚠️ {} 是占位符
print!("Name: {}", name); // Name: tom
println!("{name} "); // tom
---------------------------------------------
// 【根据变量位置输出】
println!("{1} 、 {0}", "Alice", "Bob"); // Bob 、 Alice下面直接常用的占位符,更多请参考:https://rustwiki.org/zh-CN/std/fmt/index.html
基本占位符
{} 默认格式化输出,适用于实现了 Display trait 的类型
调试输出
{:?} 用于调试输出,适用于实现了 Debug trait 的类型。这对于查看复杂类型(如结构体、枚举等)的内容非常有用
#[derive(Debug)] // 特殊的宏,所以后面{:?}才能输出结构体内部数据
struct User {
username:String,
active: bool
}
let mut user = User{
username:String::from("jack"),
active:true
};
print!("{:?}",user) // User { username: "jack", active: true }数字输出
{:b}:二进制格式{:o}:八进制格式{:x}、{:X}:十六进制格式(小写或大写)rustlet num = 15u32; println!("{:x?} ", num); // f println!("{:X?} ", num); // F{:e}、{:E}:科学计数法表示(小写或大写)
指针输出
{:p}:指针地址的格式化输出
模块化
项目/工程/软件包(Packages):根目录下有1个Cargo.toml 文件
1个项目(Packages)中可以包含多个包(Crate),每个 Crate 包含多个模块(mod)
Crate
Crate类型
Rust 中 Crate 可分为2种
- 库(--lib) :编译为
.rlib静态库,一般包含公用的函数,可供其他rust项目引入 - 二进制(--bin):编译为可执行文件。起必须包括 main 函数作为入口
一个 rust 项目
- 最少要包含1 个Crate (库、二进制 Crate 都行)
- 最多可包含 1 个库Crate + 多个二进制Crate,可通过 Cargo.toml 配置
意思就是: 一般是有 1 个工具函数 Crate,多个有 main 入口的二进制包调用这个工具函数 Crate 实现不同功能
Crate作用域
Crate 根文件所在的目录就是这个Crate 的作用域
默认约定
如果 Cargo.toml 中没有配置,则遵循 Cargo 的默认约定:
- 如果包目录中包含 src/main.rs ,则它是 二进制 crate 的根
- 如果包目录中包含 src/lib.rs,则它是库 crate 的根。包名为项目name字段(下面的例子
rust_example)
例如:cargo new xxx (默认省略了 --bin 参数,是创建的二进制Crate) 创建的默认项目
// 目录结构
├── Cargo.toml
└── src
└── main.rs // 二进制 Crate 的根
└── lib.rs // 库 Crate 的根
// Cargo.toml
[package]
name = "rust_example"
version = "0.1.0"
edition = "2021"
[dependencies]【后面会提到】 Crate 根所在的目录就是这个Crate 的作用域。以默认约定为例子,你会发现 lib.rs、main.rs 这两个 crate 的作用域有重合
配置 Crate
Cargo.toml 是 Rust 项目的配置文件,可以配置项目中的 Crate 信息:
- name 是 Crate 名
- path 是 Crate 的根
[package]
name = "my_project"
version = "0.1.0"
# 1个库 crate
[[lib]]
name = "my_lib"
path = "src/lib.rs"
# 多个二进制 Crate
[[bin]]
name = "main_program"
path = "src/bin/main.rs"
[[bin]]
name = "cli_tool"
path = "src/bin/cli.rs"标准目录结构
├── Cargo.toml
├── Cargo.lock
├── src
│ ├── main.rs
│ ├── lib.rs // 库 Crate
│ └── bin // 二进制 Crate
│ └── main1.rs
│ └── main2.rs
├── tests // 测试目录
│ └── some_integration_tests.rs
├── benches // 基准性能测试
│ └── simple_bench.rs
└── examples // 示例
└── simple_example.rsModule
一个 Crate 内可包含多个模块(Module)
模块成员可见性
模块(module)访问子级模块成员(函数、结构体、结构体字段、方法、关联方法、枚举等)默认私有,需要 pub 关键字公开
子模块访问父级模块则默认公开,无需 pub 修饰
注意:枚举设置为 pub,其所有变体都为公开
pub enum Appetizer {
Soup,
Salad,
}而结构体设置为 pub ,还需要设置字段公开
pub struct MyStruct {
// 字段默认还是私有的
field: i32,
}
pub struct MyStruct {
pub field1: i32, // 公开字段
field2: i32, // 私有字段
}模块声明
注意:
- 模块是可以无限嵌套的,存在父级、子级、孙子级....(观察3个例子的注释)。以包根(默认 src/lib.rs)为根节点呈树状关系
- 如果使用 1 个Crate 的功能,需要从包根一层一层引入 mod 中的成员(路径上都是 pub 才能访问到)
1、内联模块
mod math {// 模块 math
fn add() {
math1::add1(); // ❌ 【引入】父级引入子级模块,子模块必须 pub
}
mod math1 { // 子模块 math2
fn add1() {
super::add(); // ✅【引入】引入父模块(super代表父级),默认公开无需 pub
}
}
mod math2 { // 子模块 math2
fn add2() {
super::math1::add1(); // ❌【引入】引入兄弟模块,兄弟模块必须 pub
}
}
}2、目录 math + mod.rs 、单 rs 文件
math目录是个模块
a.rs、b.rs 单文件也是模块
src/
├── main.rs
├── lib.rs
├── math/ // 模块 math
├── mod.rs // 模块入口 ,其中引入子模块
├── a.rs // 子模块 a
└── b.rs // 子模块 b3、根 Crate
src/
├── main.rs
├── lib.rs
├── math.rs // 属于根的子模块 math默认情况下,src/main.rs 、 src/lib.rs 分别是 二进制Crate root、库 Crate root
根作用域下的文件是 Crate root 的子模块
- 把 math.rs 视为**二进制 Crate **成员,则属于于 main.rs 的子模块
- 把 math.rs 视为**库 Crate **成员,则又属于 lib.rs 的子模块
但是 Rust 要求一个模块只能属于一个 Crate,一般看作 math 是 lib 的子模块。而 main.rs 则是跨 Crate 引入了
// ----- 【math.rs】 ------
pub fn zfn(){}
// ----- 【lib.rs】 ------
pub mod math; //【引入】子模块 math
fn x() {
math::zfn();
}
// ----- 【main.rs】 ------
fn main(){
rust_example::math::zfn() // 跨 Crate 引入,后面会提到
}如果没有 lib.rs ,那就没办法了。只能把 math 当做 main 的子模块了
// ----- 【main.rs】 ------
pub mod math;同 Crate 内模块引入
同一个 Crate 内部的 module,module x 如何引用 module y 的函数、变量等成员呢?
前面例子, 注释【引入】
访问子模块
mod 子模块;
子模块::孙子模块::孙子模块内 pub 成员相对路径访问其他模块
super::b::bFn() // super 代表父级 mod绝对路径访问其他模块
crate::math::b::bFn() // crate是根模块跨 Crate 模块引用
多 Crate 的结构,即 1 个库Crate + 多个二进制Crate
二进制 Crate 引用库 Crate 的能力
注意: 库 Crate 是不能引入二进制 Crate ,如果真的需要,必须要将这个能力抽离到库 Crate 后,再由二进制 Crate 引入
Crate 引入
同一个 Crate 内只需要 pub 修饰,模块就能通过引入访问其他模块的成员
提到的例子 【module - 模块声明 - 根 Crate】
math 必须在 库Crate根中引入并公开才算是暴露导 Crate 外部,才能在 二进制 Crate中引入
src/
├── main.rs
├── lib.rs
├── math.rs // 属于根的子模块 math需要通过 Crate 名引入
fn main(){
rust_example::math::zfn();
// 我这个例子中 rust_example 是项目名,而项目名就是默认的 Crate 名
}但是每次调用 zfn 都需要写一长串,所有出现了 use 关键字(类似 JS 的 import)
use rust_example::z::zfn;
fn main(){
zfn()
}其他引入格式
// 引入
use crate名::lib::add1;
fn main() {
add1(1, 2);
}
// 引入起别名
use crate名::lib::add1 as xxx;
fn main() {
xxx(1, 2);
}
// 在 {} 按需引入
use crate名::lib::{add1,add2};
fn main() {
add1(1, 2);
add2(1, 2);
}
// 在 {} 按需引入 , self 引入lib
use crate名::lib::{self,add1};
fn main() {
add1(1, 2);
lib.add1(1, 2);
}三方 Crate 引入
三方的 Crate 需要配置项目的 Cargo.toml
# 指定项目安装的依赖
[dependencies]
xxx = "1.0" # 指定 xxx 版本 1.0.0 ,启用默认特性
yyy ={ version = "1.0", features = ["serde", "extra"] } # 启用特性
www ={ version = "1.0", default-features = false } # 禁用默认特性
zzz = { version = "1.0", optional = true } # 依赖是可选的,其他项目引入本包时,需 json 特性才会安装这个依赖 (观察下面 json = ["zzz"] 配置)
# 指定项目特性,[] 内可能是依赖crate名、特性名
[features]
default = ["std"] # 默认启用的 features , 例如 xxx 依赖只指定版本启用的features
std = [] # 一个 feature,不依赖其他 crate
json = ["serde"] # 启用 `json` feature 时,启动 serde 特性
serde = ["dep:serde"] # 依赖与 feature 重名,需要 dep 标记在 Rust 中,features(特性/功能) 是一种条件编译机制,允许你在 crate 中启用或禁用某些功能。它们常用于:
- 可选依赖:某些功能依赖特定的库,但不想强制所有用户都安装。
- 实验性功能:允许用户选择是否启用不稳定的功能。
- 性能优化:禁用不需要的功能以减少编译时间或二进制大小。
条件编译
在 Rust 代码中,安装三方依赖可以指定 feature,在安装时才会根据指定条件编译
对于 Crate 作者来说,可以使用用户根据启用的 feature 指定条件编译:
// #[cfg(xxx)] 指定编译条件,下面是启动feature = serde 时才编译
#[cfg(feature = "serde")]
use serde::{Serialize, Deserialize};
// feature = serde 时变成 #[derive(Serialize, Deserialize))]
#[cfg_attr(feature = "serde", derive(Serialize, Deserialize))] // 条件 derive
struct MyData {
value: i32,
}运行时指定
#[cfg(feature = "tokio")]
async fn run_tokio() {
tokio::spawn(async { println!("Running on Tokio!"); });
}
#[cfg(feature = "async-std")]
async fn run_async_std() {
async_std::task::spawn(async { println!("Running on async-std!"); });
}总结
| 场景 | 做法 |
|---|---|
| 定义 features | 在 Cargo.toml 的 [features] 块中声明 |
| 可选依赖 | dependencies 里加 optional = true |
| 条件编译 | #[cfg(feature = "xxx")] |
| 用户启用 | features = ["xxx"] |
| 禁用默认 | default-features = false |
如果你的 crate 需要灵活的功能开关,合理使用 features 可以让用户按需选择,避免不必要的编译开销! 🚀
标准库 std
Rust 官方提供标准库 std,其中包含了大量常用的能力
std 本质就是一个 lib crate ,我们常用的 Option、Result (后面枚举章节会提到)在 core 库中,std 只是将 core 库的模块重新导出
prelude
prelude(预导入模块),是编译器自动导入的标准库子集
// 相当于
use std::prelude::v1;其中包含了,常用类型、traits、宏。都可以直接使用,不必使用use 引入
// 类型
- Option 、Some、None // 枚举
- Result 、OK、Err // 枚举
- String // 字符串
- Vec // 动态数组
- Box
// traits
- `Copy`, `Clone`
- `Debug`, `PartialEq`, `Eq`, `PartialOrd`, `Ord`
- `Drop`
- `Default`
- `From`, `Into`
- `AsRef`, `AsMut`
- `Iterator`, `Extend`, `IntoIterator`
- `Fn`, `FnMut`, `FnOnce`宏自动导入
println!, format!, vec!, dbg!(这些通过宏定义引入)
包管理
cargo --list # 查看所有命令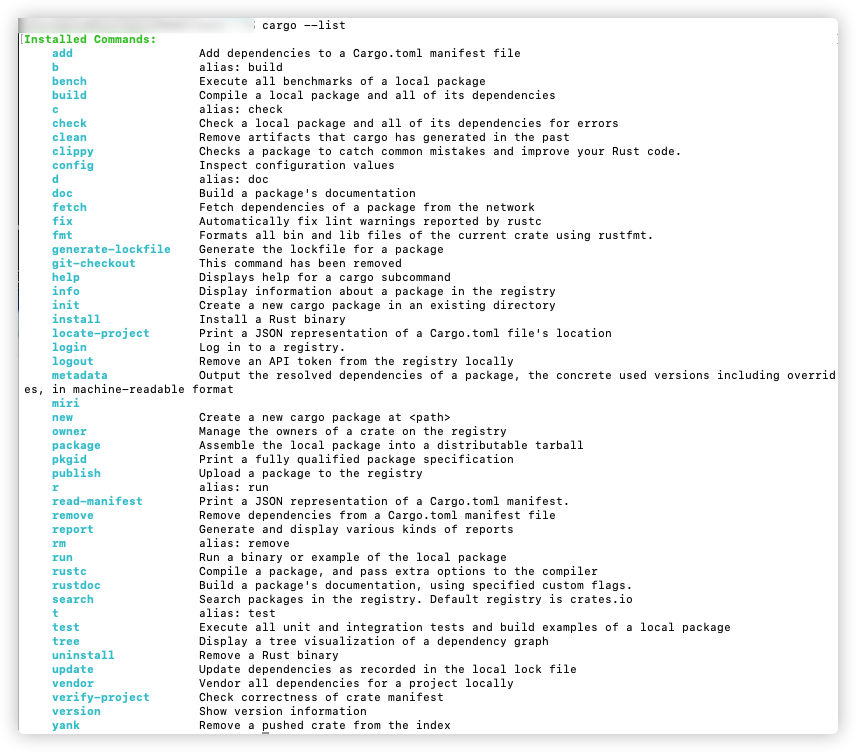
初始化项目
cargo new 项目名 # 默认创建二进制项目(即选项 --bin),选项--lib 是创建一个库项目
# 目录
├── Cargo.lock # 锁文件
├── Cargo.toml # 依赖记录文件
└── src
└── main.rs # 入口依赖管理
# 安装cargo-generate包(用来生成项目模板的工具,使用 github repo 生成项目)
# cargo 会自动下载源码编译为二进制文件到 ~/.cargo/bin 目录下
cargo install cargo-generate
# 调用了上一步骤下载的 cargo-generate
cargo generate tyr-rust-bootcamp/template # 以 https://github.com/tyr-rust-bootcamp/template 这个项目作为目模板
# 安装Cargo.toml记录的全部依赖
cargo fetch
# 更新依赖项到最新的兼容版本
cargo update构建二进制文件
cargo build # 根目录/debug下。这种编译方式的产物中包含debug相关的标准库,所以体积比较大
cargo build --release # 根目录/release下运行
cargo run注释
Rust 中注释规则比较复杂
代码注释
这部分和其他语言一致
// 行注释
/*
块注释
*/文档注释
crates.io 上发布的包,会读取特定的注释来显示为 Crate 的文档
包、模块注释
成员注释
- 库 Crate 都是通过包根暴露出来成员,所以文档注释只能加在包根文件(默认 src/lib.rs)。且只能给暴露出的成员(pub 修饰)加文档注释
- 支持 markdow 语法
/// 行注释
/**
传入值加2
*/
pub fn add(x: i32) -> i32 {
x + 2
}变量
注意:
Rust圣经将下面的语法称为:变量绑定 ,即将内存中的数据对象绑定到变量x上
rustlet x =10;声明作用域
rustconst MAX_NUM:u32=10; // const 用来声明常量,可以定义在任何作用域 fn main() { let x =10; // let 不能在全局作用域 { let x = x * 2; println!("{}",x); //20 } // 出了作用域,x=20的变量失效了。 println!("{}",x); //10 }
变量声明与绑定
使用 let 定义变量,变量默认不可变
fn main(){
// 指定类型
let x:u32=10;
let y=10u32;
// 自动推导类型
let z=10;
}fn main(){
// ❌ 编译失败,变量默认不可变
let z=10;
z=20;
// ✅ 默认变量不可变,但是可以覆盖 。 覆盖本质上是重新创建了同名变量
let w=10;
let w= ""; // 变量是全新的,甚至类型都变了
}使用 let mut 定义可变变量
fn main(){
let mut y=10;
}Rust中未使用变量,在编译时会报警告。可以使用 _ 前缀
fn main(){
let _x =10;
}常量
常量:
不可变,可以写在任何作用域
只有下面一种声明方式,不支持自动推断类型
rustconst MAX_NUM: u32 = 100000;
与不可变变量最重要的区别:变量不能放在全局作用域,在作用域外会失效,而常量声明在全局作用域就会一直有效
将值解构到变量
解构元组,除了元组外还有更复杂的用法。参考后面的【解构】章节
fn main() {
let (a, mut b): (bool,bool) = (true, false);
// a = true,不可变; b = false,可变
println!("a = {:?}, b = {:?}", a, b);
}所有权与引用
所有权
变量拥有值(内存中的数据)的所有权,遵循的规则:
- Rust 中,每一个值都有一个所有者
- 任何一个时刻,一个值只有一个所有者
- 当所有者所在作用域(scope)结束的时候,其管理的值会被一起释放掉
值是Rust管理的,我们的变量只是持有这些值。当变量作用域结束后,Rust自动释放变量只有的值
值复制(copy)
固定类型存储在栈上,赋值操作都是对值进行复制。变量各自持有一个值,与其他语言一致
- 所有的数值类型:整数(u32、u64)、浮点数 (比如 f32、f64)
- 布尔类型 bool
- 字符类型 char
- 由以上类型组成的数组、元组、Vec、HashMap 类型。(这些类型都是由其他类型组合起来的,这里扣掉了结构体,因为结构体字段无论啥类型都会发生所有权转移)
- **不可变引用类型 & ** (不可变引用很重要,这个后面会重点讲)
fn main() {
let a = 10u32;
let b = a; // 值复制
println!("{a}");
}
// a、b 离开作用域,rust 会自动调用内置函数 drop ,释放内存资源本质原因是上述类型都实现了 Copy trait
所有权转移 (move)
除去以上值复制的情况以外,都会发生所有权转移
fn main(){
// 可变类型存储在堆上,其赋值给 s2 后s1就失效 ,s1 处于无效状态
let s1=String::from("xxx"); // 创建字符串 xxx
let s2=s1;
print!("{}",s2);
}
// 函数执行完毕后,a、b 离开了作用域
// a 是无效状态,不持有数据,无需处理
// b 持有数据的所有权,rust 会自动调用内置函数 drop 来释放资源常见的所有权转移场景:
函数调用传参(实参 -> 形参)
rustfn foo(s:String){ print!("{s}"); } fn main(){ let s1=String::from("xxx"); foo(s1); // 函数实参赋值给形参,会发生所有权转移 // 值被函数形参持有,函数foo结束后值被销毁了 print!("{}",s1); // ❌ 这里就会报错,s1的值被转移了,处于无效状态 } // 函数执行完毕后,值就被回收了如何解决?采用下面方案或引用
函数调用返参(返参 -> 接收返回值变量)
rust// 正确写法 fn foo(s:String) -> String{ print!("{s}"); s // 把 s 对值的所有权转移到外部了 } fn main(){ let s1=String::from("xxx"); let s1=foo(s1); // ✅ 函数将返回值转移回 s1 , (函数结束其作用域,其中变量 s 已经转移了所有权,rust 不做 drop 释放处理 ) print!("{s}"); }for 循环中,每一次循环是独立的,变量转移到第 1次循环中了
rustfn main() { let s = "I am a superman.".to_string(); for _ in 1..10 { let tmp_s = s; ❌ println!("s is {}", tmp_s); } } // 正确写法 let tmp_s = &s; // ✅ 仅仅发生复制转移出去,转移进来
rustfn main() { // 转移进来 ,以 Vec 动态数组为例子 let x = "hello world".to_string(); let v = vec![x]; println!("{}",x) // ❌ 编译错误。 x 的所有权转移进了 v // 转移出去 let y = v[0]; // ❌ 编译错误。 v 的元素转移到 y , 这里报错是因为 Rust 中不允许 数组、数组切片、元组、Vec 部分转移 }
部分所有权转移
结构体可以部分字段转移
#[derive(Debug)]
struct Stu{
name: String,
age: u8,
}
fn main() {
let s =Stu{name:"John".to_string(),age:20};
let y = s.name; // name 是 String 类型,会发生所有权转移
println!("{:?}",s.age); // 但是剩余的字段还是可用的
}数组、元组、Vec(动态数组) 子元素不允许,发生所有权转移。一旦转移整个数组、元组都不可用
fn main() {
let arr1 = ["hello world".to_string(), "hello world".to_string()];
let s1 = arr1[0]; // ❌ 发生所有权转移,数组失效
let arr2 = [1,2,3];
let s = arr2[0]; // ✅ 元素支持 Copy Trait,会发生复制,不会失效
println!("{:?}",arr2); // [1, 2, 3]
}fn main() {
let t1 = ("hello world".to_string(), "hello world".to_string()); // 元组
let s1 = t1.0; // 转移
println!("{}", t1); // ❌ 元组失效
let t2 = (1,2); // 元组
let s2 = t2.0; // 转移
println!("{:?}", t2); // ✅ 元组失效
}HashMap 比较特殊,不支持部分 key 所有权转移。但是可以通过 remove 方法直接删除返回 Option 来达到转移的目的,同时 HashMap 仍然有效
两种引用
1、引用、借用的概念
&s1表示对变量s1的不可变引用,s2只是借用所有权,同时s1仍然持有值的所有权
s1离开作用域,rust 自动调用内置函数 drop 释放内存资源
s2离开作用域,因为其没有值的所有权,rust 不会做处理。请注意:如果 s1 先失效了,s2是借用的所有权,也会失效
fn main() {
let s1 = 5;
let s2 = &s1; // 不可变引用
// 这里能同时打印两个值; *s2 是解引用,获取实际值
println!("{}, {}", s1, *s2); // 5 5
}2、引用本质
与其他语言相似,&x 、 &mut x 的值就是变量 x 的内存地址,可变引用 &mut x 可以操作 x 持有的数据
// 请注意 x 两种情况 可变变量、不可变变量; y 两种情况 可变引用、不可变引用。共 4 种情况
// ✅ 语法正确
let x = 10;
let y = &x;
// ❌ 语法错误,从不可变变量获取可变引用
let x = 10;
let y = &mut x;
// ⚠️ 语法虽然正确,但是 y 无法操作 x 持有的数据
let mut x = 10;
let y = &x;
// ✅ 语法正确。 x可变 + x的可变引用 ,才能操作
let mut x = 10;
let y = &mut x;
*y += 1; // x=11注意复杂结构内部的成员
struct Stu{
name:String,
}
fn main() {
// 结构体
let x = &Stu{name:"x".to_string()}; // 不可变引用
let z = &x.name; // x.name 是 String 类型,必须再取引用
// 数组
let a = &[1,3,4]; // 数组引用
let b = &a[0]; // 元素本身不是引用,必须再取引用
}4、使用引用的基础例子
将原始数据传入函数,返回处理后的值,是很常见的逻辑
传入可变引用,函数内部直接修改数据
rustfn handle_data(s: &mut String ){ // 传入变量可以修改 s.push_str(" world"); }// 函数执行完毕,s 只是借用,没有值的所有权。rust 不会调用 drop 释放资源 fn main(){ let mut s =String::from("hello"); handle_data(&mut s); // 注意:虽然s是可变的,取引用 &mut 才行 ; 不可变变量不能取 &mut println!("{}",s) // hello world }rustfn handle_data(s: &mut String ) ->&str{ &s[..1] // 取切片,截取第一个字节,即"h" } // 函数外部的 s 持有所有权,这里函数结束并不会释放内存资源 fn main(){ let mut s =String::from("hello"); let res = handle_data(&mut s); println!("{}",res) // h }传入可变引用,复制部分内容存下来
rust#[derive(Debug)] struct School{ name:String, students:Vec<Student> } #[derive(Debug,Clone)] struct Student{ name:String, age:i8, } impl School { // 传入&Student,必须克隆一份才能留在 School 中,会有性能损失 fn add1(&mut self,student:&Student){ self.students.push(student.clone) } // Student会发生 move,不会有性能损失 fn add2(&mut self,student:Student){ self.students.push(student) } } fn main() { let mut school = School{ name:String::from("希望中学"), students:vec![], }; let s = Student{ name:String::from("小明"), age:20 }; // 🚩 情况 1: 如果后续还需要 s,只是临时处理下。这以后就必须用拷贝引用的值了,有性能损失 school.add1(&s); // 🚩 情况 2: s 的所有权转移了,以后不能再使用了,性能也更好 school.add2(s); print!("{:?}",school); }xxx
ruststd::mem::take 或 std::mem::replace传入不可变引用,函数返回修改后的数据
rust// 悬垂引用 fn main() { let reference_to_nothing = dangle(); } // ❌ 编译不通过 fn dangle() -> &String { let s = String::from("hello"); &s // 将引用绑定给变量 reference_to_nothing,函数结束 s 离开作用域,进而导致引用失效 } // ✅ 编译通过 fn dangle() -> String { let s = String::from("hello"); s // 将 s 对值的所有权转移给变量reference_to_nothing。 s离开作用域前是失效状态,所以s不会触发 drop 释放数据 }
作用域
变量的作用域/生命周期与其他语言一致,块级作用域、函数作用域
引用的作用域从声明的地方开始持续到最后一次使用为止
rustfn main() { let mut s = String::from("hello"); let r1 = &s; print!("{}", r1); // 👈 先用完 r1 s.push_str(", world"); // 👈 再修改,此时 r1 已“失效”(作用域内但未使用,借用已释放) }
借用检查
总结 :
- 任意时刻只能存在:一个可变借用(
&mut T),或多个不可变借用(&T) - 借用不能悬空(不存在悬垂引用)
引用作用域检查
这些限制的好处是 Rust 可以在编译时就避免数据竞争,同一作用域只能有 1 个可写引用可以修改值
判断技巧:
先观察代码块中出现可变引用(
&mut T、还有更隐蔽的 push_str 方法是使用了s 的可变引用)这时候有 2 种可能:
- 看可变引用的作用域内部否有其他引用,有就是错误的
- 看可变引用是否处于其他不可变引用的作用中
规则:
不可变引用的作用域内,不能有对该变量的可变
rust// 情况 1: fn main() { let mut s = String::from("hello"); let r1 = &s; // -----+ let r2 = &mut s; // | r1 不可变引用作用域内,出现了可变引用。❌ 编译错误 print!("{}",r1); // -----+ } // 情况 2: fn main() { let mut s = String::from("hello"); let r1 = &s; s.push_str(", world"); // push_str方法使用的是 s 的可变引用,这种更隐晦 ❌ 编译错误 print!("{}",r1); }可变引用的作用域内,不能有对这个变量的其他引用
rustfn main(){ let mut s=String::from("xxx"); let r1=&mut s; // -----+ let r2=&mut s; // | r1 可变引用作用域内,出现不可变、可变引用。❌ 编译错误 println!("{}", r1); // -----+ }
括号创造作用域
如果仅仅通过引用出现的最后一行作为其作用域结尾,当逻辑很复杂时根本看不出来每个引用的作用域。可以使用括号明确的划分作用域
fn main() {
let mut s = String::from("hello");
{
let r2 = &mut s;
println!("{}", r2);
}
let r1 = &s; // 可写作用域之间,出现了可读引用 r1
}悬垂引用检查
如果变量 r 引用了变量 x( let r = &x ),Rust 要求x 的生命周期 > r 的生命周期
如果 r 的生命周期小,则很可能在 x 存在期间,r 就失效了导致出现悬垂引用
{
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+而有些情况,Rust 编译器无法做出判断,就需要开发者手动标记生命周期
解引用
涉及很多章节,建议遇到了随时查阅
自动解引用
自动解引用(Automatic Deref coercion),自动解多层引用直到匹配的目标。例如:
x.handle() // x 会一直解开到有 handle 方法的类型print!、println!
let x = &1;
println!("{}", x); // 1模式匹配
arr是切片引用,match 、if let 语法中会自动解引用,所以分支是数组也可以
let arr = &[1, 2, 3];
match arr {
// [1, 2, 3] => println!("完全匹配"),
[_, 2, _] => println!("第 2 个元素是 2 的"),
_ => println!("其他"),
}函数参数传递
若类型 U 实现了 Deref<Target=T> (这里是关联类型语法,T 是解出来的类型),则 &U 可以自动转换为 &T
Rust中实现了 Deref Trait 的类型:
&String → &str&Vec<T> → &[T]&Box<T> → &T
fn greet(name: &str) {
println!("Hello, {name}");
}
fn main() {
let s = String::from("Rust");
greet(&s); // ✅ &String 自动变成 &str
greet(s.as_str()); // ✅ 显式转换
}方法调用
⚠️ 方法是自动解引用, 关联方法需要手动
当调用方法时,编译器会尝试对接收者进行多层解引用,直到找到匹配的方法实现
struct MyStruct;
impl MyStruct {
fn method(&self) { println!("MyStruct method"); }
}
let s = MyStruct;
let ref_s = &s;
let ref_ref_s = &&s;
ref_s.method(); // 自动解引用:&MyStruct → MyStruct
ref_ref_s.method(); // 自动解引用:&&MyStruct → &MyStruct → MyStruct操作符重载
如 +、* ,与前面实现 Deref Trait 不同
操作符重载是通过 std::ops::Add Trait 解引用,只会解引用 1 次
let a = 5;
let b = &a;
let c = &&a;
assert_eq!(a + *b, 10); // ✅ 显式解引用
assert_eq!(a + b, 10); // ✅ 自动解引用:&i32 → i32
assert_eq!(a + c, 10); // ❌ 只能解引用 1 次:&&i32 → &i32自动解引用的优先级规则
编译器按以下顺序尝试解引用,直到找到匹配的方法或类型: 直接匹配:类型完全一致。
解引用一次: &T → T
解引用多层: &&T → &T → T
解引用 + 强转(Coercion) :例如 &String → &str (通过 Deref )
优先使用 &mut T 而非 T 如果同时存在不可变和可变引用,优先选择更少层数的解引用
ruststruct Data; impl Data { fn method(&self) {} fn method_mut(&mut self) {} } let mut data = Data; let mut_ref = &mut data; mut_ref.method(); // 自动选择 &mut Data → &Data → 调用 method() mut_ref.method_mut(); // 自动选择 &mut Data → 调用 method()
手动解引用
通过 * 会触发1次解引用,*T -> *(T.deref())。注意与自动解引用的区别是:只会解1 次
直接访问内部数据:
let boxed = Box::new(42);
let value = *boxed; // 必须显式解引用修改可变引用指向的值
let mut x = 5;
let y = &mut x;
*y += 1; // 必须显式解引用模式匹配(match)
let option = Some(42);
if let Some(value) = &option {
println!("{}", value); // 自动解引用:&Option<i32> → Option<&i32>
}生命周期
悬垂引用检查
如果变量 r 引用了变量 x( let r = &x ),Rust 编译器要求 x 的生命周期 > r 的生命周期(这个属于借用检查)
如果 r 的生命周期小,则很可能在 x 存在期间,r 就失效了导致出现悬垂引用
{
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+标记生命周期
上面的例子,Rust 编译器在编译期间,能确定下面条件,所以可以进行借用检查
[1] r、x 的生命周期
[2] r 是对 x 的引用什么时候不能确定,需要手动标记生命周期?
在 Rust 中是是无法确定函数返参是否为对入参的引用,即编译器无法判断 [2]
所以,函数入参、返回值都是引用,且入参与返参相关的函数需要手动标记生命周期
(⚠️ 只需标记返参、与返参相关的入参 )
如下面例子
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
// ❌ 编译报错。 编译器无法的确定 返参是 x 还是 y 的引用
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}生命周期标记只是开发者告知编译器生命周期信息,帮助编译器进行借用检查,并不会对代码实际逻辑有影响
&i32 // 引用
&'a i32 // 不可变引用标记生命周期
&'a mut i32 // 可变引用标记生命周期开发者标记生命周期只是告诉编译器 x、y、返回值是一样的生命周期 a
// fn longest<'a> 是声明生命周期 a
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}开发者需要保证入参 x、y 生命周期都要 >= 返回值生命周期
下面编译报错就是违背了,所以借用检查没有通过
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}
fn main() {
let result; // ---------------+-- 'result
let x = String::from("abcd"); // -------+--'x |
{ // | |
let y = String::from("xyz"); // ---'y | |
result = longest(&x, &y); // | | |
} // ---------------+
println!("Result: {}", result); // ❌ 报错!result 悬垂
}其实通过这个例子,应该能意识到,虽然生命周期是标记在函数中的。实际上都是约束外部变量的关系
另一个例子,这是一个搜索函数。返回值是所有 content 的部分内容,所以只限制了 content、返回值的生命周期一致。
fn search<'a>(target:&str, content:&'a str)->Vec<&'a str>{
let mut ret =Vec::new();
for line in content.lines() {
if line.contains(target){
ret.push(line)
}
}
ret
}所以,如何指定生命周期,还是需要看实际含义。这里就不能直接指定两个入参都是 a
类型
基本类型
数值类型
整数类型
- 有符号整数:
i8,i16,i32,i64,i128,isize - 无符号整数:
u8,u16,u32,u64,u128,usize
其中,isize 和 usize 的大小取决于运行程序的计算机架构(32位或64位)。
// ** 整数字面量,默认会被推导为 i32 类型 **
// ** 下面是十进制数字 17,对应的其他进制的字面量 **
fn main() {
// 二进制
let a= 0b10001;
// 八进制
let b=0o21;
// 十进制
let c =17;
// 十六进制
let d=0x11;
// 字节
let e = b'a'; // ASCII值 17对应的是个控制字符,打不出来。这里用个 a 字母,其实际是数字 97
println!("a = {}, b = {}, c = {}, d = {} , e={}", a, b, c,d,e); // 默认输出十进制值
// a = 17, b = 17, c = 17, d = 17 , e=97
}十进制转其他进制的短除法:

浮点数类型
f32: 32位单精度浮点数f64: 64位双精度浮点数,默认使用这个类型(在现代的 CPU 中它的速度与f32几乎相同,但精度更高)
其他知识
数字字面量分隔符
下划线
_可以放在数字之间的任意位置(但不能在开头或连续使用),编译器会忽略掉。虽然位置任意,但是推荐按一定习惯分割rustlet x = 1_000_000; // 十进制 let b = 0x1_0_0; // 十六进制 0x100 (256) let c = 0b1010_1010; // 二进制 0b10101010 (170)生成连续序列
rustfor i in 1..=5 { println!("{}",i); // 从 1-5 } for i in 1..5 { println!("{}",i); // 从 1-4 }rustfor i in 'a'..='z' { println!("{}",i); // 从 a 到 z }Rust 种支持的运算符:https://course.rs/appendix/operators.html#运算符
同类型之间支持数字运算
浮点数运算存在误差。(三方crate库num)
NAN 与 JS 基本一致
rustfn main() { // 1、非法运算,产生 NAN let x = (-42.0_f32).sqrt(); // 2、is_nan 返回布尔值判断是否为 NAN if x.is_nan() { println!("未定义的数学行为") } // 3、NAN 与任何数运算都是 NAN,且两个 NAN 不能比较,否则直接 panic }
布尔类型
bool: 只能取值为 true 或 false
字符类型
char: 表示一个Unicode标量值,是四个字节长度的字符
fn main(){
let c:char='你';
}单元类型
() :其唯一的值也是 (),即空的元组
没有显示返回值的函数,默认返回()
复合类型
字符串
字符(char)
前面基本类型提到的字符类型,底层存储Unicode 值,固定四个字节长度的字符
字面量(&'static str)、字符串(String)、字符串切片(&str)
字符串底层存储 UTF-8 编码,字符是 1~4 个字节,而字符串索引是以字节为单位的
所以 Rust 中字符串无法通过角标索引
但是 字符串切片可以通过索引取出字符串的某个范围,例如 [0,1],只不过这种操作很危险,一旦么有取到字符边界(即 某个字符是 4 个字节,但是取了[0,1]就会直接 panic 崩溃)
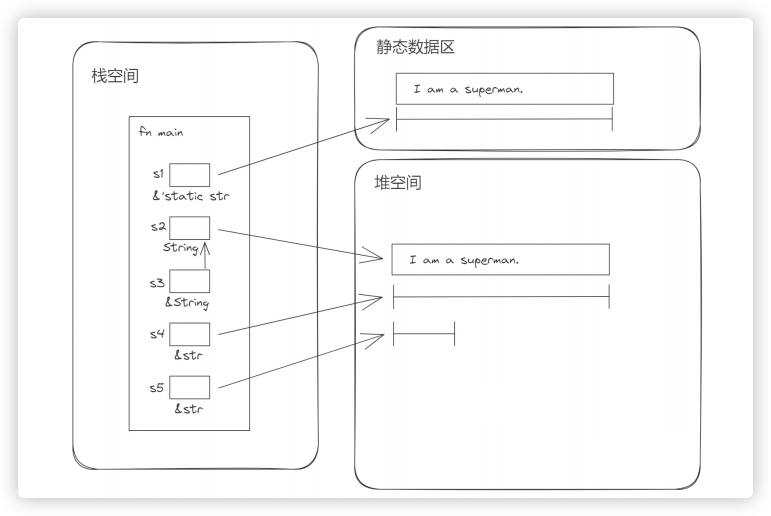
fn main(){
// 字符串字面量存储在静态数据区,类型是 &'static str
// ⚠️ &'static str 是&str的一种,所以&'static str标记为 &str 也没问题,反之不可以
let s1: &'static str = "I am a superman.";
// 字符串(String)与字面量的区别是: String拥有所有权、容量可增长、分配在堆上的
// "xxx".to_string()、String::from(xxx) 两种方式将 字面量、&String、&str(切片引用)转为 String,这个过程会将字面量拷贝到堆上
let s2: String = s1.to_string()
// String 的引用类型
let s3: &String = &s2;
// &str 切片类型本质是个`不可变引用`,是字面量类型
// String 转 &str 还可以 s2.as_str()
// &'static str、String、&String 都支持取切片
let s4: &str = &s2[..]; // 字符串的切片引用类型
let s5: &str = &s2[..6];// 字符串的切片引用类型,范围 [0,6),即左闭右开区间
let s55: &str = &s2[2..3]; // 两端范围
}
⚠️ 切片指定的索引范围,是以字节为单位的。如果字符中出现中文或者其他多字节文字,就会导致运行时崩溃,所以取字符串切片是个危险操作,除非硬编码为字母、数字字符串,否则非常不建议使用
// ❌ 编译通过,运行时会崩溃 panic
let s = "世界";
let a = &s[0..2]; // "世"是 3 个字节,所以报错。如果是&s[0..3]就不会崩溃
// ✅ 输出字符
for c in "世界".chars() {
println!("{}", c);
}
// 世
// 界
// ✅ 输出字节
for c in "世界".bytes() {
println!("{}", c);
}
// 228
// 184
// 173
// 229
// 155
// 189
// 228
// 186
// 186&[u8] 字节切片
切片的每个元素是 u8,正好是 8 bit(位) = 1byte(字节),所以叫字节切片
在重复一遍,Rust 字符串中字符使用 UTF-8,如果按字节取可能会取不到整个字符
let x = b"hello world"; // b前缀 + 字符串 ,在Rust被推断为字节切片类型。但是请注意这是 Rust 层面的,本质底层和 &str 都是一样的字符串 String 的操作
String 是分配在堆上的,是可以操作的
fn main() {
let mut s = String::from("a");
// 追加。 参数支持 char、String,改变原字符串
s.push_str("b");
println!("{}", s); // ab
// 插入。参数仅支持 char,改变原字符串
s.insert(1,'x');
println!("{}", s); // axb
// 全部替换。参数仅支持 String,不操作原始字符串
let res = s.replace("x","o");
println!("{}", res); // aob
println!("{}", s); // axb
// 范围替换。改变原字符串
s.replace_range(1..=2,"c");
println!("{}", s); // ac
// 出栈删除。改变原字符串,返回值为出栈字符。如果原始字符串为空,职责返回 None
let pop_res = s.pop();
println!("{} {:?}", s,pop_res); // a Some('c')
// remove(1) 与 truncate(1) 。改变原字符串,返回被删除的字符串
// remove入参是字节索引,如果是汉字可能会报错(不建议使用)
// truncate入参是字符索引,1就是删除索引为 1 的字符
// 清空字符串。改变原字符串
s.clear();
println!("{}", s); // 空字符串
// 两个字符串拼接 。注意 字符串 String + 字面量/切片引用 &str
// 本质是调用了 std::string中的 add 方法
let concat = s+"x";
println!("{}", concat); // x
}&String-->&str 隐式转换
某些情况下,会发生这种隐式转换
fn main(){
let s="xxx".to_string(); // s应该是 String 类型
let s1 = &s;
let s2:&str=&s; // 如果 s2 是、指定切片引用类型,Rust 会发生隐式转换
// 使用 &str 就能让函数接收 &String、&str 两种类型
fn receive(s:&str){
// 逻辑
println!("{}", s);
}
receive(&s1);
receive(s2);
// ⚠️ 这意味着在 Rust 中 &String、&str 是可以混用的
}向量与向量切片
// 参数接收 &Vec<T>向量、&[T]向量切片
fn receive(s:&[T]){
}
// 参数接收 &Vec<u8>、&[u8]向量切片 (T 是 u8时,就是字节串)
fn receive(s:&[u8]){
}String <-->&str
fn main() {
// String 转 &str
let s1=String::from("你好").as_str();
// &str 转 String
let s2="你好".to_string();
let s3="你好".to_owned();
// to_string、to_owned 在 &str -> string用法中是一样的
let s: String = "abc".to_owned();// 除此之外to_owned还能 &slice -> Vec
}String --> Vec<char>
fn main(){
let s1="你好".to_string();
let char_vec: Vec<char>=s1.chars().collect(); // chars() 可以用来把字符串转换为一个迭代器,collect() 将迭代器所有元素收集到 Vec 中
println!("{:?}",char_vec); // ['你', '好']
// for 循环迭代器
for ch in s.chars() {
println!("{:?}", ch);
}
}&str --> 数值类型
fn main() {
let str_num = "123";
println!("{}", str_num.parse::<i8>().unwrap()); // 123
// ::<i8> 是 turbofish 指定函数传入的泛型 , 用于指定 num 的类型
// 返回值是 Result ,unwrap 可以解出来数据
}
// str_num = "111aa" 这种会转换失败
// str_num = "111.11" 这种由于指定的泛型是 i8,所以也会失败元组
固定长度,元素可以是不同类型
声明
let x1=(1,1,1) // 自定推导类型
let x2:(u32,u32,u32)=(1,1,1) // 带类型声明访问
// 通过`.`访问
x1.1 // 索引 1 的元素
// 解构
let (x,y,z) = x1;数组、数组切片
数组:固定长度,元素只能是一种类型(与 Go 一致)
数组声明
let arr = [1, 2, 3, 4, 5]; // 自定推导类型
let arr:[i32;5] = [1, 2, 3, 4, 5]; // 带类型声明
let arr = [20;5]; // 元组重复,可以用 [元组;重复次数]⚠️ 创建重复数据的数组,元素必须是支持 Copy 的类型,下面 String 有所有权,每次复制都会发生转移,所以是错误的
// ❌
let array = [String::from("hi"),10];
// ✅ 闭包用法,后面会提到
let array = std::array::from_fn(|_i| String::from("rust is good!"));数组切片声明
对数组、字符串的一部分引用(范围是左闭右开)。⚠️ Rust 中切片只能是数组的局部视图,不能超过数组范围,而Go 中的切片支持自动扩容
// 数组切片
let arr = [1, 2, 3, 4, 5];
let slice = &arr[1..3]; // 自定推导类型
let slice1:&[i32] = &arr[1..3]; // 带类型声明
// 从切片生成切片
let slice2 = &slice[1..3];复习:前提到的字符串切片 &str
let s = "abcdef";
let s1 = &s[1..3];
let slice:&str = &s[1..3]; // 带类型声明结构体
结构体
// 【声明】
// ⚠️ Go 是 type User struct{}
struct User {
username:String,
active: bool
} // ⚠️ 无需分号
---------------------------------------------
// 【实例化】
let username = String::from("tom");
let active = true;
struct User {
username:String,
active: bool
}
// 字面量实例化、支持简写方式,这些类似 JS
let user1 = User{
username, // 简写
active // 简写
};
// 也支持展开实例字段,类似 JS
let user2 = User{
username:String::from("jack"),
..user1 // ⚠️ 展开结构体实例被称为 base struct , 必须在最后,这与 JS 不同
};
//
let user2 = User{
username:String::from("jack"),
..Default::default() // 特殊语法:会取User结构体字符的默认值填充。需要#[derive(Default)]派生下 Default Trait
};
---------------------------------------------
// 【修改实例】注意声明为 mut
let username = String::from("tom");
let active = true;
#[derive(Debug)] // 特殊的宏,所以后面{:?}才能输出结构体内部数据
struct User {
username:String,
active: bool
}
let mut user = User{
username,
active
};
// ⚠️ 修改实例,变量前需加 mut
user.username=String::from("jack");
print!("{:?}",user) // User { username: "jack", active: true }元组结构体
元组结构体更加紧凑
// 普通结构体
struct Point{
x:u32,
y:u32,
z:u32
}
// ---------------------------------
// 可以看下元组结构体,确实更加紧凑
// 【声明】
struct Point(u32, u32, u32);
// 【实例化】
let origin = Point(0, 0, 0);单元结构体
没有任何字段的结构体
struct ArticleModule; // ⚠️ 没有字段可省略 {}
let module = ArticleModule; // 【实例化】 没有字段,可以省略{}这个语法有歧义,很容易让人疑惑:类型为什么能直接赋给一个变量?
实际上是单元结构体省略了
关联方法、方法
在 Rust 中 Struct 实例可以调用方法、关联方法,⚠️ 实例引用调用时会自动解引用,所以也可调用
user.get_name()
&user.get_name() // ✅ &user会解引用,所以也可调用get_name关联方法
相当类的静态方法,通过::调用
// 声明结构体
struct User{
name:String,
age:u8,
}
// 关联方法
impl User {
// 1、Rust 中认为参数不含有self ,就是关联方法
// 2、习惯上,结构体都会定义 new 方法,用来实例化
fn new(name:String,age:u8) -> User { // 参数没有 self 所以是关联方法
User {name,age} // ⚠️ 隐式返回,最后一行是表达式(不要加分号),其值最为返回值
}
}
fn main() {
// 调用使用::
let user = User::new(String::from("Alice"), 30);
}方法
相当类的实例方法,通过.调用
// 声明结构体
#[derive(Debug)]
struct User{
name:String,
age:u8,
}
// 实例方法
impl User {
// 1、命名推荐下划线
// 2、函数最后一句表达式,作为返回值。⚠️ 不加分号,加了分号就是"语句"
// 3、参数类型 Self ,表示自身实例
// 🚩 方式 1
fn get_name(self) -> String { // 参数是 self:Self 的简写。会发生所有权转移
self.name
}
// 🚩 方式 2
fn get_name(&self) -> String {// 参数是 self:&Self 的简写。可读引用,只能克隆值作为返回值
self.name.clone()
}
// 🚩 方式 3
fn get_name(&mut self) -> String {// 参数是 self:&mut Self 的简写。通过可写引用,可操作实例
self.name=""
self.name.clone()
}
}🚩 方式 1 案例
// 声明结构体
#[derive(Debug)]
struct User{
name:String,
age:u8,
}
// 实例方法
impl User {
fn get_name(self) -> String {// 所有权转
self.name
}
}
fn main(){
let user= User{
name:String::from("tom"),
age:20
};
let name = user.get_name(); // User实例的所有权会转移到形参,实例不可再用
print!("{:?}",user); // ❌ 编译不通过 user 所有权已被转移
}🚩 方式 3 案例
// 声明结构体
#[derive(Debug)]
struct User{
name:String,
age:u8,
}
// 实例方法
impl User {
fn get_name(&mut self) -> String {// 参数是 self:&mut Self 的简写
self.name="变更".to_string();
self.name.clone()
}
}
fn main() {
// user 也要标记为 mut
let mut user= User{
name:String::from("tom"),
age:20
};
print!("{}",user.get_name()); // 变更
print!("{:?}",user); // User { name: "变更", age: 20 }
}所有权
转移
let user1 = User{
username:String::from("tom"),
active:true
};
let user2=user1 // 所有权发生转移
---------------------------------------------
#[derive(Debug)]
struct User{
name:String,
age:u8,
}
impl User {
fn get_name(self) -> String {
self.name
}
}
let user= User{
name:String::from("tom"),
age:20
};
let x=user.get_name(); // 所有权转移
print!("{:?}",user); // ❌ 编译报错部分(Partial Move)
结构体是多字段组成的类型,可以发生某字段的转移
let user1 = User{
username:String::from("tom"),
active:true
};
let name = user1.username // String是所有权类型,会发生所有权发生转移
print!("{:?}",user) // ❌ 编译报错枚举
变体
Rust中的变体指的是枚举项
enum Color{
Red,
Green,
Blue
}
// 使用枚举的一个变体
// Color 是类型
// Color::Red 是值
let my_color:Color = Color::Red;变体可以指定实际数据
- 与其他语言不同,Rust中数据类型只能是 isize 类型
- 不指定时,默认 Red 为 0,后续从 0 开始。如果中间某项指定数值 X,则后续从X 开始
enum Color{
Red, // 0
Blue, // 1
Black=10,
Yellow // 11
}
fn main() {
println!("{}",Color::Blue as isize);
println!("{}",Color::Yellow as isize);
}带负载的变体
当指定为某一个变体时,如果该变体带负载(类型信息),需要实例化该变体
enum Shape {
Rectangle { width:u32,height:u32 }, // 矩形, 负载是结构体 ,使用{ }
Triangle ((u32,u32),(u32,u32),(u32,u32)),// 三角形, 负载是元组 ,使用()
Circle { origin:(u32,u32), radius:u32 }, // 圆形,负载是 结构体
}
// 带负载的枚举,需要实例化数据
fn main(){
let shape = Shape::Rectangle {width:10,height:20};
}比较
在 TS 中,类似对象、数组等复杂的类型不能直接用 == 判断是否相等的。枚举作为一个值是可以比较的
但是在 Rust 中枚举是可以携带复杂数据的,所以一定切记枚举不能直接 == 比较
可以使用后面提到 match 变量{}/匹配模式、if let 枚举=变体变量、while let 枚举变体=值变量 等方式比较
自动引入变体
函数签名中使用枚举,函数作用域内自动引入
use crate::Gender::{Man, Woman};
#[derive(Debug)]
enum Gender{
Man,
Woman
}
fn main() {
fn deal(value:u8) ->Gender {
if value==0{
return Man; // ⚠️ 作用域内,可直接使用变体
}
return Woman; // ⚠️ 作用域内,可直接使用变体
}
println!("{:?}",deal(0)) // 加上#[derive(Debug)],这里输出的就是变体名,即 Man
// 入参是枚举
fn deal2(value:Gender) ->i8 {
if let Man=value{
return 0; // ⚠️ 作用域内,可直接使用变体
}
return 1; // ⚠️ 作用域内,可直接使用变体
}
}模式匹配作用域中也会自动引入(后面会讲到)
let res: Result<i32, &str> = Ok(42);
// 模式匹配
match res {
Ok(value) => println!("Success: {}", value), // 直接使用 Ok
Err(e) => println!("Error: {}", e), // 直接使用 Err
}解构带负载的枚举
let res: Result<i32, &str> = Ok(100);
// 使用解构的方式
if let Ok(value) = res {
println!("Got a value: {}", value);
} else {
println!("Error");
}
// --------------------------------
enum Gender{
Man,
Woman
}
let user = Gender::Man;
if let Man=user{ // ❌ 不带负载的不行,这种一般认为是判断是否相等,而不是解构
println!("男")
}else{
print!("女");
}枚举的方法
当变量赋值为某一变体后,该变量可调用枚举的方法
enum MyEnum {
Add,
Subtract,
}
impl MyEnum {
fn run(&self, x: i32, y: i32) -> i32 { // &self 是 self:&Self 的简写
// match 语句
match self {
Self::Add => x + y,
Self::Subtract => x - y,
}
}
}
fn main() {
// 实例化枚举
let add = MyEnum::Add;
// 实例化后执行枚举的方法
add.run(100, 200);
}Option枚举
Option 是内置的枚举,表示区分变量的零值、正常值
补充:
在 JS 中,以 null、undefined 作为空的概念。但是这样极容易出现空指针异常
后来出现了类似 Go的方式,每个类型都有默认零值表示空的概念,如果一个数字类型的值是 0,你根本无法区分是默认值还是实际值
Rust 采用的方式: 1、所有的变量定义后使用前都必须初始化; 2、把每个类型的零值单独提出来用枚举值
Option<T>::None表示
// 源码
enum Option<T> {
Some(T), // 负载是元组
None,
}
// 空字符是 GO 中的零值,但是在 Rust 中是可以区分开的
let value0 = Option::Some(""); // 根据值隐式推断
let value1: Option<String> = Option::Some(""); // 显式声明类型
let value2 = Option::<String>::Some(""); // turbofish 语法
// Rust 中指定字符串零值
// 注意 None 无法隐式推断必须用下面两种方式声明
let value3:Option<String> = Option::None // 显式声明类型
let value4 =Option::<String>None // turbofish 语法Result枚举
Result 也是内置的枚举,用于函数返回值类型,包含函数成功、出错两种状态,它包含Ok或Err两个变体
// 源码
enum Result<T,E>{
Ok(T), // 负载是元组
Err(E) // 负载是元组
}
// 应用
let res:Result<i32, &'static str>=Ok(100);
fn divide(a: i32, b: i32) -> Result<i32, &'static str> {
if b == 0 {
Err("Division by zero!") // 自动引入枚举变体,所以可以直接使用 Err 、Ok
} else {
Ok(a / b)
}
}解包枚举值
Option::<i32>::Some(100) 与 100 显然类型不一致,但是实际第一个只是100 包了个枚举这就需要引入解包枚举值获取原始值的概念了
unwrap
// ✅ 运行成功,无输出
fn main() {
let x=Option::<String>::Some(String::from("xxx"));
assert_eq!(x.expect("提示 message"), String::from("xxx"))
}
// ❌ 编译是可以通过的,但是运行时触发 panic ,输出 "提示 message"
fn main() {
let x=Option::<String>::None;
assert_eq!(x.expect("提示 message"), "xxx")
}
函数
函数
如果没有显示返回值,则默认返回单元类型()
// 入参、返参
fn add(x:i32,y:i32)->i32{
x+y // 最后一个表达式最为返回值(注意没有分号,带分号就是语句了),也支持 return 返回
}
fn main() {
// 调用
let x=add(1,2);
println!("{}",x); //3
}函数类型
给一个变量标记函数类型
let add:fn(i32,i32)->i32; // 不需要指定形参名发散函数
发散函数即没有返回值的函数,使用! 作函数返回类型
// 1、主动 panic 的函数
fn dead_end() -> ! {
panic!("你已经到了穷途末路,崩溃吧!");
}
// 2、无限循环的函数
fn forever() -> ! {
loop {
//...
};
}
// 3、退出进程
use std::process
process::exit(1)
// 4、panic! 返回值就是`!`
panic!("崩溃了")闭包类型
简介
JS 中函数拥有闭包的能力(闭包能力:捕获函数作用域内的变量)
捕获全局作用域
js// ✅ JS let x = 1; function exec() { console.log(x) } exec() // 1捕获函数作用域
rustlet x = "全局变量"; function calc(){ // 函数 let count = 1 return function add(){ // 闭包 捕获作用域内的 count count++ console.log(count, x) } } let add = calc(); add() // 2 全局变量 add(); // 3 全局变量
Rust 中闭包也是这个含义,但是其在语法上与函数区分开了
Rust 函数无法捕获变量 x ,只能通过入参传入
// ❌ Rust 编译失败
let x =1;
fn exec(){
println!("{x}"); // help: use the `|| { ... }` closure form instead
}Rust 闭包在函数的基础上,增加了捕获能力
let add_one_v1 = |x| { x + 1 }; // |入参| { 处理逻辑 }
let add_one_v2 = |x| x + 1 ; // 如果处理逻辑只有 1 句,不会写括号
// Rust函数作为 API 所以强制类型标记,而闭包大多是作为参数,Rust会根据传入的 x 自动推断类型
// 也可以标记类型
let add_one_v3 = |x: u32| -> u32 { x + 1 };
// -------------- 对比下函数 --------------
fn add_one(x: u32) -> u32 { x + 1 }但是,闭包不能取代函数,因为闭包是在编译期静态推导类型的每个闭包都有固定的参数类型和返回类型
意思就是:函数可以多次调用,闭包建议一次性使用。下面这种情况就得使用函数
let example_closure = |x| x;
let s = example_closure(String::from("hello")); // x 推断为 String 就固定了
let n = example_closure(5); // ❌ 数值不能传递给 xfn example_closure<T>(x:T) ->T{
x
}
let s = example_closure(String::from("hello"));
let n = example_closure(5); // ✅闭包类型
注意:闭包是一种有所有权的类型啊
与函数的入参相同,闭包捕获变量也有三种方式:
FnOnce 类型
该闭包类型会所有权会发生转移,所以只能调用 1 次
rustfn main() { // 定义 FnOnce 闭包 fn fn_once<F>(func: F) where F: FnOnce(usize) -> String, // FnOnce 闭包定义 { println!("{}", func(3)); // println!("{}", func(4)); // ❌ func 只能调用 1 次 } // fn_once(|num| format!("传入数据 {}", num)) }FnMut
该闭包类型以可变引用的方式捕获环境中的值
rustlet mut s = String::from("hello"); let closure = || s.push_str("x"); // 闭包默认就是 FnMut 类型,Fn
该闭包类型以不可变借用的方式捕获环境中的值
别名
type
type 可以给类型起别名 ,仅仅只是个别名,还可以使用原类型的方法
type xx = Vec<String>; // ⚠️ 这是个语句,加分号Newtype模式
通过只有一个元素的元组结构体,对基础类型进行封装
相当于一个新的类型,原类型的方法都被屏蔽了
**例如:用户 ID 和订单 ID,其数据类型都是 u64 **
// 别名:
type UserId = u64;
type OrderId = u64;
// Newtype :
struct UserId(u64);
struct OrderId(u64);
// 在使用时,UserId、OrderId 比 u64 更具有语义化
fn process_user(user_id: UserId) {
}
// 🚩 ------------------------
// Newtype相比别名,其会屏蔽内部类型的方法、属性;同时,我们可以为 Newtype 类型实现新的方法类型转换
as 语法
数值类型之间
类型不同无法运算 , 可使用 as 做类型强制转换
fn main(){
let a = 5u32;
let b = 10u8;
let c =a+b as u32;
println!("{}",c); // 15
let d =a as u8+b;
println!("{}",d); // 15
}从高精度类型 ---> 低精度类型,会造成数据精度丢失
fn main(){
let a = 5.78f32;
println!("{}",a as i32); // 5 ⚠️ 精度丢失了
}枚举类型 --> 整数
enum Status {
Active = 1,
Inactive = 2,
}
fn main() {
println!("{}",Status::Active as i32); // 结果是 1
}try_into
返回值是 Result,相比 as 可以进行错误处理
let x: i32 = 5;
// i32 转成 u8,需要在这里显式指定目标类型:
let y: u8 = x.try_into().unwrap(); // 转成 u8⚠️ 这是 Rust 中很常用的形式,函数返回 Result 枚举,直接将其放到 match 中处理成功、失败两种可能
泛型
结构体泛型
turbofish 语法传入泛型
结构体泛型
struct Point<T>{
x:T,
y:T
}
fn main() {
// 显式指定泛型 (⚠️ 与其他语言不同,显示指定泛型需要直接标记到 变量上)
let p1:Point<f32> = Point{x:1.0,y:2.0};
// 结构体名::<T>、函数名::<T> ,这种显示指定泛型的语法,称为 turbofish 语法
let p2 = Point::<i32>{x:1,y:2};
// 通过第一个类型为 T 的变量,推断出 T 的值
let p3 = Point{x:1,y:2}; // 推断为 i32
let p4 = Point{x:1.0,y:2.0}; // 推断为 f64
}
// ---------------------------------------------
// 元组结构体
struct Point<T>(T,T)结构体方法、关联方法使用泛型
struct Wrapper<T> {
item: T,
}
// impl<T> :这个 T 在 impl block 域中定义了泛型T ,后面是用的 T 都是这里定义的
// Wrapper<T>:这个是结构体的名字
impl<T> Wrapper<T> {
fn new(item: T) -> Self {
Wrapper { item }
}
fn get_item(&self) -> &T {
&self.item
}
}
// 可以为 T = 某具体类型时指定方法。例如:只有泛型是 u32时,才有 add 方法
impl Wrapper<u32> {
fn add(&mut self) -> &u32 {
self.item+=1
&self.item
}
}
fn main() {
// 默认根据 item 值推导出 T 为 &str 类型
let w1 = Wrapper::new("Hello, world!");
// turbofish 语法,通过 Wrapper::<&str> 指定泛型 T 是&str
let w2 = Wrapper::<&str>::new("Hello, world!");
// 只有 w3 有 add 方法
let w3 = Wrapper::<u32>::new(100);
println!("{}", w1.get_item());
}函数泛型
fn print_type<T>(item: T) {
println!("{:?}", item);
}
fn main() {
print_type(42); // 自动推断
print_type::<i32>(42); // turbofish 语法传入泛型
}枚举泛型
前面提到过的 Result,直接将泛型传递给变体
enum Result<T,E>{
Ok(T), // 返回成功的类型 T
Err(E) // 返回失败的类型 E
}
type xxx = Result<i32, &'static str>枚举的 turbofish 语法
let value=Option::<String>::None;特征泛型
trait MyTrait<T> {
fn get_name(&self) -> T;
}
// 实现特征
struct MyStruct{}
impl MyTrait<String> for MyStruct {
fn get_name(&self) -> String {
"get_name".to_string()
}
}
// 特征约束
fn do_something(s:impl MyTrait<String>) ->String{ // ⚠️不是 MyTrait<xxx=String>
s.get_name()
}别名泛型
type<T> = Vec<T>补充<>语法
Rust 中,将在实例化时才确定的参数放到 <> 中,例如前面学习的泛型、生命周期标记
共有三类 👇:
| 类型 | 示例 | 说明 |
|---|---|---|
| 类型参数(type parameter) | T、 U | 例如 Vec<T> |
| 生命周期参数(lifetime parameter) | 'a、'static | 生命周期标记 |
| 常量泛型参数(const generic parameter) | const N: usize | 代表编译期常量,如数组长度 [T; N] |
使用逗号分隔
特征 Trait
类似 TS inerface
但是
- Trait (特征)不是一种类型,仅仅是有对泛型进行约束的能力
- **dyn Trait(特征对象) **才是一种类型
声明特征
1、特征包含函数签名、函数,还能指定特定类型才能实现的签名、函数
trait Animate{
// 关联方法签名
fn new()->Self;
// 方法签名
fn eat(&self)->bool;
// 已实现方法,能调用签名
fn live(&self)->bool{
self.eat()
}
// 指定实现了 Sized 的类型,才需要实现的签名
fn sum(self)
where
Self: Sized // Sized trait 表示编译时大小已知的类型。
{
// ...
}
}实现特征
实现特征有 2 种方式
手动实现特征签名
rusttrait Animate{ // 方法签名 fn eat(&self)->bool; } struct Dog{ name:String, health:bool } // 为结构体 Dog 实现 Animate 特征 impl Animate for Dog{ fn eat(&self)->bool{ self.health // 健康的才能进食 } } fn main() { // 实现了特征后,也会拥有 live 方法 let d = Dog{name:"hello".to_string(),health:true}; let ret = d.eat(); }通过 derive 派生特征
Rust可以通过 derive 派生,自动为结构体、枚举类型实现某些 Trait。目前支持:
用于开发者输出的 Debug
等值比较 PartialEq、Eq
次序比较的 PartialOrd 和 Ord
复制值的 Clone和 Copy
固定大小的值映射的 Hash
默认值的 Default
参考:https://course.rs/appendix/derive.html
rust// 为结构体 Stu 派生 Debug Trait,支持{:?}输出内部结构 #[derive(Debug)] struct Stu{ name: String, } fn main() { let s = Stu{name:"John".to_string()}; println!("{:?}", s); // Stu { name: "John" } }
特征继承
trait trait_z : trait_x + trait_y{
// ...
}
// trait_z,处理要实现其内部签名,还要实现 trait_x、trait_y 的签名
struct MyStruct{};
impl trait_z for MyStruct{
// trait_z 签名
// trait_x 签名
// trait_y 签名
}特征约束(trait bound)
Trait 可以约束泛型,这里很容易和其他语言搞混。误以为 Trait 是种类型,可以把这里当成全新的语法
<T:traitX> 仅仅是描述 T 需要实现 traitX
函数入参类型
trait traitX{}
trait taritY{}
// 方式 1:约束泛型
fn notify<T:trait_x>(item:&T){}
fn notify<T:trait_x + trait_y>(item:&T){}
// 方式 2:简写语法糖 impl trait
fn notify(item: &impl trait_x) {}
fn notify(item: &(impl trait_x + trait_y)) {}
// 方式 3:where ,当泛型比较多、复杂时,建议用 where
fn notify<T,U>(item: &T)
where
T:trait_x + trait_y, // 泛型 T
U:trait_y //
{
// ...
}函数调用如何传入泛型? 前面【泛型】章节提到了,需要使用 turbofish 语法
notify::<实现了 Trait 的类型>()函数返参类型
Rust 提倡零成本抽象,特征作为入参。编译结果会将所有可能罗列出来
// 假设代码里 struct A、struct B 实现了 X
fn notify(item: &impl X){}
// 实际编译结果
fn notify(item:A){}
fn notify(item:B){}而返回值不一样,Rust 无法分析函数的复杂逻辑,所以没办法根据实际入参,推断出实际返参
所以,Rust 语法要求函数只允许返回一种具体类型
特征 X 作为返回类型, A、B 都实现了该特征 X,也会编译不通过
trait trait_x{}
struct A{}
impl trait_x for A{}
struct B{}
impl trait_x for B{}
// ✅ 编译通过
// impl trait_x 是语法糖,本质是对泛型的约束
// trait_x不是类型,为啥这里还能编译通过? 因为编译器静态分析出返回类型是 A
fn notify1() ->impl trait_x{
A {}
}
// ❌ 编译不通过
// 动态设置返回类型,编译器是分析不出来的。所以就必须明确类型
fn notify2(is:bool) ->impl trait_x{ // `impl 特征`
if is{
A {}
}else {
B {}
}
}
fn main() {
notify1();
notify2(false);
}这就引出了特征对象的概念了
特征对象
dyn Trait 才是类型,但是这是一种特殊的类型,即 DST(动态大小类型,str、[T]、dyn Trait 都是)
Rust 要求所有类型必须在编译期间就能确定大小,所以 DST 类型不能直接使用。通过下面的 2 种方式就变成指针了,类型的大小是固定的了
使用方式:
引用
rust&DST // 比如: 场景的 &str 、 &[i32] ,实际上我们很少见到 str 、[i32] 这种类型智能指针
rustBox<DST> // 比如: Box<dyn Trait>
常见场景
Vec 是多个类型
trait TraitX{}
struct StructA{}
struct StructB{}
impl TraitX for StructA {}
impl TraitX for StructB {}
fn main() {
let x:Vec<Box<dyn TraitX>> = vec![Box::new(StructA{}),Box::new(StructB{})];
}返参是多个类型
// ✅ 编译通过
trait trait_x{}
struct A{}
impl trait_x for A{}
struct B{}
impl trait_x for B{}
fn notify2(is:bool) -> Box<dyn trait_x> { // dyn trait_x 是类型,Box<_>表示将类型分配到堆上,返回栈指针,指向堆数据。这样就是 Sized 类型了
// ...
if is{
Box::new(A{}) // Box::new(数据) 是创建智能指针
}else {
Box::new(B{})
}
}
fn main() {
notify2(false);
}关联类型
trait MyTrait {
type Output; // Trait定义的类型,称为“关联类型”
fn get_name(&self) -> Self::Output;
}
// 情景 1: 实现 trait
struct Stu{
name:String
}
impl MyTrait for Stu {
type Output= String; // 指定关联类型,甚至可以用泛型传入关联类型
fn get_name(&self) -> &Self::Output{ // Self::类型名 访问到类型。或者返回类型直接写 String
&self.name
}
}
// 情景 2: 作为特征约束
fn do_something(s:impl MyTrait<Output=String>) ->String{
s.get_name() // 这里就知道返回值是 String 类型,因为<Output=String>
}情景 2 特别容易和泛型混
trait MyTrait<T> {
fn get_name(&self) -> T;
}
// 情景 1: 实现 trait
struct MyStruct{}
impl MyTrait<String> for MyStruct {
fn get_name(&self) -> String {
"get_name".to_string()
}
}
// 情景 2: 作为特征约束
fn do_something(s:impl MyTrait<String>) ->String{ // ⚠️不是 MyTrait<xxx=String>
s.get_name()
}Rust 中关联类型的例子:迭代器
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>; // next 返回迭代器中的元素,具体元素类型是 实现Iterator的类型定义的
}特殊用法
通用实现(blanket)
标准库内部的 通用实现(blanket impl),为类型 T 实现特征 B,T 需要显示先特征 A
例如 Iterator 类型实现了,【迭代器】章节会提到
// --------------- x.rs ---------------------
pub trait TraitA {
fn to_a(&self) -> String;
}
pub trait TraitB {
fn to_b(&self) -> String;
}
// blanket impl:只要实现了 ATrait,就自动实现了 X
// 两个 Trait 必须是 pub,blanket impl不用加 pub
impl<T: TraitA> TraitB for T {
fn to_b(&self) -> String { // ⚠️ 这里实现具体的方法,不能用签名
"to_b".to_string()
}
}
// --------------- main.rs ---------------------
mod x;
use x::{TraitA, TraitB};
struct Stu{}
impl TraitA for Stu { // 实现了TraitA,自动就有了TraitB的方法
fn to_a(&self) -> String {
"to_a".to_string()
}
}
fn main() {
let s = Stu{};
s.to_a();
s.to_b();
}自动派生(auto trait)
auto trait 表示该 trait 会自动为所有内置类型实现
该特性目前还没有对开发者开放 ,只有Rust 内置的 Sync、Send Trait 实现了
// 类型这种语法
auto trait IsCool {}
impl !IsCool for String {} // 表示只有 String 不实现 IsCool常见内置 Trait 总结
关于实现 Trait 的一些经验?
- 每个 Trait 都有对应的语义,比如 PartialEq Trait 是为了支持
==运算符 - 内置类型实现了没有实现某 Trait ,就证明这个类型不能支持Trait 代表的语义。
- 不要为内置类型实现 Trait
- 不要覆盖内置类型原有Trait实现
- 对于开发者来说,我们大部分是使用自定义的 结构体、枚举 ,这些类型默认是没有任何Trait实现的。例如:有结构体类型 X ,什么时候该为 X 实现 PartialEq Trait ?
- 开发过程中调用外部函数 F ,函数 F 要求入参需要实现 PartialEq 类型
- X 需要支持比较能力
Debug、Display
Display Trait
// 1、Trait 定义
pub trait Display {
fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>;
}
// 2、触发
println!("{}", x ); // {} 占位符会调用 x.fmt
// 3、实现 Trait
use std::fmt;
use std::fmt::Display;
fn main() {
struct Stu {}
impl Display for Stu {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "Display output")
}
}
println!("{}", Stu {}); // Display output
}
// 4、默认实现了该 Trait 的类型
// 简单类型都实现了,例如数字、布尔值、字符串。对于复杂对象,就要用到 Debug Trait 输出了Debug Trait
// 1、Trait 定义
pub trait Debug {
fn fmt(&self, f: &mut Formatter<'_>) -> Result;
}
// 2、触发
println!("{:?}", x ); // {:?} 占位符会调用 x.fmt
println!("{:#?}", x ); // 带缩进换行的美化输出 {:#?} 占位符会调用 x.fmt
// 3、实现 Trait
// 3-1 结构体、枚举派生宏
use std::fmt::Debug;
#[derive(Debug)]
struct Stu{}
// 3-2 手动实现
use std::fmt::Debug;
struct Point {
x: i32,
y: i32,
}
impl Debug for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "Point({}, {})", self.x, self.y)
}
}
// 4、默认实现了该 Trait 的类型
// 简单类型中 数字(对于无符号类型中只有 usize 实现了 Debug)、char、bool、str、String实现了
// 对于常用复杂结构(T1, T2, ..., TN) 元组、[T; N]数组、 Vec<T> 、HashMap<K,V>、&[T]、 其中泛型实现Debug,就整体就实现了
// 内置枚举 Option<T>、Result<T,E> ,其中 T、E:Debug 整体就实现了 Debug
// 智能指针 Box<T>、Rc<T>、Arc<T>、RefCell<T> ,其中 T:Debug 整体就实现了 Debug
// 特别注意不支持的类型:
// 1、结构体、其他枚举(支持派生宏、手动实现)
// 1、u8、u16、u32、u64 是没有实现 Debug,所以关联的 Vec<u8> 、 &[u8]也没有
impl<T: fmt::Debug, A: Allocator> fmt::Debug for Vec<T, A> {
//...
}
impl<K, V, S> Debug for HashMap<K, V, S>
where
K: Debug,
V: Debug,
{
//...
}
impl<T: Debug> Debug for [T] {
//...
}
// 这个是个 fmt_refs 宏,$tr可以传入 Debug
impl<T: ?Sized + $tr> $tr for &T {
//...
}
impl<T: ?Sized + $tr> $tr for &mut T {
//...
}Default
默认值
// 1、Trait 定义
pub trait Debug {
fn default() -> Self; // 这个 Self 指的是实现 Debug Trait 的类型
}
// 2、触发
let x :Result<u32,&str> = Err("异常");
println!("{}", x.unwrap_or_default()); // 默认值 Some(数字).default() ,即 0
// 3、实现 Trait
// 3-1 派生宏
// 返回默认值 ,Rust 为内置的类型都实现了 Default Trait
#[derive(Default)]
struct Stu{
name: String, // 默认""
age: u8, // 默认 0
score:HashMap<String, i32>,// 默认 {}
hobby:Vec<String> // 默认 []
x:X // 如果字段是结构体类型,有需要 derive 派生 Default
}
#[derive(Default)]
struct X{}
// 3-2 手动实现。可以自己设置默认值
#[derive(Debug)]
struct Stu {
name: String,
age: u8,
}
impl Default for Stu {
fn default() -> Stu {
Stu {
name: "匿名".to_string(), // 派生语法 name 默认值是空字符串,手动实现更灵活
age: 0,
}
}
}
let s = Stu {
age: 20,
..Default::default() // 结构体语法,其他字段使用默认值
};
println!("{:?}", s);
// 4、默认实现了该 Trait 的类型
// 简单类型: 数字(默认 整数是0、浮点数是0.0)、char(默认'\x00',一个不可见字符)、bool(默认false)、&str、String(默认"")
// 复杂结构: (T1, T2, ..., TN) 元组、 Vec<T> 、HashMap<K,V> 其中泛型实现Default,就整体就实现了
// 内置枚举: Option<T>(默认 None)、Result<T,E> (默认是Some(T) = T的默认值)
// 智能指针: Box<T>、Rc<T>、Arc<T>,其中 T:Default 整体就实现了PartialEq、Eq
决定了Rust 中哪些类型可以比较的
PartialEq:
==、!=时会调用 PartialEq 的方法返回结果(Rust 中一些复杂对象也能用==直接判断)Eq:继承于PartialEq,是可严格比较的标记,实际没有语法去自动掉用 Eq 的方法
有些函数入参、泛型会要求实现 Eq 或 PartialEq。例如:HashMap 要求 Key 必须实现 Eq、HashSet 的元素也要求实现 Eq
PartialEq
// 1、Trait 定义
pub trait PartialEq<Rhs: ?Sized = Self> {
// == 调用
fn eq(&self, other: &Rhs) -> bool;
// != 调用,Trait 中已实现了
fn ne(&self, other: &Rhs) -> bool {
!self.eq(other)
}
}
// 2、触发
// == 、!=
// 3、实现 Trait
// 3-1 派生宏
#[derive(PartialEq)]
struct Stu {
id: u8,
name: String,
age: u8,
}
// 3-2 手动实现
fn main() {
struct Stu {
id: u8,
name: String,
age: u8,
}
impl PartialEq for Stu {
fn eq(&self, other: &Stu) -> bool {
self.id == other.id // 只对比 id
}
}
let s1 = Stu {
id: 1,
name: "tom".to_string(),
age: 25,
};
let s2 = Stu {
id: 1,
name: "jack".to_string(),
age: 30,
};
print!("{}", s1 == s2); // true
}Eq
// 1、Trait 定义
pub trait Eq: PartialEq<Self> { // 继承PartialEq
fn assert_receiver_is_total_eq(&self) {} // ⚠️这个Trait标记了可以严格比较,不能被手动实现
}
// 2、触发
// 无
// 3、实现 Trait
// 3-1 派生宏
#[derive(Eq,PartialEq)] // 实现了Eq,必须也要实现 PartialEq
struct Stu {
id: u8,
name: String,
age: u8,
}
// 4、默认实现了该 Trait 的类型
// 简单类型中 整数数字(浮点数只实现了 PartialEq )、char、bool、String、&T(T:Eq,&T也实现了 Eq)
// 复杂类型 (T1, T2, ..., TN) 元组、 Vec<T> 、结构体 其中成员实现了 Eq,整体就实现了Ord、PartialOrd
决定了Rust 中哪些类型可以排序的
// 1、Trait 定义
pub trait PartialOrd<Rhs: ?Sized = Self>: PartialEq<Rhs> {
// 只有这一个未实现的方法
fn partial_cmp(&self, other: &Rhs) -> Option<Ordering>;
fn lt(&self, other: &Rhs) -> bool {
matches!(self.partial_cmp(other), Some(Less))
}
fn le(&self, other: &Rhs) -> bool {
matches!(self.partial_cmp(other), Some(Less | Equal))
}
fn gt(&self, other: &Rhs) -> bool {
matches!(self.partial_cmp(other), Some(Greater))
}
fn ge(&self, other: &Rhs) -> bool {
matches!(self.partial_cmp(other), Some(Greater | Equal))
}
}Copy、Clone
Rust 中最重要的概念所有权转移,也是基于 Copy 的
实现 Clone 的类型,可调用 clone 方法拷贝数据
实现 Copy 的类型,发生赋值时会复制了一份数据给新变量,没实现的就会所有权转移
注意:Copy 的能力是编辑器提供的,并不依赖 Clone 提供的能力。但是 Rust 为了保证语义上的统一,即能自动Copy的类型,肯定也能手动Clone,所以要求实现 Copy 时,必须先实现 Clone
// 1、Trait 定义
pub trait Clone: Sized {
// 只有这个是未实现的方法
fn clone(&self) -> Self;
fn clone_from(&mut self, source: &Self) {
*self = source.clone()
}
}
// 2、触发
// 手动调用.clone()
// 某些方法,例如迭代器 clone 是对每个元素调用.cloned()
// 3、实现 Trait
// 3-1 派生宏
#[derive(Clone)]
// 3-2 手动实现(略)
// 4、默认实现了该 Trait 的类型
// 简单类型: 数字、char、bool、&T
// 复杂结构: (T1, T2, ..., TN) 元组、 Vec<T> 、HashMap<K,V> 保证泛型实现Clone
// 内置枚举: Option<T>、Result<T,E> ,保证 T 实现Clone
// 智能指针: Box<T>、Rc<T>、Arc<T>,保证 T 实现Clone// 1、Trait 定义 (Copy 由编译器内部来实现,所以是空的)
pub trait Copy: Clone {
// Empty.
}
// 2、触发
// 赋值,或是某些方法,例如迭代器 copy 是对每个元素调用.copied()
// 3、实现 Trait
// 3-1 派生宏
// 结构体默认是没有 Copy 的会发生 move,但是派生后,赋值不会发生所有转移了
// 注意:要求结构体字段都实现 Copy ,才能派生 Copy
#[derive(Copy,Clone)]
struct Stu<'a>{
name:&'a str,
age:u8
}
// 4、默认实现了该 Trait 的类型
// 参考:前面所有权转移规则里的类型Deref
实现了Deref<Target=U>的类型T,可以解引用 &T -> &U
- 在自动解引用场景
- 手动解引用场景
*T(*触发了解引用*T = *(T.deref()))
// Deref 定义
pub trait Deref {
type Target: ?Sized; // 关联类型
fn deref(&self) -> &Self::Target;
}
// 通用实现 blanket
// 为所有引用类型实现Deref,解引用 &T -> &T ,看起来没啥用。其实引用类型能自动调用deref
impl<T: ?Sized> const Deref for &T {
type Target = T;
fn deref(&self) -> &T { // 返回的是引用
*self
}
}Drop
Hash
Send & Sync
集合类型
Vec
动态数组。每个元组类型一致,可以动态增、减的数组元素
动态数组也有长度 v.len()、容量的概念 v.capacity()。容量是底层划分的存储元素个数,长度是实际占用的
增加元素时,如果容量不足就会导致 vector 扩容(目前的策略是重新申请一块 2 倍大小的内存,再将所有元素拷贝到新的内存位置,同时更新指针数据),频繁扩容导致的内存拷贝会降低程序的性能
初始化
// 1、申请 Vec 容量为 20 ,追加数据
let mut v = Vec::with_capacity(20);
v.extend([1,2,3]);
// 2、结构体 Vec 的 new 方法 (空的,默认容量 0)
let mut v = Vec::new(); // v.push(1) 推入元素时自动扩容
// 3、结构体 Vec 的 from 方法 (支持初始化元素,默认容量=初始化数组长度)
let mut v = Vec::from([1, 2, 3, 4, 5]);
// 4、数组 / 切片转成 Vec
let mut v = [11, 22].to_vec();
// 5、使用 vec! 宏 (支持初始化元素,默认容量=初始化数组长度m)
let mut v = vec![1, 2, 3, 4];v.reserve(100); // 参数 n 表示扩容空间,总容量 = 原本的len + n读取元素
let x = v[0]; // 返回索引 0 的元素
let x = v.get(0); // 返回一个 Option 类型,即 Some(值) 或 None
// 区别
// get数组越界程序不会崩溃,而是返回 None遍历读取
Vec不是迭代器类型,但是其实现了 IntoIterator Trait, for 语法会调用 into_iter 转换为迭代器类型
into_iter():将 Vec 转化为迭代器,发生所有权转移iter():将 Vec 转化为不可变引用迭代器iter_mut():将 Vec 转化为可变引用迭代器
// 会发生所有转移
let v = vec![1, 2, 3];
for i in v { // 这个底层 let iter = v.into_iter(); vec 的说有钱转移到了迭代器上
println!("{i}");
}
print!("{}",v) ❌
// --------------------------------------
// 所以一般用&、&mut,避免所有权转移
let v = vec![1, 2, 3];
for i in &v {
println!("{i}");
}
// 遍历过程中修改
let mut v = vec![1, 2, 3];
for i in &mut v {
*i+=1;
println!("{i}");
}
// 需要索引。这里需要显式转成迭代器
for (index,value) in v.iter().enumerate() {
println!("{index},{value}");
}常用动态数组操作方法
// 操作 vec 需要 mut 类型
let mut v = vec![1, 2];
println!("{}", v.is_empty()); // false 判空
v.insert(2,3);; // [1, 2, 3] 插入
v.append(&mut vec![4,5]); // [1, 2, 3, 4, 5] 追加数组 。⚠️ 这里入参是&mut,这是因为append 保留了原数组所有权,将原数组掏空,转移到了v中
v.truncate(3); // [1, 2, 3] 截断 3 位
v.push(4); // [1, 2, 3, 4]
v.pop();// [1, 2, 3] 返回 Option
println!("{:?}",&v[1..]); // [2, 3] 动态数组切片 (切片是动态大小类型,在编译时大小未知,无法直接作为值使用所以会报错。只能用引用形式)
v.remove(1); // [2] 移除指定位置元素,返回被移除的元素
v.clear(); // [] 清空处理数据的方法,通常将 vec 转化为不变引用迭代器(iter)处理数据,返回处理结果
struct Stu {
name:String,
age:u8
}
fn main() {
// 类似 JS 的 filter
let v1 = vec![1,2,3];
v1.retain(|x| *x >= 2);
println!("{:?}",v1); // [2, 3]
// 转换为迭代器
let v3 = vec![
Stu{ name:"tom".to_string(), age:20 },
Stu{ name:"jack".to_string(), age:10 },
];
// map 方法是映射到新的 Vec 中
// v3.iter() Vec 不是迭代器类型,需要 iter 获取Itr<Stu>,才能遍历 。需要用&否则所有权会转移
// name_list 是 Vec<&String> 类型
// collect函数传入泛型 ::<Vec<&String>> ,泛型是生成的 Vec 的类型
let name_list: Vec<_>= v3.iter().map(|item| &item.name ).collect::<Vec<&String>>();
println!("{:?}",name_list); // ["tom", "jack"]
}排序:
- 稳定的排序
sort和sort_by - 非稳定排序
sort_unstable和sort_unstable_by
排序时当遇到相同数值时,稳定排序会保留源数据顺序。不稳定排序,则不一定
#[derive(Debug)]
struct Stu {
name:String,
age:u8
}
fn main() {
// 排序
let mut v1=vec![5,2,3];
v1.sort();
println!("{:?}",v1); // [2, 3, 5] 从小到大
// 类似 JS 的 map
let v2 = vec![
Stu{ name:"tom".to_string(), age:20 },
Stu{ name:"jack".to_string(), age:10 },
];
// 按年龄排序
// x.cmp 返回 Ordering枚举 ,sort_by 接收这个枚举类型
//pub enum Ordering {
// Less = -1,
// Equal = 0,
// Greater = 1,
//}
// a第一个、b 第二个数据,x.cmp(y)就直接看 x<y。y 是 b 就是朝向大的方向
v2.sort_by(|a,b| a.age.cmp(&b.age));
println!("{:?}",v); // [Stu { name: "jack", age: 10 }, Stu { name: "tom", age: 20 }]
}切片 、 Vec类型
// 1、Vec<T> --> &[T]
let x: Vec<String> = vec![
"Rust".to_string(),
"is".to_string(),
"awesome!".to_string()
];
// 两种写法:
&x // 自动解引用成切片:&Vec<String> -> &[String]
&x[..] // 显式转成切片
// 2、Vec<T> <-- &[T]
let y: &[u8] = b"Hello, world!"; // 使用字节字符串语法。内存存储与"Hello, world!"一样,只是Rust中推断的类型不一样
y.to_vec(); // ⚠️ 这种会发生内存深拷贝,十分损耗性能。建议一般不要转化
// eq 比较 ,注意需要 T 实现了 Eq Trait
Vec<T>.eq(&[T])HashMap
HashMap 没有在 prelude 引入,所以需要开发者手动引入
初始化
use std::collections::HashMap;
fn main() {
// 1、确定容量
let mut h = HashMap::with_capacity(10);
// 2、HashMap的 new 方法
let mut h = HashMap::new();
// 第一次写入元素时,才会推导类型。我们也可以自己标记
let mut h:HashMap<&str,&str> = HashMap::new();
// 3、初始化内容
let h = HashMap::from([("a", 1), ("b", 2)]);
}写入数据 ( 第一次写入元素时,类型就推导出来了 )
// 1、插入 key-value ,返回值是 Option,Option::Some携带插入的 value
let ret = h.insert("name","tom"); // h 推断为: HashMao<&str,&str>
h.insert("name","jack"); // 插入 key 相同,则会覆盖
// 2、数组
h.extend([
("name","tom"),
("age","tom"),
]);
// 3、动态数组转换为 HashMap
let v = vec![
("数学",80),
("语文",80),
("英语",100),
];
let h =v.into_iter().collect::<HashMap<_, _>>(); // 转化为迭代器,然后collect转化为 HashMap
println!("{:?}", v); // ❌ into_iter会将 v 的所有权转移到迭代器中更新value
// 1、instert key已存在则覆盖。返回值:Option
let value_option = h.insert("name","tom");
// 2、entry 判断是否存在 key,存在返回 &mut value。不存在也提供大量函数出入数据后返回 &mut value
let entry = h.entry("key"); // 返回枚举 Entry,表示 key 是否存在
// pub enum Entry<'a, K: 'a, V: 'a> {
// Occupied(OccupiedEntry<'a, K, V>), // key 已存在
// Vact(VacantEntry<'a, K, V>), // key 不存在
// }
// 存在 key 则 and_modify 操作 value,不存在则出入 5
map.entry("name")
.and_modify(|v| *v += 5) // v 是 【&mut value 类型】
.or_insert(5);
let value = h.entry("name").or_insert(5);
// 不存在 key , 才会插入 key=5
let value = h.entry("name").or_insert(5);
// 不存在 key ,通过闭包计算插入值
let value = h.entry("name").or_insert_with(|| 1+1);
// 不存在 key ,通过闭包计算插入值。闭包入参是 key
let value = h.entry("name").or_insert_with_key(|key| key.len());
// 不存在 key ,插入默认值(注意啊需要标记 h 的类型,否则不知道 value 是啥类型的,咋写默认值啊)
let value = h.entry("name").or_default(); // {"name": ""}查找数据 (注意只是查找,返回的 value 都是 Some ,其中携带的都是引用,所以并不会导致元素所有权转移)
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("数学"), 10);
// 1、get 入参引用,返参 Some(不可变引用)
let ret= scores.get("数学");
println!("{:?}", ret); // Some(10)
println!("{:?}", scores); // {"数学": 10 }
// 2、get_mut 入参引用,返参 Some(可变引用)
if let Some(score) = scores.get_mut("数学") {
*score += 5; // 给 数学 加 5 分
}
println!("{:?}", scores); // {"数学": 15 }删除
if let Some(v) = h.remove("a") {
println!("{}",v)
}取出 key、value、key+value
注意: 没有 keys_mut 是因为hash根据 key 来存储的,不能随意改变 key
use std::collections::HashMap;
fn main() {
let h = HashMap::from([
("a", 1),
("b", 2)
]);
// keys 返回的是不变引用; into_keys 会转移所有权,导致 h 不可用
for key in h.keys() {
println!("{key}")
} // a b
// values返回的是不变引用;values_mut返回的是可变引用;into_values会转移所有权,导致 h 不可用
for value in h.values() {
println!("{value}")
} // 1 2
// iter返回的是不变引用元组(&Key,&Value) ;iter_mut返回的是可变引用元组 ; into_iter 转移所有权
for (key, value) in h.iter() {
println!("{key}:{value}")
} // b:2 a:1
} let mut s: HashSet<u64> = h.keys().cloned().collect(); // keys 是不可变引用,用 cloned 后收集为 HashSet遍历
与 Vec 一样,HashMap 也不是迭代器,但是其实现了 IntoIterator Trait,所以 for 语法能自动调用 into_iter 将其转化为迭代器
// 会发生所有权转移
for (key, value) in h {
println!("{} -> {}", key, value);
}
println!("{:?}",h); // ❌ 所有权转移
// 一般使用引用,不会转移
for (key, value) in &h {
println!("{:?} -> {}", key, value);
}
for (key, value) in &mut h { // 记得 h 也要是 mut 才行, let mut h =xxx
*value*=2; // 分数乘 2
println!("{:?} -> {}", key, value);
}经典计数器例子
use std::collections::HashMap;
fn main() {
let v =vec!['a', 'b', 'a'];
let mut m = HashMap::new();
for item in &v{
match m.get(item){
None => {
m.insert(*item, 1);
},
Some(count) =>{
m.insert(*item, *count+1);
}
}
}
println!("{:?}", m);
}使用 entry 真优雅啊。Rust 总是提供大量函数,帮助我们减少分支判断
use std::collections::HashMap;
fn main() {
let v =vec!['a', 'b', 'a'];
let mut m = HashMap::new();
for item in &v {
let mut count = m.entry(item).or_insert(0);
*count+=1;
}
print!("{:?}",m);
}BTreeMap
与 HashMap 相比
- 有序:键按照排序顺序存储,允许你以升序或降序遍历它们
- 无需哈希函数:不像
HashMap需要键实现了Hash和Eq,BTreeMap只需要键实现了Ord(或者使用自定义的PartialOrd实现) - 内存连续:
BTreeMap的节点在内存中是连续分配的,这可能改善缓存局部性
其他基本一致
HashSet(待补充)
就是 Set 集合,元素不重复
Sized
Rust 中的所有类型都可以分成两大类
- sized 定长类型,即编译期类型大小已知
- unsized 不定长类型(也称为 DST,dynamically sized types)),运行时才能动态获取
Rust 强制要求编译时必须确定类型大小
- 字符切片
&str,但是没有提到的str - 数组切片
&[T],但是没有提到的[T] - dyn Trait 也是 DST
我们只能间接使用 DST 类型:引用、智能指针两种方式。本质是使用指针指向动态类型,指针是存储在栈上的定长类型
泛型默认约束是 Sized 的,可以使用 ?Sized 来使用不定长类型
既然 Rust 只能用 Sized 类型,为啥还整个 ?Sized,无非是传入泛型的时候可以简单点,实际函数中还是使用引用 &T
fn generic<T: ?Sized>(t: &T) {
//
}裸指针
Rust 中的引用、智能指针,属于安全指针,受 Rust 所有权和借用规则保护。而裸指针是不安全的,用于底层操作,需谨慎使用
| 特性 | &mut T(可变引用) | *mut T(裸指针) |
|---|---|---|
| 类型类别 | 引用(reference) | 裸指针(raw pointer) |
| 安全性 | 安全(编译期保证别名规则) | 不安全(需 unsafe 使用) |
| 空值 | 永远非空(non-null) | 可以为 null |
| 生命周期 | 有生命周期(如 &'a mut T) | 无生命周期,不被借用检查器跟踪 |
| 创建方式 | &mut expr | &mut expr as *mut T 或 ptr::null_mut() |
| 解引用 | 直接 *y = 2;(安全) | 必须在 unsafe 块中:unsafe { *y = 2; } |
let mut x = 1;
// 可变引用:&mut i32
let y: &mut i32 = &mut x;
*y = 42; // ✅ 安全,无需 unsafe
// 裸指针:*mut i32
let z: *mut i32 = &mut x as *mut i32;
unsafe {
*z = 100; // ❗必须用 unsafe
}Rust 圣经中裸指针有下面例子:
let p = 5 as *mut u8; // 一般情况下,我们是从引用中读取地址,转化为裸指针。这里是将 5 当做内存地址,即0x00000005智能指针
智能指针是实现了 Deref 和 Drop trait 的类型,它们像指针一样可以解引用,但能自动管理资源(如内存、文件句柄、锁等)
**Deref Trait **
可以让智能指针使用例如 *T,解出内部的数据 (解引用的总结:【所有权与引用 - 解引用】)
智能指针解引用返回的是 内部数据的引用 ,再加 *才获取到数据
// Deref Trait
pub trait Deref {
type Target: ?Sized; // 关联类型
fn deref(&self) -> &Self::Target;
}
// 以智能指针 Box 为例子,他的实现
impl<T: ?Sized, A: Allocator> Deref for Box<T, A> {
type Target = T;
fn deref(&self) -> &T {
&**self
}
}例子
let mut count = Box::new(0);
*count += 1;
print!("{count1}");Drop Trait
开发者指定智能指针超出作用域后自动执行的代码,做一些数据清除等收尾工作(Rust 几乎为所有类型都实现了 Drop Trait)。但是,例如文件描述符、网络 socket 等,当这些值超出作用域需要手动进行关闭以释放相关的资源
struct MyStruct{};
impl Drop for MyStruct {
fn drop(&mut self) {
println!("drop 前执行的清理逻辑");
}
}
// ---------- 主动释放 ------------
let x = MyStruct{};
// ❌ drop 方法参数是个可变引用,如果通过引用释放了内存,那持有所有权变量就错了
x.drop();
// ✅ drop 函数参数会转移所有权,就能直接 drop 释放了
drop(x)
// ---------- Copy Trait ------------
// 实现了 Copy Trait 的类型,不能实现 Drop Trait。
// 而且,本来Rust中默认实现 Copy 的类型,都是分配在栈上的,只需要栈指针回退即可,无需 drop 释放内存Box
Rust 中的类型都需要是在编译器能确定的固定大小的。而有些类型是不固定的,这时候就需要用 Box了
前面提到的 Vec 和 String 都是智能指针,指针存储在栈上,指向堆上的数据
智能指针类型 Box<T>
Box::new
例子参考【特征 Trait - 特征对象】章节
Box::leak
入参是 Box<T> 指针,解引用拿到堆上数据并转换为 &'static T , 即 Rust 不会再管理这块内存,永远不会 drop
// 正常情况下,所有权在函数里,必须返回 s 才能保证内存不被 drop
// 通过 Box::leak 手动制造了内存泄露
fn gen_static_str() -> &'static str {
let mut s = String::new();
s.push_str("hello, world");
Box::leak(s.into_boxed_str())// 将字符串转成 Box<str>
// Box::leak 解引用拿到堆上数据返回
}这个用处很大,将一个动态内容变成静态的。注意:不要大量制造这种内存泄露
使用场景: 动态读取的配置、动态注册
读取配置
rust// config 是读取的 static GLOBAL: &str = Box::leak(config.to_string().into_boxed_str());插件注册表
rustfn register(name: &'static str) { REGISTRY.lock().unwrap().push(name); } fn main() { // plugin_name 是动态输入的 let plugin_name = Box::leak(plugin_name.to_string().into_boxed_str()); register(plugin_name); }
Rc、Arc
作用:打破所有权限制,允许数据能被多个变量持有,使用引用计数器记录被引用此时,当应用计数器归零则释放资源
Rc、Arc 功能一致,唯一的区别是 Arc 具有原子性是用在多线程中的
值发生所有权转移到某一个线程中,就其他线程不能用了,Arc 允许多个线程共用同一个值,例子参考【并发】章节
let num = Rc::new(0); // num 是一个引用
let num2 = Rc::clone(&num); // 再创建一个 num2 引用。虽然名为 clone 实际上不会发生数据的复制
// let num2 = num.clone() // Rc、Arc 都实现了 Clone Trait,调用.clone 也是等价的圣经的例子
use std::rc::Rc;
struct Owner {
name: String,
// ...其它字段
}
struct Gadget {
id: i32,
owner: Rc<Owner>,
// ...其它字段
}
fn main() {
// 创建一个基于引用计数的 `Owner`.
let gadget_owner: Rc<Owner> = Rc::new(Owner {
name: "Gadget Man".to_string(),
});
// 创建两个不同的工具,它们属于同一个主人
let gadget1 = Gadget {
id: 1,
owner: Rc::clone(&gadget_owner),
};
let gadget2 = Gadget {
id: 2,
owner: Rc::clone(&gadget_owner),
};
// 释放掉第一个 `Rc<Owner>`
drop(gadget_owner);
// 尽管在上面我们释放了 gadget_owner,但是依然可以在这里使用 owner 的信息
// 原因是在 drop 之前,存在三个指向 Gadget Man 的智能指针引用,上面仅仅
// drop 掉其中一个智能指针引用,而不是 drop 掉 owner 数据,外面还有两个
// 引用指向底层的 owner 数据,引用计数尚未清零
// 因此 owner 数据依然可以被使用
println!("Gadget {} owned by {}", gadget1.id, gadget1.owner.name);
println!("Gadget {} owned by {}", gadget2.id, gadget2.owner.name);
// 在函数最后,`gadget1` 和 `gadget2` 也被释放,最终引用计数归零,随后底层
// 数据也被清理释放
}Mutex、MutexGuard
作用:数据加锁,参考【并发】章节
let guard = Mutex::new(数据); //
let mut xx = guard.lock().unwrap(); // 返回 MutexGuard 智能指针,实现了 Deref 自动解引用拿到内部数据的引用
*x // 拿到数据Cell、RefCell
作用:打破借用检查,在拥有不可变引用的同时可以修改目标数据
借用检查只是 Rust 为了内存安全而设置的保守策略,即使违背了也不一定是错的。Cell、RefCell 相当于告诉编译器不需要报错,由开发者来保证正确性
Cell、RefCell 内部包裹了数据,即使这个对象是不可变引用,我们也能修改
Cell 用于已经实现了 Copy 的对象,剩下的用 RefCell
rustuse std::cell::Cell; fn main() { let c = Cell::new("asdf"); let one = c.get(); c.set("qwer"); let two = c.get(); println!("{},{}", one, two); }RefCell
rustuse std::cell::RefCell; // 三方定义的 Trait pub trait Messenger { fn send(&self, msg: String); } // 我们实现这个 Trait pub struct MsgQueue { msg_cache: RefCell<Vec<String>>, } impl Messenger for MsgQueue { fn send(&self, msg: String) { self.msg_cache.borrow_mut().push(msg) // 因为三方定义 send 是用来了 &self ,所以不能修改 msg_cache // ⭕️ RefCell 类型有方法 borrow_mut 可以打破借用检查 } } fn main() { let mq = MsgQueue { msg_cache: RefCell::new(Vec::new()), }; mq.send("hello, world".to_string()); }RefCell 还有其他方法
操作 方法 是否 panic 风险 获取共享借用(读) .borrow()❌ 如果有 .borrow_mut()正在进行获取可变借用(写) .borrow_mut()❌ 如果有其他借用正在使用 尝试获取共享借用 .try_borrow()✅ 不 panic,返回 Result尝试获取可变借用 .try_borrow_mut()✅ 返回 Result直接获取内部值的 mutable 引用 .get_mut()(&mut RefCell才有这个方法)❌ 无 panic 消耗 RefCell 获取原始值 .into_inner()❌ 无 panic
Cow
总结
Rc + RefCell 组合:Rc 负责同一数据的多个引用,RefCell 负责每个引用的修改
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let s = Rc::new(RefCell::new("多个主人".to_string()));
let s1 = s.clone();
let s2 = s.clone();
s2.borrow_mut().push_str(", oh yeah!");
println!("{:?}\n{:?}\n{:?}", s, s1, s2);
}Arc + Mutex 组合:Arc 负责多线程引用同一数据,Mutex 将数据加锁,保证并发正确性
迭代器(待补充)
迭代器 Iterator Trait
pub trait Iterator{
// ...
}迭代器最重要的是 next 方法,通过 next 方法可以不断消耗迭代器的内容
常见迭代器
// 动态数组
let v = vec![1, 2, 3, 4, 5]
v.into_iter() // 夺走每个元素的所有权
v.iter() // 对每个元素,生成借用
v.mut_iter() // 对每个元素,生成可变借用
// v 实现了IntoIterator trait,for 会自动调用 into_iter()
for i in v {
}
// 这会导致 v 不再可用,如果后续还需要用推荐使用
for i in &v{
}
// rang literal
for i in (1..4){
}通用实现
// 为 Iterator trait 实现了类型,实现 IntoIterator trait
// 翻译:如果类型 X 是迭代器类型,就是 IntoIterator 类型
impl<I: Iterator> IntoIterator for I {
type Item = I::Item;
type IntoIter = I;
#[inline]
fn into_iter(self) -> I {
self
}
}迭代器适配器
注意:
- 适配器方法,会消费原迭代器(原迭代器发生 move),返回新的迭代器
- 适配器方法是惰性的,需要调用消费适配器才会开始执行
| 适配器方法 | 含义简述 |
|---|---|
.map(f) | 每个元素映射为另一个值 |
.filter(f) | 筛选满足条件的元素 |
filter_map | 过滤 + 映射 (JS 里缺少这个方法,需用 reduce 才行,rust 直接提供了) |
.take(n) | 取前 n 个元素 |
.skip(n) | 跳过前 n 个元素 |
.rev() | 反转顺序(需要 DoubleEndedIterator) |
.enumerate() | 生成 (index, value) 元素对组成的迭代器 |
.zip(other) | 将两个迭代器“配对” |
.chain(other) | 拼接两个迭代器 |
.inspect(f) | 类似 tap,用于调试,中途查看 |
.flatten() | 将嵌套迭代器展平 |
.flat_map(f) | 映射并展平 |
.cloned() | 克隆元素(如 &T -> T),元素必须实现Clone |
.copied() | 复制元素(如 &i32 -> i32),元素必须实现Copy |
适配器可以链式调用处理数据,结尾必须使用消费适配器才能真正执行
fn main() {
let v = vec![1,2,3,4,5];
let ret = v
.into_iter()
.map(|item| item*2) // [2,4,6,8,10] item 是元素类型i32 ( 假设用 v.iter() 就是&i32 )
.filter(|item| *item < 9) // [2,4,6,8] item是元素的不可变引用 &i32
.take(3) // [2,4,6] 取前 n 个
.skip(1)// [4,6] 跳过前 n 个
.collect::<Vec<i32>>() // 将迭代器转成 Vec<i32>
// rev 逆序要求是 DoubleEndedIterator Trait,
// 经过filter、flat_map 后会失去该特性
.into_iter()
.rev()
.collect::<Vec<i32>>(); // [6, 4]
println!("{:?}", ret); // 因为用了 inter_iter ,这里 v 就已经失效了,转移到 ret 了
}
fn main() {
let v = vec![1,2,3,4,5];
let numbers: Vec<i32> = v
.into_iter()
.filter_map(|s| { // 返回值必须是 Option
if s % 2 == 1 {
Some(s*2)
} else {
None
}
})
.collect();
println!("{:?}", numbers); // [2, 6, 10]
}zip 组合两个迭代器元素,返回迭代器(元素是元组)
fn main() {
let names = vec!["Alice", "Bob", "Charlie"];
let ages = vec![30, 25, 35, 40]; // 注意:ages 比 names 长
// zip 会以较短的 names 为准,忽略 ages 的最后一个元素 (40)
for (name, age) in names.iter().zip(ages.iter()) {
println!("{} is {} years old.", name, age);
}
// 输出:
// Alice is 30 years old.
// Bob is 25 years old.
// Charlie is 35 years old.
}enumerate 常用来获取索引
for (index, item) in v.iter().enumerate() {
println!("{}. {}", index, item);
}注意所有权转移的问题。迭代器都是 self 的方法,但是动态数组 vec 使用 into_iter| iter | iter_mut 转化迭代器都能用 ( 调用方法时,会自动解引用为 self)
pub trait Iterator {
fn map<B, F>(self, f: F) -> Map<Self, F>
}消费适配器
| 终结器方法 | 含义简述 |
|---|---|
.collect() | 收集成容器(Vec、HashMap 等) |
.count() | 计数 |
.sum() | 求和 |
.product() | 连乘 |
.find() | 查找第一个满足条件的元素 |
.any() / .all() | 是否存在 / 所有都满足 |
.for_each() | 遍历每个元素,执行副作用逻辑 |
for x in 迭代器{} | |
.fold() | 累积归约(带初始值) |
.reduce() | 类似 fold 但无初始值 |
.max() / .min() | 最大 / 最小值 |
控制流
条件
支持作为表达式返回值
fn main() {
let number = 20;
let result = if number < 18 {
"未成年"
} else if number>=18 && number<50{
"中年"
} else {
"老年"
};
println!("{}", result); // 中年
}Rust中 判断 2 个变量是否相等
数组、切片、元组
在其他语言中,复杂类型都是无法直接比较的
rustfn main(){ let a = [1,2,3]; let b = [1,2,3]; if a == b{ println!("ok"); // 输出 ok }else { println!("fail"); } }
循环
支持 break、continue
for
for 循环 Range
for value in 1..5{
println!("{}", value); // 从 1 到 4
}
for value in 1..=5{
println!("{}", value); // 从 1 到 5
}遍历数组
fn main() {
let mut x =[1,2,3];
// 每个 value 持有元素的所有权
for value in x{
print!("{} ", value);
}
// 不可变引用,只读不能改变元素
for value in &x{ // 等价于 for value in x.iter()
print!("{} ", value);
}
// 可变引用,可以遍历过程中改变值
for value in &mut x{
*value+=1;
}
print!("{:?} ", x); //[2, 3, 4]
// 迭代器enumerate方法,支持返回索引、值
for (index,value) in x.iter().enumerate(){
println!("index:{} value:{}", index,value); //[2, 3, 4]
}
}loop
一直循环
fn main() {
let mut counter = 0;
// loop 是一直循环,可以通过 break 结束并返回值
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2; // break xxx 支持作为 loop 的返回值
}
};
println!("{}",result);
}while
fn main() {
let mut index = 0;
while index < 5 {
println!("{}", index);
index = index + 1;
}
}模式匹配
match
类似与其他语言中的 switch 语法
match 变量其中变量支持多种类型- 分支只能是常量
- 多个满足条件的分支,命中第一个
数值、布尔值、字符、字符串
直接对比变量匹配哪个分支
fn main() {
let number = 13;
// 你可以试着修改上面的数字值,看看下面走哪个分支
println!("Tell me about {}", number);
match number {
// 匹配单个数字
1 => println!("One!"),
// 匹配几个数字
2 | 3 | 5 | 7 | 11 => println!("This is a prime"),
// 匹配一个范围,左闭右闭区间
13..=19 => println!("A teen"),
// 处理剩下的情况
_ => println!("Ain't special"),
}
}数值、字符加支持匹配范围
13..=19 => println!("A teen"),
'a'..='z' => println!("early ASCII letter"),枚举
不带负载的枚举,也是直接对比变量匹配哪个分支
enum Color{
Blue,
Yellow,
Red,
Green,
Black
}
fn main() {
let my_color = Color::Red;
// match 有返回值
let ret = match my_color{
// 1、 多个条件用 | 拼接
Color::Blue|Color::Yellow => "blue或yellow",
// 2、 处理语句多行时,需要放在{}作用域内
Color::Red => "red", // 这可千万别当成 JS 的箭头函数。而是函数的最后一个表达式就是返回值
Color::Green => {
"green"
},
// 3、Rust 强制必须把枚举的所有分支都写出来,如何需要省略就用 _
_ => {
"未知"
}
}; // 一旦赋值就是语句了,加分号
println!("{}",ret);
}match 带变体的枚举,命中枚举类型后可以解构携带的数据
enum Shape {
Rectangle { width:u32,height:u32 }, // 矩形, 负载是结构体 ,使用{ }
Triangle ((u32,u32),(u32,u32),(u32,u32)),// 三角形, 负载是元组 ,使用()
Circle { origin:(u32,u32), radius:u32 }, // 圆形,负载是 结构体
}
fn main(){
// let s = Shape::Circle {origin:(0,0),radius:20};
let s = Shape::Triangle ((0,0),(1,1),(2,2));
match s{
// 常量
Shape::Rectangle {width:120,height:20} =>{ // 必须与实例化数据一致才能匹配上
println!("命中")
}
// 解构结构体字段
Shape::Circle {origin,radius} =>{ // 解构构(类似 JS 中的解构)
println!("命中 origin:{:?} radius:{}",origin,radius) // 输出 命中 origin:(0, 0) radius:20
}
// 还可以将更深层的内容解开
//Shape::Circle {origin:(x,y),radius} =>{ //
// println!("命中 origin:({},{}) radius:{}",x,y,radius) // 输出 命中 origin:(0, 0) radius:20
//}
Shape::Triangle(x,y,z)=>{
println!("命中 {:?} {:?} {:?}",x,y,z);
}
_ => {
println!("未命中");
}
}
}结构体
命中符合条件的结构体类型后,解构字段
fn main(){
struct Point { x: i32, y: i32 }
let p = Point { x: 1, y: 2 };
match p {
Point { x: 0, y } => println!("x is zero, y = {}", y),
Point { x, y } => println!("Point at ({}, {})", x, y),
}
}元组
命中符合条件的元组类型后,解构数组中的数据
fn main(){
let t = (1, true);
match t {
// (1, true) => println!("完全匹配"),
(x, true) => println!("{}",x), // 1
_ => println!("其他"),
}
}数组、切片
命中符合条件的数组类型后,解构数组中的数据
fn main(){
let arr = [1, 2, 3];
match arr {
// [1, 2, 3] => println!("完全匹配"),
[_, 2, _] => println!("第 2 个元素是 2 的"),
_ => println!("其他"),
}
}match 匹配守卫
前面提到 带负载的枚举、数组、元组、结构体等等,都能部分匹配上,然后解构复杂类型里的数据
可以看到分支,可以用 if 继续验证解构出来的数据
fn main(){
struct Point { x: i32, y: i32 }
let p = Point { x: 1, y: 2 };
match p {
Point { x: 0, y } => println!("x = 0, y = {}", y),
Point { x, y } if y==2 => println!("x = {}, y = {}", x, y), // x = 1, y = 2
_ => {}
}
}为啥加个守卫?解构出来数据后, if 可以进行更具体的判断
fn main(){
struct Stu { name :String}
let s = Stu { name:"tom".to_string() };
match s {
// ❌ 分支必须是常量,这里 name 值需要用函数创建,所以报错
// Stu{ name:"tom".to_string() } => { println!("ok"); },
// 用法 1:分支有限制,但是 if 守卫没有限制必须为常量
Stu{ name } if name =="tom".to_string() => { println!("Hello, {}!", name); }, // Hello, tom!
_ => {}
}
}当然也可以直接用 if ,其实本质两者一样
if s.name == "tom".to_string(){
println!("ok"); // ok
}if let
if let 是 match 的一个语法糖,相当于只有一个分支的 match
// 1、不要和 if 条件判断语法弄混
// 2、if let 不能直接通过 == 判断分支,必须 if let 常量 = 变量 {}
// 3、match 分支必须是常量,if let 后也必须接常量以枚举作为例子
enum Color{
Blue,
Yellow,
}
fn main() {
let my_color = Color::Yellow;
// match 语法
match my_color {
Color::Blue => println!("命中 Blue"),
Color::Yellow => println!("命中 Yellow"),
}
// if let 语法中
if let Color::Yellow = my_color{
println!("命中 Yellow");
}else{ // 也支持 else
println!("未命中 Yellow");
}
}@绑定语法
只能用在匹配模式中
// let else 与 @
let binding @ pattern else { }
// match 与 @
match value{
binding @ pattern // 如果 x 符合pattern条件,则将 x 赋值给 binding
}let else 的例子
let val @ Some(_) = Some(5) else { todo!() }; // pattern 是 Some(_) = Some(5)
println!("{:?}", val); // Some(5)match 的例子
let x = 5;
match x {
val @ 1..=10 => println!("{}", val), // pattern 是 1..=10
_ => println!("Out of range"),
}结合解构结构体重命名语法
enum Message {
Hello { id: i32 },
World (u8)
}
let msg = Message::Hello { id: 5 };
match msg {
// 前面提到的解构语法
Message::Hello { id } => {
println!("{}", id)
},
// id 重命名为 x ,这是结构体解构的特殊语法。前面也提到过
Message::Hello { id:x } => {
println!("{}", x)
},
// id 重命名为 x , 注意: x @ 3..=7 这里是绑定语法
Message::Hello { id: x @ 3..=7 } => {
println!("{}", x) // 这里可以用新变量
},
// 元组结构体,取出 score 符合范围则
Message::World(score @ 1..7)=>{
println!("{}", score) // 这里可以用新变量
}
}还有一种语法:
// id:常量。 id 解构出来的值符合条件才命中
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
},解构
Rust 可以通过解
构语法,提取复杂数据(元组、数组、数组切片、结构体)内部携带的数据。模式匹配语法还额外支持解构带负载的枚举
下面是列举了常用的使用解构的场景,具体如何解构不同类型的数据,参考 let 声明 里列举的方式就行
let 声明
// 元组
let (x, y) = (10, 20);
println!("x: {}, y: {}", x, y);
// 数组
let [x, y] = [10, 20];
println!("x: {}, y: {}", x, y);
// 数组切片
let [x, y] = &[10, 20]; // 因为是引用,x、y 是 &i32 类型
println!("x: {}, y: {}", x, y);
// 结构体
struct Point {
x: i32,
y: i32,
}
let Point { x, y } = Point{ x:1 , y:2}
// 结构体 - 支持特殊的语法
let Point { x:new_var, y } = Point{ x:1 , y:2}; // 将 x 重命名为new_var,⚠️ 不存在变量 x 了,打印 x 会报错⚠️ 不需要提取的部分,可以用 _ 替代
let (_, y) = (10, 20);⚠️ 支持解构数组、数组切片,但是不支持解构 Vec
// 解构数组、元组不能只取部分。回忆下前面提到的 数组、数组切片、元组不能转移部分所有权,这样会使整个数据不可用
let [first,second] =[1,2,3]; // ❌函数入参
// 元组例子
fn deal((x,y,z):(u32,u32,u32)){
println!("{},{},{}",x,y,z); // jack,20
}
fn main() {
deal((1,2,3)) // 1,2,3
}
// 结构体例子
struct Point {
x: i32,
y: i32,
}
fn print_point(Point { x, y }: Point) {
println!("Point: ({}, {})", x, y);
}for循环
let pairs = vec![(1, 2), (3, 4), (5, 6)];
for (x, y) in pairs {
println!("x: {}, y: {}", x, y);
}模式匹配
match、if let、while let 等
模式匹配处理可以解构前面提到的(元组、数组、数组切片、结构体)这些复杂数据 ,还支持解构带负载的枚举
例子参考【模式匹配章节】
解构导致的所有权转移
⚠️ 解构会发生所有权转移,如果你还需要原数据可以用,请注意
以解构结构体为例子,通过 ref 、mut ref 解决
struct User{
name:String,
age:u8,
}
fn main() {
let user=User{
name:"jack".to_string(),
age:20
};
let User{name,age} = user;
println!("{}、{}",name,age); // jack 、 20
println!("{}",user.age); // 20
println!("{}",user.name); // ❌ 编译失败。 name 是 String 会发生 所有权部分移动(partially moved),所以 user 中的 name 不再可用
}ref
struct User{
name:String,
age:u8,
}
fn main() {
let user=User{
name:"jack".to_string(),
age:20
};
// ref 告诉编译器不需要所有权转移, 自动获取的是借用,所以 name 实际类型是 &String
let User{ ref name, age} = user;
// let User{ ref mut name, age} = user; mut name花
println!("{}、{}",name,age); // jack 、 20
println!("{}",user.age); // 20
println!("{}",user.name); // jack
}ref mut 通过引用修改
struct User{
name:String,
age:u8,
}
fn main() {
let mut user=User{
name:"jack".to_string(),
age:20
};
// ref 告诉编译器不需要所有权转移, 自动获取的是借用,所以 name 实际类型是 &String
let User{ ref mut name,age} = user;
let mut new_name="tom".to_string();
*name="tom".to_string();
println!("{}",user.age); // 20
println!("{}",user.name); // tom
}其他类型也是支持的
let (ref z, y) =x; // 元组
let [ref z, y] =x; // 数组、切片错误处理
Rust 的错误处理很有特点
panic!
panic 一般都是严重错误,会终止线程。如果在子线程只会终止子线程,不影响主线程
一般性错误,使用后面的 Result ,这种错误可以捕获处理
fn main() {
panic!();
}
// thread 'main' panicked at src/main.rs:11:5:
// explicit panic //
// stack backtrace: 后面是调用栈
fn main() {
panic!("xxx");
}
// thread 'main' panicked at src/main.rs:11:5:
// xxx // 这里是具体原因
// stack backtrace: 后面是调用栈错误处理
Rust 中函数返参如果可能出现错误使用Result ,否则 Option
Result作为函数返回值,包含返回值或错误,函数调用链中通过返回Result 来传递错误
enum Option<T> {
None,
Some(T),
}
enum Result<T, E> {
Ok(T),
Err(E),
}下面提到的所有函数都是用来出来 Result 的,只不过各有特点
解开返回类型
unwarp、expect
这两个方法是 Option、 Result 才有
- unwrap 将携带的数据解出来,如果是
Option::None|Result::Err则直接 panic - expect 是更高级的处理,唯一的区别是可以设置
panic( "自定义错误信息" )
除非明确不会报错,否则不要使用。还会要用下面的 Result 来处理错误
use std::fs::read;
// 读取文件
fn read_file(file_path:&str) -> String{
let bytes = read(file_path).unwrap() //
let bytes = read(file_path).expect("xxx");//
String::from_utf8(bytes)
}
fn main() {
let content = read_file("../.gitignore");
println!("{:?}", content);
}match
match、if let 匹配语法解出来返回值相对繁琐
use std::fs::{read};
use std::io::ErrorKind;
fn read_file(file_path:&str) -> Result<String, &str>{ // 这里指的是 Ok(String)\Err(&str)
let bytes = read(file_path); // 返回值是 Result
match bytes {
// 读取成功。返回值是字节
Ok(bytes) => {
match String::from_utf8(bytes) { // 转化为 String
Ok(string) => Ok(string),
Err(e) => Err("utf8转换失败")
}
},
// 读取失败
Err(e) =>{
if e.kind() == ErrorKind::NotFound {
return Err("文件不存在")
}
Err("未知异常")
}
}
}
fn main() {
println!("当前工作目录: {:?}", env::current_dir().unwrap());
let content = read_file("./.gitignore"); // 结果是 Result 需要解开,才能拿到内容
match content {
Ok(content) => {
println!("{}", content); // 文件内容
},
Err(e)=>println!("{}", e) // 内部抛出的错误
}
}?语法
?是 match 处理的语法糖
1、获取 Result 返回值
- 必须有变量接收,否则报错
- 成功就解出数据后直接赋值变量,失败就终止函数并抛出错误。函数返回值 Result 的 E 必须是 std::error::Error 类型
use std::error::Error;
let ret = read(file_path)?;
// 返回的错误类型,不一定是哪个函数抛出的错误类型。Error是通用的 Error,用 Box<dyn Error>
fn read_file(file_path:&str) -> Result<String, Box<dyn Error> >{
// 成功就直接赋值变量,失败就终止抛出 std::error::Error 类型的错误
let bytes = read(file_path)?;
let content = String::from_utf8(bytes)?;
Ok(content)
}2、链式调用
let mut s = String::new();
File::open("hello.txt")?.read_to_string(&mut s)?; //open错误就抛出,正常才调用read_to_string3、不仅可以用与 Result,还能用于 Option
- 成功解出携带的数据,失败终止函数并抛出 None,函数返回值
Option<T>
fn get_number(opt: Option<i32>) -> Option<i32> {
let num = opt?; // 如果是 None,直接 return None
Some(num + 1)
}
fn main() {
let result = get_number(Some(10));
println!("{:?}", result); // 输出 Some(11)
let result_none = get_number(None);
println!("{:?}", result_none); // 输出 None
}解开返回类型,添加Err 默认处理
unwrap_* 这些方法是用来解开 Option、 Result 的,遇到错误不会 panic
unwrap_or、unwrap_or_else、unwrap_or_default
返回 Ok、Some 会解出来携带的数据,如果是 Err、None 则返回默认值。不会 panic
let res1 :Result<&str,&str> = Ok("正常");
let res2 :Result<&str,&str> = Err("异常");
// ------------ unwrap_or() ---------------
// 手动设置固定默认值
println!("{}", res1.unwrap_or("默认值")); // 正常
println!("{}", res2.unwrap_or("默认值")); // 默认值
// ------------ unwrap_or_else() ---------------
// 手动设置动态的默认值。参数是个闭包,返回值就是默认值
let res2 :Result<&str,&str> = Err("异常");
println!("{}", res2.unwrap_or_else(|err| {
//可以进行 打印日志、清理资源 之类的操作
"默认值"
})); // 默认值
println!("{}", res2.unwrap_or_else(|err| {
//可以进行 打印日志、清理资源 之类的操作
process::exit(1); // 不用默认值,直接退出
}));
// ------------ unwrap_or_default() 按照默认值返回---------------
// 返回默认值 ,Rust 为内置的类型都实现了Default Trait
// 结构体需要用derive派生语法,字段是对应类型的默认值
#[derive(Default)]
struct Stu{
name: String, // 默认""
age: u8, // 默认 0
score:HashMap<String, i32>,// 默认 {}
hobby:Vec<String> // 默认 []
x:X // 如果字段是结构体类型,有需要 derive 派生 Default
}
#[derive(Default)]
struct X{}
// 也可以自己实现 Default Trait
struct Stu{ name:String }
impl Default for Stu{
fn default()->Stu{
Stu{name:"匿名".to_string()}
}
}unwrap_err
只能提取Err、None 携带的数据,如果是 Ok、Some 则直接 panic
所以,请明确一定报错,才能使用这个
let e: Result<&str, &str> = Err("wrong");
println!("{}",e.unwrap_err()) // wrong不解开操作携带数据
对函数返回的错误进行包装,以增加更多信息
let d: Result<i32, String> = Err("某种错误".to_string());
assert_eq!(d.map_err(|inner| { format!("附加信息:{}", inner) }), Err("附加信息:某种错误".to_string()));确定为 Some、Ok ,通过 map 操作内部数据返回原类型
let a = Some(1);
assert_eq!(a.map(|inner| { inner + 1 }), Some(2));
let c:Result<i32, String> = Ok(1);
assert_eq!(c.map(|inner| { inner + 1 }), Ok(2));如果不确定,请使用map_or、map_or_else 同样操作Some、Ok,但是如果出现 None、Err 则使用默认值
// m ,如果是None、Err 用来处理默认值
let b = None;
assert_eq!(b.map_or(10, |inner: i32| { inner + 1 }), 10);
assert_eq!(b.map_or_else(|| { 12 }, |inner: i32| { inner + 1 }), 12); // 通过闭包提供默认值直接判断
is_ok
如果只关系 Result 是 Ok 还是 Err,不关系 Ok 携带的数据可以用
let res1 :Result<&str,&str> = Ok("正常");
println!("{}", res1.is_ok()); // true
let res2 :Result<&str,&str> = Err("错误");
println!("{}", res2.is_ok()); // false自定义错误(待补充)
Rust 中通过 Result::Err(E) 作为出现错误时的返回值,如果携带字符串 Err("错误 xxx"),不方便根据属于哪种类型的错误
属性语法
#[...] 被称为属性(attributes),用来向编译器提供元信息,控制编译行为或代码生成逻辑
#[derive(xxx)]派生宏属性,xxx为 Rust 内置的特征 Trait,被标记的类型自动实现了 Trait
Rust 支持的派生 Trait :https://course.rs/appendix/derive.html
rust#[derive(Debug)] struct X{} print!("{:?}",X{}); // 派生了 Debug Trait 的结构体,print 可以打印其内部字段#[cfg(xxx)]条件编译属性, 编译器会在符合
xxx条件的情况下执行代码rust#[cfg(test)] // 最常用的就是标记mod,只有在 `cargo test` 才编译 mod tests { #[test] // 编译完成后,自动调用被标记为测试函数的函数 fn xx(){ // } } | 示例 | 含义 | | ----------------------------- | --------------------------- | | `#[cfg(test)]` | 仅在 `cargo test` 下编译 | | `#[cfg(debug_assertions)]` | 仅在 debug 模式下编译(非 release) | | `#[cfg(target_os = "linux")]` | 仅在 Linux 平台下编译 | | `#[cfg(feature = "foo")]` | 仅在启用了名为 `foo` 的 feature 时编译 |
并发
并发:交替运行
并行:真正的同时运行
Rust 的进程、线程都是直接使用的系统进程、线程,运行时时是由系统调度的
线程同步
有几点注意:
代码执行到
thread::spawn()时,就开始创建子线程运行了子线程 B,并不属于创建的它的线程 A,而是都属于 main 进程的子线程。
main 结束会直接终止全部子线程;线程A结束不会终止线程B
rustfn main(){ // main 进程 let handler = thread::spawn(move || { // 线程 A thread::spawn(move ||{ // 线程 B // xxx }) }); }join上面提到线程都属于 main,但是 join 提供了一种方式让线程阻塞当前进程的执行,等待子线程执行完毕rustuse std::thread; fn main() { let mut handlers = vec![]; for i in 0..5 { let handler = thread::spawn(move || println!("{i}")); // 已经开始执行了 handlers.push(handler); } for handler in handlers { // 将线程的 handler.join 到外部线程,外部线程就会阻塞住等待内部线程执行完毕 。 类似 JS 的 Promise.allSettled // 进程当前可能得状态: // 1、执行完毕了,join立即返回 // 2、正在执行新,join阻塞等待结果 // 3、panic 了,join 会返回 Err match hdl.join() { Ok(val) => println!("正常: {:?}", val), Err(e) => println!("子线程 panic: {:?}", e), // ✅ 能捕获! } } }
多线程并发
- channel :通过通信来共享内存
- 锁 :共享内存
channel 更简单,而锁能实现更精细的控制具有更高的性能
channel
Rust 中有2 种通道
- 异步通道(channel):生产者可以一直写入 channel
- 同步通道(sync_channel):通道可以设置通道缓冲区,通道满了就会阻塞生产者,这个更像 Go 的 channel
所有权类型的数据从生产者传递给消费者,发生所有权转移
Rust 不必手动关闭通道,当所有生产者或所有消费者离开作用域,满足其一会自动 drop 通道 (在编译期实现的,完全没有运行期性能损耗)
异步通道
use std::sync::mpsc;
use std::thread;
// channel
fn main() {
let (w, r) = mpsc::channel::<String>();
for i in 0..5 {
let w = w.clone(); // 需要 clone 分别传入每个线程
thread::spawn(move || {
w.send(format!("hello {}", i)).unwrap();
drop(w)
});
}
drop(w); // ⚠️ 线程结束后会自动 drop生产者,但是最初创建的生产者需要手动 drop,否则接收端会一直阻塞等待发送者发送数据。
// 读取通道数据:-------
// 方式 1: 返回Result。 阻塞进程,直到读取1次数据后结束。如果读取到数据前通道 channel 关闭,则返回 Err(RecvError)
let msg = r.recv()
// 方式 2: 返回Result。不阻塞进程尝试读取一次数据后结束。可能是Ok(数据)、Err(TryRecvError::Empty)通道为空、Err(TryRecvError::Disconnected)通道关闭
let msg = r.try_recv().unwrap()
// 方式 3:for 循环。会阻塞等待数据,直到所有生产者都被 drop,才继续执行
for msg in r {
println!("{}", msg);
}
print!("end");
}同步通道
use std::sync::mpsc;
use std::thread;
fn main() {
let (w, r) = mpsc::sync_channel(1); // 通道缓冲区
let handle = thread::spawn(move || {
w.send(1).unwrap();
w.send(2).unwrap(); // 阻塞等待 1 被读取了,才能写入 2
});
for msg in r {
println!("receive {}", msg)
}
handle.join().unwrap();
}锁
Mutex
数据 count 从 0 开始,每个线程拿到锁后才能对数据 +1,所以用了 Mutex::new
每个线程就会夺走所有权,而所有权只有 1 分,所以用了 Arc::new
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
// 将数据 0 ,包裹在 Mutex 锁里
// Arc是引用计数器,允许值所有权能转移到多个进程中。线程结束自动计数器-1,当计数器为 0 时释放资源
let count = Arc::new(Mutex::new(0));
let mut handlers = vec![];
for i in 0..5 {
let count = Arc::clone(&count); // 这个 clone 底层Arc只是引用+1,并不是真的克隆数据
let handler = thread::spawn(move || {
let mut count = count.lock().unwrap(); // lock获取锁 MutexGuard
*count += 1 // MutexGuard上解引用+1
});
handlers.push(handler)
}
// 在父线程中执行 [子线程.join],用阻塞父进程等待子进程结束。感觉像JS的Promise.allSettle
for handler in handlers {
handler.join().unwrap();
}
println!("{}", *count.lock().unwrap()); // 5
}除了 lock 阻塞获取锁,还有 try_lock非阻塞获取锁,如果失败返回 Err
use std::sync::{Mutex, Arc};
use std::thread;
use std::time::Duration;
fn main() {
let mutex = Arc::new(Mutex::new(0));
let mutex_clone = mutex.clone();
// 在另一个线程中占用锁一段时间
thread::spawn(move || {
let mut data = mutex_clone.lock().unwrap();
*data += 1;
println!("Data incremented to {}", *data);
// 离开作用域自动释放锁,用睡眠模拟长时间占用锁
thread::sleep(Duration::from_secs(4));
});
// 阻塞主线程,以保证子线程先拿到锁并一直持有
thread::sleep(Duration::from_secs(3));
// 尝试获取锁
loop {
match mutex.try_lock() {
Ok(mut guard) => {
// 成功获取锁后执行操作
*guard += 1;
println!("Data incremented to {} in main thread", *guard);
break; // 跳出循环
}
Err(_) => {
// 获取锁失败时的处理逻辑
println!("Failed to get the lock, retrying...");
// 等待一段时间后重试
thread::sleep(Duration::from_millis(500));
}
}
}
}RwLock
Metux 无论读写都会阻塞其他线程,而 RwLock 可以多进程并发读取。但是根据 Rust 圣经描述 RwLock使用的是系统实现,性能不佳
Atomic原子类型
原子指的是一系列不可被 CPU 上下文交换的机器指令,这些指令组合在一起就形成了原子操作。原子操作不会被其他 CPU 操作打断
由于原子操作是通过指令提供的支持,因此它的性能相比锁和消息传递会好很多
Send & Sync
Send:类型不能同时被多个线程引用,而是可以在线程间安全的传递其所有权
Sync:类型在线程间安全的共享(通过引用,例如:Arc )
这两个 Trait 是标记特征,实际上没有任何实现,只是提示使用者某些类型是否线程安全
规则:
- 类型&T 实现了 Send,就一定实现了 Sync
- Sync、Send 是自动派生 Trait,复合类型的成员都实现了则该复合类型就是自动实现了 Sync、Send
MuteGuard 、Rc 、Cell 、裸指针 x
实践
多进程执行任务,返回处理结果
类型 Promise.allSettled ,多进程处理任务最后统计处理结果
这个没有涉及读写公共数据,所以都用不上加锁
use std::fmt::format;
use std::thread;
fn main() {
let mut handlers = vec![];
for i in 0..5 {
let handler = thread::spawn(move || {
if i % 2 == 0 {
return Err(format!("线程 {} panic", i));
}
Ok(format!("线程 {} 执行完毕", i))
});
handlers.push(handler);
}
for handler in handlers {
match handler.join() {
Ok(ret) => {
println!("{:?}", ret);
}
Err(err) => println!("{:?}", err),
}
}
println!("结束");
}异步(待补充)
需要引入官方维护的依赖
[dependencies]
futures = "0.3"顺序调用异步函数
use futures::executor::block_on;
fn main() {
// async函数返回 Future
async fn f1() {
f2().await; // 必须用 await,否则 f2不会
println!("hello f1");
}
async fn f2() {
println!("hello f2");
}
// 需要执行器来执行 Future,否则函数什么也不会做(JS 异步函数调用就会执行)
// block_on 是一种简单粗暴的执行器 ,入参 Future,会阻塞线程等待 Future 完成
block_on(f1());
}并发异步函数
类Promise.allSettled
futures::join! 、futures::future::join_all
use futures::executor::block_on;
fn main() {
// async函数返回 Future
async fn f1() -> String {
println!("执行 f1");
"f1".to_string()
}
async fn f2() -> String {
println!("执行 f2");
"f2".to_string()
}
async fn parallel() {
let res = futures::join!(f1(), f2());
println!("{:?}", res); // ("f1", "f2")
// 1、 f1、f2 在当前线程并发
// 2、 返回值是元组,对应异步函数返回值
// 原理:
// Future 轮询返回 Poll::Pending 状态,继续轮询直到 Poll:Ready(T)停止。其中 T 就是结果
// f1、f2 交替轮询,因为没有阻塞所有第一次轮询就是 Ready 了,所以输出顺序也是固定的
}
block_on(parallel());
// --------------------------------------------
// 简写: Rust 中没有 JS 的自执行函数,但是可以用下面的写法。
block_on(async {
let res = futures::join!(f1(), f2()); // 块的返回值是 Future 就行p
println!("{:?}", res); // ("f1", "f2") 返回元组
});
}入参是 Future 动态数组
use futures::future::join_all;
use std::future::Future;
use std::pin::Pin;
block_on(async {
let futures_vec: Vec<Pin<Box<dyn Future<Output = String>>>> =
vec![Box::pin(f1()), Box::pin(f2())];
// async 返回的 impl Future,Vec 要求元素类型一致。所以用 Box 包一层
let res = join_all(futures_vec).await;
println!("{:?}", res); // ["f1", "f2"] 返回 Vec<String>
});类Promise.all
类 Promise.race
select!
use futures::{
future::FutureExt, // for `.fuse()`
pin_mut,
select,
};
async fn task_one() { /* ... */ }
async fn task_two() { /* ... */ }
async fn race_tasks() {
let t1 = task_one().fuse();
let t2 = task_two().fuse();
pin_mut!(t1, t2);
select! {
() = t1 => println!("任务1率先完成"),
() = t2 => println!("任务2率先完成"),
}
}Macro 宏(简略介绍)
宏分为两大类:
- 声明式宏( declarative macros)
macro_rules! - 三种过程宏( procedural macros )
- 派生宏:为目标结构体或枚举派生指定的代码,例如
#[derive(Debug)] - 类属性宏:为目标添加自定义的属性
- 类函数宏
- 派生宏:为目标结构体或枚举派生指定的代码,例如
宏类似函数,例如 vec![1,2,3] 就会生成 Vec 动态数组。但是不同的是:
- 宏更像是一种标记,在编译期间展开为真正的 Rust 代码(函数是运行时执行)
- 宏支持任意参数,而函数是固定的参数
Rust中头疼的问题
声明
正常使用 let 声明变量
let x = 10;但是在很多语法中,就不遵守这个规则
// 1、for 语法中
let x = [1,2,3,4,5];
for value in x { // 声明变量 value
print!("{value}");
}
// 2、match 、if let 模式匹配中解构
enum Shape {
Rectangle { width:u32,height:u32 }, // 矩形
}
fn main(){
let s = Shape::Rectangle {width:10,height:20};
match s {
Shape::Rectangle{width,height} => {
println!("{} {}",width , height); // 声明变量 width,height
},
_=>{}
}
//
if let Shape::Rectangle{width,height} = s {
println!("{} {}",width , height); // 声明变量 width,height
}
}语法检查
Rust 都需要进行啥语法检查?
熟悉后看报错,就能快速定位到底是哪个检查出错了
类型检查|不可变变量修改检查|未使用变量检查|match 匹配语法是否穷尽检查
线程安全检查
所有权检查
使用失效的变量会报错
rustlet s1 = String::from("hello"); let s2 = s1; // 所有权转移 println!("{}", s1); // ❌ 错:s1 已无效借用检查
- 任意时刻只能存在:
- 一个可变借用(
&mut T),或 - 多个不可变借用(
&T)
- 一个可变借用(
- 借用不能悬空(不存在悬垂引用)
- 任意时刻只能存在:
生命周期
生命周期一般会自动推导,复杂情况下需要手动标注
Sized检查
dyn Trait、[T] 都是 DST(动态类型),需要用引用、智能指针间接使用